Dowiedz się, jak działają AI crawlers takie jak GPTBot i ClaudeBot, czym różnią się od tradycyjnych crawlerów wyszukiwarek oraz jak zoptymalizować swoją stronę pod kątem widoczności w AI search.
Opublikowano Jan 3, 2026.Ostatnia modyfikacja Jan 3, 2026 o 3:24 am
AI crawlers to zautomatyzowane programy zaprojektowane do systematycznego przeszukiwania internetu i zbierania danych ze stron internetowych, specjalnie w celu trenowania i ulepszania modeli sztucznej inteligencji. W przeciwieństwie do tradycyjnych crawlerów wyszukiwarek, takich jak Googlebot, które indeksują treści na potrzeby wyników wyszukiwania, AI crawlers zbierają surowe dane z sieci, aby zasilić duże modele językowe (LLMs) takie jak ChatGPT, Claude i inne systemy AI. Te boty działają nieprzerwanie na milionach stron, pobierając strony, analizując treści i wyodrębniając informacje, które pomagają platformom AI zrozumieć wzorce językowe, fakty i różnorodne style pisania. Najwięksi gracze w tej dziedzinie to GPTBot od OpenAI, ClaudeBot od Anthropic, Meta-ExternalAgent od Meta, Amazonbot od Amazon oraz PerplexityBot od Perplexity.ai, z których każdy obsługuje potrzeby treningowe i operacyjne własnych platform AI. Zrozumienie działania tych crawlerów stało się kluczowe dla właścicieli stron i twórców treści, ponieważ widoczność w AI bezpośrednio wpływa na to, jak Twoja marka pojawia się w wynikach wyszukiwania i rekomendacjach opartych na sztucznej inteligencji.
Wzrost popularności AI Crawlers
Krajobraz crawlownia stron internetowych przeszedł w ostatnim roku radykalną transformację: AI crawlers odnotowały eksplozję wzrostu, podczas gdy tradycyjne crawlers wyszukiwarek utrzymują stabilne wzorce. Między majem 2024 a majem 2025 całkowity ruch crawlerów wzrósł o 18%, ale rozkład zmienił się znacząco — GPTBot zanotował wzrost o 305% w liczbie żądań, podczas gdy inne crawlers, jak ClaudeBot, spadły o 46%, a Bytespider aż o 85%. To przetasowanie odzwierciedla rosnącą konkurencję między firmami AI o pozyskanie danych treningowych i ulepszanie modeli. Oto szczegółowe zestawienie najważniejszych crawlerów i ich obecnej pozycji rynkowej:
Dane pokazują, że choć Googlebot utrzymuje dominację z 4,5 miliarda żądań miesięcznie, AI crawlers łącznie stanowią około 28% wolumenu Googlebota, co czyni je znaczącą siłą w ruchu internetowym. Eksplozja PerplexityBota (wzrost o 157 490%) pokazuje, jak szybko nowe platformy AI skalują własne operacje crawlownia, podczas gdy spadki niektórych większych AI crawlerów sugerują konsolidację rynku wokół najbardziej skutecznych platform AI.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
GPTBot to crawler sieciowy OpenAI, zaprojektowany specjalnie do zbierania danych na potrzeby treningu i ulepszania ChatGPT oraz innych modeli tej firmy. Rozpoczynając jako stosunkowo mały gracz z udziałem 5% rynku w maju 2024, GPTBot stał się dominującym AI crawlerem, odpowiadając za 30% całego ruchu AI crawlerów do maja 2025 — imponujący wzrost o 305% w liczbie żądań. Ten gwałtowny wzrost odzwierciedla agresywną strategię OpenAI, by ChatGPT miał dostęp do świeżych, różnorodnych treści internetowych zarówno do treningu modelu, jak i funkcji wyszukiwania w czasie rzeczywistym (ChatGPT Search). GPTBot stosuje odmienny wzorzec crawlownia — priorytetowo pobiera treści HTML (57,70% pobrań), pobiera także pliki JavaScript i obrazy, choć nie wykonuje JavaScript do renderowania treści dynamicznych. Crawler często napotyka błędy 404 (34,82% żądań), co sugeruje, że może podążać za nieaktualnymi linkami lub próbować uzyskać dostęp do zasobów, które już nie istnieją. Dla właścicieli stron dominacja GPTBota oznacza, że zapewnienie dostępności treści dla tego crawlera stało się kluczowe, by być widocznym w wyszukiwarce ChatGPT i mieć szansę na włączenie do przyszłych iteracji treningowych modelu.
ClaudeBot i podejście Anthropic
ClaudeBot, opracowany przez Anthropic, jest głównym crawlerem służącym do trenowania i aktualizacji asystenta Claude AI oraz wspierania funkcji wyszukiwania i uziemiania odpowiedzi Claude’a. Będąc drugim co do wielkości AI crawlerem z 27% udziałem w rynku w maju 2024, ClaudeBot odnotował spadek do 21% udziału w maju 2025, a liczba żądań spadła o 46% rok do roku. Ten spadek niekoniecznie oznacza problem ze strategią Anthropic — raczej odzwierciedla rynkowy zwrot w stronę dominacji OpenAI i pojawienia się nowych konkurentów, jak Meta-ExternalAgent. ClaudeBot zachowuje się podobnie do GPTBota, priorytetowo pobiera treści HTML, ale większy procent żądań poświęca na obrazy (35,17% pobrań), co sugeruje, że Anthropic może trenować Claude’a do lepszego rozumienia treści wizualnych obok tekstu. Podobnie jak inne AI crawlers, ClaudeBot nie renderuje JavaScriptu, co oznacza, że widzi wyłącznie surowy HTML strony bez dynamicznie ładowanych treści. Dla twórców treści utrzymanie widoczności dla ClaudeBota wciąż jest istotne, by Claude mógł uzyskać dostęp i cytować Twoje materiały, zwłaszcza gdy Anthropic rozwija funkcje wyszukiwania i wnioskowania Claude’a.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Inne ważne AI Crawlers
Poza GPTBotem i ClaudeBotem, kilka innych istotnych AI crawlerów aktywnie zbiera dane z sieci na potrzeby własnych platform:
Meta-ExternalAgent (Meta): Crawler Meta wszedł dynamicznie do czołówki, zdobywając 19% udziału w rynku do maja 2025 jako nowy uczestnik. Bot zbiera dane dla inicjatyw AI Meta, w tym potencjalnie dla treningu Meta AI oraz integracji z funkcjami AI na Instagramie i Facebooku. Szybki wzrost Meta sugeruje poważne zaangażowanie firmy w AI search i rekomendacje.
PerplexityBot (Perplexity.ai): Mimo tylko 0,2% udziału rynkowego, PerplexityBot odnotował najbardziej spektakularny wzrost — 157 490% rok do roku. Odzwierciedla to szybkie skalowanie Perplexity jako silnika odpowiedzi AI, który opiera się na wyszukiwaniu w sieci w czasie rzeczywistym. Dla stron internetowych wizyty PerplexityBota to bezpośrednia szansa na cytowanie w odpowiedziach generowanych przez AI Perplexity.
Amazonbot (Amazon): Crawler Amazonu spadł z 21% do 11% udziału rynkowego, a liczba żądań spadła o 35% rok do roku. Amazonbot zbiera dane na potrzeby wyszukiwania i zastosowań AI Amazonu, choć spadający udział sugeruje, że firma zmienia strategie AI lub konsoliduje operacje crawlownia.
Applebot (Apple): Crawler Apple odnotował 26% spadek liczby żądań — z 1,9% do 1,2% udziału. Applebot obsługuje głównie Siri i wyszukiwanie Spotlight, ale może też wspierać rozwijające się inicjatywy AI Apple. W przeciwieństwie do większości AI crawlerów, Applebot potrafi renderować JavaScript, co daje mu możliwości podobne do Googlebota.
Czym AI Crawlers różnią się od Googlebota
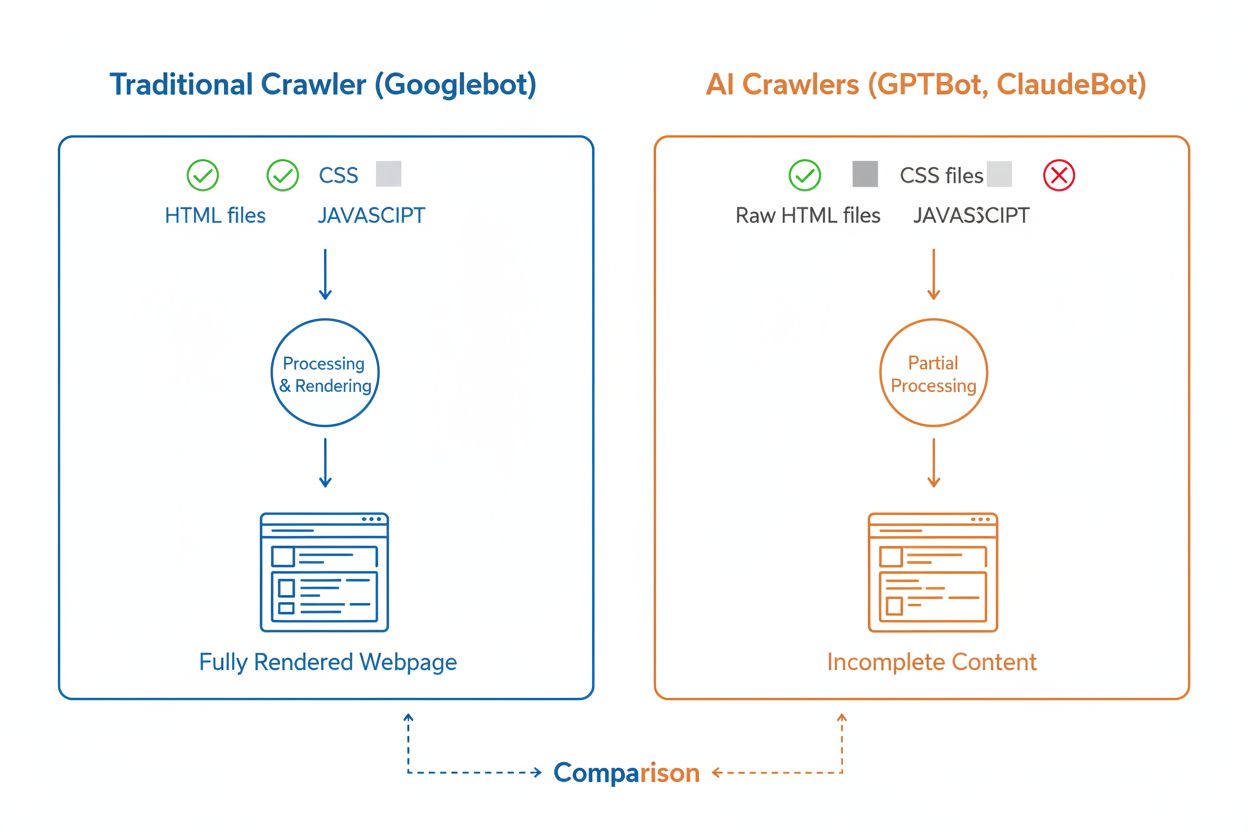
Choć AI crawlers i tradycyjne crawlers wyszukiwarek, takie jak Googlebot, systematycznie przeszukują sieć, ich możliwości techniczne i zachowania różnią się znacząco, co bezpośrednio wpływa na to, jak Twoje treści są odkrywane i rozumiane. Najważniejsza różnica to renderowanie JavaScriptu: Googlebot potrafi wykonać JavaScript po pobraniu strony, dzięki czemu widzi treści ładowane dynamicznie, podczas gdy większość AI crawlerów (GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider) odczytuje wyłącznie surowy HTML i ignoruje treści zależne od JavaScriptu. Oznacza to, że jeśli Twoja strona polega na renderowaniu po stronie klienta, AI crawlers zobaczą niepełną wersję Twoich stron. Dodatkowo, AI crawlers wykazują mniej przewidywalne wzorce crawlownia niż systematyczny Googlebot — poświęcają 34,82% żądań na strony 404 i 14,36% na przekierowania, podczas gdy Googlebot tylko 8,22% na 404 i 1,49% na przekierowania. Częstotliwość crawlownia także się różni: Googlebot odwiedza strony, opierając się na zaawansowanym systemie crawl budget, a AI crawlers wydają się crawlować częściej, lecz mniej systematycznie — badania pokazują, że AI crawlers potrafią odwiedzać strony ponad 100 razy częściej niż Google w niektórych przypadkach. Oznacza to, że tradycyjne strategie SEO mogą nie wystarczyć dla crawlability przez AI, wymagając osobnego podejścia skoncentrowanego na SSR i czystych strukturach URL.
Ograniczenia renderowania JavaScriptu
Jednym z najważniejszych wyzwań technicznych dla AI crawlerów jest ich niezdolność do renderowania JavaScriptu — wynika to z kosztowności obliczeniowej wykonywania JavaScriptu na skalę wymaganą do trenowania dużych modeli językowych. Kiedy crawler pobiera Twoją stronę, otrzymuje początkową odpowiedź HTML, ale wszelkie treści ładowane lub modyfikowane przez JavaScript — takie jak szczegóły produktów, ceny, opinie użytkowników czy elementy nawigacji — pozostają dla AI crawlerów niewidoczne. Stwarza to poważny problem dla nowoczesnych stron, które mocno polegają na frameworkach renderowania po stronie klienta, jak React, Vue czy Angular, bez renderowania po stronie serwera (SSR) lub generowania statycznych stron (SSG). Przykładowo, sklep internetowy ładujący dane o produktach przez JavaScript będzie dla AI crawlerów pustą stroną bez szczegółów produktów, co uniemożliwia systemom AI zrozumienie czy cytowanie tych treści. Rozwiązaniem jest zapewnienie, by wszystkie kluczowe treści były podawane w początkowej odpowiedzi HTML dzięki renderowaniu po stronie serwera, które generuje pełny HTML na serwerze przed wysłaniem do przeglądarki. Takie podejście gwarantuje, że zarówno ludzie, jak i AI crawlers otrzymują tę samą, bogatą w treści stronę. Strony korzystające z nowoczesnych frameworków, jak Next.js z SSR, generatory statyczne jak Hugo czy Gatsby, lub tradycyjne platformy jak WordPress, są naturalnie przyjazne dla AI crawlerów, zaś te polegające wyłącznie na renderowaniu po stronie klienta napotykają poważne wyzwania z widocznością w AI search.
Częstotliwość i wzorce crawlownia
AI crawlers wykazują charakterystyczne wzorce częstotliwości crawlownia, które wyraźnie różnią się od zachowań Googlebota i mają istotne konsekwencje dla szybkości przechwytywania treści przez systemy AI. Badania wskazują, że AI crawlers, jak ChatGPT i Perplexity, często odwiedzają strony częściej niż Google w krótkim okresie po publikacji treści — w niektórych przypadkach 8 razy częściej niż Googlebot w ciągu kilku pierwszych dni. Sugeruje to, że platformy AI priorytetowo traktują szybkie odkrywanie i indeksowanie nowych treści, by ich modele i funkcje wyszukiwania miały dostęp do najnowszych informacji. Po tej intensywnej, początkowej fazie crawlownia AI crawlers mogą nie wracać, jeśli treść nie spełnia standardów jakości — dlatego pierwsze wrażenie jest kluczowe. W przeciwieństwie do Googlebota, który wraca na strony regularnie na podstawie częstotliwości aktualizacji i znaczenia, AI crawlers zdają się podejmować decyzję, czy warto wrócić na daną stronę. Oznacza to, że jeśli AI crawler odwiedzi Twoją stronę i napotka słabą treść, błędy techniczne lub złe sygnały UX, może minąć dużo czasu, zanim wróci — a może nie wrócić wcale. Wniosek dla twórców treści: nie można liczyć na drugą szansę optymalizacji pod AI crawlers jak w przypadku tradycyjnych wyszukiwarek, dlatego kontrola jakości przed publikacją jest niezbędna.
robots.txt i kontrola AI crawlerów
Właściciele stron mogą użyć pliku robots.txt do określenia preferencji dotyczących dostępu AI crawlerów, choć skuteczność i egzekwowanie tych reguł różnią się znacznie w zależności od crawlera. Według najnowszych danych około 14% z 10 000 największych stron wdrożyło konkretne reguły allow/disallow dla AI botów w robots.txt. GPTBot jest najczęściej blokowanym crawlerem — 312 domen (250 całkowicie, 62 częściowo) wyraźnie go blokuje, choć jest także najczęściej wyraźnie dopuszczanym crawlerem — 61 domen wyraźnie go pozwala. Inne często blokowane crawlers to CCBot (Common Crawl) i Google-Extended (token treningowy Google do AI). Problem z robots.txt polega na tym, że stosowanie się do niego jest dobrowolne — crawlers honorują te reguły tylko jeśli ich operatorzy zdecydują się wdrożyć taką funkcjonalność, a niektóre nowsze lub mniej transparentne crawlers mogą je całkowicie ignorować. Dodatkowo, tokeny robots.txt, takie jak „Google-Extended”, nie odpowiadają bezpośrednio user-agentom w żądaniach HTTP — sygnalizują raczej cel crawlownia, więc nie zawsze możesz zweryfikować zgodność na podstawie logów serwera. Dla mocniejszej kontroli właściciele stron coraz częściej korzystają z reguł firewalla i Web Application Firewall (WAF), które potrafią aktywnie blokować określone user-agenty crawlerów, dając pewniejszą kontrolę niż sam robots.txt. To przejście na aktywne mechanizmy blokowania odzwierciedla rosnące obawy o prawa do treści i potrzebę egzekwowalnej kontroli dostępu crawlerów AI.
Monitorowanie aktywności AI crawlerów
Śledzenie aktywności AI crawlerów na stronie jest niezbędne, by zrozumieć swoją widoczność w AI search, lecz stanowi wyzwanie w porównaniu z monitoringiem tradycyjnych crawlerów wyszukiwarek. Tradycyjne narzędzia analityczne, jak Google Analytics, polegają na śledzeniu przez JavaScript, którego AI crawlers nie wykonują — oznacza to, że te narzędzia nie pozwalają zobaczyć wizyt AI botów. Podobnie, tracking pikselowy nie działa, bo większość AI crawlerów przetwarza wyłącznie tekst i ignoruje obrazy. Jedynym niezawodnym sposobem śledzenia AI crawlerów jest monitoring po stronie serwera — analiza nagłówków żądań HTTP i logów serwera, by identyfikować user-agenty crawlerów przed wysłaniem strony. Wymaga to albo ręcznej analizy logów, albo wyspecjalizowanych narzędzi zaprojektowanych specjalnie do identyfikacji i śledzenia ruchu AI crawlerów. Monitoring w czasie rzeczywistym jest szczególnie ważny, bo AI crawlers działają w nieprzewidywalnych cyklach i mogą nie wracać na strony, jeśli napotkają problemy — tygodniowy lub miesięczny audyt crawlownia może nie wychwycić istotnych problemów. Jeśli AI crawler odwiedzi Twoją stronę i napotka błąd techniczny lub słabą jakość treści, możesz nie mieć kolejnej szansy na dobre wrażenie. Wdrożenie rozwiązań 24/7, które natychmiast powiadomią Cię o problemach napotkanych przez AI crawlers — takich jak 404, wolne ładowanie strony czy brak oznaczeń schema — pozwala rozwiązać problemy, zanim wpłyną one na Twoją widoczność w AI search. Takie podejście w czasie rzeczywistym to zasadnicza zmiana względem tradycyjnego monitoringu SEO i odzwierciedla tempo oraz nieprzewidywalność zachowań AI crawlerów.
Optymalizacja pod AI Crawlers
Optymalizacja strony pod AI crawlers wymaga innego podejścia niż tradycyjne SEO, skupiającego się na technicznych czynnikach decydujących o dostępie i zrozumieniu treści przez systemy AI. Najważniejsze jest renderowanie po stronie serwera: zadbaj, by wszystkie kluczowe treści — nagłówki, treść, metadane, dane strukturalne — były zawarte w początkowym HTML, a nie ładowane dynamicznie przez JavaScript. Dotyczy to strony głównej, kluczowych landing pages i wszelkich treści, które chcesz, by były cytowane lub referowane przez AI. Po drugie, zaimplementuj oznaczenia danych strukturalnych (Schema.org) na stronach o największym znaczeniu, w tym schema artykułów dla blogów, schema produktów dla e-commerce i schema autora dla budowania wiarygodności. AI crawlers korzystają z danych strukturalnych, by szybko zrozumieć hierarchię i kontekst treści, co znacznie ułatwia im analizę i cytowanie informacji. Po trzecie, dbaj o wysoką jakość treści na wszystkich stronach — AI crawlers wydają się szybko oceniać, czy treść warto zindeksować i cytować. Oznacza to, że treści powinny być oryginalne, dobrze zbadane, dokładne i realnie wartościowe dla czytelników. Po czwarte, monitoruj i optymalizuj Core Web Vitals i ogólną wydajność strony — wolno ładujące się strony to zły sygnał UX i mogą zniechęcić AI crawlers do powrotu. Na koniec, utrzymuj czystą i spójną strukturę URL, aktualizuj mapę XML strony i skonfiguruj poprawnie plik robots.txt, by kierować crawlers do najważniejszych treści. Takie optymalizacje techniczne tworzą fundament, dzięki któremu Twoje treści stają się łatwe do znalezienia, zrozumienia i cytowania przez systemy AI.
Przyszłość AI Crawlers
Krajobraz AI crawlerów będzie się szybko zmieniał wraz z nasilającą się konkurencją między firmami AI i dojrzewaniem technologii. Jednym z wyraźnych trendów jest konsolidacja udziałów wokół najskuteczniejszych platform — GPTBot od OpenAI wyrasta na dominującą siłę, podczas gdy nowi gracze jak Meta-ExternalAgent szybko się skalują, co sugeruje, że rynek ustabilizuje się wokół kilku głównych graczy. Wraz z rozwojem AI crawlerów możemy spodziewać się poprawy ich możliwości technicznych, przede wszystkim w zakresie renderowania JavaScriptu i efektywniejszych wzorców crawlownia, które ograniczą ilość żądań na strony 404 i przestarzałe treści. Branża zmierza też w stronę bardziej ustandaryzowanych protokołów komunikacyjnych, takich jak powstająca specyfikacja llms.txt, która pozwala stronom wyraźnie komunikować strukturę treści i preferencje crawlownia systemom AI. Ponadto, mechanizmy egzekwowania kontroli dostępu do AI crawlerów stają się coraz bardziej zaawansowane — platformy takie jak Cloudflare oferują już automatyczne blokowanie botów trenujących AI domyślnie, dając właścicielom stron bardziej szczegółową kontrolę nad własnymi treściami. Dla twórców treści i właścicieli stron oznacza to konieczność ciągłego monitorowania aktywności AI crawlerów, utrzymywania infrastruktury technicznej zoptymalizowanej pod dostępność dla AI i adaptacji strategii treści do rzeczywistości, że systemy AI stanowią dziś istotną część ruchu na stronie i kluczowy kanał widoczności marki. Przyszłość należy do tych, którzy zrozumieją i zoptymalizują się pod nowe ekosystemy crawlerów.
Najczęściej zadawane pytania
Czym jest AI crawler i czym różni się od crawlera wyszukiwarki?
AI crawlers to zautomatyzowane programy, które zbierają dane z internetu specjalnie w celu trenowania i ulepszania modeli sztucznej inteligencji, takich jak ChatGPT i Claude. W przeciwieństwie do tradycyjnych crawlerów wyszukiwarek, takich jak Googlebot, które indeksują treści do wyników wyszukiwania, AI crawlers zbierają surowe dane z sieci, aby zasilić duże modele językowe. Oba typy crawlerów systematycznie przeszukują internet, lecz służą różnym celom i mają odmienne możliwości techniczne.
Dlaczego AI crawlers muszą mieć dostęp do mojej strony?
AI crawlers uzyskują dostęp do Twojej strony, aby zbierać dane do trenowania modeli AI, ulepszania funkcji wyszukiwania i uwiarygadniania odpowiedzi AI aktualnymi informacjami. Gdy systemy AI, takie jak ChatGPT czy Perplexity, odpowiadają na pytania użytkowników, często muszą pobrać Twoje treści w czasie rzeczywistym, by dostarczyć dokładne, cytowane informacje. Pozwolenie AI crawlers na dostęp do strony zwiększa szansę, że Twoja marka zostanie wspomniana i zacytowana w odpowiedziach generowanych przez AI.
Czy mogę zablokować AI crawlers dostęp do mojej strony?
Tak, możesz użyć pliku robots.txt, aby zabronić dostępu wybranym AI crawlers, określając ich nazwy user-agentów. Jednak stosowanie się do robots.txt jest dobrowolne i nie wszystkie crawlers respektują te zasady. Aby zapewnić skuteczniejszą ochronę, możesz użyć reguł firewalla i Web Application Firewalls (WAF), aby aktywnie blokować wybrane user-agenty crawlerów. Daje to większą kontrolę nad tym, które AI crawlers mają dostęp do Twoich treści.
Czy AI crawlers renderują JavaScript tak jak Google?
Nie, większość AI crawlers (GPTBot, ClaudeBot, Meta-ExternalAgent) nie wykonuje JavaScript. Odczytują tylko surowy HTML Twoich stron, więc wszelkie treści ładowane dynamicznie przez JavaScript będą dla nich niewidoczne. Dlatego renderowanie po stronie serwera jest kluczowe dla crawlability przez AI. Jeśli Twoja strona opiera się na renderowaniu po stronie klienta, AI crawlers zobaczą niekompletną wersję Twoich stron.
Jak często AI crawlers odwiedzają strony internetowe?
AI crawlers odwiedzają strony internetowe częściej niż tradycyjne wyszukiwarki w krótkim okresie po publikacji treści. Badania pokazują, że mogą odwiedzać strony 8-100 razy częściej niż Google w ciągu kilku pierwszych dni. Jednak jeśli treść nie spełnia standardów jakości, mogą nie wrócić. To sprawia, że pierwsze wrażenie jest kluczowe — możesz nie otrzymać drugiej szansy na optymalizację pod AI crawlers.
Jak najlepiej zoptymalizować stronę pod AI crawlers?
Najważniejsze optymalizacje to: (1) Używaj renderowania po stronie serwera, aby kluczowe treści były w początkowym HTML, (2) Dodaj oznaczenia danych strukturalnych (Schema), by ułatwić AI zrozumienie Twoich treści, (3) Dbaj o wysoką jakość i aktualność treści, (4) Monitoruj Core Web Vitals dla dobrej obsługi użytkownika oraz (5) Utrzymuj przejrzystą strukturę URL i aktualizuj mapę strony. Te techniczne optymalizacje tworzą fundament, dzięki któremu Twoje treści są odnajdywane i cytowane przez systemy AI.
Który AI crawler jest najważniejszy dla mojej strony?
GPTBot od OpenAI jest obecnie dominującym AI crawlerem, odpowiadając za 30% całego ruchu AI crawlerów i notując 305% wzrost rok do roku. Jednak warto zoptymalizować stronę także pod inne główne crawlers, w tym ClaudeBot (Anthropic), Meta-ExternalAgent (Meta), PerplexityBot (Perplexity) i inne. Różne platformy AI mają różnych użytkowników, więc widoczność wśród wielu crawlerów maksymalizuje obecność Twojej marki w AI search.
Jak śledzić aktywność AI crawlerów na mojej stronie?
Tradycyjne narzędzia analityczne, takie jak Google Analytics, nie rejestrują aktywności AI crawlerów, ponieważ opierają się na śledzeniu przez JavaScript. Zamiast tego potrzebujesz monitorowania po stronie serwera, które analizuje nagłówki żądań HTTP i logi serwera, by identyfikować user-agenty crawlerów. Wyspecjalizowane narzędzia do śledzenia AI crawlerów dają wgląd w czasie rzeczywistym, które strony są crawlowane, jak często i czy crawlers napotykają problemy techniczne.
Monitoruj widoczność swojej marki w AI Search
Śledź, jak AI crawlers takie jak GPTBot i ClaudeBot uzyskują dostęp do Twoich treści i cytują je. Uzyskaj wgląd w czasie rzeczywistym w swoją widoczność w AI search z AmICited.
Jak zidentyfikować crawlery AI w logach serwera: Kompletny przewodnik po wykrywaniu
Dowiedz się, jak identyfikować i monitorować crawlery AI takie jak GPTBot, PerplexityBot i ClaudeBot w logach serwera. Poznaj ciągi user-agent, metody weryfikac...
Jakim Crawlerom AI Pozwolić na Dostęp? Kompletny Przewodnik na 2025
Dowiedz się, którym crawlerom AI pozwolić, a które zablokować w swoim pliku robots.txt. Kompleksowy przewodnik obejmujący GPTBot, ClaudeBot, PerplexityBot oraz ...
Wpływ AI Crawlerów na Zasoby Serwera: Czego Się Spodziewać
Dowiedz się, jak AI crawlery wpływają na zasoby serwera, przepustowość i wydajność. Poznaj prawdziwe statystyki, strategie łagodzenia skutków oraz rozwiązania i...
9 min czytania
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.