
Cytowania z Wikipedii jako dane treningowe AI: Efekt fali
Dowiedz się, jak cytowania z Wikipedii kształtują dane treningowe AI i tworzą efekt fali wśród LLM. Sprawdź, dlaczego obecność Twojej marki w Wikipedii ma znacz...
7 min czytania

Dowiedz się, skąd ChatGPT czerpie dane treningowe, jak cytuje źródła, o datach granicznych wiedzy oraz dlaczego monitorowanie cytowań AI jest ważne dla Twojej marki.
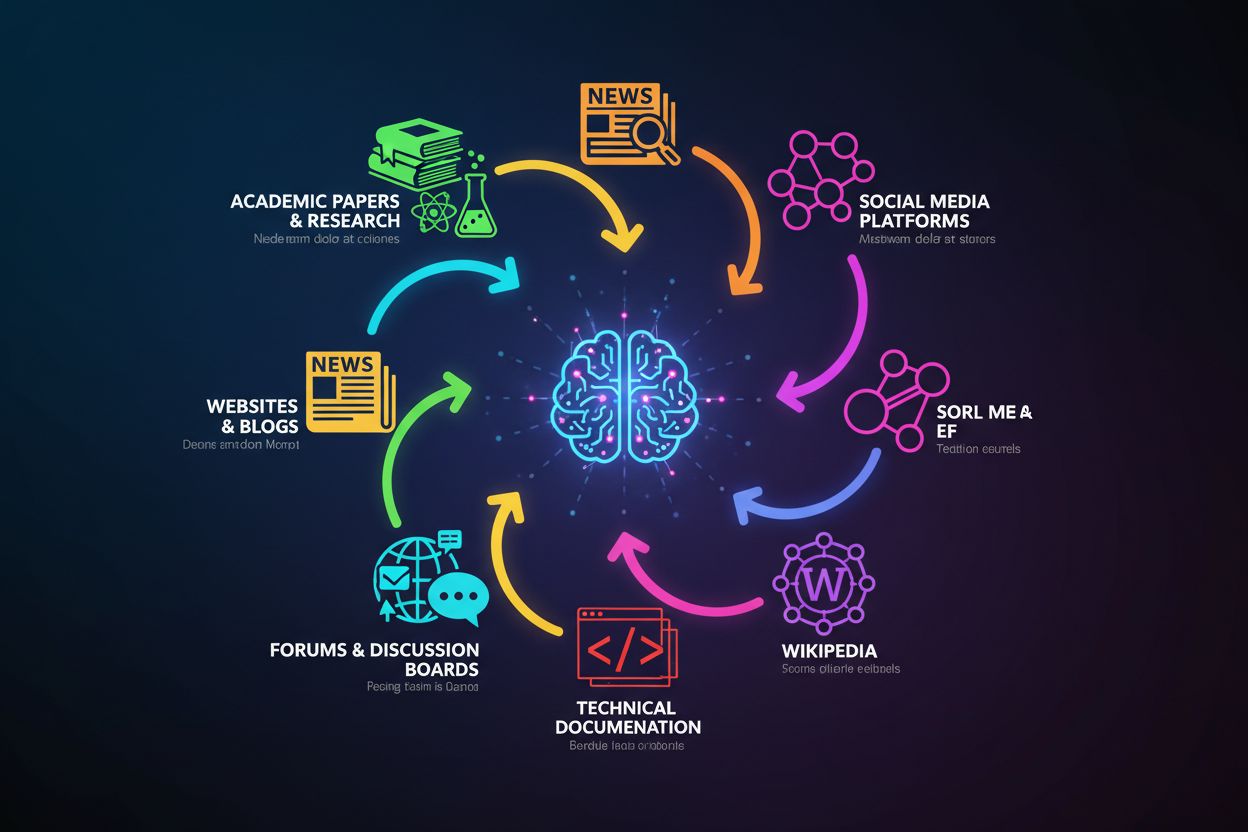
Baza wiedzy ChatGPT powstała z różnorodnej kolekcji publicznie dostępnych danych internetowych, połączonych z licencjonowanymi zbiorami danych oraz doskonaleniem przez ludzką ocenę. Model był trenowany na trzech głównych źródłach: publicznie dostępnych danych internetowych (strony internetowe, artykuły i treści online), licencjonowanych zbiorach danych (w tym książki i publikacje naukowe) oraz informacji zwrotnej od ludzi, którzy pomagali doskonalić odpowiedzi. Te dane treningowe obejmują niezwykle szeroką gamę źródeł, w tym portale informacyjne, czasopisma naukowe, książki, dokumentację techniczną, fora takie jak Reddit i Stack Overflow, artykuły Wikipedii oraz niezliczone inne publicznie dostępne strony www. Ogromna liczba i różnorodność tych źródeł—obejmujących wiele języków, dziedzin i perspektyw—tworzy kompleksową bazę wiedzy, która pozwala ChatGPT omawiać tematy od fizyki kwantowej, przez historię średniowiecza, po współczesną popkulturę. Należy jednak pamiętać, że ChatGPT nie ma dostępu do informacji w czasie rzeczywistym ani do baz danych na wyłączność; może czerpać wyłącznie z tego, co było dostępne w okresie treningowym.
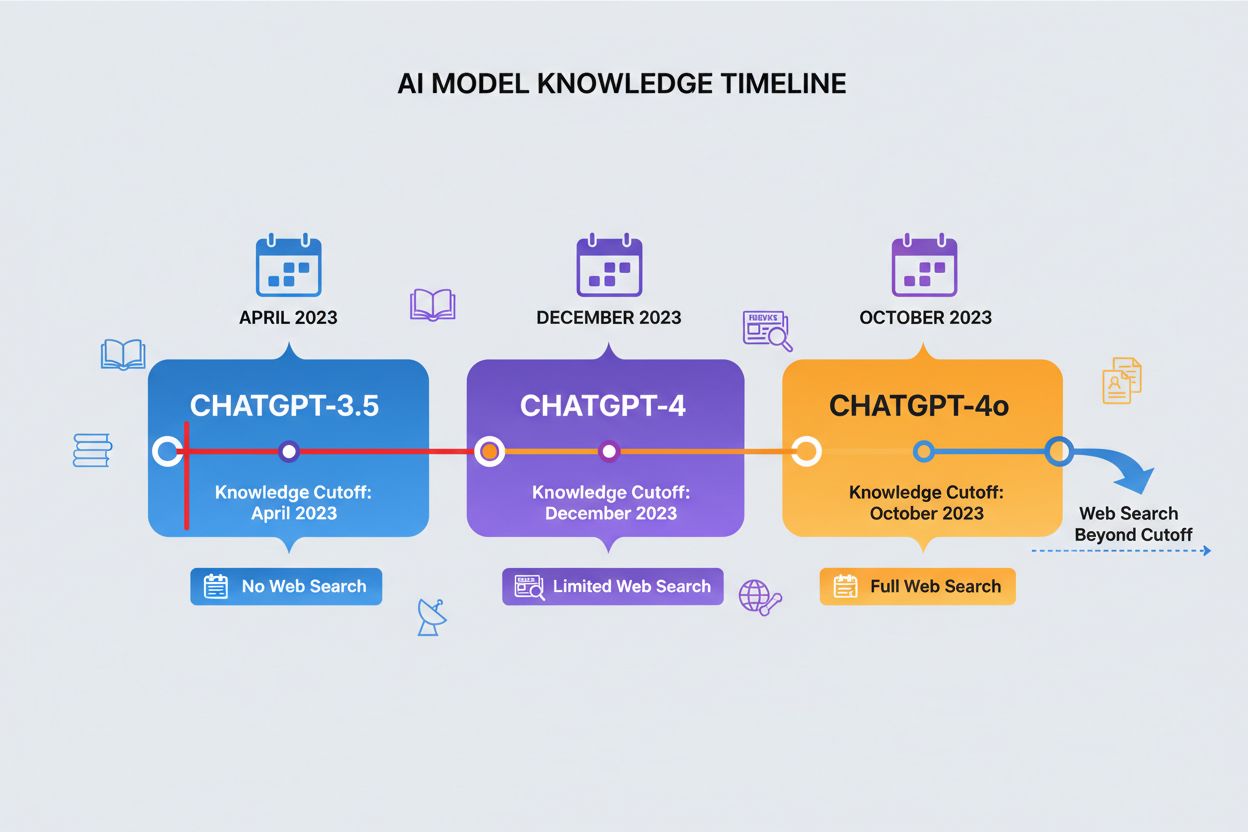
Data graniczna wiedzy oznacza moment, po którym ChatGPT nie posiada już nowych danych treningowych, wyznaczając twardą granicę dla dostępnych informacji. Różne wersje ChatGPT mają różne daty graniczne: ChatGPT-4 był trenowany na danych do grudnia 2023 roku, natomiast ChatGPT-4o (wersja zoptymalizowana) ma granicę na październik 2023 roku. Te daty znacząco wpływają na dokładność i aktualność odpowiedzi, zwłaszcza w przypadku najnowszych wydarzeń, świeżych badań czy bieżących statystyk, które mogły się zmienić po zebraniu danych treningowych. Niektóre nowsze wersje ChatGPT potrafią wykonywać wyszukiwania internetowe, aby pobierać aktualne informacje poza swoją datą graniczną, choć ta funkcja nie jest dostępna we wszystkich wersjach i kontekstach. Znajomość daty granicznej wiedzy Twojego modelu jest kluczowa dla użytkowników potrzebujących bieżących informacji, gdyż ChatGPT nie jest w stanie udzielić dokładnych odpowiedzi na pytania dotyczące wydarzeń po zakończeniu okresu treningowego. To ograniczenie jest jednym z najważniejszych czynników przy ocenie wiarygodności ChatGPT w przypadku zapytań wymagających aktualnych danych.
| Wersja ChatGPT | Data graniczna wiedzy | Możliwość wyszukiwania w sieci | Główne zastosowanie |
|---|---|---|---|
| ChatGPT-4 | grudzień 2023 | ograniczona | Wiedza ogólna, analiza, wnioskowanie |
| ChatGPT-4o | październik 2023 | dostępna | Zoptymalizowana wydajność, zadania multimodalne |
| ChatGPT-3.5 | kwiecień 2023 | brak | Podstawowe zapytania, oszczędna opcja |
| ChatGPT z przeglądaniem | na bieżąco | tak | Wydarzenia bieżące, nowe badania |
W przeciwieństwie do wyszukiwarek, które pobierają konkretne dokumenty czy strony internetowe w odpowiedzi na zapytania, ChatGPT generuje odpowiedzi poprzez syntezę wzorców poznanych podczas treningu—co jest zasadniczo innym procesem. Gdy zadasz pytanie ChatGPT, nie przeszukuje on bazy danych czy indeksu, lecz korzysta ze statystycznych wzorców ze swoich danych treningowych, by przewidzieć najbardziej prawdopodobną sekwencję słów stanowiącą pomocną odpowiedź. To podejście generatywne oznacza, że ChatGPT łączy informacje z wielu źródeł zawartych w danych treningowych, tworząc nowe odpowiedzi, które mogą nie występować dosłownie w żadnym z jego materiałów źródłowych. Model uczy się relacji między pojęciami, faktami i ideami, a następnie rekonstruuje tę wiedzę w odpowiedzi na konkretne zapytanie. Ma to jednak poważną wadę: gdy model nie jest pewny informacji lub gdy wzorce w danych są sprzeczne lub rzadkie, może wygenerować przekonująco brzmiące, lecz fałszywe informacje, co określa się jako “halucynacje”. Nowsze wersje ChatGPT z funkcją wyszukiwania internetowego mogą wspomagać ten proces poprzez pobieranie aktualnych informacji z sieci, jednak funkcja ta wymaga ręcznego włączenia i nie jest dostępna we wszystkich platformach.
Dane treningowe ChatGPT pochodzą z kilku głównych kategorii źródeł, z których każda wnosi do bazy wiedzy inną wartość:
Znaczenie tych różnorodnych źródeł polega na ich komplementarnych mocnych stronach: artykuły naukowe dają rzetelność, wiadomości—aktualność, książki—głębię, a fora—praktykę. Jednak jakość źródeł jest bardzo zróżnicowana—recenzowana praca naukowa ma większą wagę niż przypadkowy wpis na blogu, a proces treningu ChatGPT nie rozróżnia ich wprost. Oznacza to, że wiedza ChatGPT odzwierciedla zarówno wysokiej jakości autorytatywne źródła, jak i te niższej jakości lub potencjalnie mylące, dlatego weryfikacja jest niezbędna przy wykorzystaniu modelu do ważnych decyzji.
Po wstępnym treningu na ogromnych zbiorach tekstu, OpenAI zastosowało technikę zwaną uczeniem przez wzmocnienie z informacją zwrotną od człowieka (RLHF) w celu udoskonalenia odpowiedzi ChatGPT. W tym procesie ludzcy trenerzy oceniali odpowiedzi modelu i przekazywali opinię, pomagając systemowi nauczyć się, które odpowiedzi są bardziej pomocne, dokładne i zgodne z wartościami ludzi. Trenerzy nie sprawdzali każdego twierdzenia pod kątem prawdziwości; oceniali raczej ogólną jakość, przydatność i bezpieczeństwo odpowiedzi, co pośrednio wpłynęło na to, jak model priorytetyzuje i prezentuje informacje. Proces RLHF mocno wpływa na to, które informacje są eksponowane w odpowiedziach i jak przedstawiane są różne tematy, wprowadzając element ludzkiego osądu do modelu, który byłby czysto statystyczny. Jednak ten proces ma swoje ograniczenia: trenerzy mają własne uprzedzenia, luki w wiedzy i ograniczenia, i nie są w stanie ocenić dokładności wszystkich twierdzeń ze wszystkich dziedzin. Ponadto proces ten jest kosztowny i możliwy do zastosowania tylko do ułamka potencjalnych odpowiedzi modelu, przez co znaczna część zachowania ChatGPT nadal odzwierciedla surowe wzorce z danych treningowych, a nie świadomą kurację człowieka.
Cytowanie ChatGPT jest istotne dla integralności naukowej i przejrzystości, pozwalając odbiorcom zrozumieć, skąd pochodzą informacje i umożliwiając replikację lub weryfikację Twoich ustaleń. Format cytowania zależy od wymaganego stylu, ale oto najczęściej stosowane podejścia:
Przykład w stylu MLA:
OpenAI. "ChatGPT." Dostęp [Data], https://chat.openai.com.
W stylu MLA cytujesz ChatGPT jako stronę internetową, podając datę dostępu, ponieważ treści są dynamiczne i mogą się zmieniać. Cytując konkretną odpowiedź, warto podać datę dostępu i najlepiej również użyte zapytanie (prompt).
Przykład w stylu APA:
OpenAI. (2024). ChatGPT (Wersja 4) [Model językowy].
Pobrano z https://chat.openai.com
APA traktuje ChatGPT jako narzędzie programistyczne lub aplikację, uwzględniając numer wersji i datę pobrania. Niektóre wytyczne APA zalecają podanie konkretnego promptu w cytowaniu lub w przypisie.
Kiedy cytować ChatGPT: Należy cytować narzędzie za każdym razem, gdy wykorzystujesz jego wyniki w pracy naukowej, raportach zawodowych lub w każdym kontekście, w którym wymagana jest atrybucja. Udokumentuj dokładny prompt, którego użyłeś, datę dostępu oraz najlepiej wersję ChatGPT, ponieważ te szczegóły wpływają na powtarzalność. Kluczowa różnica między cytowaniem ChatGPT a tradycyjnych źródeł polega na tym, że odpowiedzi ChatGPT są generowane dynamicznie—ten sam prompt może dawać nieco inne wyniki przy różnych okazjach—dlatego samo zapytanie staje się częścią poprawnej praktyki cytowania. Wiele instytucji wciąż wypracowuje własne formalne wytyczne dotyczące cytowań AI, dlatego sprawdź preferowany format w swojej organizacji lub wydawnictwie.
Choć ChatGPT jest niezwykle zaawansowany, ma istotne ograniczenia wpływające na wiarygodność informacji. ChatGPT potrafi z przekonaniem podawać fałszywe informacje—problem znany jako halucynacje—szczególnie przy pytaniach o rzadkie tematy, najnowsze wydarzenia po dacie granicznej wiedzy lub wobec sprzecznych danych treningowych. Dane treningowe modelu zawierają wrodzone uprzedzenia odzwierciedlające perspektywy, demografię i poglądy obecne w źródłach, co może skutkować niezamierzonym faworyzowaniem pewnych punktów widzenia lub zawierać stereotypy. Informacje z danych treningowych ChatGPT szybko się dezaktualizują wraz z upływem czasu, przez co nie nadają się do aktualnych statystyk, najnowszych badań czy dynamicznych sytuacji. Z tych powodów weryfikacja twierdzeń ChatGPT jest niezbędna, szczególnie przy podejmowaniu ważnych decyzji—kluczowe fakty należy sprawdzać w źródłach pierwotnych, najnowszych publikacjach i autorytatywnych bazach danych. Aby zweryfikować informacje ChatGPT, należy konfrontować jego twierdzenia z niezależnymi źródłami, porównywać daty i statystyki z bieżącymi danymi oraz szczególnie sceptycznie podchodzić do konkretnych liczb, nazw czy nowych wydarzeń. Pamiętaj, że ChatGPT nie jest źródłem pierwotnym; to źródło wtórne syntetyzujące informacje z innych źródeł, dlatego w pracy naukowej lub zawodowej należy cytować oryginalne źródła, do których odnosi się ChatGPT, a nie sam model.
Wraz ze wzrostem roli ChatGPT i innych systemów AI w odkrywaniu informacji, monitorowanie, jak te systemy cytują i odnoszą się do Twojej marki lub organizacji, staje się kluczowe. AmICited to platforma do monitorowania odpowiedzi AI zaprojektowana specjalnie do śledzenia, jak ChatGPT, Claude i inne duże modele językowe wspominają, cytują lub odnoszą się do Twojej firmy, produktów czy marki w swoich odpowiedziach. Platforma pomaga zrozumieć, kiedy i jak Twoja marka pojawia się w odpowiedziach generowanych przez AI, zapewniając wgląd w nowy i rosnący kanał odkrywania informacji, który często umyka tradycyjnym narzędziom monitorującym sieć. Ta funkcjonalność jest kluczowa, ponieważ cytowania AI działają inaczej niż tradycyjne cytowania internetowe—są osadzone w odpowiedziach konwersacyjnych, z których codziennie korzystają miliony użytkowników, a większość marek nie ma wglądu w sposób, w jaki są tam prezentowane. Korzystając z AmICited do śledzenia wzmianek i cytowań AI, zyskujesz wgląd w postrzeganie marki w systemach AI, możesz identyfikować nieścisłości lub przestarzałe informacje wymagające korekty oraz dowiedzieć się, jak Twoja marka wypada na tle konkurencji w odpowiedziach generowanych przez AI. W czasach, gdy systemy AI stają się głównym źródłem informacji dla wielu użytkowników, monitorowanie swojej obecności w tych systemach jest równie ważne, co śledzenie wyników wyszukiwania, czyniąc takie narzędzia jak AmICited niezbędnymi dla nowoczesnego zarządzania marką i przejrzystości AI.
ChatGPT został wytrenowany na trzech głównych źródłach: publicznie dostępnych danych internetowych (strony internetowe, artykuły, fora), licencjonowanych zbiorach danych (książki i publikacje naukowe) oraz informacjach zwrotnych od trenerów. Dane treningowe obejmują serwisy informacyjne, czasopisma naukowe, dokumentację techniczną, Wikipedię, Reddit, Stack Overflow i niezliczone inne publicznie dostępne strony internetowe zebrane do daty granicznej wiedzy modelu.
Data graniczna wiedzy to moment, po którym ChatGPT nie posiada już nowych danych treningowych. ChatGPT-4 ma granicę na grudzień 2023 roku, a ChatGPT-4o na październik 2023. To ważne, ponieważ ChatGPT nie jest w stanie podać dokładnych informacji o wydarzeniach, badaniach czy odkryciach, które miały miejsce po zakończeniu okresu treningowego, co czyni go zawodnym przy zapytaniach wymagających aktualnych danych.
ChatGPT nie ma dostępu do informacji w czasie rzeczywistym wyłącznie na podstawie swoich danych treningowych. Jednak nowsze wersje ChatGPT mogą wykonywać wyszukiwania w internecie, aby pobierać aktualne informacje wykraczające poza datę graniczną wiedzy, choć ta funkcja nie jest dostępna we wszystkich wersjach czy kontekstach i wymaga ręcznego włączenia.
W formacie MLA cytuj ChatGPT jako stronę internetową z datą dostępu. W formacie APA traktuj go jak oprogramowanie i podaj numer wersji. Oba formaty wymagają udokumentowania dokładnej komendy (promptu), której użyłeś, daty dostępu oraz, najlepiej, wersji ChatGPT, ponieważ ten sam prompt może generować różne odpowiedzi w różnych okolicznościach.
Nie. ChatGPT może z przekonaniem przedstawiać fałszywe informacje (halucynacje), szczególnie w odniesieniu do mało znanych tematów, najnowszych wydarzeń po dacie granicznej wiedzy lub sprzecznych informacji. Dane treningowe zawierają wrodzone uprzedzenia, a informacje szybko się dezaktualizują. Zawsze weryfikuj ważne twierdzenia w źródłach pierwotnych i autorytatywnych bazach danych.
Dane treningowe ChatGPT nie są aktualizowane na bieżąco. Nowe wersje są wydawane okresowo z aktualizowanymi datami granicznymi wiedzy, ale nie ma ciągłej aktualizacji modelu bazowego. OpenAI udostępnia nowe wersje (np. GPT-4o) z nowszymi danymi treningowymi, ale dokładny harmonogram aktualizacji nie jest publicznie znany.
ChatGPT nie cytuje konkretnych źródeł dla poszczególnych twierdzeń, ponieważ syntetyzuje informacje na podstawie wzorców z danych treningowych, a nie pobiera konkretnych dokumentów. Nie może wskazać dokładnego źródła danej informacji. W pracach naukowych powinieneś zweryfikować twierdzenia ChatGPT i cytować odnalezione oryginalne źródła, a nie samo ChatGPT.
AmICited śledzi, jak ChatGPT, Claude i inne systemy AI wspominają, cytują lub odnoszą się do Twojej marki w swoich odpowiedziach. Zapewnia wgląd w to, jak Twoja firma pojawia się w odpowiedziach generowanych przez AI, pomaga identyfikować nieścisłości i pokazuje, jak Twoja marka wypada na tle konkurencji w systemach AI — co jest niezbędne dla nowoczesnego zarządzania marką w erze AI.
Śledź cytowania ChatGPT i wzmianki AI w czasie rzeczywistym z AmICited. Zrozum, jak systemy AI odnoszą się do Twojej marki i bądź na bieżąco z odkrywaniem informacji napędzanym przez AI.
Dowiedz się, jak cytowania z Wikipedii kształtują dane treningowe AI i tworzą efekt fali wśród LLM. Sprawdź, dlaczego obecność Twojej marki w Wikipedii ma znacz...

Dowiedz się, jak Wikipedia pełni kluczową rolę w danych treningowych AI, jaki ma wpływ na dokładność modeli, jakie są umowy licencyjne i dlaczego firmy AI poleg...
Dowiedz się, dlaczego Reddit dominuje w cytowaniach ChatGPT z udziałem 40,1% wszystkich odpowiedzi AI. Poznaj, jak działają preferencje źródeł AI i co to oznacz...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.