
Jak zidentyfikować AI crawler’y w logach serwera
Dowiedz się, jak identyfikować i monitorować AI crawler’y, takie jak GPTBot, ClaudeBot i PerplexityBot, w logach serwera. Kompletny przewodnik z przykładami use...
8 min czytania

Dowiedz się, jak śledzić i monitorować aktywność AI crawlerów na swojej stronie za pomocą logów serwera, narzędzi i najlepszych praktyk. Rozpoznawaj GPTBot, ClaudeBot i inne boty AI.
Boty sztucznej inteligencji odpowiadają dziś za ponad 51% globalnego ruchu internetowego, a większość właścicieli stron nie ma pojęcia, że uzyskują dostęp do ich treści. Tradycyjne narzędzia analityczne, takie jak Google Analytics, całkowicie pomijają tych odwiedzających, ponieważ AI crawlery celowo nie wywołują śledzenia opartego na JavaScript. Logi serwera wychwytują 100% żądań botów, co czyni je jedynym wiarygodnym źródłem wiedzy o tym, jak systemy AI wchodzą w interakcję z Twoją stroną. Zrozumienie zachowania botów jest kluczowe dla widoczności w AI — jeśli AI crawlery nie mogą poprawnie uzyskać dostępu do Twoich treści, nie pojawią się one w odpowiedziach generowanych przez AI, gdy potencjalni klienci zadają istotne pytania.

AI crawlery zachowują się zupełnie inaczej niż tradycyjne boty wyszukiwarek. Googlebot podąża za mapą witryny XML, respektuje robots.txt i cyklicznie crawl’uje, by aktualizować indeksy, natomiast boty AI mogą ignorować standardowe protokoły, odwiedzać strony w celu trenowania modeli językowych i stosować niestandardowe identyfikatory. Najważniejsze AI crawlery to GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (bot treningowy Google AI), Bingbot-AI (Microsoft) oraz Applebot-Extended (Apple). Te boty skupiają się na treściach, które pomagają odpowiadać na pytania użytkowników, a nie tylko na sygnałach rankingowych, przez co ich wzorce crawl są często nieprzewidywalne i agresywne. Zrozumienie, które boty odwiedzają Twoją stronę i jak się zachowują, jest kluczowe dla optymalizacji strategii treści w erze AI.
| Typ crawlera | Typowe RPS | Zachowanie | Cel |
|---|---|---|---|
| Googlebot | 1-5 | Stały, respektuje crawl-delay | Indeksowanie wyszukiwarki |
| GPTBot | 5-50 | Burst, wysoka objętość | Trenowanie modeli AI |
| ClaudeBot | 3-30 | Ukierunkowane pobieranie | Trening AI |
| PerplexityBot | 2-20 | Selektywne crawl’owanie | AI search |
| Google-Extended | 5-40 | Agresywny, skupiony na AI | Trening AI Google |
Twój serwer WWW (Apache, Nginx lub IIS) automatycznie generuje logi rejestrujące każde żądanie do Twojej strony, w tym te od botów AI. Logi te zawierają kluczowe informacje: adresy IP pokazujące źródło żądania, user agenty identyfikujące oprogramowanie żądające, znaczniki czasu żądania, żądane adresy URL oraz kody odpowiedzi serwera. Dostęp do logów uzyskasz przez FTP lub SSH, logując się na serwer hostingowy i przechodząc do katalogu z logami (zwykle /var/log/apache2/ dla Apache lub /var/log/nginx/ dla Nginx). Każdy wpis logu ma standardowy format, który dokładnie pokazuje, co się wydarzyło podczas żądania.
Przykładowy wpis logu z wyjaśnieniem pól:
192.168.1.100 - - [01/Jan/2025:12:00:00 +0000] "GET /blog/ai-crawlers HTTP/1.1" 200 5432 "-" "Mozilla/5.0 (compatible; GPTBot/1.0; +https://openai.com/gptbot)"
Adres IP: 192.168.1.100
User Agent: GPTBot/1.0 (identyfikuje bota)
Znacznik czasu: 01/Jan/2025:12:00:00
Żądanie: GET /blog/ai-crawlers (odwiedzona strona)
Kod statusu: 200 (udane żądanie)
Rozmiar odpowiedzi: 5432 bajty
Najprostszym sposobem identyfikacji AI botów jest wyszukiwanie znanych user agentów w logach. Typowe sygnatury user agentów AI botów to: “GPTBot” dla crawlery OpenAI, “ClaudeBot” dla Anthropic, “PerplexityBot” dla Perplexity AI, “Google-Extended” dla bota treningowego Google oraz “Bingbot-AI” dla crawlery Microsoftu. Jednak niektóre boty AI nie identyfikują się jasno, przez co są trudniejsze do wykrycia prostym przeszukiwaniem user agentów. Możesz użyć narzędzi linii poleceń, takich jak grep, by szybko znaleźć konkretne boty: grep "GPTBot" access.log | wc -l policzy wszystkie żądania GPTBot, a grep "GPTBot" access.log > gptbot_requests.log utworzy osobny plik do analizy.
Znane user agenty AI botów, które warto monitorować:
Mozilla/5.0 (compatible; GPTBot/1.0; +https://openai.com/gptbot)Mozilla/5.0 (compatible; PerplexityBot/1.0; +https://www.perplexity.ai/bot)Mozilla/5.0 (compatible; Google-Extended; +https://www.google.com/bot.html)Mozilla/5.0 (compatible; Bingbot-AI/1.0)Dla botów, które nie identyfikują się jasno, wykorzystaj reputację IP, porównując adresy IP z opublikowanymi zakresami głównych firm AI.
Monitorowanie odpowiednich metryk pozwala zrozumieć intencje botów i zoptymalizować stronę. Tempo żądań (requests per second — RPS) pokazuje, jak agresywnie bot crawl’uje stronę — zdrowe crawlery utrzymują 1-5 RPS, podczas gdy agresywne AI boty mogą osiągać 50+ RPS. Zużycie zasobów ma znaczenie, bo jeden AI bot może zużyć więcej przepustowości w jeden dzień niż wszyscy użytkownicy razem. Rozkład kodów statusu HTTP pokazuje, jak serwer odpowiada na żądania botów: wysoki udział 200 (OK) oznacza skuteczny crawling, częste 404 sugerują, że bot podąża za błędnymi linkami lub szuka ukrytych zasobów. Częstotliwość crawlów i wzorce pokazują, czy boty są stałymi gośćmi, czy pojawiają się w krótkich zrywach, a śledzenie pochodzenia geograficznego ujawnia, czy żądania pochodzą z infrastruktury firmowej czy podejrzanych lokalizacji.
| Metryka | Co oznacza | Zdrowy zakres | Czerwone flagi |
|---|---|---|---|
| Żądania/godzinę | Intensywność aktywności | 100-1000 | 5000+ |
| Przepustowość (MB/h) | Zużycie zasobów | 50-500 | 5000+ |
| Kody 200 | Udane żądania | 70-90% | <50% |
| Kody 404 | Odwiedzone błędne linki | <10% | >30% |
| Częstotliwość crawl | Jak często bot odwiedza | Codziennie-tygodniowo | Kilka razy/godz. |
| Koncentracja geograficzna | Źródło żądań | Znane data center | ISP dla domów |
Do monitorowania aktywności AI crawlerów masz do dyspozycji różne opcje — od darmowych narzędzi linii poleceń po platformy klasy enterprise. Narzędzia jak grep, awk i sed są darmowe i potężne dla małych i średnich serwisów; pozwalają w kilka sekund wydobyć wzorce z logów. Komercyjne platformy, takie jak Botify, Conductor i seoClarity, oferują rozbudowane funkcje — automatyczną identyfikację botów, pulpity wizualizacyjne, korelację z rankingami i ruchem. Narzędzia do analizy logów, takie jak Screaming Frog Log File Analyser i OnCrawl, ułatwiają przetwarzanie dużych plików logów i identyfikację wzorców crawl. Platformy analityczne oparte o AI wykorzystują uczenie maszynowe do automatycznej identyfikacji nowych typów botów, przewidywania zachowań i wykrywania anomalii bez ręcznej konfiguracji.
| Narzędzie | Koszt | Funkcje | Najlepsze dla |
|---|---|---|---|
| grep/awk/sed | Darmowe | Wzorce w linii poleceń | Użytkownicy techniczni, małe strony |
| Botify | Enterprise | Śledzenie botów AI, korelacja z wydajnością | Duże strony, szczegółowa analiza |
| Conductor | Enterprise | Monitorowanie w czasie rzeczywistym, aktywność AI crawlerów | Zespoły SEO enterprise |
| seoClarity | Enterprise | Analiza logów, śledzenie botów AI | Kompleksowe platformy SEO |
| Screaming Frog | $199/rok | Analiza logów, symulacja crawl | Specjaliści SEO technicznego |
| OnCrawl | Enterprise | Analiza w chmurze, dane o wydajności | Średnie i duże firmy |
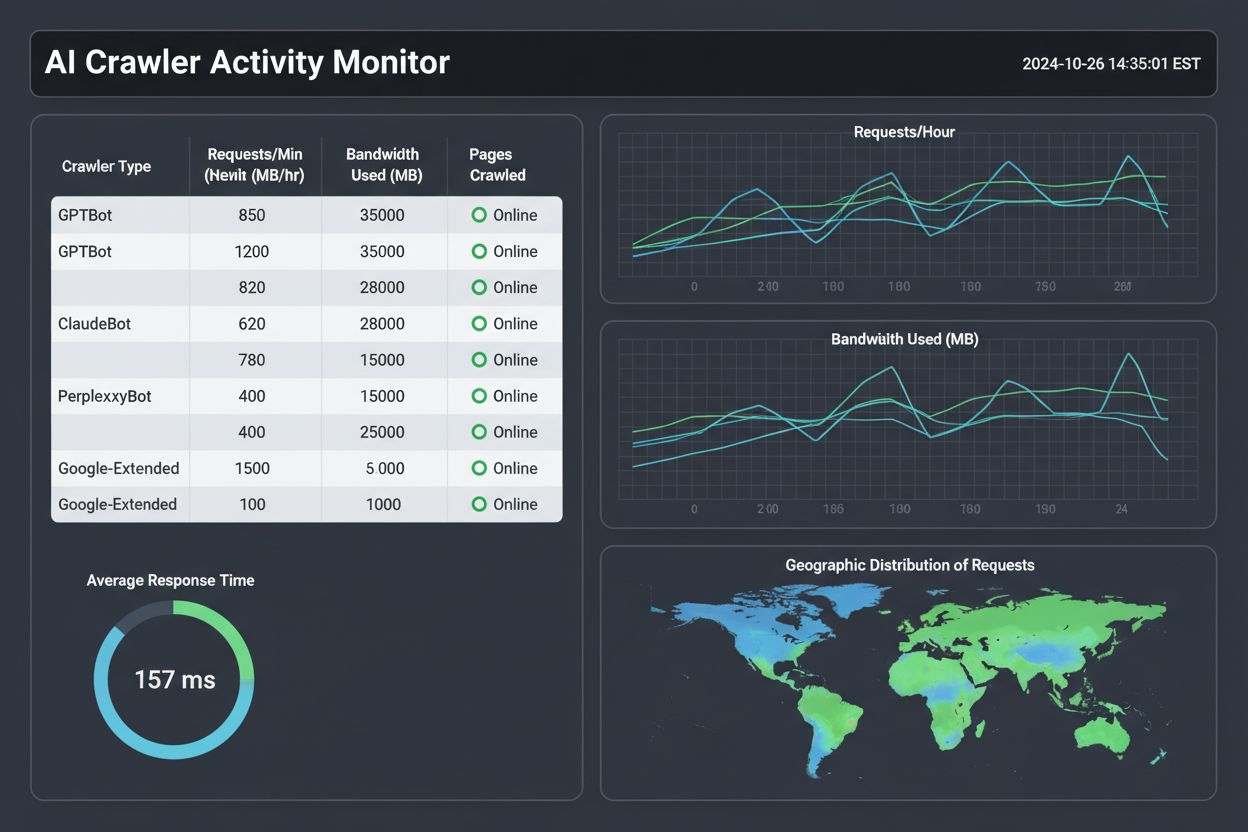
Pierwszym krokiem do skutecznego monitorowania jest ustalenie bazowych wzorców crawl. Zbierz co najmniej dwa tygodnie danych z logów (najlepiej miesiąc), aby zrozumieć normalne zachowanie botów, zanim wyciągniesz wnioski o anomaliach. Skonfiguruj automatyczne monitorowanie, tworząc skrypty analizujące logi i generujące raporty codziennie — możesz użyć Pythona z biblioteką pandas lub prostych skryptów bash. Ustaw alerty na nietypową aktywność, np. nagłe skoki liczby żądań, pojawienie się nowych typów botów lub próby dostępu do chronionych zasobów. Regularnie przeglądaj logi — cotygodniowo dla stron o dużym ruchu, comiesięcznie dla mniejszych, by wychwycić trendy.
Przykładowy prosty skrypt bash do ciągłego monitorowania:
#!/bin/bash
# Codzienny raport aktywności botów AI
LOG_FILE="/var/log/nginx/access.log"
REPORT_FILE="/reports/bot_activity_$(date +%Y%m%d).txt"
echo "=== Raport aktywności botów AI ===" > $REPORT_FILE
echo "Data: $(date)" >> $REPORT_FILE
echo "" >> $REPORT_FILE
echo "Żądania GPTBot:" >> $REPORT_FILE
grep "GPTBot" $LOG_FILE | wc -l >> $REPORT_FILE
echo "Żądania ClaudeBot:" >> $REPORT_FILE
grep "ClaudeBot" $LOG_FILE | wc -l >> $REPORT_FILE
echo "Żądania PerplexityBot:" >> $REPORT_FILE
grep "PerplexityBot" $LOG_FILE | wc -l >> $REPORT_FILE
# Wyślij alert, jeśli wykryto nietypową aktywność
GPTBOT_COUNT=$(grep "GPTBot" $LOG_FILE | wc -l)
if [ $GPTBOT_COUNT -gt 10000 ]; then
echo "ALERT: Wykryto nietypową aktywność GPTBot!" | mail -s "Bot Alert" admin@example.com
fi
Plik robots.txt to pierwsza linia obrony kontroli dostępu botów AI, a największe firmy AI respektują wytyczne dla swoich botów treningowych. Możesz tworzyć osobne reguły dla różnych botów — pozwalając np. Googlebotowi na pełny dostęp, a GPTBot ograniczyć do wybranych sekcji, lub ustawić crawl-delay, by ograniczyć tempo żądań. Limity żądań zabezpieczają infrastrukturę przed przeciążeniem, można je ustawić na kilku poziomach: na adres IP, user agenta i rodzaj zasobu. Jeśli bot przekroczy limit, zwróć kod 429 (Too Many Requests) z nagłówkiem Retry-After; dobrze wychowane boty uszanują to i zwolnią, a scrappery zignorują i będą wymagały blokady IP.
Przykłady robots.txt dla zarządzania dostępem AI crawlerów:
# Pozwól wyszukiwarkom, ogranicz boty treningowe AI
User-agent: Googlebot
Allow: /
User-agent: GPTBot
Disallow: /private/
Disallow: /proprietary-content/
Crawl-delay: 1
User-agent: ClaudeBot
Disallow: /admin/
Crawl-delay: 2
User-agent: *
Disallow: /
Powstający standard LLMs.txt daje dodatkową kontrolę, umożliwiając przekazywanie preferencji AI crawlerom w ustrukturyzowanej formie, podobnie jak robots.txt, ale przeznaczony specjalnie dla AI.
Uczynienie strony przyjazną dla AI crawlerów poprawia widoczność treści w odpowiedziach AI i zapewnia dostęp do najważniejszych podstron. Jasna struktura witryny z konsekwentną nawigacją, silnym linkowaniem wewnętrznym i logiczną organizacją treści pomaga botom AI zrozumieć i eksplorować zawartość sprawnie. Wdrażaj schema markup w formacie JSON-LD, by określić typ treści, kluczowe informacje, powiązania między treściami i dane firmy — to pozwala AI poprawnie interpretować i cytować Twoje treści. Zapewnij szybkie ładowanie strony, responsywny design, który działa dla każdego bota, oraz twórz wysokiej jakości, oryginalne treści, które AI będzie mogło cytować.
Najlepsze praktyki optymalizacji pod AI crawlery:
Wielu właścicieli stron popełnia krytyczne błędy przy zarządzaniu dostępem AI crawlerów, które podważają strategię widoczności w AI. Błędna identyfikacja ruchu botów przez poleganie wyłącznie na user agentach pomija zaawansowane boty podszywające się pod przeglądarki — analizuj także zachowanie: częstotliwość żądań, preferencje treści i lokalizację geograficzną. Niepełna analiza logów skupiona tylko na user agentach, bez uwzględnienia innych danych, przegapia ważną aktywność botów; kompleksowe śledzenie powinno obejmować częstotliwość żądań, preferencje treści, lokalizację oraz metryki wydajności. Zbyt restrykcyjne blokowanie przez robots.txt uniemożliwia legalnym AI botom dostęp do treści, które mogą zwiększyć widoczność w AI.
Najczęstsze błędy do uniknięcia:
Ekosystem botów AI rozwija się szybko i praktyki monitorowania muszą ewoluować wraz z nim. Boty AI stają się coraz bardziej zaawansowane — wykonują JavaScript, wypełniają formularze, nawigują po złożonej architekturze stron — przez co tradycyjne metody detekcji stają się mniej skuteczne. Oczekuj pojawienia się nowych standardów umożliwiających ustrukturyzowaną komunikację z botami AI, podobnie jak robots.txt, ale z bardziej precyzyjną kontrolą. Nadchodzą także zmiany prawne — niektóre jurysdykcje mogą nakładać obowiązek ujawniania źródeł danych do trenowania AI i rekompensaty dla twórców treści, co czyni logi potencjalnym dowodem prawnym aktywności botów. Wkrótce mogą pojawić się usługi pośredniczące (bot brokerzy), które automatycznie negocjują dostęp, pozwolenia i rozliczenia między twórcami a firmami AI.
Branża zmierza w stronę standaryzacji z nowymi protokołami i rozszerzeniami robots.txt, które zapewnią ustrukturyzowaną komunikację z botami AI. Coraz częściej analiza logów będzie wspierana przez uczenie maszynowe, automatycznie wykrywając nowe wzorce botów i sugerując zmiany polityk bez ingerencji człowieka. Strony, które już teraz opanują monitorowanie AI crawlerów, zyskają przewagę w kontroli swoich treści, infrastruktury i modeli biznesowych, gdy systemy AI staną się kluczowe dla przepływu informacji w sieci.
Chcesz monitorować, jak AI cytuje i referuje Twoją markę? AmICited.com uzupełnia analizę logów serwera o śledzenie rzeczywistych wzmianek i cytowań marki w odpowiedziach generowanych przez AI na ChatGPT, Perplexity, Google AI Overviews i innych platformach AI. Logi serwera pokazują, które boty crawl’ują Twoją stronę, a AmICited ujawnia prawdziwy wpływ — jak Twoje treści są wykorzystywane i cytowane w odpowiedziach AI. Zacznij śledzić swoją widoczność w AI już dziś.
AI crawlery to boty wykorzystywane przez firmy AI do trenowania modeli językowych i zasilania aplikacji AI. W przeciwieństwie do botów wyszukiwarki, które budują indeksy do rankingowania, AI crawlery skupiają się na zbieraniu różnorodnych treści do trenowania modeli AI. Często crawlą bardziej agresywnie i mogą ignorować tradycyjne zasady robots.txt.
Sprawdź logi serwera pod kątem znanych user agentów botów AI, takich jak 'GPTBot', 'ClaudeBot' czy 'PerplexityBot'. Użyj narzędzi linii poleceń, takich jak grep, aby wyszukać te identyfikatory. Możesz także skorzystać z narzędzi do analizy logów, takich jak Botify lub Conductor, które automatycznie identyfikują i kategoryzują aktywność AI crawlerów.
To zależy od celów biznesowych. Blokowanie AI crawlerów uniemożliwia pojawienie się Twoich treści w odpowiedziach generowanych przez AI, co może obniżyć widoczność. Jednak jeśli obawiasz się kradzieży treści lub zużycia zasobów, możesz ograniczyć dostęp za pomocą robots.txt. Rozważ udostępnienie treści publicznych, jednocześnie ograniczając dostęp do informacji zastrzeżonych.
Śledź tempo żądań (żądania na sekundę), zużycie przepustowości, kody statusu HTTP, częstotliwość crawlów oraz geograficzne pochodzenie żądań. Monitoruj, które strony boty odwiedzają najczęściej i jak długo przebywają na Twojej stronie. Te dane pokazują intencje botów i pomagają zoptymalizować witrynę.
Darmowe opcje to narzędzia linii poleceń (grep, awk) i open-source'owe analizatory logów. Komercyjne platformy, takie jak Botify, Conductor i seoClarity, oferują zaawansowane funkcje, w tym automatyczną identyfikację botów oraz korelację z wydajnością. Wybierz narzędzie w zależności od umiejętności technicznych i budżetu.
Zadbaj o szybkie ładowanie stron, stosuj dane strukturalne (schema markup), utrzymuj czytelną architekturę witryny i udostępniaj treści w łatwy sposób. Wdroż właściwe nagłówki HTTP i reguły robots.txt. Twórz wysokiej jakości, oryginalne treści, które systemy AI będą mogły poprawnie zacytować i zreferować.
Tak, agresywne AI crawlery mogą zużywać znaczną przepustowość i zasoby serwera, powodując spowolnienia lub wzrost kosztów hostingu. Monitoruj aktywność crawlerów i wdrażaj limity żądań, by zapobiec przeciążeniu. Używaj robots.txt i nagłówków HTTP, aby kontrolować dostęp w razie potrzeby.
LLMs.txt to powstający standard umożliwiający stronom internetowym przekazywanie preferencji AI crawlerom w ustrukturyzowany sposób. Chociaż nie wszystkie boty jeszcze go obsługują, wdrożenie go daje dodatkową kontrolę nad tym, jak systemy AI uzyskują dostęp do Twoich treści. Jest podobny do robots.txt, ale zaprojektowany specjalnie pod kątem AI.
Śledź, jak systemy AI cytują i referują Twoje treści w ChatGPT, Perplexity, Google AI Overviews i innych platformach AI. Poznaj swoją widoczność w AI i zoptymalizuj strategię treści.
Dowiedz się, jak identyfikować i monitorować AI crawler’y, takie jak GPTBot, ClaudeBot i PerplexityBot, w logach serwera. Kompletny przewodnik z przykładami use...

Dowiedz się, jak przeprowadzić audyt dostępu AI crawlerów do swojej strony. Odkryj, które boty widzą Twoje treści i napraw blokady ograniczające widoczność w Ch...

Dowiedz się, jak identyfikować i monitorować crawlery AI takie jak GPTBot, PerplexityBot i ClaudeBot w logach serwera. Poznaj ciągi user-agent, metody weryfikac...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.