
Czym są AI Crawlers: GPTBot, ClaudeBot i inni
Dowiedz się, jak działają AI crawlers takie jak GPTBot i ClaudeBot, czym różnią się od tradycyjnych crawlerów wyszukiwarek oraz jak zoptymalizować swoją stronę ...
12 min czytania

Web crawler Amazona używany do ulepszania produktów i usług, w tym Alexa, asystenta zakupowego Rufus oraz funkcji wyszukiwania Amazona opartych na AI. Przestrzega protokołu wykluczania robotów i może być kontrolowany za pomocą dyrektyw w pliku robots.txt. Może być wykorzystywany do trenowania modeli AI.
Web crawler Amazona używany do ulepszania produktów i usług, w tym Alexa, asystenta zakupowego Rufus oraz funkcji wyszukiwania Amazona opartych na AI. Przestrzega protokołu wykluczania robotów i może być kontrolowany za pomocą dyrektyw w pliku robots.txt. Może być wykorzystywany do trenowania modeli AI.
Amazonbot to oficjalny web crawler Amazona, zaprojektowany w celu ulepszania produktów i usług firmy poprzez zbieranie i analizę treści z internetu. Ten zaawansowany crawler zasila kluczowe funkcje Amazona, w tym asystenta głosowego Alexa, AI asystenta zakupowego Rufus oraz wyszukiwanie Amazona oparte na sztucznej inteligencji. Amazonbot działa z użyciem user agent stringa Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36, który identyfikuje go dla serwerów. Dane zbierane przez Amazonbot mogą być wykorzystywane do trenowania modeli sztucznej inteligencji Amazona, co czyni go kluczowym elementem szeroko pojętej infrastruktury AI Amazona i strategii rozwoju produktów.
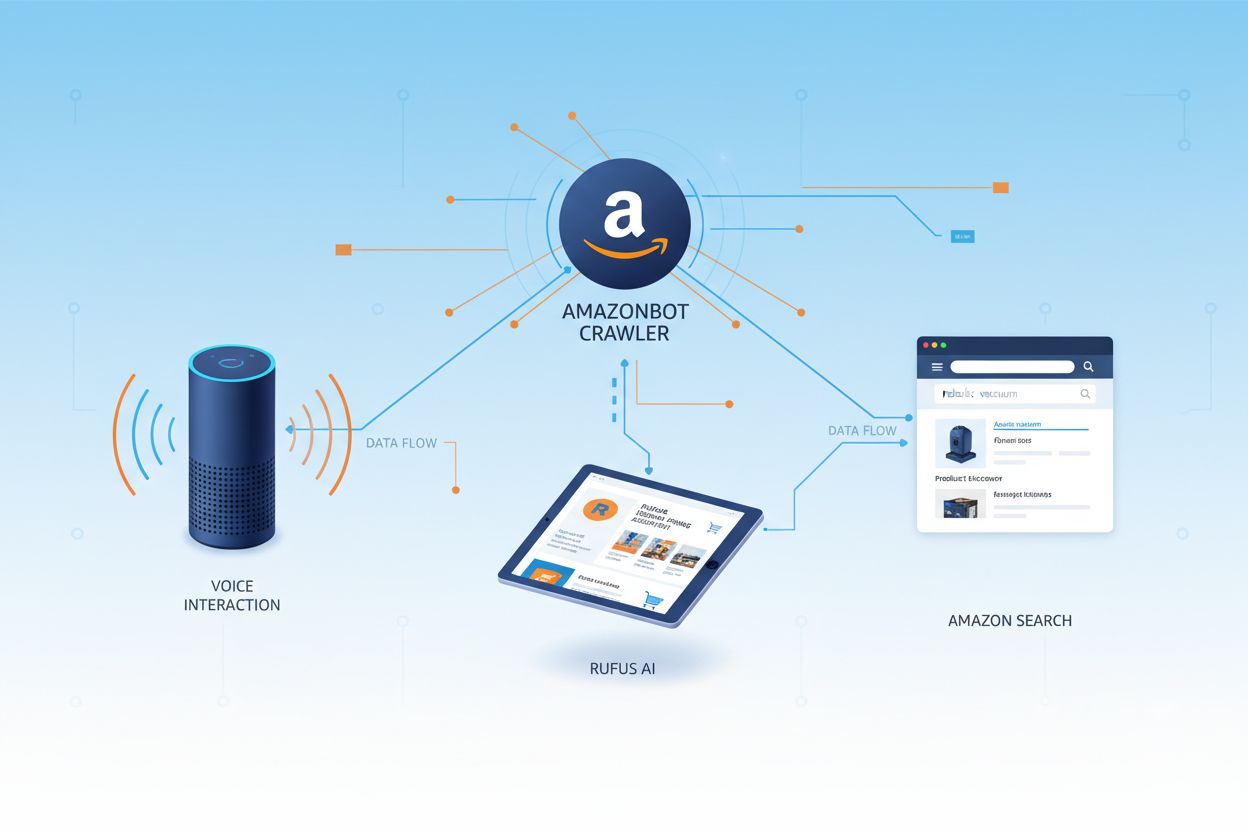
Amazon obsługuje trzy różne crawlery internetowe, z których każdy pełni określone funkcje w jego ekosystemie. Amazonbot to główny crawler wykorzystywany do ogólnego ulepszania produktów i usług, a także może być używany do trenowania modeli AI. Amzn-SearchBot jest zaprojektowany specjalnie do ulepszania wyników wyszukiwania w produktach Amazona, takich jak Alexa i Rufus, ale co ważne, NIE pobiera treści do trenowania generatywnych modeli AI. Amzn-User obsługuje działania inicjowane przez użytkownika, takie jak pobieranie aktualnych informacji, gdy klienci pytają Alexę o dane wymagające najnowszych treści z internetu, i również nie pobiera treści do trenowania AI. Wszystkie trzy crawlery przestrzegają protokołu wykluczania robotów oraz respektują dyrektywy z pliku robots.txt, co umożliwia właścicielom stron kontrolowanie dostępu. Amazon publikuje adresy IP każdego crawlera na swoim portalu developerskim, umożliwiając weryfikację autentyczności ruchu. Dodatkowo, wszystkie crawlery Amazona respektują dyrektywy rel=nofollow na poziomie linków oraz meta tagi robots na poziomie strony: noarchive (blokuje użycie do trenowania modeli), noindex (blokuje indeksowanie) i none (blokuje oba).
| Nazwa crawlera | Główne przeznaczenie | Trenowanie modeli AI | User Agent | Kluczowe zastosowania |
|---|---|---|---|---|
| Amazonbot | Ogólne ulepszanie produktów/usług | Tak | Amazonbot/0.1 | Usprawnianie usług Amazona, trenowanie AI |
| Amzn-SearchBot | Ulepszanie wyników wyszukiwania | Nie | Amzn-SearchBot/0.1 | Wyszukiwanie Alexa, indeksowanie Rufus |
| Amzn-User | Pobieranie na życzenie użytkownika | Nie | Amzn-User/0.1 | Bieżące zapytania do Alexy, aktualne informacje |
Amazon przestrzega branżowego standardu protokołu wykluczania robotów (RFC 9309), co oznacza, że właściciele stron mogą kontrolować dostęp Amazonbota za pomocą pliku robots.txt. Amazon pobiera plik robots.txt z katalogu głównego domeny (np. example.com/robots.txt) i, jeśli nie jest dostępny, korzysta z kopii zapasowej z ostatnich 30 dni. Zmiany w pliku robots.txt są zwykle odzwierciedlane w systemach Amazona w ciągu około 24 godzin. Protokół obsługuje standardowe dyrektywy user-agent oraz allow/disallow, umożliwiając precyzyjną kontrolę, które crawlery mają dostęp do wybranych katalogów lub plików. Ważne jest jednak, że crawlery Amazona NIE obsługują dyrektywy crawl-delay — ta opcja zostanie zignorowana, jeśli pojawi się w pliku robots.txt.
Przykład kontroli dostępu Amazonbota:
# Zablokuj Amazonbota na całej stronie
User-agent: Amazonbot
Disallow: /
# Zezwól Amzn-SearchBot na widoczność w wyszukiwarce
User-agent: Amzn-SearchBot
Allow: /
# Zablokuj konkretny katalog dla Amazonbota
User-agent: Amazonbot
Disallow: /private/
# Zezwól wszystkim innym crawlerom
User-agent: *
Disallow: /admin/
Właściciele stron internetowych, zaniepokojeni ruchem botów, powinni zweryfikować, czy crawlery podające się za Amazonbota są rzeczywiście autentyczne. Amazon udostępnia proces weryfikacji z użyciem zapytań DNS, pozwalający potwierdzić autentyczność ruchu Amazonbota. Aby zweryfikować crawlera, najpierw znajdź adres IP z logów serwera, następnie wykonaj odwrotne wyszukiwanie DNS tego adresu IP za pomocą polecenia host. Otrzymana nazwa domenowa powinna być subdomeną crawl.amazonbot.amazon. Następnie wykonaj zwykłe wyszukiwanie DNS tej domeny, by potwierdzić, że rozwiązuje się na pierwotny adres IP. Ten dwukierunkowy proces weryfikacji pomaga zapobiegać podszywaniu się, ponieważ złośliwi aktorzy mogą ustawić odwrotne rekordy DNS, aby podszywać się pod Amazonbota. Amazon publikuje zweryfikowane adresy IP wszystkich swoich crawlerów na portalu developerskim pod adresem developer.amazon.com/amazonbot/ip-addresses/, co stanowi dodatkowy punkt referencyjny do weryfikacji.
Przykład procesu weryfikacji:
$ host 12.34.56.789
789.56.34.12.in-addr.arpa domain name pointer 12-34-56-789.crawl.amazonbot.amazon.
$ host 12-34-56-789.crawl.amazonbot.amazon
12-34-56-789.crawl.amazonbot.amazon has address 12.34.56.789
Jeśli masz pytania dotyczące Amazonbota lub chcesz zgłosić podejrzaną aktywność, skontaktuj się bezpośrednio z Amazonem pod adresem amazonbot@amazon.com i dołącz odpowiednie nazwy domen.
Istotną różnicą pomiędzy crawlerami Amazona jest ich udział w trenowaniu modeli AI. Amazonbot może być wykorzystywany do trenowania modeli sztucznej inteligencji Amazona, co jest ważne dla twórców treści zaniepokojonych wykorzystaniem ich pracy w AI. Z kolei Amzn-SearchBot i Amzn-User wyraźnie NIE pobierają treści do trenowania generatywnych modeli AI — skupiają się wyłącznie na ulepszaniu wyszukiwania i obsłudze zapytań użytkowników. Jeśli nie chcesz, by Twoje treści były wykorzystywane do trenowania modeli AI, możesz użyć meta tagu robots noarchive w nagłówku HTML strony — Amazonbot nie powinien wówczas ich używać do trenowania modeli. To rozróżnienie jest istotne dla wydawców, twórców i właścicieli stron, którzy chcą mieć kontrolę nad wykorzystaniem swoich treści w pipeline AI, a jednocześnie umożliwić ich obecność w wynikach wyszukiwania Amazona i rekomendacjach Rufusa.
Rufus to zaawansowany asystent zakupowy AI Amazona, łączący web crawling i sztuczną inteligencję w celu dostarczania spersonalizowanych rekomendacji i wsparcia zakupowego. Choć Amazonbot wspiera całą infrastrukturę AI Amazona, Rufus korzysta przede wszystkim z Amzn-SearchBot do indeksowania informacji produktowych i treści internetowych istotnych dla zapytań zakupowych. Rufus bazuje na Amazon Bedrock i wykorzystuje zaawansowane modele językowe, w tym Claude Sonnet od Anthropic i Amazon Nova, połączone z autorskim modelem wytrenowanym na katalogu produktów Amazona, recenzjach, pytaniach społeczności i informacjach z sieci. Asystent zakupowy pomaga klientom w badaniu produktów, porównywaniu opcji, śledzeniu cen, wyszukiwaniu okazji oraz automatycznym zakupie, gdy ceny osiągną ustalony poziom. Od czasu premiery Rufus zyskał ogromną popularność — korzysta z niego ponad 250 milionów klientów, liczba aktywnych użytkowników miesięcznie wzrosła o 149%, a liczba interakcji zwiększyła się o 210% rok do roku. Klienci korzystający z Rufusa podczas zakupów są o ponad 60% bardziej skłonni do dokonania zakupu w danej sesji, co pokazuje, jak duży wpływ na zachowania konsumenckie mają rozwiązania zakupowe oparte na AI.
Właściciele stron powinni strategicznie zarządzać crawlerami Amazona w zależności od celów biznesowych i polityki dotyczącej treści:
noarchive lub całkowicie zablokuj go w robots.txtamazonbot@amazon.com, podając informacje o swojej domenie, aby uzyskać indywidualne wsparcie w kwestii interakcji crawlerów Amazona z Twoją stronąAmazonbot to ogólnego przeznaczenia crawler Amazona, używany do ulepszania produktów i usług, a także może być wykorzystywany do trenowania modeli AI. Amzn-SearchBot jest specjalnie zaprojektowany do wyszukiwania w Alexa i Rufus i wyraźnie NIE pobiera treści do trenowania modeli AI. Jeśli chcesz zapobiec wykorzystywaniu Twoich treści do trenowania AI, zablokuj Amazonbot, ale pozwól Amzn-SearchBot na dostęp dla widoczności w wyszukiwarce.
Dodaj poniższe linie do pliku robots.txt w katalogu głównym domeny: User-agent: Amazonbot, a następnie Disallow: /. To uniemożliwi Amazonbotowi indeksowanie całej witryny. Możesz także użyć Disallow: /konkretny-katalog/, aby zablokować tylko wybrane katalogi.
Tak, Amazonbot może być wykorzystywany do trenowania modeli sztucznej inteligencji Amazona. Jeśli chcesz temu zapobiec, użyj meta tagu robots w nagłówku HTML swojej strony, co poinstruuje Amazonbota, by nie wykorzystywał strony do trenowania modeli.
Wykonaj odwrotne wyszukiwanie DNS adresu IP crawlera i sprawdź, czy domena jest subdomeną crawl.amazonbot.amazon. Następnie wykonaj zwykłe wyszukiwanie DNS, by potwierdzić, że domena rozwiązuje się z powrotem na pierwotny adres IP. Możesz też sprawdzić opublikowane przez Amazona adresy IP na developer.amazon.com/amazonbot/ip-addresses/.
Użyj standardowej składni robots.txt: User-agent: Amazonbot, aby wskazać crawlera, następnie Disallow: /, by zablokować cały dostęp, lub Disallow: /ścieżka/, by zablokować konkretne katalogi. Możesz także użyć Allow: /, aby jawnie zezwolić na dostęp.
Amazon zazwyczaj wdraża zmiany w robots.txt w ciągu około 24 godzin. Amazon regularnie pobiera Twój plik robots.txt i utrzymuje jego kopię w pamięci podręcznej przez maksymalnie 30 dni, więc zmiany mogą potrzebować całego dnia, by zostać odzwierciedlone w ich systemach.
Tak, oczywiście. Możesz utworzyć osobne reguły dla każdego crawlera w swoim pliku robots.txt. Na przykład zezwól Amzn-SearchBot za pomocą User-agent: Amzn-SearchBot i Allow: /, jednocześnie blokując Amazonbot regułą User-agent: Amazonbot i Disallow: /.
Skontaktuj się bezpośrednio z Amazonem pod adresem amazonbot@amazon.com. Zawsze dołącz nazwę swojej domeny oraz wszelkie istotne szczegóły dotyczące zgłoszenia. Zespół wsparcia Amazona udzieli indywidualnych wskazówek w Twojej sprawie.
Śledź wzmianki o swojej marce w systemach AI, takich jak Alexa, Rufus czy Google AI Overviews, dzięki AmICited – wiodącej platformie monitorowania odpowiedzi AI.
Dowiedz się, jak działają AI crawlers takie jak GPTBot i ClaudeBot, czym różnią się od tradycyjnych crawlerów wyszukiwarek oraz jak zoptymalizować swoją stronę ...

Dowiedz się o Amazon Rufus, asystencie zakupowym AI, który odpowiada na pytania o produkty, porównuje artykuły i dostarcza spersonalizowane rekomendacje. Odkryj...

Dowiedz się, czym jest GPTBot, jak działa i czy powinieneś dopuścić lub zablokować crawlera internetowego OpenAI. Zrozum wpływ na widoczność Twojej marki w wysz...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.