Ekosystem Platform AI
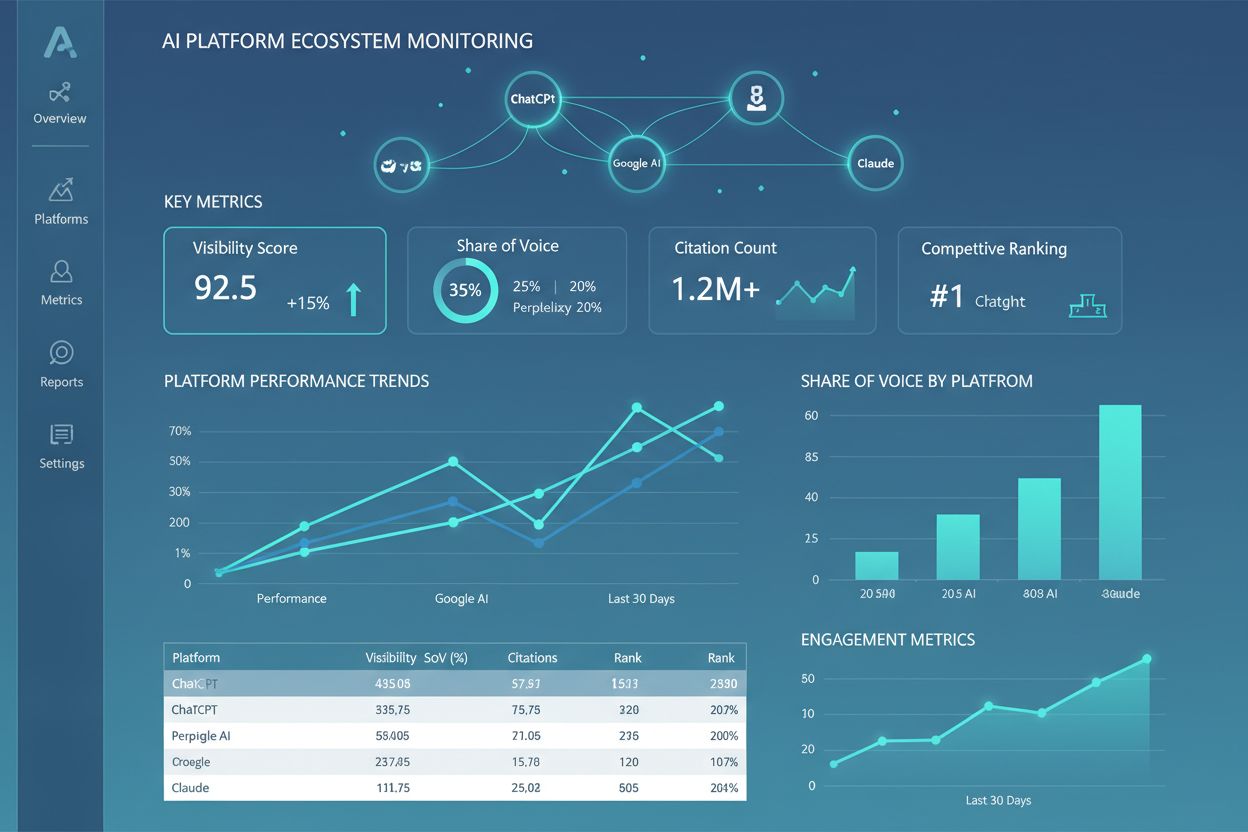
Dowiedz się, czym jest Ekosystem Platform AI, jak współdziałające systemy AI współpracują i dlaczego zarządzanie obecnością marki na wielu platformach AI ma klu...
5 min czytania

Izolowane środowiska typu sandbox zaprojektowane do walidacji, ewaluacji i debugowania modeli oraz aplikacji sztucznej inteligencji przed wdrożeniem do produkcji. Te kontrolowane przestrzenie umożliwiają testowanie wydajności treści AI na różnych platformach, pomiar metryk oraz zapewnienie niezawodności bez wpływu na systemy produkcyjne i ujawniania wrażliwych danych.
Izolowane środowiska typu sandbox zaprojektowane do walidacji, ewaluacji i debugowania modeli oraz aplikacji sztucznej inteligencji przed wdrożeniem do produkcji. Te kontrolowane przestrzenie umożliwiają testowanie wydajności treści AI na różnych platformach, pomiar metryk oraz zapewnienie niezawodności bez wpływu na systemy produkcyjne i ujawniania wrażliwych danych.
Środowisko testowe AI to kontrolowana, izolowana przestrzeń obliczeniowa zaprojektowana do walidacji, ewaluacji i debugowania modeli oraz aplikacji sztucznej inteligencji przed wdrożeniem do systemów produkcyjnych. Służy jako sandbox, w którym deweloperzy, data scientistci i zespoły QA mogą bezpiecznie uruchamiać modele AI, testować różne konfiguracje oraz mierzyć wydajność względem zdefiniowanych metryk bez wpływu na działające systemy i bez ujawniania wrażliwych danych. Środowiska te replikują warunki produkcyjne przy zachowaniu pełnej izolacji, co pozwala zespołom identyfikować problemy, optymalizować zachowanie modeli i zapewnić niezawodność w różnych scenariuszach. Środowisko testowe stanowi kluczowy punkt kontrolny jakości w cyklu rozwoju AI, łącząc etap prototypowania z wdrożeniem na poziomie enterprise.

Kompleksowe środowisko testowe AI składa się z kilku powiązanych ze sobą warstw technicznych, które razem zapewniają pełne możliwości testowe. Warstwa wykonawcza modeli odpowiada za inferencję i obliczenia, obsługując wiele frameworków (PyTorch, TensorFlow, ONNX) i typów modeli (LLM, computer vision, szeregów czasowych). Warstwa zarządzania danymi obsługuje zbiory testowe, fiksy i generowanie danych syntetycznych przy zachowaniu izolacji i zgodności. Framework ewaluacyjny obejmuje silniki metryk, biblioteki asercji oraz systemy oceniania, mierzące wyniki modeli względem oczekiwanych rezultatów. Warstwa monitoringu i logowania rejestruje ślady wykonania, metryki wydajności, opóźnienia i logi błędów do analizy po teście. Warstwa orkiestracji zarządza przepływem testów, równoległym wykonywaniem, alokacją zasobów i provisionowaniem środowisk. Poniżej znajduje się porównanie kluczowych komponentów architektonicznych różnych typów środowisk testowych:
| Komponent | Testowanie LLM | Computer Vision | Szeregi czasowe | Multi-modalne |
|---|---|---|---|---|
| Uruchamianie modelu | Inferencja Transformer | Inferencja akcelerowana GPU | Przetwarzanie sekwencyjne | Wykonanie hybrydowe |
| Format danych | Tekst/tokeny | Obrazy/tensory | Sekwencje numeryczne | Media mieszane |
| Metryki ewaluacyjne | Podobieństwo semantyczne, halucynacje | Dokładność, IoU, F1-score | RMSE, MAE, MAPE | Wyrównanie między modalnościami |
| Wymagania dot. opóźnień | 100-500ms typowo | 50-200ms typowo | <100ms typowo | 200-1000ms typowo |
| Metoda izolacji | Kontener/VM | Kontener/VM | Kontener/VM | Firecracker microVM |
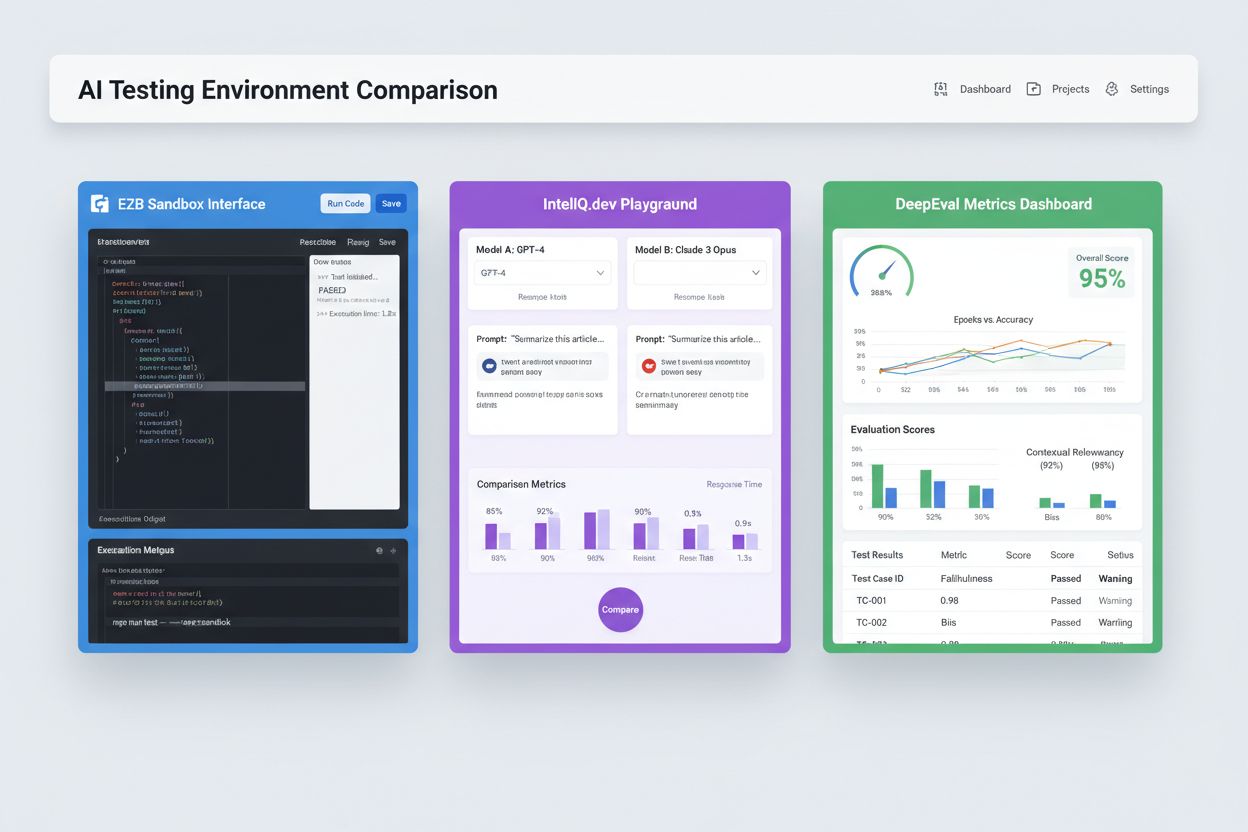
Nowoczesne środowiska testowe AI muszą obsługiwać heterogeniczne ekosystemy modeli, umożliwiając testowanie aplikacji na różnych dostawcach LLM, frameworkach i środowiskach wdrożeniowych jednocześnie. Testy wieloplatformowe pozwalają organizacjom porównywać wyniki modeli GPT-4 od OpenAI, Claude od Anthropic, Mistral i open-source’owych alternatyw jak Llama w tym samym środowisku testowym, ułatwiając świadome decyzje dotyczące wyboru modelu. Platformy takie jak E2B oferują izolowane sandboxy wykonujące kod generowany przez dowolny LLM, obsługując Python, JavaScript, Ruby i C++ z pełnym dostępem do systemu plików, terminalem i instalacją pakietów. IntelIQ.dev umożliwia bezpośrednie porównywanie wielu modeli AI w jednolitym interfejsie, pozwalając testować prompt’y z ograniczeniami oraz szablony zgodne z politykami na różnych dostawcach. Środowiska testowe muszą obsługiwać:
Środowiska testowe AI służą różnym potrzebom organizacji w obszarach rozwoju, kontroli jakości i zgodności. Zespoły deweloperskie wykorzystują środowiska testowe do walidacji działania modeli podczas iteracyjnego rozwoju, testowania wariantów promptów, tuningu parametrów czy debugowania nieoczekiwanych wyników przed integracją. Zespoły data science oceniają w nich wydajność modeli na zbiorach walidacyjnych, porównują architektury i mierzą metryki takie jak dokładność, precyzja, recall i F1-score. Monitoring produkcyjny obejmuje ciągłe testy wdrożonych modeli względem bazowych metryk, wykrywanie degradacji wydajności i uruchamianie pipeline’ów retrainingu przy przekroczeniu progów jakości. Zespoły ds. zgodności i bezpieczeństwa wykorzystują środowiska testowe do walidacji zgodności modeli z regulacjami, wykrywania biasu i właściwej obsługi danych wrażliwych. Przykłady zastosowań enterprise:
Ekosystem testowania AI obejmuje specjalistyczne platformy dostosowane do różnych scenariuszy i skali organizacji. DeepEval to open-source’owy framework ewaluacji LLM oferujący ponad 50 metryk naukowych, w tym poprawność odpowiedzi, podobieństwo semantyczne, wykrywanie halucynacji i toksyczności, z natywną integracją z Pytest do pipeline’ów CI/CD. LangSmith (od LangChain) zapewnia kompleksową obserwowalność, ewaluację i wdrażanie, z wbudowanym tracingiem, wersjonowaniem promptów i zarządzaniem zbiorami danych dla aplikacji LLM. E2B oferuje bezpieczne, izolowane sandboxy oparte o Firecracker microVMs, obsługujące wykonanie kodu z czasem uruchomienia poniżej 200 ms, sesjami do 24h i integracją z głównymi dostawcami LLM. IntelIQ.dev stawia na testy prywatności, oferując szyfrowanie end-to-end, kontrolę dostępu opartą na rolach i wsparcie dla wielu modeli AI, w tym GPT-4, Claude i alternatyw open-source. Porównanie kluczowych funkcji:
| Narzędzie | Główne zastosowanie | Metryki | Integracja CI/CD | Wsparcie wielu modeli | Model płatności |
|---|---|---|---|---|---|
| DeepEval | Ewaluacja LLM | 50+ metryk | Natywnie z Pytest | Ograniczone | Open-source + chmura |
| LangSmith | Obserwowalność i ewaluacja | Metryki własne | Integracja przez API | Ekosystem LangChain | Freemium + enterprise |
| E2B | Wykonanie kodu | Metryki wydajności | GitHub Actions | Wszystkie LLM | Opłata za użycie + enterprise |
| IntelIQ.dev | Testy prywatności | Metryki własne | Kreator workflow | GPT-4, Claude, Mistral | Model subskrypcyjny |
Środowiska testowe AI klasy enterprise muszą wdrażać rygorystyczne mechanizmy bezpieczeństwa chroniące dane wrażliwe, zapewniające zgodność regulacyjną i zapobiegające nieautoryzowanemu dostępowi. Izolacja danych wymaga, by dane testowe nigdy nie trafiały do zewnętrznych API czy usług trzecich; platformy jak E2B używają Firecracker microVMs, zapewniając pełną izolację procesów bez współdzielonego kernela. Standardy szyfrowania powinny obejmować szyfrowanie end-to-end danych w spoczynku i w przesyle oraz wsparcie dla wymagań HIPAA, SOC 2 Type 2 i GDPR. Kontrole dostępu muszą egzekwować uprawnienia oparte na rolach, logowanie audytowe i workflowy zatwierdzania scenariuszy testowych z danymi wrażliwymi. Do dobrych praktyk należą: utrzymywanie oddzielnych zbiorów testowych wolnych od danych produkcyjnych, maskowanie danych osobowych (PII), generowanie danych syntetycznych dla realistycznych testów bez ryzyka naruszenia prywatności, regularne audyty bezpieczeństwa infrastruktury testowej oraz dokumentowanie wszystkich wyników dla celów zgodności. Organizacje powinny także wdrażać mechanizmy wykrywania biasu do identyfikacji dyskryminujących zachowań modeli, używać narzędzi interpretowalności jak SHAP czy LIME do analizy decyzji modeli oraz rejestrować logi decyzyjne wyjaśniające uzyskiwane wyniki dla rozliczalności regulacyjnej.
Środowiska testowe AI muszą bezproblemowo integrować się z istniejącymi pipeline’ami ciągłej integracji i wdrażania (CI/CD), by umożliwiać automatyczne bramki jakości i szybkie cykle iteracyjne. Natywna integracja z CI/CD pozwala uruchamiać testy automatycznie przy commitach, pull requestach czy według harmonogramu, korzystając z platform takich jak GitHub Actions, GitLab CI czy Jenkins. Integracja DeepEval z Pytest umożliwia deweloperom pisanie przypadków testowych w Pythonie, które wykonują się razem z klasycznymi testami jednostkowymi w pipeline. Automatyczna ewaluacja pozwala mierzyć metryki wydajności modeli, porównywać wyniki z wersjami bazowymi i blokować wdrożenia, jeśli progi jakości nie są spełnione. Zarządzanie artefaktami obejmuje przechowywanie zbiorów testowych, checkpointów modeli i wyników ewaluacji w systemach kontroli wersji lub repozytoriach artefaktów dla powtarzalności i audytów. Typowe wzorce integracji to:
Krajobraz środowisk testowych AI szybko się rozwija, odpowiadając na wyzwania związane ze wzrostem złożoności modeli, skalą i różnorodnością. Testowanie agentowe zyskuje na znaczeniu wraz z przejściem AI od pojedynczych modeli do wieloetapowych workflow, gdzie agenci korzystają z narzędzi, podejmują decyzje i integrują się z systemami zewnętrznymi—co wymaga nowych frameworków ewaluacyjnych mierzących kompletność zadania, bezpieczeństwo i niezawodność. Rozproszona ewaluacja umożliwia testy na dużą skalę poprzez uruchamianie tysięcy instancji testowych w chmurze, kluczowe dla reinforcement learning i treningu dużych modeli. Monitoring w czasie rzeczywistym przekształca się z ewaluacji wsadowej w ciągłe, produkcyjne testowanie wykrywające degradację wydajności, dryf danych i pojawiające się biasy w systemach na żywo. Platformy obserwowalności takie jak AmICited stają się kluczowymi narzędziami do kompleksowego monitoringu i wglądu w AI, oferując centralne dashboardy śledzące wydajność modeli, wzorce użycia i metryki jakości dla całego portfolio AI. Przyszłe środowiska testowe będą coraz częściej wdrażać automatyczną naprawę, gdzie systemy nie tylko wykrywają problemy, lecz także automatycznie uruchamiają pipeline’y retrainingu lub aktualizacje modeli, oraz ewaluację cross-modalną, obsługującą jednoczesne testowanie modeli tekstowych, obrazowych, dźwiękowych i wideo w jednolitych frameworkach.
Środowisko testowe AI to izolowany sandbox, w którym można bezpiecznie testować modele, prompt'y i konfiguracje bez wpływu na produkcyjne systemy i użytkowników. Wdrożenie produkcyjne to środowisko na żywo, w którym modele obsługują prawdziwych użytkowników. Środowiska testowe pozwalają wychwycić problemy, zoptymalizować wydajność i zweryfikować zmiany przed wdrożeniem do produkcji, co zmniejsza ryzyko i zapewnia jakość.
Tak, nowoczesne środowiska testowe AI obsługują testowanie wielu modeli jednocześnie. Platformy takie jak E2B, IntelIQ.dev i DeepEval umożliwiają testowanie tego samego promptu lub wejścia na różnych dostawcach LLM (OpenAI, Anthropic, Mistral itd.) jednocześnie, co pozwala bezpośrednio porównać wyniki i metryki wydajności.
Środowiska testowe AI klasy enterprise wdrażają wiele warstw zabezpieczeń, w tym izolację danych (containerization lub microVM), szyfrowanie end-to-end, kontrolę dostępu opartą na rolach, logowanie audytowe oraz certyfikaty zgodności (SOC 2, GDPR, HIPAA). Dane nigdy nie opuszczają izolowanego środowiska, chyba że zostaną jawnie wyeksportowane, co chroni wrażliwe informacje.
Środowiska testowe umożliwiają zgodność poprzez zapewnienie ścieżek audytu wszystkich ewaluacji modeli, wspierają maskowanie danych i generowanie danych syntetycznych, egzekwują kontrolę dostępu i utrzymują pełną izolację danych testowych od systemów produkcyjnych. Ta dokumentacja i kontrola pomagają organizacjom spełniać wymagania regulacyjne, takie jak GDPR, HIPAA i SOC 2.
Kluczowe metryki zależą od zastosowania: dla LLM-ów monitoruj dokładność, podobieństwo semantyczne, halucynacje i opóźnienia; dla systemów RAG mierz precyzję/pełność kontekstu i wierność; dla modeli klasyfikacyjnych śledź precyzję, recall i F1-score; dla wszystkich modeli analizuj degradację wydajności w czasie oraz wskaźniki biasu.
Koszty zależą od platformy: DeepEval jest open-source i darmowy; LangSmith oferuje darmową wersję oraz płatne plany od 39$/miesiąc; E2B stosuje model opłat zależny od zużycia czasu pracy sandboxa; IntelIQ.dev oferuje subskrypcje. Wiele platform posiada także plany enterprise dla wdrożeń na dużą skalę.
Tak, większość nowoczesnych środowisk testowych obsługuje integrację z CI/CD. DeepEval integruje się natywnie z Pytest, E2B współpracuje z GitHub Actions i GitLab CI, a LangSmith zapewnia integrację przez API. Umożliwia to automatyczne testowanie przy każdym commicie i egzekwowanie kontroli jakości przed wdrożeniem.
Testowanie end-to-end traktuje całą aplikację AI jako czarną skrzynkę, testując końcowy wynik względem oczekiwanych rezultatów. Testowanie na poziomie komponentu ocenia osobno poszczególne elementy (wywołania LLM, retrievery, użycie narzędzi) z użyciem śledzenia i instrumentacji. Testowanie komponentowe daje głębszy wgląd w miejsce występowania problemów, podczas gdy end-to-end weryfikuje zachowanie całego systemu.
AmICited śledzi, jak systemy AI odnoszą się do Twojej marki i treści w ChatGPT, Claude, Perplexity i Google AI. Uzyskaj wgląd w czasie rzeczywistym w obecność AI dzięki kompleksowemu monitoringowi i analizom.
Dowiedz się, czym jest Ekosystem Platform AI, jak współdziałające systemy AI współpracują i dlaczego zarządzanie obecnością marki na wielu platformach AI ma klu...
Dowiedz się, czym jest Centrum Doskonałości Widoczności AI, jakie są jego kluczowe obowiązki, możliwości monitorowania oraz jak umożliwia organizacjom utrzymani...

Opanuj testy A/B dla widoczności AI dzięki naszemu kompleksowemu przewodnikowi. Poznaj eksperymenty GEO, metodologię, najlepsze praktyki oraz studia przypadków ...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.