
Czym jest meta tag noai i jak chroni Twoje treści przed AI?
Dowiedz się, czym jest meta tag noai, jak działa w celu zapobiegania zbieraniu danych treningowych przez AI, jakie ma ograniczenia oraz jak wdrożyć go na swojej...
6 min czytania

Dowiedz się, jak wdrożyć meta tagi noai i noimageai, aby kontrolować dostęp crawlerów AI do treści Twojej strony. Kompletny przewodnik po nagłówkach kontroli dostępu AI i metodach implementacji.
Crawlery internetowe to zautomatyzowane programy, które systematycznie przeszukują internet, zbierając informacje ze stron. Historycznie, boty te były obsługiwane głównie przez wyszukiwarki takie jak Google, którego Googlebot indeksował strony i kierował użytkowników do witryn poprzez wyniki wyszukiwania — tworząc obopólnie korzystną relację. Jednak pojawienie się crawlerów AI fundamentalnie zmieniło ten układ. W przeciwieństwie do tradycyjnych botów wyszukiwarek, które w zamian za dostęp do treści generują ruch zwrotny, crawlery treningowe AI pochłaniają ogromne ilości treści, by budować zbiory danych do modeli językowych, często nie oddając żadnego lub tylko minimalny ruch wydawcom. Ta zmiana sprawiła, że meta tagi — krótkie polecenia HTML przekazujące instrukcje crawlerom — stały się kluczowe dla twórców chcących zachować kontrolę nad wykorzystaniem swoich treści przez systemy sztucznej inteligencji.
Meta tagi noai i noimageai to dyrektywy stworzone przez DeviantArt w 2022 roku, mające pomóc twórcom w zapobieganiu wykorzystania ich prac do trenowania generatorów obrazów AI. Działają podobnie jak długo stosowana dyrektywa noindex, która informuje wyszukiwarki, by nie indeksowały danej strony. Dyrektywa noai sygnalizuje, że żadna treść na stronie nie powinna być użyta do treningu AI, natomiast noimageai blokuje wykorzystanie obrazów w tym celu. Tag można dodać do sekcji head HTML w następujący sposób:
<!-- Blokuj całą zawartość przed trenowaniem AI -->
<meta name="robots" content="noai">
<!-- Blokuj tylko obrazy przed trenowaniem AI -->
<meta name="robots" content="noimageai">
<!-- Blokuj zarówno treść, jak i obrazy -->
<meta name="robots" content="noai, noimageai">
Oto tabela porównawcza różnych dyrektyw meta tagów i ich zastosowań:
| Dyrektywa | Cel | Składnia | Zakres |
|---|---|---|---|
| noai | Blokuje całą treść przed treningiem AI | content="noai" | Cała zawartość |
| noimageai | Blokuje obrazy przed treningiem AI | content="noimageai" | Tylko obrazy |
| noindex | Blokuje indeksowanie przez wyszukiwarki | content="noindex" | Wyniki wyszukiwań |
| nofollow | Blokuje śledzenie linków | content="nofollow" | Linki wychodzące |
Podczas gdy meta tagi umieszczane są bezpośrednio w HTML, nagłówki HTTP stanowią alternatywny sposób przekazywania dyrektyw crawlerom na poziomie serwera. Nagłówek X-Robots-Tag może zawierać te same dyrektywy co meta tagi, ale działa inaczej — jest wysyłany w odpowiedzi HTTP jeszcze przed przesłaniem treści strony. Jest to szczególnie przydatne do kontroli dostępu do plików nie-HTML, takich jak PDF-y, obrazy czy filmy, gdzie nie można osadzić meta tagu.
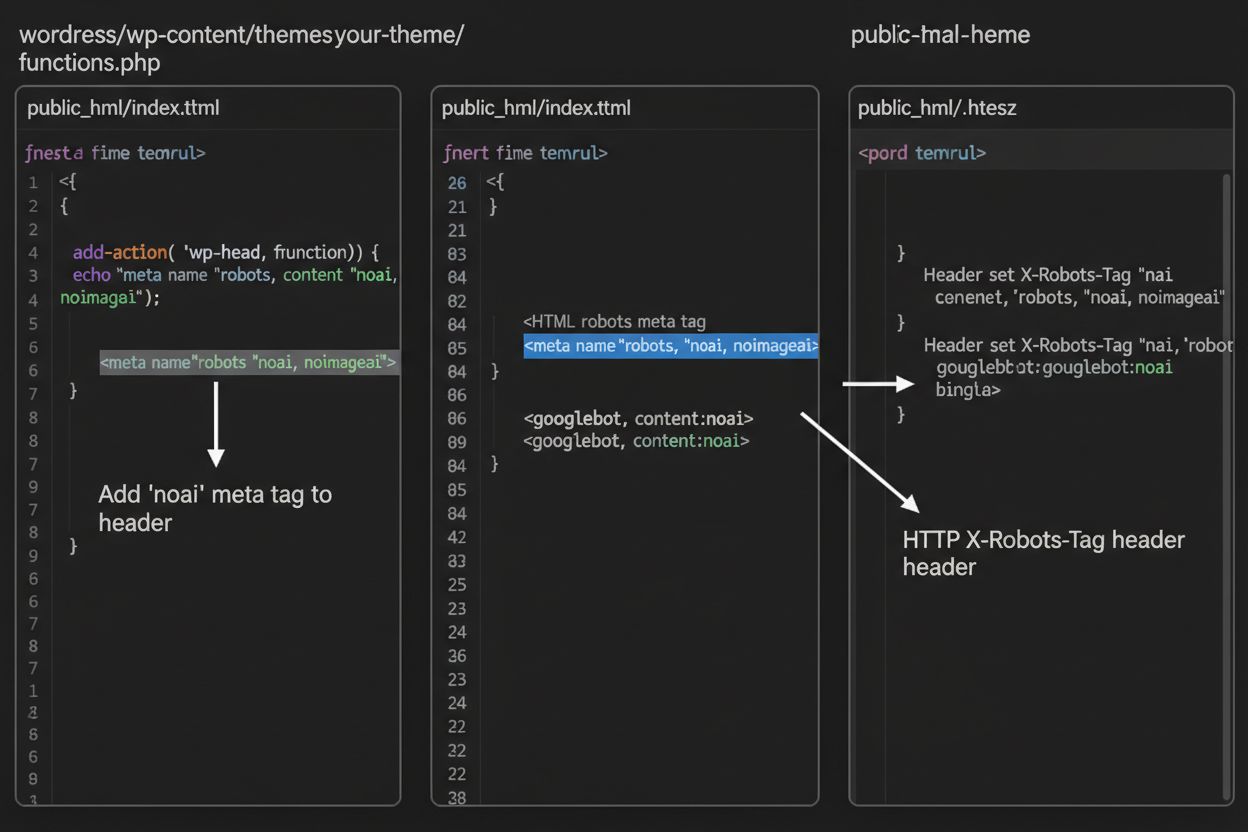
Dla serwerów Apache możesz ustawić nagłówki X-Robots-Tag w pliku .htaccess:
<IfModule mod_headers.c>
Header set X-Robots-Tag "noai, noimageai"
</IfModule>
Dla serwerów NGINX dodaj nagłówek w konfiguracji serwera:
location / {
add_header X-Robots-Tag "noai, noimageai";
}
Nagłówki zapewniają ochronę globalną dla całej strony lub wybranych katalogów, co czyni je idealnym narzędziem w kompleksowej strategii kontroli dostępu AI.
Skuteczność tagów noai i noimageai zależy całkowicie od tego, czy crawlery zdecydują się je respektować. Dobrze zachowujące się crawlery głównych firm AI zazwyczaj przestrzegają tych dyrektyw:
Jednak źle zachowujące się boty i złośliwe crawlery mogą celowo ignorować te dyrektywy, ponieważ nie istnieje żaden mechanizm egzekwowania. W przeciwieństwie do robots.txt, który jest branżowym standardem, noai nie jest oficjalną normą, więc crawlery nie mają obowiązku się do niej stosować. Dlatego eksperci ds. bezpieczeństwa zalecają wielowarstwowe podejście, łączące różne metody ochrony, a nie polegające wyłącznie na meta tagach.
Implementacja tagów noai i noimageai zależy od zastosowanej platformy. Oto instrukcje krok po kroku dla najpopularniejszych rozwiązań:
1. WordPress (przez functions.php) Dodaj ten kod do pliku functions.php motywu potomnego:
function add_noai_meta_tag() {
echo '<meta name="robots" content="noai, noimageai">' . "\n";
}
add_action('wp_head', 'add_noai_meta_tag');
2. Statyczne strony HTML
Dodaj bezpośrednio do sekcji <head> w HTML:
<head>
<meta name="robots" content="noai, noimageai">
</head>
3. Squarespace Przejdź do Ustawienia > Zaawansowane > Wstrzykiwanie kodu, a następnie dodaj do sekcji Header:
<meta name="robots" content="noai, noimageai">
4. Wix Wejdź w Ustawienia > Własny kod, kliknij “Dodaj własny kod”, wklej meta tag, wybierz “Head” i zastosuj do wszystkich stron.
Każda platforma oferuje różny poziom kontroli — WordPress umożliwia implementację na wybranych podstronach przez wtyczki, a Squarespace i Wix zapewniają opcje globalne dla całej witryny. Wybierz metodę odpowiadającą Twoim umiejętnościom technicznym i potrzebom.
Chociaż tagi noai i noimageai to ważny krok w kierunku ochrony twórców treści, mają one istotne ograniczenia. Po pierwsze, nie są oficjalnym standardem — stworzył je DeviantArt jako inicjatywę społecznościową, więc nie mają formalnej specyfikacji ani mechanizmu egzekwowania. Po drugie, przestrzeganie ich jest całkowicie dobrowolne. Dobrze zachowujące się crawlery głównych firm AI respektują te dyrektywy, ale źle zachowujące się boty i scraperzy mogą je ignorować bez konsekwencji. Po trzecie, brak standaryzacji oznacza zróżnicowaną adopcję. Niektóre mniejsze firmy AI czy organizacje badawcze mogą nawet nie znać tych dyrektyw, a co dopiero je wdrażać. Wreszcie, same meta tagi nie zatrzymają zdeterminowanych złych aktorów przed zeskrobaniem Twoich treści. Złośliwy crawler może całkowicie zignorować Twoje polecenia, dlatego kluczowe są dodatkowe warstwy ochrony.
Najskuteczniejsza strategia kontroli dostępu AI opiera się na wielu warstwach ochrony, a nie na pojedynczym rozwiązaniu. Oto porównanie różnych podejść:
| Metoda | Zakres | Skuteczność | Trudność |
|---|---|---|---|
| Meta tagi (noai) | Poziom strony | Średnia (dobrowolne stosowanie) | Łatwa |
| robots.txt | Cała witryna | Średnia (charakter doradczy) | Łatwa |
| Nagłówki X-Robots-Tag | Poziom serwera | Średnio-wysoka (wszystkie pliki) | Średnia |
| Reguły zapory sieciowej | Sieć | Wysoka (blokada infrastruktury) | Trudna |
| Whitelista IP | Sieć | Bardzo wysoka (tylko zweryfikowane źródła) | Trudna |
Kompleksowa strategia może obejmować: (1) wdrożenie meta tagów noai na wszystkich stronach, (2) dodanie reguł robots.txt blokujących znane crawlery treningowe AI, (3) ustawienie nagłówków X-Robots-Tag na poziomie serwera dla plików nie-HTML oraz (4) monitorowanie logów serwera w celu identyfikacji crawlerów ignorujących Twoje dyrektywy. Takie podejście znacząco utrudnia zadanie złym aktorom przy zachowaniu zgodności z dobrze zachowującymi się crawlerami.
Po wdrożeniu tagów noai i innych dyrektyw powinieneś zweryfikować, czy crawlery rzeczywiście ich przestrzegają. Najprostszą metodą jest sprawdzanie logów dostępu serwera pod kątem aktywności crawlerów. Na serwerach Apache możesz wyszukać określone crawlery:
grep "GPTBot\|ClaudeBot\|PerplexityBot" /var/log/apache2/access.log
Jeśli widzisz żądania od crawlerów, które zablokowałeś, oznacza to, że ignorują one Twoje dyrektywy. Dla NGINX sprawdź /var/log/nginx/access.log tą samą komendą grep. Dodatkowo, narzędzia takie jak Cloudflare Radar dają wgląd w ruch crawlerów AI na Twojej stronie, pokazując, które boty są najbardziej aktywne i jak zmienia się ich zachowanie w czasie. Regularny monitoring logów — przynajmniej raz w miesiącu — pozwala wykryć nowe crawlery i upewnić się, że Twoje środki ochronne działają zgodnie z założeniami.
Obecnie tagi noai i noimageai istnieją w szarej strefie: są szeroko rozpoznawalne i respektowane przez największe firmy AI, ale pozostają nieoficjalne i niestandaryzowane. Jednak rośnie presja na formalizację standardów. W3C (World Wide Web Consortium) i różne grupy branżowe prowadzą rozmowy o stworzeniu oficjalnych standardów kontroli dostępu AI, które nadałyby tym dyrektywom taką samą rangę jak robots.txt. Gdyby noai stało się oficjalnym standardem, jego przestrzeganie byłoby oczekiwanym zachowaniem branżowym, co znacząco zwiększyłoby skuteczność tych rozwiązań. Te działania odzwierciedlają szerszy zwrot branży technologicznej w stronę praw twórców treści i wyważenia rozwoju AI z ochroną wydawców. Im więcej wydawców wdraża te tagi i domaga się silniejszej ochrony, tym większa szansa na oficjalną standaryzację — co może sprawić, że kontrola dostępu AI stanie się równie fundamentem zarządzania siecią jak zasady indeksowania przez wyszukiwarki.
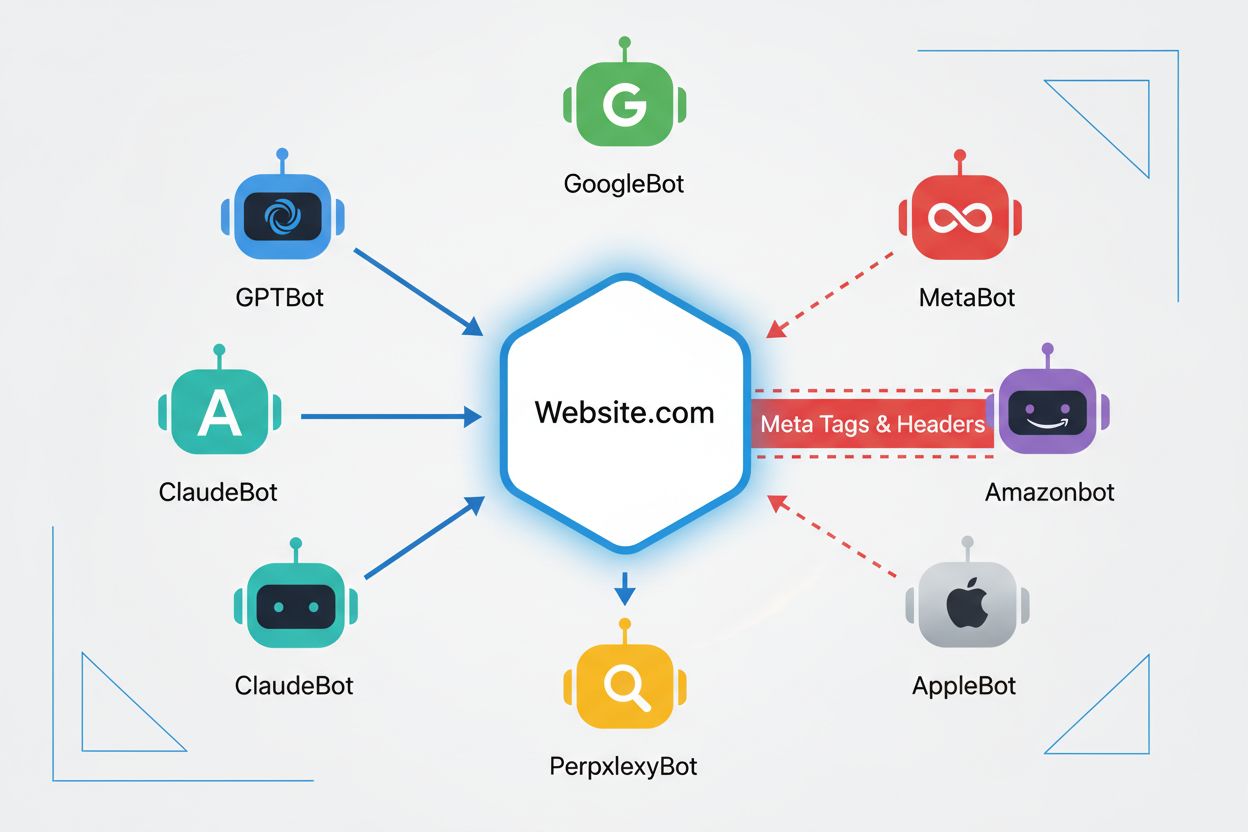
Meta tag noai to dyrektywa umieszczana w sekcji head HTML Twojej strony, która sygnalizuje crawlerom AI, że Twoje treści nie powinny być wykorzystywane do trenowania modeli sztucznej inteligencji. Działa poprzez przekazanie Twoich preferencji dobrze zachowującym się botom AI, jednak nie jest to oficjalny standard internetowy i niektóre crawlery mogą ją ignorować.
Nie, noai i noimageai nie są oficjalnymi standardami internetowymi. Zostały stworzone przez DeviantArt jako inicjatywa społecznościowa, aby pomóc twórcom chronić ich prace przed trenowaniem AI. Jednak główne firmy AI, takie jak OpenAI, Anthropic i inne, zaczęły respektować te dyrektywy w swoich crawlerach.
Główne crawlery AI, w tym GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity), Amazonbot (Amazon) i inne, respektują dyrektywę noai. Jednak niektóre mniejsze lub źle zachowujące się crawlery mogą ją ignorować, dlatego zalecane jest stosowanie wielowarstwowej ochrony.
Meta tagi umieszczane są w sekcji head HTML i dotyczą pojedynczych stron, podczas gdy nagłówki HTTP (X-Robots-Tag) ustawiane są na poziomie serwera i mogą działać globalnie lub dla określonych typów plików. Nagłówki sprawdzają się w przypadku plików niebędących HTML, takich jak PDF i obrazy, co czyni je bardziej wszechstronnymi w kompleksowej ochronie.
Tak, możesz wdrożyć tagi noai w WordPressie na kilka sposobów: dodając kod do pliku functions.php motywu, korzystając z wtyczki takiej jak WPCode lub przez narzędzia typu page builder (Divi, Elementor). Najczęściej używana jest metoda functions.php, która polega na dodaniu prostego hooka wstawiającego meta tag do nagłówka strony.
To zależy od Twoich celów biznesowych. Blokowanie crawlerów treningowych chroni Twoje treści przed wykorzystaniem do rozwoju modeli AI. Jednak blokowanie crawlerów wyszukiwarek, takich jak OAI-SearchBot, może ograniczyć Twoją widoczność w wynikach wyszukiwania opartych o AI i na platformach odkrywania treści. Wielu wydawców stosuje selektywne podejście, blokując crawlery treningowe, a pozwalając na działanie crawlerów wyszukiwarek.
Możesz sprawdzić swoje logi serwera pod kątem aktywności crawlerów, używając komend takich jak grep do wyszukiwania określonych user agentów botów. Narzędzia takie jak Cloudflare Radar pozwalają analizować wzorce ruchu crawlerów AI. Regularnie monitoruj logi, aby sprawdzić, czy zablokowane crawlery nadal uzyskują dostęp do Twoich treści, co oznaczałoby, że ignorują Twoje dyrektywy.
Jeśli crawlery ignorują Twoje meta tagi, wdroż dodatkowe warstwy ochrony, takie jak reguły robots.txt, nagłówki HTTP X-Robots-Tag oraz blokowanie na poziomie serwera przez .htaccess lub reguły zapory sieciowej. Dla mocniejszej weryfikacji zastosuj whitelistę IP, by zezwolić na ruch tylko z potwierdzonych adresów IP publikowanych przez główne firmy AI.
Użyj AmICited, aby śledzić, jak systemy AI, takie jak ChatGPT, Perplexity i Google AI Overviews, cytują i odnoszą się do Twoich treści na różnych platformach AI.
Dowiedz się, czym jest meta tag noai, jak działa w celu zapobiegania zbieraniu danych treningowych przez AI, jakie ma ograniczenia oraz jak wdrożyć go na swojej...
Dowiedz się, jak identyfikować i monitorować crawlery AI takie jak GPTBot, PerplexityBot i ClaudeBot w logach serwera. Poznaj ciągi user-agent, metody weryfikac...

Dowiedz się, czym są meta tagi NoAI, jak działają w zapobieganiu scrapowaniu przez AI, jak je wdrożyć i na ile są skuteczne w ochronie Twoich treści przed nieau...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.