
Plik LLMs.txt
Dowiedz się, czym są pliki LLMs.txt, czym różnią się od robots.txt i dlaczego są niezbędne dla widoczności i cytowań w AI, takich jak ChatGPT, Perplexity i Goog...
9 min czytania

Krytyczna analiza skuteczności LLMs.txt. Dowiedz się, czy ten standard AI jest niezbędny dla Twojej strony, czy to tylko moda. Rzeczywiste dane o adopcji, wsparciu przez platformy i tym, co faktycznie działa dla widoczności w AI.
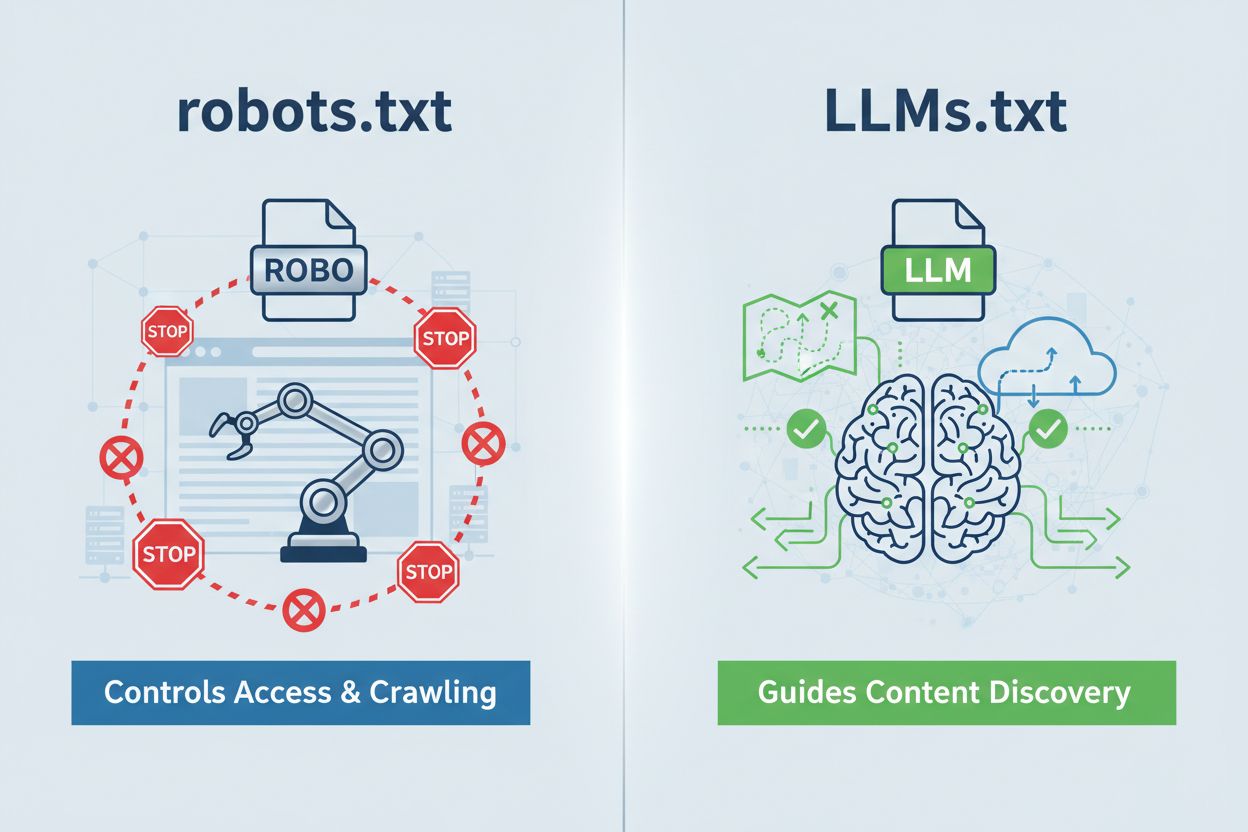
LLMs.txt to zwykły plik tekstowy umieszczany pod adresem domena.com/llms.txt, który służy jako kuratorski przewodnik dla systemów AI do odkrywania Twoich najwyższej jakości treści. To zasadniczo coś innego niż robots.txt—podczas gdy robots.txt reguluje, czy roboty AI mogą uzyskać dostęp do Twojej strony, LLMs.txt działa na poziomie dostępu podczas wnioskowania, pomagając AI określić, które strony zasługują na priorytet przy generowaniu odpowiedzi. To raczej mapa skarbów niż policjant ruchu: nie ogranicza eksploracji, a jedynie wskazuje, gdzie zakopane są prawdziwe wartości. Format jest odświeżająco prosty—czysty markdown, bez skomplikowanej składni—co czyni go dostępnym dla każdej organizacji niezależnie od poziomu technicznego. To rozróżnienie jest kluczowe, bo zmienia całą dyskusję: LLMs.txt nie służy kontroli crawlów, lecz optymalizuje, jak systemy AI interpretują i priorytetyzują treści czytelne dla AI po tym, jak już Cię znajdą.
Liczby pokazują prawdziwy ruch: ponad 844 000 stron wdrożyło LLMs.txt do października 2025 roku, z koncentracją wśród firm rozumiejących rolę AI w swojej przyszłości. Najwięksi gracze jak Anthropic, Cloudflare, Stripe, Vercel i Supabase przyjęli ten standard, co sygnalizuje, że poważne firmy infrastrukturalne widzą w tym eksperymencie wartość. Decyzja Mintlify o automatycznym generowaniu plików dla tysięcy stron dokumentacyjnych w listopadzie 2024 spowodowała znaczący wzrost wdrożeń, pokazując, że wsparcie narzędzi przyspiesza adaptację. Trzy katalogi społecznościowe śledzą teraz wdrożenia, z 788+ zweryfikowanymi witrynami. Sposób wdrożenia ujawnia jednak coś ważnego: implementacja koncentruje się w narzędziach deweloperskich i platformach dokumentacyjnych—czyli w sektorach, które najwięcej zyskują na widoczności w AI. Oto jak wygląda krajobraz wdrożeń:
| Firma/Platforma | Wdrożenie | Liczba tokenów | Status |
|---|---|---|---|
| Anthropic | Tak | ~2 000 | Aktywne |
| Cloudflare | Tak | ~5 000 | Aktywne |
| Stripe | Tak | ~8 000 | Aktywne |
| Vercel | Tak | ~3 500 | Aktywne |
| Supabase | Tak | ~4 200 | Aktywne |
| Mintlify (automatycznie generowane) | Tak | Różnie | Aktywne |
I tu pojawia się uzasadniony sceptycyzm: ŻADNA z głównych platform AI nie potwierdziła oficjalnie korzystania z LLMs.txt w swoich systemach wyszukiwania. John Mueller z Google powiedział wprost: “Żaden system AI nie używa obecnie llms.txt”, komentarz, który powinien zakończyć dyskusję, a jednak nie zakończył. OpenAI, Anthropic, Google, Microsoft i Perplexity milczą strategicznie — brak oficjalnej dokumentacji, potwierdzeń, publicznych planów. Istnieją dowody, że niektóre platformy pobierają pliki (zaobserwowano boty Microsoft i OpenAI pobierające LLMs.txt), ale pobieranie a faktyczne użycie to dwie różne rzeczy. Optymistyczna interpretacja sugeruje, że platformy testują to po cichu przed oficjalnym wdrożeniem; sceptyczna — że nigdy tego nie wdrożą, bo nie rozwiązuje to ich realnych problemów. To milczenie jest sednem argumentu o “przereklamowaniu”: 18 miesięcy po popularyzacji standardu mamy powszechne wdrożenia, a zero oficjalnych adopcji przez platformy. To nie standard—tylko nadzieja.
Sceptycy opierają się na prostym założeniu: nie ma dowodów, że LLMs.txt poprawia wyszukiwanie w AI, zwiększa ruch czy widoczność treści. Problem zaufania się pogłębia—tworząc osobny plik, który może zawierać inną treść niż HTML, umożliwiasz manipulację. Badania nad zachowaniem LLM pokazują, że są 2,5x bardziej skłonne rekomendować treści specjalnie wyróżnione, co rodzi pokusę do “gry”. Organizacja może umieścić w LLMs.txt tylko najlepiej radzące sobie treści i ukryć słabsze albo, co gorsza, dodać tam coś, co nie istnieje na stronie. Dostawcy narzędzi SEO wzmocnili presję, sygnalizując brak LLMs.txt jako szansę na optymalizację—Rank Math, SEMrush i inni tworzą samonapędzający się cykl wdrożeń, bo narzędzia każą, nie dlatego, że to działa. To prawdziwy problem: 18 miesięcy presji bez ani jednego udokumentowanego przypadku mierzalnej korzyści. To cyfrowy odpowiednik kupowania losów na loterię, bo sama loteria reklamuje się na okrągło.
Obóz pro-LLMs.txt argumentuje zupełnie inaczej, opierając się na nieuchronnych zmianach, nie na obecnych dowodach. Carolyn Shelby z Yoast ujęła to najlepiej: “Ranking nie jest już nagrodą—jest nią obecność.” Windsurf, edytor kodu AI, podaje, że LLMs.txt oszczędza czas i tokeny przy analizie dokumentacji, co sugeruje rzeczywistą efektywność dla AI, które to stosują. Anthropic poprosił Mintlify o wdrożenie LLMs.txt w ich dokumentacji, co sugeruje wewnętrzną wartość, nawet bez publicznego potwierdzenia. Google ujęło LLMs.txt w protokole A2A (Agents to Agents), co wskazuje, że widzi w tym część przyszłej infrastruktury AI-to-AI. Wdrożenie trwa 1–4 godziny bez ryzyka—nie psujesz niczego, nie szkodzisz SEO, po prostu tworzysz plik. Obserwacja Jeremy’ego Howarda trafia w sedno: “99,9% uwagi za chwilę będą poświęcać LLM-y, nie ludzie,” więc optymalizacja pod AI nie jest opcją, lecz koniecznością. Springs Apps odnotowało 20% wzrost widoczności po wdrożeniu, choć pozostaje to niezweryfikowane i może być koincydencją.
Aby zrozumieć, dlaczego LLMs.txt może się nie udać, trzeba zobaczyć, dlaczego inne standardy się przyjęły. Robots.txt zadziałał, bo dawał obustronne korzyści przy minimalnych kosztach i otrzymał oficjalne wsparcie RFC (RFC 9309)—wyszukiwarki chciały sprawnie crawlować, strony chciały kontrolować crawlery, a wdrożenie było banalne. Schema.org odniosło sukces dzięki współpracy Google, Microsoftu, Yahoo i Yandexa—nikt nie był właścicielem, co budowało zaufanie. Sitemap.xml zdobył szerokie wsparcie platform przed powszechnym wdrożeniem, nie po. LLMs.txt nie ma żadnego z tych czynników: brak udziału W3C, brak konsorcjum, brak wsparcia platform, brak dowodów na wzrost ruchu, pozycji czy precyzji. Standardy działają, gdy są wspólne, mają mierzalne korzyści i trudno je “ograć”. LLMs.txt ma nadzieję. Ma wdrożenia wśród entuzjastów. Ma wsparcie narzędzi. Ale nie ma fundamentów, które zamieniły poprzednie eksperymenty w infrastrukturę.
Jeśli LLMs.txt pozostaje niepotwierdzony, co naprawdę daje widoczność w AI i cytowania AI? Odpowiedź jest mniej egzotyczna niż nowy format pliku:
Tego typu działania działają, bo odpowiadają temu, jak AI faktycznie przetwarzają informacje, a nie dlatego, że są zoptymalizowane pod konkretny plik.

Dyskusja o LLMs.txt odzwierciedla głębsze przesunięcie w sukcesie treści online: konwergencję UX człowieka i optymalizacji pod AI. Badania nad Generative Engine Optimization (GEO) pokazują, że treści wygrywające w AI mają konkretne cechy—jasność, strukturę, autorytet i precyzję. Vercel raportuje, że 10% rejestracji pochodzi obecnie bezpośrednio z wzmianek w ChatGPT, a nie z wyszukiwarki—co byłoby niemożliwe pięć lat temu. Sukces to coraz częściej obecność w odpowiedziach generowanych przez AI, nie tylko pozycja w wynikach wyszukiwania—to inne cele i inne wymagania. Krajobraz narzędzi już to śledzi: SEMrush AIO, monitorowanie GEO Profound, Ahrefs Brand Radar mierzą dziś widoczność w AI obok tradycyjnych rankingów. Najważniejsza zmiana: bycie cytowanym znaczy więcej niż bycie wysoko, a bycie wspominanym więcej niż bycie zaindeksowanym. To tłumaczy, dlaczego LLMs.txt zyskał popularność mimo braku oficjalnego wsparcia—jest próbą optymalizacji pod nową ekonomię uwagi, gdzie AI to główny kanał dystrybucji.
Jeśli zdecydujesz się wdrożyć, zrób to poprawnie. Plik musi być dostępny pod adresem domena.com/llms.txt (uwaga: liczba mnoga), w formacie zwykłego markdown, nie XML ani JSON. Zacznij od nagłówka H1 z nazwą strony, opcjonalnie dodaj blok cytatu z opisem celu witryny. Podziel treści na sekcje H2, jeśli masz różne obszary (Dokumentacja, Blog, API itd.), z opisem każdej z nich. Użyj formatu [Tytuł](URL): Opis dla poszczególnych stron, opis krótki, ale treściwy. Co dodać: ponadczasowe treści, dobrze zorganizowane strony, materiały pokazujące Twoją ekspertyzę. Czego unikać: strony głównej (zwykle bezwartościowa w izolacji), wszystkich URL-i (liczy się jakość, nie ilość), stron niezrozumiałych bez kontekstu. Przykładowa struktura:
# Nazwa firmy
> Krótki opis działalności i dlaczego AI powinno zainteresować się Twoimi treściami
## Dokumentacja
[Zaczynamy](https://example.com/docs/getting-started): Przewodnik krok po kroku dla nowych użytkowników
[API Reference](https://example.com/docs/api): Pełna dokumentacja API z przykładami
[Best Practices](https://example.com/docs/best-practices): Sprawdzone wzorce korzystania z naszej platformy
## Blog
[Dlaczego to stworzyliśmy](https://example.com/blog/why-we-built-this): Problem, który rozwiązaliśmy i jak to zrobiliśmy
Opcjonalnie możesz dodać sekcję dla URL-i do pominięcia, jeśli potrzebny krótszy kontekst, choć większość wdrożeń tego nie wymaga.
Tak, warto wdrożyć LLMs.txt. Nie dlatego, że jest udowodniony, lecz bo nie wiąże się z żadnym ryzykiem, a potencjalne korzyści są realne. Jeśli AI nigdy go nie przyjmą oficjalnie, plik po prostu sobie leży—bez wpływu na SEO, ruch, czy funkcjonalność. Wdrożenie to ok. 10 minut dla małej strony, może godzinę dla większej. Ruch już rozprasza się między różnymi systemami AI: ChatGPT, Perplexity, Claude i inni obsługują łącznie setki milionów zapytań miesięcznie. Już jesteś widoczny dla AI—LLMs.txt pomaga im znaleźć Twoje najlepsze treści zamiast losowych. Nawet jeśli LLMs.txt nigdy nie stanie się standardem, uczysz AI rozumieć strukturę i priorytety Twojej strony, co zawsze ma wartość. Wniosek: za darmo zabezpieczasz się na przyszłość. Wdroż standard, optymalizuj treści pod widoczność w AI sprawdzonymi metodami i monitoruj, co faktycznie przynosi ruch z AI. Za rok będziesz mieć własne dane, czy LLMs.txt ma znaczenie dla Twojej firmy—a to znacznie cenniejsze niż spekulacje.
LLMs.txt to zwykły plik tekstowy, który kieruje systemy AI do najlepszych treści na Twojej stronie w celu dostępu na etapie wnioskowania, podczas gdy robots.txt kontroluje dostęp crawlerów i indeksowanie. LLMs.txt niczego nie ogranicza—kuratoruje i wyróżnia Twoje najcenniejsze strony dla lepszego zrozumienia przez AI. Myśl o robots.txt jak o policjancie ruchu, a o LLMs.txt jak o mapie skarbów.
Nieoficjalnie nie. Pomimo wdrożenia przez ponad 844 000 stron, żadna duża platforma AI nie potwierdziła, że używa LLMs.txt do generowania odpowiedzi. Istnieją dowody na pobieranie plików przez boty OpenAI i Microsoftu, ale nie ma potwierdzenia użytkowania do celów wnioskowania lub cytowania. To sedno argumentu o 'przereklamowaniu'.
Tak. Wdrożenie zajmuje 10–30 minut i nie niesie ze sobą żadnego ryzyka. Jeśli platformy przyjmą ten standard, już jesteś przygotowany. Jeśli nie, plik nie szkodzi. To niskie ryzyko przy potencjalnie dużej korzyści dla widoczności w AI. W istocie to zakład o przyszłość odkrywania treści przez AI.
Zamieść ponadczasowe, dobrze ustrukturyzowane treści, które odpowiadają na konkretne pytania: poradniki, FAQ, dokumentację API, treści filarowe i autorytatywne artykuły. Unikaj strony głównej, wszystkich URL-i i stron, które wyrwane z kontekstu nie mają sensu. Najważniejsza zasada: jakość ponad ilość.
Tak, to uzasadniona obawa. Możesz zamieścić w LLMs.txt inną treść niż na rzeczywistych stronach, co podważa zaufanie. Dlatego niektórzy eksperci są sceptyczni wobec długoterminowej trwałości standardu i platformy przyjmują go ostrożnie.
llms.txt zawiera wyselekcjonowane linki do najlepszych stron wraz z opisami. llms-full.txt to pełna wersja z całą dokumentacją w jednym ogromnym pliku (czasem ponad 400 000 słów). Użyj llms-full.txt, jeśli chcesz przekazać systemom AI wszystko od razu, bez konieczności podążania za linkami.
LLMs.txt to jedno z narzędzi w szerszej strategii GEO. GEO polega na tym, by Twoje treści były łatwe do znalezienia i cytowania przez systemy AI dzięki przejrzystej strukturze, cytacjom, danym i autorytatywnej wiedzy. LLMs.txt pomaga skierować AI do najlepiej zoptymalizowanych pod GEO treści.
Tak. Każda strona internetowa odnosi korzyści, pomagając AI zrozumieć i cytować swoje treści. Blogi, firmy lokalne, sklepy e-commerce i społeczności niszowe także uzyskują ruch z wyszukiwania AI. LLMs.txt to prosty sposób na poprawę widoczności w ChatGPT, Claude, Perplexity i innych platformach AI.
Śledź, jak systemy AI takie jak ChatGPT, Claude i Perplexity cytują Twoje treści. Uzyskaj wgląd w czasie rzeczywistym w odniesienia AI do Twojej marki i widoczność na platformach AI.
Dowiedz się, czym są pliki LLMs.txt, czym różnią się od robots.txt i dlaczego są niezbędne dla widoczności i cytowań w AI, takich jak ChatGPT, Perplexity i Goog...

Dowiedz się, jak wdrożyć LLMs.txt na swojej stronie internetowej, aby pomóc systemom AI lepiej rozumieć Twoje treści. Kompletny przewodnik krok po kroku dla wsz...

Dowiedz się, czym jest LLMs.txt, czy faktycznie działa i czy warto wdrożyć go na swojej stronie. Szczera analiza tego nowego standardu AI SEO.
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.