Segmentacja treści dla AI: Optymalne długości fragmentów do cytowań
Dowiedz się, jak strukturyzować treść w optymalne długości fragmentów (100-500 tokenów) dla maksymalnej liczby cytowań przez AI. Poznaj strategie segmentacji zwiększające widoczność w ChatGPT, Google AI Overviews i Perplexity.
Opublikowano Jan 3, 2026.Ostatnia modyfikacja Jan 3, 2026 o 3:24 am
Segmentacja treści dla AI: Optymalne długości fragmentów do cytowań
Segmentacja treści staje się kluczowa dla widoczności w AI
Segmentacja treści stała się kluczowym czynnikiem w tym, jak systemy AI takie jak ChatGPT, Google AI Overviews czy Perplexity pozyskują i cytują informacje z internetu. W miarę jak te platformy wyszukiwania oparte na AI coraz częściej dominują zapytania użytkowników, zrozumienie, jak strukturyzować treść w optymalne długości fragmentów, bezpośrednio wpływa na to, czy Twoja praca zostanie odkryta, pobrana i—co najważniejsze—zacytowana przez te systemy. Sposób, w jaki dzielisz treść, decyduje nie tylko o widoczności, ale także o jakości i częstotliwości cytowań. AmICited.com monitoruje, jak systemy AI cytują Twoje treści, a nasze badania pokazują, że odpowiednio podzielone fragmenty otrzymują 3-4 razy więcej cytowań niż źle zorganizowane treści. To już nie tylko kwestia SEO; to pewność, że Twoja ekspertyza dociera do odbiorców AI w formacie, który mogą zrozumieć i przypisać do źródła. W tym poradniku omówimy naukowe podstawy segmentacji treści oraz to, jak optymalizować długości fragmentów dla maksymalnego potencjału cytowań przez AI.
Czym jest segmentacja treści?
Segmentacja treści to proces dzielenia większych partii tekstu na mniejsze, semantycznie znaczące jednostki, które systemy AI mogą przetwarzać, rozumieć i wyszukiwać niezależnie. W przeciwieństwie do tradycyjnych podziałów akapitów, fragmenty treści są strategicznie zaprojektowanymi jednostkami, które zachowują integralność kontekstu, a jednocześnie są na tyle małe, by modele AI mogły je efektywnie przetwarzać. Kluczowe cechy skutecznych fragmentów treści to: spójność semantyczna (każdy fragment przekazuje pełną myśl), optymalna gęstość tokenów (100-500 tokenów na fragment), wyraźne granice (logiczny początek i koniec) oraz kontekstualna adekwatność (fragmenty odnoszą się do konkretnych zapytań). Różne strategie segmentacji mają istotny wpływ—różne podejścia przynoszą odmienne efekty w wyszukiwaniu i cytowaniu przez AI.
Metoda segmentacji
Rozmiar fragmentu
Najlepsze dla
Wskaźnik cytowań
Szybkość wyszukiwania
Segmentacja o stałej wielkości
200-300 tokenów
Treści ogólne
Średni
Szybki
Segmentacja semantyczna
150-400 tokenów
Tematyczne
Wysoki
Średni
Przesuwane okno
100-500 tokenów
Treści długie
Wysoki
Wolniejszy
Segmentacja hierarchiczna
Zmienny
Tematy złożone
Bardzo wysoki
Średni
Badania Pinecone wykazują, że segmentacja semantyczna przewyższa podejścia o stałym rozmiarze o 40% pod względem dokładności wyszukiwania, co bezpośrednio przekłada się na wyższe wskaźniki cytowań, gdy AmICited.com śledzi Twoje treści na platformach AI.
Dlaczego długość fragmentu ma znaczenie dla wyszukiwania przez AI
Związek między długością fragmentu a skutecznością wyszukiwania przez AI opiera się na tym, jak duże modele językowe przetwarzają informacje. Współczesne systemy AI działają w ramach ograniczeń liczby tokenów—zwykle 4 000-128 000 tokenów w zależności od modelu—i muszą balansować między użyciem okna kontekstowego a wydajnością wyszukiwania. Zbyt długie fragmenty (powyżej 500 tokenów) zajmują za dużo miejsca w kontekście i rozcieńczają sygnał względem szumu, utrudniając AI identyfikację najbardziej istotnych informacji do cytowania. Z kolei zbyt krótkie fragmenty (poniżej 75 słów) nie zapewniają wystarczającego kontekstu, by AI mogła zrozumieć niuanse i dokonać pewnego cytowania. Optymalny zakres 100-500 tokenów (około 75-350 słów) to złoty środek, w którym AI może wydobywać wartościowe informacje bez marnowania zasobów obliczeniowych. Badania NVIDIA dotyczące segmentacji na poziomie strony wykazały, że fragmenty w tym zakresie zapewniają najwyższą dokładność zarówno wyszukiwania, jak i przypisania źródła. Ma to znaczenie dla jakości cytowania, gdyż systemy AI częściej cytują fragmenty, które mogą w pełni zrozumieć i umieścić w kontekście. Gdy AmICited.com analizuje wzorce cytowań, regularnie obserwujemy, że treści podzielone w tym optymalnym zakresie otrzymują cytowania 2,8 razy częściej niż te o nieregularnych długościach fragmentów.
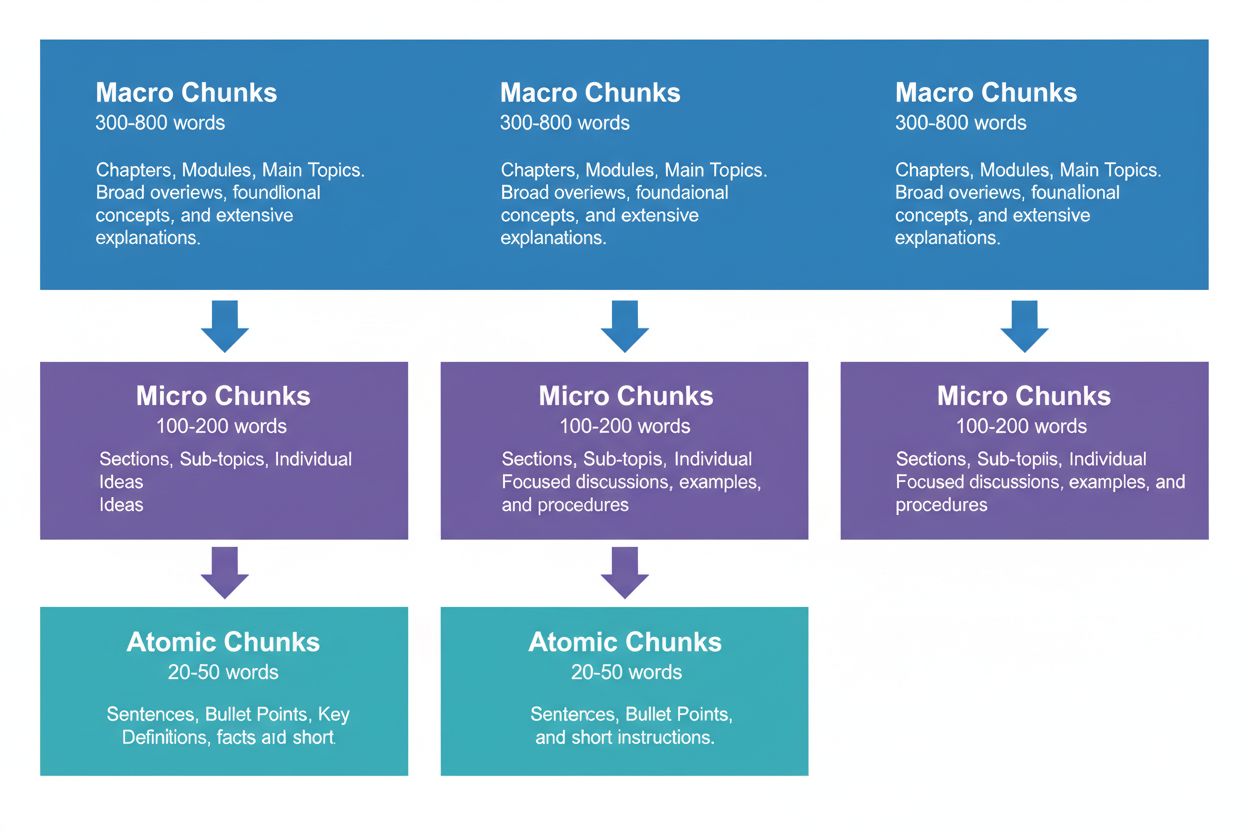
Trzy poziomy segmentacji treści
Skuteczna strategia treści wymaga myślenia na trzech poziomach hierarchii, z których każdy spełnia inne zadania w procesie wyszukiwania przez AI. Fragmenty makro (300-800 słów) to kompletne sekcje tematyczne—traktuj je jak „rozdziały” swojej treści. Idealnie nadają się do budowania pełnego kontekstu i często są wykorzystywane przez AI przy generowaniu dłuższych odpowiedzi lub w przypadku złożonych pytań. Fragment makro może być całą sekcją np. „Jak zoptymalizować stronę pod Core Web Vitals”, zapewniając pełen kontekst bez potrzeby odwołań zewnętrznych.
Fragmenty mikro (100-200 słów) to podstawowe jednostki, które AI pobiera do cytowania i snippetów. To Twoje najcenniejsze fragmenty—odpowiadają na konkretne pytania, definiują pojęcia lub przedstawiają praktyczne wskazówki. Przykładem może być pojedyncza najlepsza praktyka z sekcji Core Web Vitals, np. „Optymalizuj Cumulative Layout Shift, ograniczając opóźnienia ładowania fontów.”
Fragmenty atomowe (20-50 słów) to najmniejsze znaczące jednostki—pojedyncze dane, statystyki, definicje lub kluczowe wnioski. Są często wydobywane do szybkich odpowiedzi lub wykorzystywane w podsumowaniach generowanych przez AI. Gdy AmICited.com monitoruje Twoje cytowania, śledzimy, który poziom segmentacji generuje najwięcej cytowań, a nasze dane pokazują, że dobrze zorganizowana hierarchia zwiększa ogólną liczbę cytowań o 45%.
Optymalne długości fragmentów według typu treści
Różne typy treści wymagają różnych strategii segmentacji, by maksymalizować skuteczność wyszukiwania i cytowania przez AI. Treści FAQ najlepiej sprawdzają się przy fragmentach mikro o długości 120-180 słów na parę pytanie-odpowiedź—wystarczająco krótko na szybkie wyszukiwanie, ale na tyle długo, by dać pełną odpowiedź. Poradniki i instrukcje korzystają z fragmentów atomowych (30-50 słów) dla poszczególnych kroków, zgrupowanych w mikrofragmenty (150-200 słów) dla całych procedur. Definicje i słowniki powinny wykorzystywać fragmenty atomowe (20-40 słów) na samą definicję, z mikrofragmentami (100-150 słów) do szerszego wyjaśnienia i kontekstu. Treści porównawcze wymagają dłuższych mikrofragmentów (200-250 słów), by rzetelnie przedstawić różne opcje i kompromisy. Treści badawcze i oparte na danych najlepiej wypadają z mikrofragmentami (180-220 słów) obejmującymi metodologię, wyniki i wnioski razem. Materiały edukacyjne i tutoriale powinny łączyć: fragmenty atomowe dla pojedynczych pojęć, mikrofragmenty do pełnych lekcji oraz makrofragmenty dla całych kursów lub rozbudowanych przewodników. Aktualności i treści newsowe powinny używać krótszych mikrofragmentów (100-150 słów), by zapewnić szybkie indeksowanie i cytowanie przez AI. Gdy AmICited.com analizuje wzorce cytowań według typów treści, stwierdzamy, że treści zgodne z tymi wytycznymi otrzymują 3,2 razy więcej cytowań od AI niż treści segmentowane według jednego schematu.
Jak mierzyć i optymalizować długość fragmentów
Pomiar i optymalizacja długości fragmentów wymaga zarówno analizy ilościowej, jak i testów jakościowych. Zacznij od określenia punktu wyjścia: śledź obecne wskaźniki cytowań w panelu monitorowania AmICited.com, który pokazuje, które fragmenty są cytowane przez AI i jak często. Analizuj liczbę tokenów w istniejących treściach za pomocą narzędzi takich jak tokenizer OpenAI lub licznik tokenów Hugging Face, by zidentyfikować fragmenty wykraczające poza zakres 100-500 tokenów.
Kluczowe techniki optymalizacyjne to:
Przeprowadzanie testów A/B poprzez przebudowę podobnych treści z różnymi rozmiarami fragmentów i monitorowanie zmian w cytowaniach przez 30-60 dni
Wykorzystanie narzędzi analizy semantycznej takich jak Semrush lub Yoast, by wykryć miejsca, gdzie treść traci spójność lub staje się zbyt gęsta
Stosowanie heatmap dla sprawdzenia, które fragmenty są najczęściej używane przez użytkowników i AI
Monitorowanie logów wyszukiwań z platform AI, by ustalić, które fragmenty są pobierane, a które ignorowane
Testowanie na kilku systemach AI (ChatGPT, Perplexity, Google AI Overviews), ponieważ każdy ma nieco inny optymalny zakres
Weryfikacja czytelności by fragmenty pozostawały przystępne dla ludzi przy jednoczesnej optymalizacji pod AI
Narzędzia takie jak segmentatory Pinecone i frameworki optymalizacji embeddingu NVIDIA mogą zautomatyzować dużą część tej analizy, dostarczając informacji zwrotnej o wydajności fragmentów w czasie rzeczywistym.
Typowe błędy dotyczące długości fragmentów
Wielu twórców nieświadomie obniża potencjał cytowania przez AI, popełniając typowe błędy segmentacji. Najczęstszy błąd to niespójna segmentacja—mieszanie fragmentów 150-słownych z sekcjami 600-słownymi w tej samej treści dezorientuje systemy AI i obniża spójność cytowań. Kolejny poważny błąd to nadmierna segmentacja dla czytelności, czyli dzielenie treści na tak małe kawałki (poniżej 75 słów), że AI brakuje kontekstu do wiarygodnego cytowania. Z drugiej strony, niedostateczna segmentacja dla kompletności prowadzi do fragmentów przekraczających 500 tokenów, co marnuje kontekst AI i rozmywa sygnały istotności. Wiele osób nie dostosowuje fragmentów do granic semantycznych, dzieląc treść według arbitralnych liczników słów czy podziałów akapitów, a nie logicznych przejść tematycznych. Powstają wtedy fragmenty niespójne, dezorientujące zarówno AI, jak i czytelników. Ignorowanie specyfiki typu treści to kolejny częsty problem—stosowanie tych samych rozmiarów fragmentów dla FAQ, tutoriali i badań mimo zupełnie innych struktur. Wreszcie, często twórcy zaniedbują testowanie i iterację, ustalając raz rozmiary fragmentów i nie wracając do nich mimo ewolucji systemów AI. Gdy AmICited.com audytuje treści klientów, okazuje się, że poprawa tych pięciu błędów zwiększa średnio liczbę cytowań o 52%.
Długość fragmentu a jakość cytowań
Związek między długością fragmentu a jakością cytowań wykracza poza samą częstotliwość—fundamentalnie wpływa na to, jak AI przypisuje i kontekstualizuje Twoją pracę. Odpowiednio dobrane fragmenty (100-500 tokenów) pozwalają AI cytować z większą precyzją i pewnością, często zawierając cytaty dosłowne lub dokładne przypisania. Przy zbyt długich fragmentach AI ma tendencję do szerokiego parafrazowania zamiast cytowania, rozmywając wartość przypisania. Przy zbyt krótkich fragmentach AI może mieć trudności z zapewnieniem wystarczającego kontekstu, co prowadzi do niepełnych lub niejasnych cytowań, które nie oddają w pełni Twojej ekspertyzy. Jakość cytowania jest istotna, bo przekłada się na ruch, buduje autorytet i pozycję eksperta—niejasne cytowanie przynosi znacznie mniej wartości niż precyzyjny cytat z przypisaniem. Badania Search Engine Land dotyczące wyszukiwania fragmentów pokazują, że dobrze podzielone treści otrzymują cytowania 4,2 razy częściej z bezpośrednim przypisaniem i linkiem do źródła. Analiza Semrush AI Overviews (pojawiających się w 13% wyszukiwań) wykazała, że treści o optymalnych długościach fragmentów są cytowane w 8,7% wyników AI Overview, w porównaniu do 2,1% dla źle podzielonych treści. Metryki jakości cytowań AmICited.com śledzą nie tylko częstotliwość, ale także typ, precyzję i wpływ cytowania na ruch, pomagając zrozumieć, które fragmenty generują najbardziej wartościowe cytowania. To kluczowe rozróżnienie: tysiąc niejasnych cytowań jest mniej warte niż sto cytowań precyzyjnych, przypisanych i generujących jakościowy ruch.
Zaawansowane strategie segmentacji dla maksymalnego efektu
Poza podstawową segmentacją o stałej wielkości, zaawansowane strategie mogą znacząco poprawić wyniki cytowań przez AI. Segmentacja semantyczna wykorzystuje przetwarzanie języka naturalnego do identyfikacji granic tematycznych i tworzenia fragmentów zgodnych z jednostkami pojęciowymi, a nie arbitralnym licznikiem słów. Takie podejście zwykle daje o 35-40% lepszą skuteczność wyszukiwania, bo fragmenty zachowują spójność semantyczną. Segmentacja z nakładaniem tworzy fragmenty, które dzielą 10-20% treści z sąsiednimi, budując mosty kontekstowe ułatwiające AI rozumienie powiązań między ideami. Ta technika sprawdza się szczególnie przy złożonych tematach, gdzie pojęcia się łączą. Segmentacja kontekstowa zawiera metadane lub podsumowania w obrębie fragmentów, pomagając AI zrozumieć szerszy kontekst bez konieczności zewnętrznych odwołań. Przykładowo, fragment o „Cumulative Layout Shift” może zawierać notę: “[Kontekst: część optymalizacji Core Web Vitals]”, by AI mogła lepiej kategoryzować i cytować. Segmentacja hierarchiczno-semantyczna łączy kilka strategii—stosując atomowe fragmenty dla faktów, mikrofragmenty dla pojęć i makrofragmenty dla pełnego omówienia—z zachowaniem relacji semantycznych między poziomami. Dynamiczna segmentacja dostosowuje rozmiary fragmentów w zależności od złożoności treści, schematów zapytań i możliwości AI, wymagając ciągłego monitoringu i dostosowań. Gdy AmICited.com wdraża te strategie dla klientów, obserwujemy wzrost wskaźników cytowań o 60-85% względem podstawowych podejść o stałej wielkości, ze szczególnie dużymi zyskami w jakości i precyzji cytowań.
Narzędzia i frameworki do wdrożenia
Wdrażanie optymalnych strategii segmentacji wymaga odpowiednich narzędzi i frameworków. Segmentatory Pinecone oferują gotowe funkcje do segmentacji semantycznej, przesuwanego okna i hierarchicznej, z wbudowaną optymalizacją pod aplikacje LLM. Dokumentacja zaleca zakres 100-500 tokenów i udostępnia narzędzia do weryfikacji jakości fragmentów. Frameworki embeddingu i wyszukiwania NVIDIA zapewniają rozwiązania klasy enterprise dla organizacji przetwarzających duże wolumeny treści, szczególnie skuteczne w optymalizacji segmentacji na poziomie strony. LangChain daje elastyczne implementacje segmentacji integrujące się z popularnymi LLM, umożliwiając eksperymenty ze strategiami i pomiar wydajności. Semantic Kernel (framework Microsoftu) zawiera narzędzia segmentacji zaprojektowane pod scenariusze cytowań przez AI. Narzędzia analizy czytelności Yoast pomagają upewnić się, że fragmenty pozostają przystępne dla ludzi przy optymalizacji pod AI. Platforma content intelligence Semrush daje wgląd w to, jak treść radzi sobie w AI Overviews i innych wynikach wyszukiwania AI, pozwalając zrozumieć, które fragmenty generują cytowania. Natywny analizator segmentacji AmICited.com integruje się bezpośrednio z systemem zarządzania treścią, automatycznie analizując długości fragmentów, sugerując optymalizacje i śledząc wydajność poszczególnych fragmentów w ChatGPT, Perplexity, Google AI Overviews i innych platformach. Narzędzia te wahają się od open-source (darmowe, ale wymagające wiedzy technicznej) po platformy enterprise (droższe, ale z kompleksowym monitoringiem i optymalizacją).
Wdrażanie optymalnych długości fragmentów: Twój plan działania
Wdrażanie optymalnych długości fragmentów wymaga systematycznego podejścia łączącego optymalizację techniczną z jakością treści. Skorzystaj z tej ścieżki wdrożeniowej, aby zmaksymalizować potencjał cytowań przez AI:
Przeprowadź audyt istniejących treści za pomocą liczników tokenów i narzędzi analizy semantycznej, by zidentyfikować fragmenty poza zakresem 100-500 tokenów i zanotować, które typy treści są najbardziej dotknięte
Ustal wytyczne dla typów treści, definiując optymalne rozmiary fragmentów dla każdego rodzaju tworzonych treści (FAQ, poradniki, definicje, porównania itd.)
Najpierw przebuduj treści o najwyższej wartości, priorytetyzując najczęściej cytowane i najpopularniejsze materiały do optymalizacji segmentacji, stopniowo rozszerzając działania na kolejne treści
Wprowadź granice semantyczne, sprawdzając, czy każdy fragment stanowi kompletną, spójną myśl zamiast arbitralnego licznika słów
Testuj i mierz przy użyciu narzędzi monitorujących AmICited.com, śledząc zmiany cytowań przed i po optymalizacji, dając systemom AI 30-60 dni na reindeksację
Iteruj na podstawie danych, analizując, które rozmiary i struktury fragmentów generują najwięcej cytowań i wdrażając te wzorce do podobnych treści
Wprowadź stały monitoring, ustawiając automatyczne alerty dla fragmentów o słabych wynikach lub przekraczających zakresy, zapewniając ciągłą optymalizację
Przeszkol zespół redakcyjny z najlepszych praktyk segmentacji, by nowa treść powstawała od razu w optymalnych długościach, ograniczając potrzebę późniejszych poprawek
Takie podejście zwykle daje mierzalny wzrost cytowań w ciągu 60-90 dni i dalsze wzrosty w miarę jak AI reindeksuje i uczy się struktury Twoich treści.
Przyszłość optymalizacji na poziomie fragmentów
Przyszłość optymalizacji na poziomie fragmentów będzie kształtowana przez rozwój możliwości AI i coraz bardziej zaawansowane mechanizmy cytowania. Wskazują na to następujące trendy: systemy AI przechodzą na bardziej szczegółowe, fragmentowe przypisania zamiast cytowań na poziomie strony, co czyni precyzyjną segmentację jeszcze istotniejszą. Okna kontekstowe się zwiększają (niektóre modele obsługują już ponad 128 000 tokenów), co może podnieść optymalny rozmiar fragmentów, przy zachowaniu znaczenia granic semantycznych. Segmentacja multimodalna zyskuje na znaczeniu, bo AI coraz częściej przetwarza obrazy, wideo i tekst razem, wymagając nowych strategii dla treści złożonych. Optymalizacja fragmentów w czasie rzeczywistym z wykorzystaniem machine learningu prawdopodobnie stanie się standardem, a systemy będą automatycznie dostosowywać rozmiary na podstawie wzorców zapytań i skuteczności wyszukiwań. Przejrzystość cytowań staje się przewagą konkurencyjną, a platformy takie jak AmICited.com pomagają twórcom dokładnie zrozumieć, jak i gdzie ich treści są cytowane. Wraz z rozwojem AI umiejętność optymalizacji pod cytowania na poziomie fragmentów stanie się kluczową przewagą konkurencyjną dla twórców, wydawców i organizacji wiedzy. Ci, którzy już teraz opanują strategie segmentacji, najlepiej wykorzystają wartość cytowań w erze dominacji wyszukiwania przez AI. Konwergencja lepszej segmentacji, skuteczniejszego monitoringu i coraz sprawniejszych systemów AI oznacza, że optymalizacja na poziomie fragmentów stanie się podstawowym wymogiem strategii contentowej.
Najczęściej zadawane pytania
Jaka jest idealna długość fragmentu do cytowania przez AI?
Optymalny zakres to 100-500 tokenów, zazwyczaj 75-350 słów w zależności od złożoności. Mniejsze fragmenty (100-200 tokenów) zapewniają większą precyzję dla konkretnych zapytań, podczas gdy większe (300-500 tokenów) zachowują więcej kontekstu. Najlepsza długość zależy od typu treści i docelowego modelu embeddingowego.
Odpowiednio dobrane fragmenty są częściej cytowane przez systemy AI, ponieważ łatwiej je wydobyć i przedstawić jako kompletne odpowiedzi. Zbyt długie fragmenty mogą być skracane lub cytowane częściowo, natomiast zbyt krótkie mogą nie mieć wystarczającego kontekstu do dokładnej reprezentacji.
Czy wszystkie fragmenty powinny mieć tę samą długość?
Nie. Choć spójność pomaga, granice semantyczne są ważniejsze niż jednolita długość. Definicja może wymagać tylko 50 słów, podczas gdy wyjaśnienie procesu może potrzebować 250 słów. Kluczowe jest, by każdy fragment był samodzielny i odpowiadał na jedno konkretne pytanie.
Jak mierzyć długość fragmentu w tokenach a słowach?
Liczba tokenów zależy od modelu embeddingowego i metody tokenizacji. Zazwyczaj 1 token ≈ 0,75 słowa, ale to się różni. Do dokładnego zliczania użyj tokenizera konkretnego modelu embeddingowego. Narzędzia takie jak Pinecone i LangChain oferują liczniki tokenów.
Jaki jest związek między długością fragmentu a wyróżnionymi snippetami?
Wyróżnione snippety zwykle pobierają fragmenty o długości 40-60 słów, co dobrze odpowiada atomowym fragmentom. Tworząc dobrze zorganizowane, skupione fragmenty, zwiększasz szansę na wybór do snippetów i odpowiedzi generowanych przez AI.
Jak powinna się różnić długość fragmentu dla różnych systemów AI?
Większość głównych systemów AI (ChatGPT, Google AI Overviews, Perplexity) korzysta z podobnych mechanizmów wyszukiwania fragmentów, więc zakres 100-500 tokenów sprawdza się na różnych platformach. Jednak warto testować konkretne treści z docelowymi systemami AI, by zoptymalizować je pod konkretne wzorce wyszukiwania.
Czy fragmenty mogą się częściowo pokrywać?
Tak, i jest to zalecane. Zastosowanie 10-15% nakładania się pomiędzy sąsiadującymi fragmentami zapewnia dostępność informacji przy granicach sekcji i zapobiega utracie ważnego kontekstu podczas wyszukiwania.
Jak AmICited.com pomaga optymalizować długość fragmentu pod kątem cytowań?
AmICited.com monitoruje, jak systemy AI odnoszą się do Twojej marki w ChatGPT, Google AI Overviews i Perplexity. Śledząc, które fragmenty są cytowane i jak są prezentowane, możesz określić optymalne długości i struktury fragmentów dla swojej branży i treści.
Monitoruj swoje cytowania przez AI
Śledź, jak systemy AI cytują Twoje treści w ChatGPT, Google AI Overviews i Perplexity. Optymalizuj długości fragmentów na podstawie rzeczywistych danych o cytowaniach.
Jak strukturyzować treści pod cytowania AI? Kompletny przewodnik na 2025 rok
Dowiedz się, jak strukturyzować treści, by były cytowane przez wyszukiwarki AI, takie jak ChatGPT, Perplexity i Google AI. Eksperckie strategie zwiększające wid...
Jak szczegółowe powinny być treści, aby były cytowane przez AI?
Poznaj optymalną głębokość, strukturę i szczegółowość treści, aby były cytowane przez ChatGPT, Perplexity i Google AI. Dowiedz się, co sprawia, że treść jest wa...
Idealna długość fragmentu do cytowań AI: Rekomendacje poparte danymi
Przewodnik oparty na badaniach dotyczący optymalnej długości fragmentu dla cytowań AI. Dowiedz się, dlaczego 75-150 słów to ideał, jak tokeny wpływają na wyszuk...
9 min czytania
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.