
Hva er RAG i AI-søk: Komplett guide til Retrieval-Augmented Generation
Lær hva RAG (Retrieval-Augmented Generation) er i AI-søk. Oppdag hvordan RAG forbedrer nøyaktighet, reduserer hallusinasjoner og driver ChatGPT, Perplexity og G...
7 min lesing

En Retrieval-Augmented Generation (RAG)-pipeline er en arbeidsflyt som gjør det mulig for AI-systemer å finne, rangere og sitere eksterne kilder når de genererer svar. Den kombinerer dokumenthenting, semantisk rangering og LLM-generering for å gi nøyaktige, kontekstuelt relevante svar forankret i reelle data. RAG-systemer reduserer hallusinasjoner ved å konsultere eksterne kunnskapsbaser før svar genereres, noe som gjør dem essensielle for applikasjoner som krever faktanøyaktighet og kildehenvisning.
En Retrieval-Augmented Generation (RAG)-pipeline er en arbeidsflyt som gjør det mulig for AI-systemer å finne, rangere og sitere eksterne kilder når de genererer svar. Den kombinerer dokumenthenting, semantisk rangering og LLM-generering for å gi nøyaktige, kontekstuelt relevante svar forankret i reelle data. RAG-systemer reduserer hallusinasjoner ved å konsultere eksterne kunnskapsbaser før svar genereres, noe som gjør dem essensielle for applikasjoner som krever faktanøyaktighet og kildehenvisning.
En Retrieval-Augmented Generation (RAG)-pipeline er en AI-arkitektur som kombinerer informasjonsinnhenting med generering fra store språkmodeller (LLM) for å produsere mer nøyaktige, kontekstuelt relevante og verifiserbare svar. I stedet for å stole utelukkende på en LLMs treningsdata, henter RAG-systemer dynamisk relevante dokumenter eller data fra eksterne kunnskapsbaser før de genererer svar, noe som reduserer hallusinasjoner betydelig og forbedrer faktanøyaktigheten. Pipen fungerer som en bro mellom statiske treningsdata og sanntidsinformasjon, slik at AI-systemer kan referere til oppdatert, domenespesifikt eller proprietært innhold. Denne tilnærmingen har blitt avgjørende for organisasjoner som krever svar med kildereferanser, etterlevelse av nøyaktighetsstandarder og transparens i AI-generert innhold. RAG-pipelines er spesielt verdifulle i overvåking av AI-systemer der sporbarhet og kildehenvisning er kritiske krav.
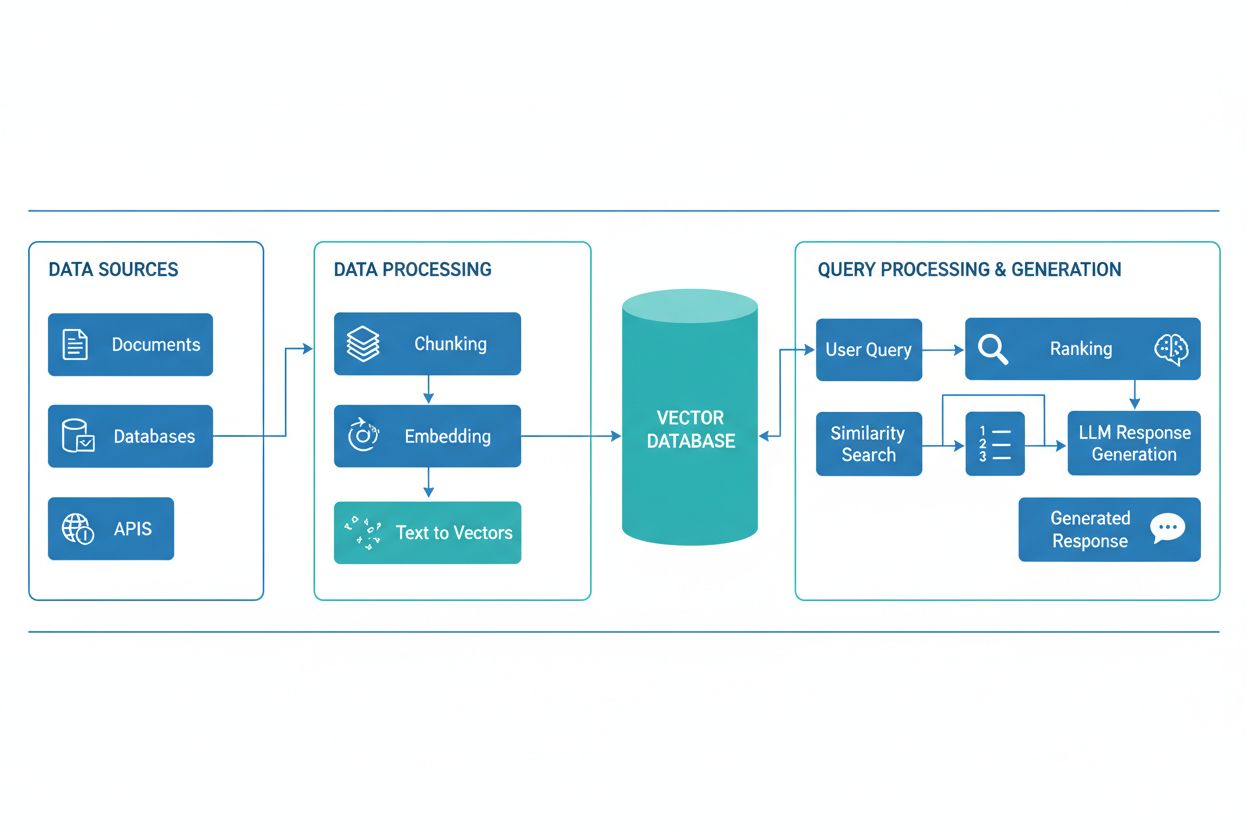
En RAG-pipeline består av flere sammenkoblede komponenter som samarbeider for å hente relevant informasjon og generere forankrede svar. Arkitekturen inkluderer vanligvis et dokumentinntakslag som behandler og klargjør rådata, en vektordatabase eller kunnskapsbase som lagrer embeddinger og indeksert innhold, en hentemekanisme som identifiserer relevante dokumenter basert på brukerforespørsler, et rangeringssystem som prioriterer de mest relevante resultatene, og en genereringsmodul drevet av en LLM som syntetiserer hentet informasjon til sammenhengende svar. Tilleggskomponenter inkluderer spørreprosessering og forhåndsbehandling som normaliserer brukerinput, embeddingmodeller som konverterer tekst til numeriske representasjoner, og en tilbakemeldingssløyfe som kontinuerlig forbedrer hente-nøyaktigheten. Orkestreringen av disse komponentene avgjør RAG-systemets samlede effektivitet og ytelse.
| Komponent | Funksjon | Nøkkelteknologier |
|---|---|---|
| Dokumentinntak | Behandling og klargjøring av rådata | Apache Kafka, LangChain, Unstructured |
| Vektordatabase | Lagring av embeddinger og indeksert innhold | Pinecone, Weaviate, Milvus, Qdrant |
| Hentemotor | Identifisere relevante dokumenter | BM25, Dense Passage Retrieval (DPR) |
| Rangeringssystem | Prioritere søkeresultater | Cross-encoders, LLM-basert omrangering |
| Genereringsmodul | Syntetisere svar fra kontekst | GPT-4, Claude, Llama, Mistral |
| Spørreprosessor | Normalisere og forstå brukerinput | BERT, T5, tilpassede NLP-pipelines |
RAG-pipelinen opererer gjennom to distinkte faser: hente-fasen og genereringsfasen. I hente-fasen konverterer systemet brukerens forespørsel til en embedding ved bruk av samme embeddingmodell som bearbeidet kunnskapsbasedokumentene, og søker deretter i vektordatabasen for å identifisere de mest semantisk like dokumentene eller avsnittene. Denne fasen returnerer vanligvis en rangert liste med kandidatdokumenter, som kan raffineres videre gjennom omrangeringalgoritmer som benytter cross-encoders eller LLM-basert poenggiving for å sikre relevans. I genereringsfasen formateres de høyest rangerte hentede dokumentene inn i et kontekstvindu og sendes til LLM-en sammen med den opprinnelige forespørselen, slik at modellen kan generere svar forankret i faktisk kildemateriale. Denne to-fase tilnærmingen sikrer at svarene både er kontekstuelt passende og sporbare til spesifikke kilder, noe som gjør det ideelt for applikasjoner som krever sitering og ansvarlighet. Kvaliteten på sluttresultatet avhenger kritisk av både relevansen til de hentede dokumentene og LLM-ens evne til å syntetisere informasjon sammenhengende.
RAG-økosystemet omfatter et bredt spekter av spesialiserte verktøy og rammeverk utviklet for å forenkle bygging og utrulling av pipeliner. Moderne RAG-implementeringer benytter flere teknologikategorier:
Disse verktøyene kan kombineres modulært, slik at organisasjoner kan bygge RAG-systemer tilpasset sine spesifikke behov og infrastrukturbegrensninger.
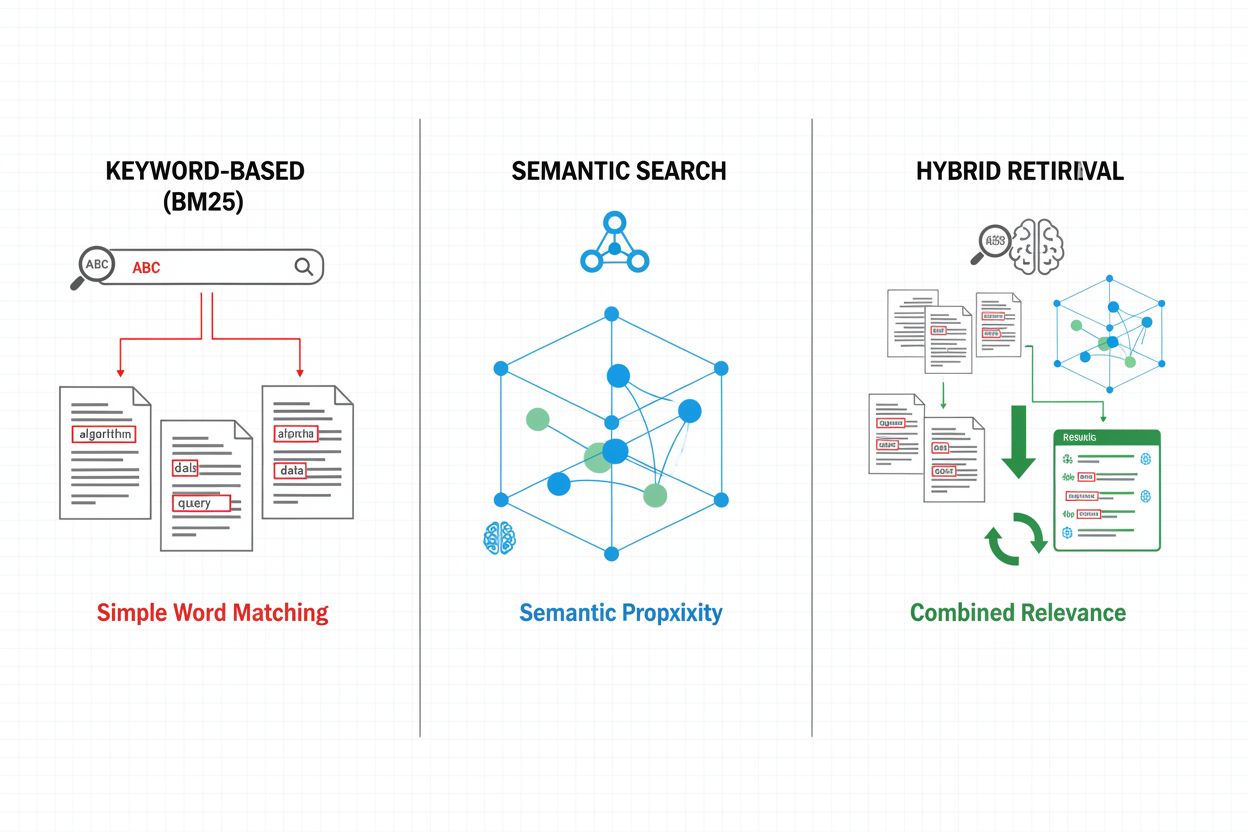
Hentemekanismer utgjør fundamentet for RAG-pipelineens effektivitet, og har utviklet seg fra enkle nøkkelordbaserte metoder til sofistikerte semantiske søkemetoder. Tradisjonell nøkkelordbasert henting med BM25-algoritmer er fortsatt beregningseffektiv og egnet for eksakte treff, men sliter med semantisk forståelse og synonymer. Dense Passage Retrieval (DPR) og andre nevrale hente-metoder adresserer disse begrensningene ved å kode både forespørsler og dokumenter til tette vektorembeddinger, slik at semantisk likhet kan matches og mening fanges utover overfladiske nøkkelord. Hybride hente-tilnærminger kombinerer nøkkelordbasert og semantisk søk, og utnytter styrkene fra begge metoder for å forbedre recall og presisjon på tvers av ulike forespørselstyper. Avanserte hentemekanismer inkluderer spørreutvidelse, der den opprinnelige forespørselen utvides med relaterte termer eller omformuleringer for å fange opp flere relevante dokumenter. Omrangeringslag raffinerer ytterligere resultatene ved å bruke mer beregningstunge modeller som vurderer kandidatdokumentene ut fra dypere semantisk forståelse eller oppgavespesifikk relevans. Valg av hentemekanisme påvirker både nøyaktigheten på hentet kontekst og den beregningsmessige kostnaden for RAG-pipelinen, og krever nøye vurdering av avveininger mellom hastighet og kvalitet.
RAG-pipelines gir betydelige fordeler over tradisjonelle LLM-baserte tilnærminger, spesielt for applikasjoner som krever nøyaktighet, oppdatert informasjon og sporbarhet. Ved å forankre svarene i hentede dokumenter, reduserer RAG-systemer dramatisk hallusinasjoner—tilfeller der LLM-er genererer tilsynelatende plausible, men faktuelt ukorrekte opplysninger—og gjør dem dermed egnet for høy-risiko domener som helse, jus og finans. Muligheten til å referere til eksterne kunnskapsbaser gjør det mulig for RAG-systemer å levere oppdatert informasjon uten å måtte trene modellene på nytt, slik at organisasjoner kan holde svarene oppdaterte etter hvert som ny informasjon blir tilgjengelig. RAG-pipelines støtter domenespesifikk tilpasning ved å inkludere proprietære dokumenter, interne kunnskapsbaser og spesialisert terminologi, noe som gir mer relevante og kontekstuelt passende svar. Hentekomponenten gir transparens og revisjonsmuligheter ved eksplisitt å vise hvilke kilder som har informert hvert svar, avgjørende for etterlevelse og brukertillit. Kostnadseffektiviteten forbedres gjennom bruk av mindre, mer effektive LLM-er som kan generere høy-kvalitets svar når de får relevant kontekst, noe som reduserer beregningskostnader sammenlignet med større modeller. Disse fordelene gjør RAG spesielt verdifullt for organisasjoner som implementerer AI-overvåkingssystemer der siteringsnøyaktighet og innholdssynlighet er sentralt.
Til tross for fordelene står RAG-pipelines overfor flere tekniske og driftsmessige utfordringer som krever nøye håndtering. Kvaliteten på de hentede dokumentene avgjør direkte kvaliteten på svarene, og feil i henting er vanskelige å rette opp—et fenomen kjent som “garbage in, garbage out”, der irrelevante eller utdaterte dokumenter i kunnskapsbasen forplanter seg til sluttresultatet. Embeddingmodeller kan ha problemer med domenespesifikk terminologi, sjeldne språk eller svært teknisk innhold, noe som fører til dårlig semantisk matching og tap av relevante dokumenter. Beregningskostnadene for henting, embeddinggenerering og omrangering kan være betydelige i stor skala, særlig ved store kunnskapsbaser eller høyt spørringsvolum. Kontekstvindubegrensninger i LLM-er begrenser mengden hentet informasjon som kan inkluderes i prompten, og krever nøye utvalg og oppsummering av relevante avsnitt. Å opprettholde kunnskapsbasens oppdatering og konsistens gir driftsmessige utfordringer, spesielt i dynamiske miljøer der informasjon ofte endres eller kommer fra mange kilder. Evaluering av RAG-systemets ytelse krever omfattende måleparametre utover tradisjonell nøyaktighet, inkludert hente-presisjon, svarrelevans og siteringsriktighet, noe som kan være vanskelig å vurdere automatisk.
RAG representerer én tilnærming blant flere strategier for å forbedre LLM-nøyaktighet og relevans, med ulike avveininger. Finjustering innebærer å trene LLM-er på domenespesifikke data og gir dyp modelltilpasning, men krever betydelige beregningsressurser, merkede treningsdata og løpende vedlikehold etter hvert som informasjon endres. Prompt engineering optimaliserer instruksjonene og konteksten som gis til LLM-er uten å endre modellvektene, og gir fleksibilitet og lave kostnader, men begrenses av modellens treningsdata og kontekstvinduets størrelse. In-context learning bruker fåeksempler i promten for å styre modellatferd, gir rask tilpasning, men bruker verdifulle konteksttokens og krever nøye valg av eksempler. Sammenlignet med disse gir RAG en mellomløsning: den gir dynamisk tilgang til oppdatert informasjon uten retrening, opprettholder transparens gjennom eksplisitt kildehenvisning, og skalerer effektivt på tvers av ulike kunnskapsdomener. RAG introduserer imidlertid ekstra kompleksitet gjennom henteinfrastruktur og potensielle hente-feil, mens finjustering gir tettere integrering av domenekunnskap i modellatferd. Den optimale tilnærmingen innebærer ofte å kombinere flere strategier—for eksempel å bruke RAG med finjusterte modeller og nøye utformede promter—for å maksimere nøyaktighet og relevans for spesifikke bruksområder.
Å implementere en produksjonsklar RAG-pipeline krever systematisk planlegging innen datapreparering, arkitekturdesign og driftsmessige hensyn. Prosessen starter med klargjøring av kunnskapsbasen: innhenting av relevante dokumenter, rengjøring og standardisering av format, og deling av innhold i passende store biter som balanserer kontekstbevaring mot presis henting. Deretter velger organisasjoner embeddingmodeller og vektordatabaser basert på ytelseskrav, ventetidsbegrensninger og skalerbarhet, med hensyn til embeddingdimensjonalitet, spørringgjennomstrømning og lagringskapasitet. Hentesystemet konfigureres så, inkludert valg av hentealgoritmer (nøkkelord, semantisk eller hybrid), omrangeringsstrategier og filtreringskriterier. Integrasjon med LLM-leverandører følger, og det etableres forbindelse til genereringsmodeller og defineres promptmaler som effektivt inkorporerer hentet kontekst. Testing og evaluering er kritisk, og krever måleparametre for henting (presisjon, recall, MRR), generering (relevans, sammenheng, faktualitet) og ende-til-ende-systemytelse. Utrullingshensyn inkluderer oppsett av overvåking for hente-nøyaktighet og genereringskvalitet, implementering av tilbakemeldingssløyfer for å identifisere og løse feilmønstre, og etablering av prosesser for oppdatering og vedlikehold av kunnskapsbasen. Til slutt innebærer kontinuerlig optimalisering analyse av brukerinteraksjoner, identifisering av vanlige feilmønstre og iterativ forbedring av hente-mekanismer, omrangeringsstrategier og prompt engineering for å øke den samlede systemytelsen.
RAG-pipelines er grunnleggende for moderne AI-overvåkingsplattformer som AmICited.com, der sporing av kilder og nøyaktighet for AI-generert innhold er essensielt. Ved eksplisitt å hente og sitere kildedokumenter, skaper RAG-systemer et reviderbart spor som gjør det mulig for overvåkingsplattformer å verifisere påstander, vurdere faktanøyaktighet og oppdage potensielle hallusinasjoner eller feilattribusjoner. Denne siteringsmuligheten dekker et kritisk behov for AI-transparens: brukere og revisorer kan spore svar tilbake til opprinnelige kilder, noe som muliggjør uavhengig verifisering og bygger tillit til AI-generert innhold. For innholdsprodusenter og organisasjoner som bruker AI-verktøy gir RAG-basert overvåking innsikt i hvilke kilder som har bidratt til spesifikke svar, og støtter etterlevelse av krav til kreditering og innholdsstyring. Hentekomponenten i RAG-pipelines genererer rike metadata—inkludert relevansscore, dokumentrangering og hente-tillitsmålinger—som overvåkingssystemer kan analysere for å vurdere svarenes pålitelighet og oppdage når AI-systemer opererer utenfor sitt kunnskapsdomene. Integrasjon av RAG med overvåkingsplattformer muliggjør deteksjon av siteringsdrift, der AI-systemer gradvis beveger seg bort fra autoritative kilder mot mindre pålitelige, og støtter håndhevelse av innholdspolicyer rundt kildekvalitet og mangfold. Etter hvert som AI-systemer blir stadig mer integrert i kritiske arbeidsflyter, skaper kombinasjonen av RAG-pipelines og omfattende overvåking ansvarlighetsmekanismer som beskytter brukere, organisasjoner og det bredere informasjonssamfunnet mot AI-generert feilinformasjon.
RAG og finjustering er komplementære tilnærminger for å forbedre LLM-ytelse. RAG henter eksterne dokumenter ved forespørsel uten å endre modellen, noe som gir sanntidstilgang til data og enkle oppdateringer. Finjustering trener modellen på domenespesifikke data, gir dypere tilpasning, men krever betydelige beregningsressurser og manuelle oppdateringer når informasjon endres. Mange organisasjoner bruker begge teknikkene sammen for optimale resultater.
RAG reduserer hallusinasjoner ved å forankre LLM-svar i hentede faktadokumenter. I stedet for å stole utelukkende på treningsdata, henter systemet relevante kilder før generering, og gir modellen konkrete bevis å referere til. Denne tilnærmingen sikrer at svarene er basert på faktisk informasjon, ikke bare modellens lærte mønstre, og forbedrer faktanøyaktigheten betydelig og reduserer feilaktige eller misvisende påstander.
Vektorembeddinger er numeriske representasjoner av tekst som fanger semantisk mening i et flerdimensjonalt rom. De gjør det mulig for RAG-systemer å utføre semantisk søk, finne dokumenter med lignende betydning selv om de bruker ulike ord. Embeddinger er avgjørende fordi de lar RAG gå utover nøkkelordmatching for å forstå konseptuelle relasjoner, forbedre relevansen av henting og muliggjøre mer nøyaktig svargenerering.
Ja, RAG-pipelines kan inkorporere sanntidsdata gjennom kontinuerlig innhenting og indekseringsprosesser. Organisasjoner kan sette opp automatiserte pipelines som regelmessig oppdaterer vektordatabasen med nye dokumenter, slik at kunnskapsbasen alltid er oppdatert. Denne muligheten gjør RAG ideell for applikasjoner som krever oppdatert informasjon, som nyhetsanalyse, prisintelligens og markedsmonitorering, uten behov for å trene LLM-en på nytt.
Semantisk søk er en henteteknikk som finner dokumenter basert på betydningslikhet ved hjelp av vektorembeddinger. RAG er en komplett pipeline som kombinerer semantisk søk med LLM-generering for å produsere svar forankret i hentede dokumenter. Mens semantisk søk fokuserer på å finne relevant informasjon, legger RAG til genereringskomponenten som syntetiserer hentet innhold til sammenhengende svar med siteringer.
RAG-systemer bruker flere mekanismer for å velge kilder til sitering. De benytter hentealgoritmer for å finne relevante dokumenter, omrangeringmodeller for å prioritere de mest relevante resultatene, og verifiseringsprosesser for å sikre at siteringene faktisk støtter påstandene. Noen systemer bruker 'siter mens du skriver'-metoder der påstander bare gjøres hvis de støttes av hentede kilder, mens andre verifiserer siteringer etter generering og fjerner påstander som ikke kan støttes.
Nøkkelutfordringer inkluderer å opprettholde kunnskapsbasens oppdatering og kvalitet, optimalisere hente-nøyaktighet på tvers av ulike innholdstyper, håndtere kostnader i stor skala, håndtere domenespesifikk terminologi som embedding-modeller kanskje ikke forstår godt, og evaluere systemytelse med omfattende måleparametre. Organisasjoner må også håndtere begrensninger i LLM-ens kontekstvindu og sikre at hentede dokumenter forblir relevante etter hvert som informasjonen utvikler seg.
AmICited sporer hvordan AI-systemer som ChatGPT, Perplexity og Google AI Overviews henter og siterer innhold via RAG-pipelines. Plattformen overvåker hvilke kilder som velges for sitering, hvor ofte merkevaren din dukker opp i AI-svar, og om siteringene er korrekte. Denne innsikten hjelper organisasjoner å forstå sin tilstedeværelse i AI-formidlet søk og sikre korrekt kreditering av innholdet sitt.
Følg med på hvordan AI-systemer som ChatGPT, Perplexity og Google AI Overviews refererer til innholdet ditt. Få innsikt i RAG-siteringer og overvåking av AI-svar.
Lær hva RAG (Retrieval-Augmented Generation) er i AI-søk. Oppdag hvordan RAG forbedrer nøyaktighet, reduserer hallusinasjoner og driver ChatGPT, Perplexity og G...
Lær hvordan RAG kombinerer LLM-er med eksterne datakilder for å generere nøyaktige AI-svar. Forstå femstegsprosessen, komponentene og hvorfor det er viktig for ...

Oppdag hvordan Retrieval-Augmented Generation forvandler AI-sitater, muliggjør nøyaktig kildehenvisning og forankrede svar på tvers av ChatGPT, Perplexity og Go...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.