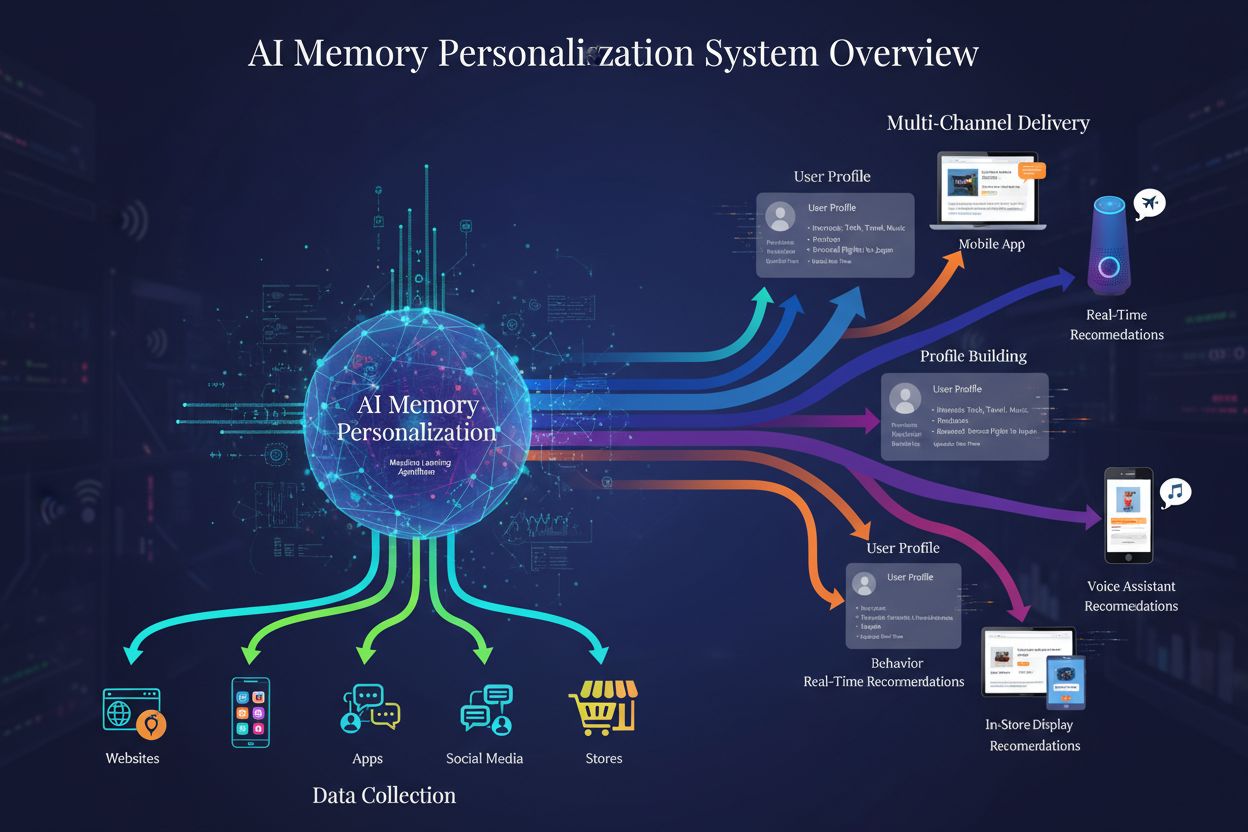
Personalizacja pamięci AI
Dowiedz się, jak systemy personalizacji pamięci AI budują szczegółowe profile użytkowników, aby dostarczać spersonalizowane rekomendacje marek. Poznaj technolog...
13 min czytania
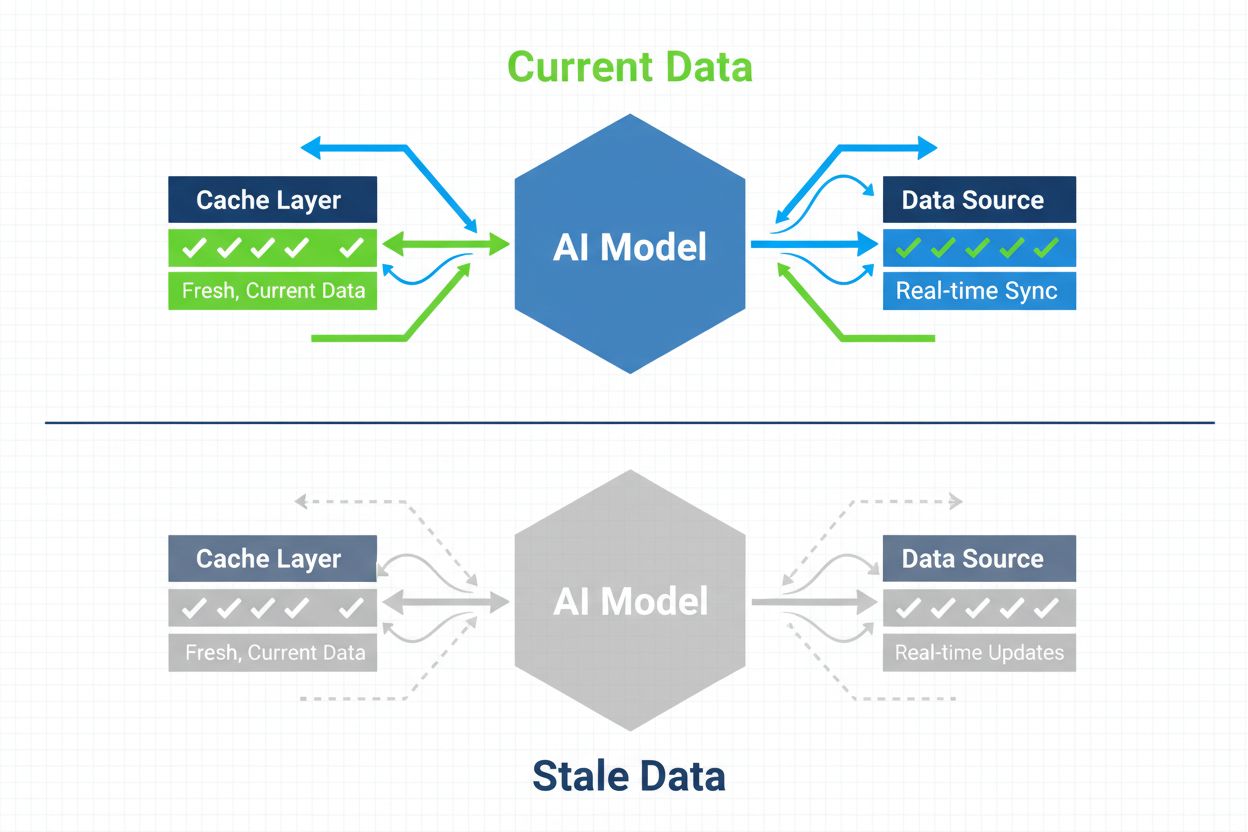
Strategie zapewniające, że systemy AI mają dostęp do aktualnych treści, a nie przestarzałych wersji z pamięci podręcznej. Zarządzanie pamięcią podręczną równoważy korzyści wydajnościowe z ryzykiem serwowania nieaktualnych informacji, wykorzystując strategie unieważniania i monitorowanie w celu utrzymania świeżości danych przy jednoczesnym ograniczaniu opóźnień i kosztów.
Strategie zapewniające, że systemy AI mają dostęp do aktualnych treści, a nie przestarzałych wersji z pamięci podręcznej. Zarządzanie pamięcią podręczną równoważy korzyści wydajnościowe z ryzykiem serwowania nieaktualnych informacji, wykorzystując strategie unieważniania i monitorowanie w celu utrzymania świeżości danych przy jednoczesnym ograniczaniu opóźnień i kosztów.
Zarządzanie pamięcią podręczną AI to systematyczne podejście do przechowywania i pobierania wcześniej obliczonych wyników, wyjść modeli lub odpowiedzi API w celu uniknięcia nadmiarowego przetwarzania i zmniejszenia opóźnień w systemach sztucznej inteligencji. Kluczowe wyzwanie polega na znalezieniu równowagi między korzyściami wydajnościowymi wynikającymi z użycia pamięci podręcznej a ryzykiem serwowania nieaktualnych lub przestarzałych informacji, które nie odzwierciedlają bieżącego stanu systemu ani potrzeb użytkownika. Jest to szczególnie istotne w dużych modelach językowych (LLM) i aplikacjach AI, gdzie koszty wnioskowania są znaczne, a czas odpowiedzi bezpośrednio wpływa na doświadczenie użytkownika. Systemy zarządzania pamięcią podręczną muszą inteligentnie określać, kiedy wyniki z pamięci podręcznej pozostają ważne, a kiedy konieczne jest ponowne przetwarzanie, co czyni to zagadnienie podstawowym elementem architektury wdrożeń AI na produkcji.
Wpływ skutecznego zarządzania pamięcią podręczną na wydajność systemów AI jest znaczący i mierzalny w wielu aspektach. Wdrożenie strategii buforowania może skrócić czas odpowiedzi o 80-90% dla powtarzających się zapytań, jednocześnie obniżając koszty API o 50-90%, w zależności od współczynnika trafień do pamięci podręcznej i architektury systemu. Poza wskaźnikami wydajności, zarządzanie pamięcią podręczną bezpośrednio wpływa na spójność dokładności i niezawodność systemu, ponieważ prawidłowo unieważniane buforowanie gwarantuje użytkownikom dostęp do aktualnych informacji, podczas gdy źle zarządzana pamięć podręczna prowadzi do problemów z przestarzałymi danymi. Te usprawnienia nabierają szczególnego znaczenia w miarę skalowania systemów AI do obsługi milionów żądań, gdzie łączny efekt wydajności pamięci podręcznej wprost przekłada się na koszty infrastruktury i satysfakcję użytkowników.
| Aspekt | Systemy z buforowaniem | Systemy bez buforowania |
|---|---|---|
| Czas odpowiedzi | 80-90% szybciej | Wartość bazowa |
| Koszty API | 50-90% redukcji | Pełny koszt |
| Dokładność | Spójna | Zmienna |
| Skalowalność | Wysoka | Ograniczona |
Strategie unieważniania pamięci podręcznej określają, jak i kiedy dane z pamięci podręcznej są odświeżane lub usuwane z magazynu, stanowiąc jedną z najważniejszych decyzji przy projektowaniu architektury pamięci podręcznej. Różne podejścia do unieważniania niosą ze sobą różne kompromisy między świeżością danych a wydajnością systemu:
Wybór strategii unieważniania zależy fundamentalnie od wymagań aplikacji: systemy stawiające na dokładność danych mogą zaakceptować większe opóźnienia dla agresywnego unieważniania, podczas gdy aplikacje krytyczne pod względem wydajności mogą tolerować lekko przestarzałe dane, by utrzymać odpowiedzi w czasie poniżej milisekundy.
Buforowanie promptów w dużych modelach językowych to wyspecjalizowana forma zarządzania pamięcią podręczną, polegająca na przechowywaniu pośrednich stanów modelu i sekwencji tokenów, aby uniknąć ponownego przetwarzania identycznych lub podobnych wejść. LLM obsługują dwa główne podejścia: buforowanie dokładne dopasowuje identyczne prompty znak w znak, podczas gdy buforowanie semantyczne identyfikuje funkcjonalnie równoważne prompty mimo różnic w sformułowaniu. OpenAI implementuje automatyczne buforowanie promptów z 50% redukcją kosztów dla buforowanych tokenów, wymagając minimalnych segmentów promptów o długości 1024 tokenów, aby aktywować korzyści z buforowania. Anthropic oferuje ręczne buforowanie promptów z bardziej agresywną 90% redukcją kosztów, ale wymaga od deweloperów jawnego zarządzania kluczami i czasem buforowania, z minimalnymi wymaganiami od 1024 do 2048 tokenów w zależności od konfiguracji modelu. Czas buforowania w systemach LLM zwykle waha się od kilku minut do kilku godzin, równoważąc oszczędności obliczeniowe wynikające z ponownego użycia stanów z ryzykiem serwowania przestarzałych wyników modelu w aplikacjach wrażliwych na czas.
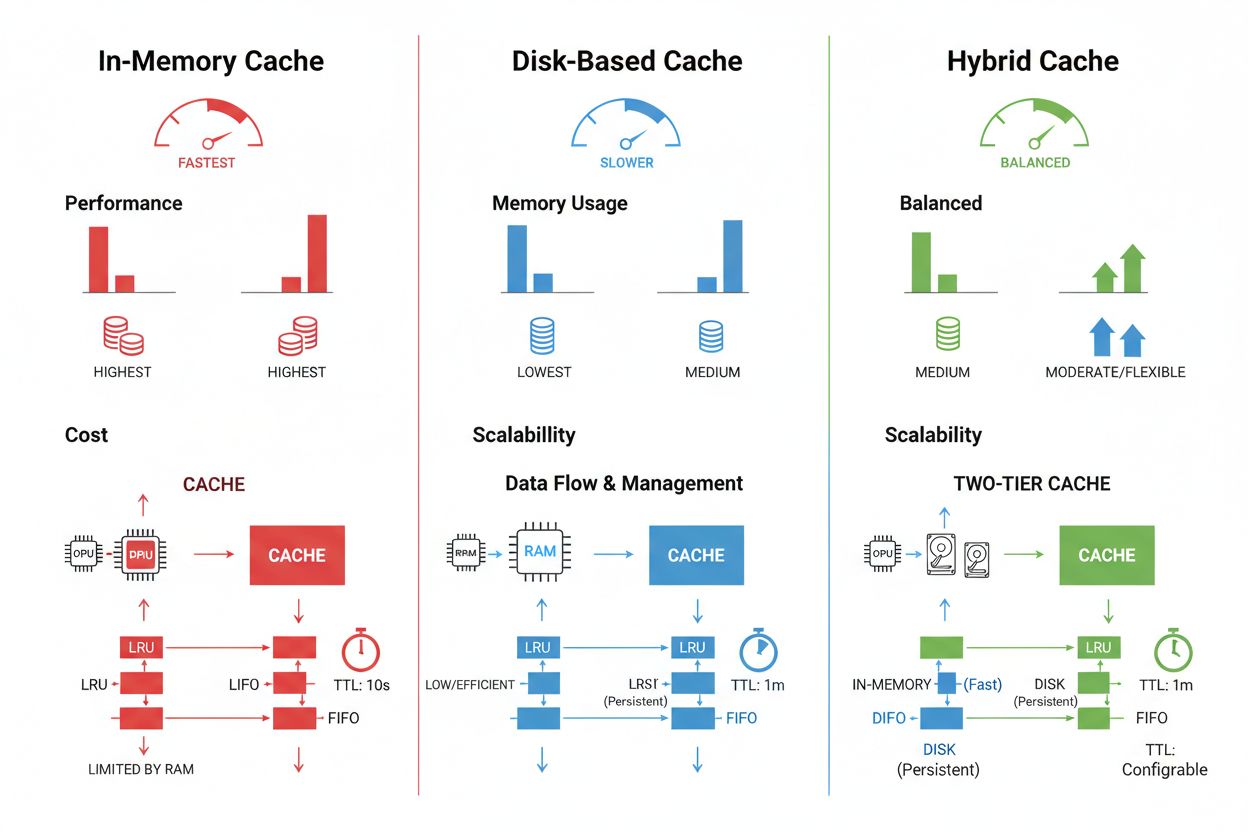
Techniki przechowywania i zarządzania pamięcią podręczną różnią się znacząco w zależności od wymagań wydajnościowych, wolumenu danych oraz ograniczeń infrastruktury — każda z metod niesie ze sobą określone zalety i ograniczenia. Rozwiązania typu pamięć operacyjna, jak Redis, zapewniają dostęp na poziomie mikrosekundowym, idealny dla częstych zapytań, ale zużywają dużo RAM i wymagają starannego zarządzania pamięcią. Buforowanie na dysku pozwala przechowywać większe zbiory danych i przetrwać restart systemu, ale wprowadza opóźnienia liczone w milisekundach w porównaniu do rozwiązań in-memory. Podejścia hybrydowe łączą oba typy magazynowania, kierując często używane dane do pamięci, a większe zbiory przechowując na dysku:
| Typ pamięci | Najlepsze zastosowanie | Wydajność | Zużycie pamięci |
|---|---|---|---|
| In-memory (Redis) | Częste zapytania | Najszybsza | Wyższe |
| Dyskowa | Duże zbiory danych | Umiarkowana | Niższe |
| Hybrydowa | Różnorodne obciążenia | Zrównoważona | Zrównoważone |
Skuteczne zarządzanie pamięcią podręczną wymaga odpowiedniej konfiguracji TTL, odpowiadającej zmienności danych — krótkie TTL (minuty) dla szybko zmieniających się danych, dłuższe (godziny/dni) dla treści stabilnych — w połączeniu z ciągłym monitorowaniem współczynników trafień, wzorców usuwania oraz wykorzystania pamięci w celu identyfikacji możliwości optymalizacji.
Rzeczywiste aplikacje AI pokazują zarówno transformacyjny potencjał, jak i złożoność operacyjną zarządzania pamięcią podręczną w różnych przypadkach użycia. Chatboty obsługi klienta wykorzystują buforowanie, by dostarczać spójne odpowiedzi na często zadawane pytania i jednocześnie obniżać koszty wnioskowania o 60-70%, umożliwiając efektywne kosztowo skalowanie do tysięcy równoczesnych użytkowników. Asystenci programistyczni buforują popularne wzorce kodu i fragmenty dokumentacji, pozwalając deweloperom na otrzymywanie podpowiedzi autouzupełniania z opóźnieniem poniżej 100 ms nawet w szczycie obciążenia. Systemy przetwarzania dokumentów buforują embeddingi i reprezentacje semantyczne często analizowanych dokumentów, znacząco przyspieszając wyszukiwanie podobieństw i zadania klasyfikacyjne. Zarządzanie pamięcią podręczną w produkcji wiąże się jednak z wieloma wyzwaniami: złożoność unieważniania rośnie wykładniczo w systemach rozproszonych, gdzie spójność pamięci podręcznej musi być utrzymywana między wieloma serwerami, ograniczenia zasobów wymuszają trudne kompromisy między rozmiarem pamięci a jej pokryciem, pojawiają się zagrożenia bezpieczeństwa, gdy buforowane dane zawierają informacje wrażliwe wymagające szyfrowania i kontroli dostępu, a koordynacja aktualizacji pamięci podręcznej w mikroserwisach prowadzi do potencjalnych warunków wyścigu i niespójności danych. Kompleksowe rozwiązania monitorujące śledzące świeżość pamięci podręcznej, współczynniki trafień oraz zdarzenia unieważnień stają się niezbędne dla utrzymania niezawodności systemu i identyfikowania momentów, gdy strategie buforowania wymagają dostosowania do zmieniających się wzorców danych i zachowań użytkowników.
Unieważnianie pamięci podręcznej usuwa lub aktualizuje przestarzałe dane, gdy nastąpią zmiany, zapewniając natychmiastową świeżość, ale wymagając wyzwalaczy zdarzeń. Wygaśnięcie pamięci podręcznej ustala limit czasu (TTL), przez jaki dane pozostają w pamięci podręcznej, oferując prostszą implementację, lecz mogąc serwować nieaktualne dane, jeśli TTL jest zbyt długi. Wiele systemów łączy oba podejścia dla optymalnej wydajności.
Efektywne zarządzanie pamięcią podręczną może obniżyć koszty API o 50-90% w zależności od współczynnika trafień do pamięci podręcznej i architektury systemu. Buforowanie promptów w OpenAI oferuje 50% redukcji kosztów dla buforowanych tokenów, podczas gdy Anthropic zapewnia do 90% redukcji. Faktyczne oszczędności zależą od wzorców zapytań i tego, ile danych można skutecznie buforować.
Buforowanie promptów przechowuje pośrednie stany modelu i sekwencje tokenów, aby uniknąć ponownego przetwarzania identycznych lub podobnych wejść w dużych modelach językowych. Obsługuje buforowanie dokładne (dopasowania znak w znak) i semantyczne (funkcjonalnie równoważne prompty o różnym sformułowaniu). Zmniejsza to opóźnienie o 80% i koszty o 50-90% dla powtarzających się zapytań.
Podstawowe strategie to: Wygaśnięcie oparte na czasie (TTL) do automatycznego usuwania po określonym czasie, unieważnianie oparte na zdarzeniach dla natychmiastowych aktualizacji przy zmianie danych, unieważnianie semantyczne dla podobnych zapytań na podstawie znaczenia oraz podejścia hybrydowe łączące różne strategie. Wybór zależy od zmienności danych i wymagań dotyczących świeżości.
Buforowanie w pamięci (np. Redis) zapewnia dostęp z prędkością mikrosekundową, idealne do częstych zapytań, ale zużywa znaczną ilość RAM. Buforowanie na dysku pozwala obsłużyć większe zbiory danych i utrzymuje je po restartach, ale wprowadza opóźnienia rzędu milisekund. Podejścia hybrydowe łączą oba, kierując często używane dane do pamięci, a większe zbiory przechowując na dysku.
TTL to licznik czasu określający, jak długo dane w pamięci podręcznej pozostają ważne przed wygaśnięciem. Krótkie TTL (minuty) są odpowiednie dla szybko zmieniających się danych, a dłuższe (godziny/dni) dla stabilnych treści. Prawidłowa konfiguracja TTL równoważy świeżość danych z niepotrzebnym odświeżaniem pamięci i obciążeniem serwera.
Efektywne zarządzanie pamięcią podręczną pozwala systemom AI obsługiwać znacznie więcej żądań bez proporcjonalnej rozbudowy infrastruktury. Dzięki zmniejszeniu obciążenia obliczeniowego na żądanie, systemy mogą obsługiwać miliony użytkowników bardziej ekonomicznie. Wskaźniki trafień do pamięci podręcznej bezpośrednio determinują koszty infrastruktury i satysfakcję użytkowników w środowiskach produkcyjnych.
Buforowanie danych wrażliwych generuje ryzyko bezpieczeństwa, jeśli nie są one odpowiednio szyfrowane i kontrolowane pod względem dostępu. Zagrożenia obejmują nieautoryzowany dostęp do danych z pamięci podręcznej, ujawnienie danych podczas unieważniania oraz przypadkowe buforowanie poufnych treści. Kompleksowe szyfrowanie, kontrola dostępu i monitorowanie są niezbędne do ochrony buforowanych danych wrażliwych.
AmICited śledzi, jak systemy AI odnoszą się do Twojej marki i zapewnia aktualność Twoich treści w pamięciach podręcznych AI. Uzyskaj wgląd w zarządzanie pamięcią podręczną AI i świeżość treści w GPT, Perplexity i Google AI Overviews.
Dowiedz się, jak systemy personalizacji pamięci AI budują szczegółowe profile użytkowników, aby dostarczać spersonalizowane rekomendacje marek. Poznaj technolog...

Dowiedz się, jak zarządzać dostępem robotów AI do treści Twojej strony internetowej. Poznaj różnicę między robotami do trenowania a robotami wyszukiwarek AI, wp...

Odkryj, jak systemy pamięci AI tworzą trwałe relacje z marką dzięki powracającym, spersonalizowanym rekomendacjom, które ewoluują w czasie. Dowiedz się więcej o...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.