Definicja mechanizmu uwagi
Mechanizm uwagi to technika uczenia maszynowego, która kieruje modele głębokiego uczenia do priorytetyzowania (czyli „skupiania uwagi” na) najbardziej istotnych fragmentach danych wejściowych podczas dokonywania predykcji. Zamiast traktować wszystkie elementy wejściowe jednakowo, mechanizmy uwagi obliczają wagi uwagi odzwierciedlające względną istotność każdego elementu dla zadania, a następnie dynamicznie wzmacniają lub osłabiają konkretne dane wejściowe. Ta fundamentalna innowacja stała się podstawą współczesnych architektur transformatorowych i dużych modeli językowych (LLM), takich jak ChatGPT, Claude czy Perplexity, umożliwiając im przetwarzanie sekwencyjnych danych z niespotykaną dotąd wydajnością i precyzją. Mechanizm inspirowany jest ludzką uwagą poznawczą – zdolnością selektywnego skupiania się na ważnych szczegółach przy jednoczesnym filtrowaniu informacji nieistotnych – a jego matematycznie rygorystyczna i wyuczonalna implementacja stała się komponentem sieci neuronowych.
Kontekst historyczny i ewolucja
Pojęcie mechanizmów uwagi zostało po raz pierwszy wprowadzone przez Bahdanau i współpracowników w 2014 roku, by rozwiązać kluczowe ograniczenia rekurencyjnych sieci neuronowych (RNN) stosowanych w tłumaczeniu maszynowym. Przed wprowadzeniem uwagi modele Seq2Seq polegały na pojedynczym wektorze kontekstu do zakodowania całych zdań źródłowych, co tworzyło wąskie gardło informacyjne i znacznie ograniczało wydajność przy dłuższych sekwencjach. Oryginalny mechanizm uwagi pozwolił dekoderowi uzyskiwać dostęp do wszystkich stanów ukrytych enkodera, a nie tylko ostatniego, dynamicznie wybierając, które fragmenty wejścia są najistotniejsze przy każdym kroku dekodowania. To przełomowe rozwiązanie znacząco poprawiło jakość tłumaczeń, zwłaszcza dla długich zdań. W 2015 roku Luong i współpracownicy wprowadzili uwagę iloczynową, zastępując kosztowną obliczeniowo uwagę addytywną wydajnym mnożeniem macierzy. Kluczowy moment nastąpił w 2017 roku wraz z publikacją „Attention is All You Need”, która przedstawiła architekturę transformatora opartą wyłącznie na mechanizmach uwagi, bez rekurencji. Ta praca zrewolucjonizowała głębokie uczenie, umożliwiając powstanie BERT-a, modeli GPT i całego współczesnego ekosystemu generatywnej AI. Obecnie mechanizmy uwagi są wszechobecne w przetwarzaniu języka naturalnego, widzeniu komputerowym i systemach multimodalnych AI, a ponad 85% najnowocześniejszych modeli wykorzystuje jakąś formę architektury opartej na uwadze.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Architektura techniczna i komponenty
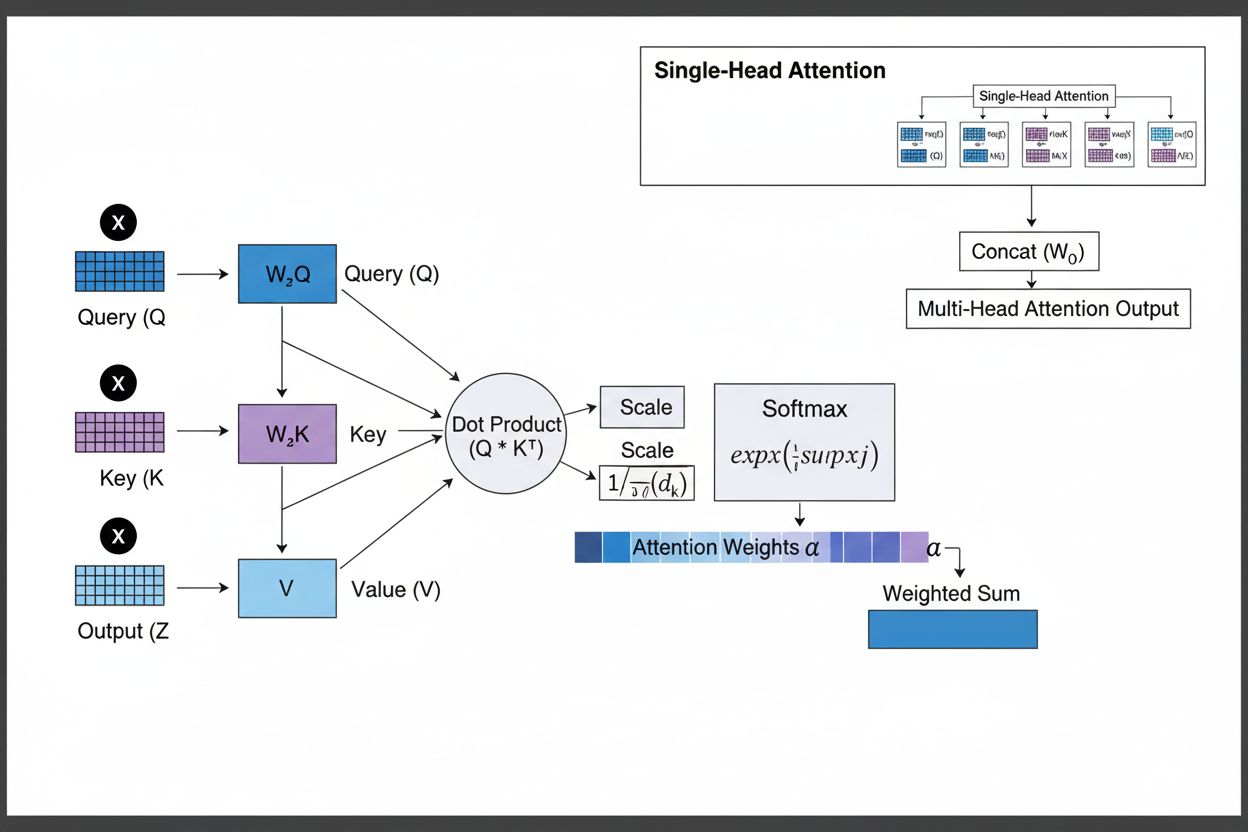
Mechanizm uwagi działa poprzez zaawansowaną współpracę trzech kluczowych komponentów matematycznych: zapytań (Q), kluczy (K) i wartości (V). Każdy element wejściowy jest przekształcany do tych trzech reprezentacji za pomocą wyuczonych projekcji liniowych, tworząc strukturę przypominającą relacyjną bazę danych, gdzie klucze pełnią rolę identyfikatorów, a wartości zawierają rzeczywiste informacje. Mechanizm oblicza współczynniki dopasowania mierząc podobieństwo zapytania do wszystkich kluczy, zwykle przy użyciu skalowanej uwagi iloczynowej, gdzie wynik to QK^T/√d_k. Te surowe wyniki są następnie normalizowane przez funkcję softmax, która zamienia je w rozkład prawdopodobieństwa sumujący się do 1, zapewniając każdemu elementowi wagę z przedziału 0–1. Ostatecznym krokiem jest obliczenie ważonej sumy wektorów wartości przy użyciu tych wag, co daje wektor kontekstu reprezentujący najistotniejsze informacje z całej sekwencji wejściowej. Wektor kontekstu jest następnie łączony z oryginalnym wejściem przez połączenia rezydualne i przekazywany przez warstwy feedforward, pozwalając modelowi iteracyjnie ulepszać rozumienie wejścia. Matematyczna elegancja tego rozwiązania – łączącego wyuczalne transformacje, obliczenia podobieństwa i probabilistyczne ważenie – umożliwia uchwycenie złożonych zależności przy pełnej różniczkowalności pod kątem optymalizacji gradientowej.
Porównanie wariantów mechanizmu uwagi
| Typ uwagi | Metoda obliczeń | Złożoność obliczeniowa | Najlepsze zastosowanie | Kluczowa zaleta |
|---|
| Uwaga addytywna | Sieć feed-forward + aktywacja tanh | O(n·d) na zapytanie | Krótkie sekwencje, zmienne wymiary | Obsługuje różne wymiary zapytań/kluczy |
| Uwaga iloczynowa | Proste mnożenie macierzy | O(n·d) na zapytanie | Standardowe sekwencje | Wydajność obliczeniowa |
| Skalowana uwaga iloczynowa | QK^T/√d_k + softmax | O(n·d) na zapytanie | Nowoczesne transformatory | Zapobiega zanikowi gradientu |
| Wielogłowa uwaga | Wiele równoległych głów uwagi | O(h·n·d) gdzie h=liczba głów | Złożone relacje | Uchwycenie różnych aspektów semantycznych |
| Samo-uwaga | Zapytania, klucze, wartości z tej samej sekwencji | O(n²·d) | Relacje wewnątrz sekwencji | Umożliwia przetwarzanie równoległe |
| Uwaga krzyżowa | Zapytania z jednej sekwencji, klucze/wartości z innej | O(n·m·d) | Enkoder-dekoder, multimodalność | Łączy różne modalności |
| Uwaga zgrupowanych zapytań | Dzielenie kluczy/wartości między głowy zapytań | O(n·d) | Wydajne wnioskowanie | Redukuje pamięć i obliczenia |
| Uwaga rzadka | Ograniczona do lokalnych/stratowanych pozycji | O(n·√n·d) | Bardzo długie sekwencje | Obsługuje ekstremalnie długie sekwencje |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Jak mechanizmy uwagi działają w praktyce
Mechanizm uwagi działa poprzez starannie zaplanowaną sekwencję transformacji matematycznych, które umożliwiają sieciom neuronowym dynamiczne skupianie się na istotnych informacjach. Podczas przetwarzania sekwencji wejściowej każdy element jest najpierw osadzany w przestrzeni wektorowej o wysokiej liczbie wymiarów, oddającej informacje semantyczne i składniowe. Te osadzenia są następnie projektowane do trzech oddzielnych przestrzeni za pomocą wyuczonych macierzy wag: przestrzeni zapytań (określającej, jakich informacji szukamy), przestrzeni kluczy (określającej, jakie informacje zawiera każdy element) oraz przestrzeni wartości (zawierającej właściwe dane do agregacji). Dla każdej pozycji zapytania mechanizm oblicza współczynnik podobieństwa z każdym kluczem jako ich iloczyn skalarny, otrzymując wektor surowych współczynników dopasowania. Wyniki te są skalowane przez podzielenie przez pierwiastek kwadratowy z wymiaru klucza (√d_k), co zapobiega nadmiernym wartościom przy dużej liczbie wymiarów i zanikaniu gradientów podczas wstecznej propagacji. Skalowane wyniki przechodzą przez funkcję softmax, która eksponencjuje i normalizuje je do rozkładu prawdopodobieństwa sumującego się do 1, tworząc rozkład prawdopodobieństwa pozycjonującego wszystkie wejścia. Ostatecznie te wagi uwagi służą do obliczenia ważonej średniej wektorów wartości – pozycje z wyższą wagą mają większy wpływ na końcowy wektor kontekstu. Wektor kontekstu jest następnie łączony z oryginalnym wejściem przez połączenia rezydualne i przetwarzany przez warstwy feedforward, umożliwiając modelowi iteracyjne ulepszanie reprezentacji. Cały proces jest różniczkowalny, dzięki czemu model może uczyć się optymalnych wzorców uwagi gradientowo podczas treningu.
Mechanizmy uwagi stanowią fundamentalny blok konstrukcyjny architektur transformatorowych, które stały się dominującym paradygmatem w głębokim uczeniu. W przeciwieństwie do RNN, które przetwarzają sekwencje szeregowo, i CNN, które operują na stałych oknach lokalnych, transformatory stosują samo-uwagę, by każda pozycja mogła bezpośrednio „patrzeć” na wszystkie inne pozycje jednocześnie, umożliwiając masowe równoleglenie na GPU i TPU. Architektura transformatora składa się z naprzemiennych warstw wielogłowej samo-uwagi i sieci feedforward, z każdą warstwą uwagi pozwalającą modelowi selektywnie skupiać się na różnych aspektach wejścia. Wielogłowa uwaga uruchamia wiele mechanizmów uwagi równolegle – każda głowa specjalizuje się w innym typie relacji: jedna w zależnościach gramatycznych, inna w relacjach semantycznych, kolejna w dalekosiężnych koreferencjach. Wyjścia wszystkich głów są łączone i projektowane, umożliwiając modelowi jednoczesne monitorowanie licznych zjawisk językowych. Ta architektura okazała się niezwykle skuteczna dla dużych modeli językowych takich jak GPT-4, Claude 3 czy Gemini, które korzystają z architektury tylko-dekoderowej, gdzie każdy token może „patrzeć” tylko na wcześniejsze tokeny (maskowanie przyczynowe), zachowując własność generatywną. Mechanizm uwagi umożliwia uchwycenie dalekozasiężnych zależności bez problemów zaniku gradientu, które trapiły RNN-y, co było kluczowe dla obsługi okien kontekstowych rzędu 100 000+ tokenów z zachowaniem spójności. Badania pokazują, że około 92% najnowocześniejszych modeli NLP opiera się na architekturach transformatorowych z mechanizmem uwagi, co dowodzi ich podstawowego znaczenia dla współczesnych systemów AI.
Mechanizmy uwagi w wyszukiwaniu AI i monitoringu
W kontekście platform wyszukiwania AI takich jak ChatGPT, Perplexity, Claude czy Google AI Overviews, mechanizmy uwagi odgrywają kluczową rolę w ustalaniu, które fragmenty przeszukiwanych dokumentów i baz wiedzy są najbardziej istotne dla zapytań użytkownika. Podczas generowania odpowiedzi, systemy te dynamicznie ważą różne źródła i fragmenty na podstawie ich znaczenia, umożliwiając tworzenie spójnych odpowiedzi z wielu źródeł przy zachowaniu poprawności faktograficznej. Wagi uwagi wyliczane podczas generowania mogą być analizowane, by zrozumieć, które informacje model uznał za priorytetowe, co daje wgląd w sposób interpretacji i odpowiedzi AI na zapytania. Dla monitoringu marki i GEO (Generative Engine Optimization) zrozumienie mechanizmów uwagi jest kluczowe, gdyż decydują one, które treści i źródła zostaną wyróżnione w odpowiedziach AI. Treści strukturalnie dopasowane do sposobu ważenia informacji przez mechanizm uwagi – dzięki jasnemu definiowaniu bytów, autorytatywnemu sourcingowi i kontekstowej relewancji – są znacznie bardziej prawdopodobne do cytowania i eksponowania w odpowiedziach AI. AmICited wykorzystuje wgląd w mechanizmy uwagi do monitorowania, jak marki i domeny pojawiają się na platformach AI, rozumiejąc, że cytowania ważone przez uwagę są najbardziej wpływowe. Wraz z rosnącym znaczeniem monitoringu obecności w odpowiedziach AI, świadomość, że mechanizmy uwagi napędzają wzorce cytowań, staje się kluczowa dla optymalizacji strategii treści i widoczności marki w erze generatywnej AI.
Kluczowe aspekty i kwestie wdrożeniowe
- Wydajność obliczeniowa: Skalowana uwaga iloczynowa zapewnia złożoność O(n²) przy ogromnych możliwościach równoleglania, co umożliwia obsługę tysięcy tokenów na nowoczesnych GPU
- Przepływ gradientu: Współczynnik skalowania (1/√d_k) zapobiega zanikowi gradientu, umożliwiając stabilny trening bardzo głębokich sieci z wieloma warstwami uwagi
- Interpretowalność: Wagi uwagi pozwalają na wizualizacje pokazujące, które elementy wejściowe wpłynęły na konkretne predykcje, zwiększając transparentność modeli
- Kodowanie pozycyjne: Transformatory wymagają jawnej informacji o pozycji (np. sinusoidalnej lub obrotowej), ponieważ sama uwaga nie zachowuje kolejności sekwencji
- Maskowanie przyczynowe: Modele autoregresyjne typu GPT stosują maskowanie przyczynowe, by zapobiec „patrzeniu” na przyszłe pozycje, zachowując własność generowania
- Wydajność pamięciowa: Warianty takie jak uwaga zgrupowanych zapytań czy uwaga rzadka redukują wymagania pamięciowe z O(n²) do O(n·√n) dla bardzo długich sekwencji
- Uwaga wieloskalowa: Różne głowy uwagi uczą się skupiać na różnych skalach kontekstu – od lokalnych relacji słów po tematy na poziomie dokumentu
- Dopasowanie między modalnościami: Uwaga krzyżowa umożliwia modelom takim jak Stable Diffusion powiązanie tekstu z generacją obrazu czy zakotwiczenie języka w wizji w modelach multimodalnych
Ewolucja i przyszłe kierunki
Obszar mechanizmów uwagi dynamicznie się rozwija – powstają coraz bardziej zaawansowane warianty, by przezwyciężać ograniczenia obliczeniowe i poprawiać wydajność. Wzorce uwagi rzadkiej ograniczają uwagę do lokalnych sąsiedztw lub pozycji skokowych, zmniejszając złożoność z O(n²) do O(n·√n) przy zachowaniu wydajności dla bardzo długich sekwencji. Wydajne mechanizmy uwagi jak FlashAttention optymalizują sposób dostępu do pamięci przy obliczeniach uwagi, osiągając 2–4-krotne przyspieszenia dzięki lepszemu wykorzystaniu GPU. Uwaga zgrupowanych zapytań i wielozapytaniowa zmniejszają liczbę głów kluczy i wartości przy zachowaniu wydajności, znacząco redukując wymagania pamięciowe podczas wnioskowania – co jest krytyczne przy wdrażaniu dużych modeli w produkcji. Architektury Mixture of Experts łączą uwagę z rzadkim routingiem, umożliwiając skalowanie modeli do bilionów parametrów przy zachowaniu wydajności obliczeniowej. Najnowsze badania eksplorują wyuczalne wzorce uwagi adaptowane dynamicznie do charakterystyki wejścia i uwagę hierarchiczną działającą na różnych poziomach abstrakcji. Integracja mechanizmów uwagi z generowaniem wspieranym wyszukiwaniem (RAG) pozwala modelom dynamicznie skupiać się na zewnętrznej wiedzy, zwiększając faktograficzność i ograniczając halucynacje. Wraz z szerokim wdrażaniem AI w krytycznych zastosowaniach mechanizmy uwagi wzbogaca się o funkcje wyjaśniające, by zapewnić większą przejrzystość decyzji modelu. Przyszłość najpewniej przyniesie hybrydowe architektury łączące uwagę z alternatywami jak modele stanów przestrzennych (przykład – Mamba), oferujące złożoność liniową przy konkurencyjnych wynikach. Zrozumienie ewolucji mechanizmów uwagi jest kluczowe zarówno dla praktyków budujących nową generację systemów AI, jak i dla organizacji monitorujących swoją obecność w treściach generowanych przez AI, ponieważ właśnie te mechanizmy decydują o wzorcach cytowań i eksponowaniu treści.
Mechanizmy uwagi a wzorce cytowań AI
Dla organizacji korzystających z AmICited do monitorowania widoczności marki w odpowiedziach AI, zrozumienie mechanizmów uwagi dostarcza kluczowego kontekstu do interpretacji wzorców cytowań. Gdy ChatGPT, Claude czy Perplexity cytują Twoją domenę w odpowiedziach, to właśnie wagi uwagi wyliczone podczas generowania zadecydowały, że Twoje treści były najistotniejsze dla zapytania użytkownika. Wysokiej jakości, dobrze zorganizowane treści jasno definiujące byty i dostarczające autorytatywnych informacji naturalnie otrzymują wyższe wagi uwagi, przez co są częściej wybierane do cytowania. Wizualizacje uwagi dostępne w niektórych platformach AI pokazują, które źródła były najważniejsze podczas generowania odpowiedzi, de facto ukazując najbardziej wpływowe cytowania. Ta wiedza pozwala organizacjom optymalizować strategię treści, rozumiejąc, że mechanizmy uwagi nagradzają przejrzystość, relewancję i autorytatywność. Wraz z rozwojem wyszukiwania AI – ponad 60% przedsiębiorstw inwestuje już w generatywną AI – zdolność do rozumienia i optymalizacji pod mechanizmy uwagi jest coraz cenniejsza dla utrzymania widoczności marki i zapewnienia jej właściwej reprezentacji w treściach generowanych przez AI. Przecięcie mechanizmów uwagi i monitoringu marki to nowy obszar GEO, gdzie zrozumienie matematycznych podstaw działania AI w zakresie ważenia i cytowania informacji przekłada się bezpośrednio na lepszą widoczność i wpływ w ekosystemie generatywnej AI.