
Rozpoznawanie encji
Rozpoznawanie encji to funkcja AI NLP, która identyfikuje i kategoryzuje nazwy własne w tekście. Dowiedz się, jak to działa, o jego zastosowaniach w monitoringu...
10 min czytania

Rozróżnianie encji to proces ustalania, do której konkretnej encji odnosi się dane wystąpienie, gdy wiele encji dzieli tę samą nazwę. Pomaga to systemom AI dokładnie rozumieć i cytować treści poprzez rozwiązywanie niejednoznaczności w odniesieniach do nazwanych encji, zapewniając, że wzmianki o ‘Apple’ poprawnie identyfikują, czy chodzi o Apple Inc., owoc, czy inną encję o tej samej nazwie.
Rozróżnianie encji to proces ustalania, do której konkretnej encji odnosi się dane wystąpienie, gdy wiele encji dzieli tę samą nazwę. Pomaga to systemom AI dokładnie rozumieć i cytować treści poprzez rozwiązywanie niejednoznaczności w odniesieniach do nazwanych encji, zapewniając, że wzmianki o 'Apple' poprawnie identyfikują, czy chodzi o Apple Inc., owoc, czy inną encję o tej samej nazwie.
Rozróżnianie encji to proces ustalania, do której konkretnej encji odnosi się dane wystąpienie, gdy wiele encji dzieli tę samą nazwę lub podobne odniesienia. W kontekście sztucznej inteligencji i przetwarzania języka naturalnego (NLP), rozróżnianie encji zapewnia, że gdy system AI napotyka nazwę własną w tekście, poprawnie identyfikuje, do którego rzeczywistego obiektu, osoby, organizacji lub miejsca się ona odnosi. To zasadniczo różni się od rozpoznawania nazwanych encji (NER), które jedynie wykrywa, że w tekście występuje encja i klasyfikuje ją do kategorii takich jak “osoba”, “organizacja” czy “miejsce”. Podczas gdy NER odpowiada na pytanie „Czy tu jest encja?”, rozróżnianie encji odpowiada „Która to konkretnie encja?”. Przykładowo, podczas przetwarzania zdania „Apple był dziełem Steve’a Jobsa”, NER rozpoznaje „Apple” jako organizację, natomiast rozróżnianie encji określa, czy chodzi o Apple Inc., firmę technologiczną, czy inną encję o tej samej nazwie. To rozróżnienie jest kluczowe dla systemów AI, które muszą dokładnie rozumieć i cytować treści, dlatego AmICited.com monitoruje, jak systemy AI takie jak ChatGPT, Perplexity i Google AI Overviews radzą sobie z rozróżnianiem encji podczas generowania odpowiedzi o markach i organizacjach.
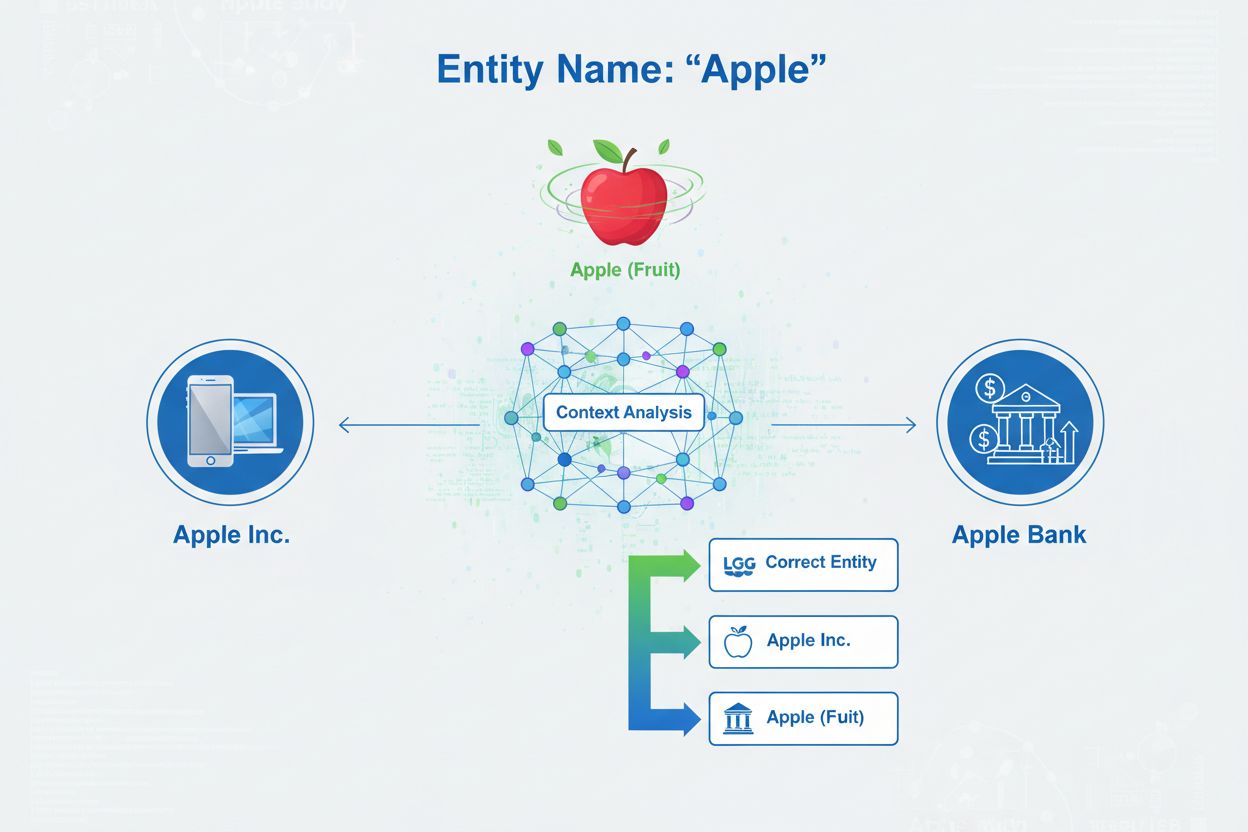
Podstawowy problem, który rozwiązuje rozróżnianie encji, to niejednoznaczność — fakt, że wiele nazw encji może odnosić się do różnych rzeczywistych obiektów. Ta niejednoznaczność stanowi ogromne wyzwanie dla systemów AI próbujących zrozumieć i generować poprawne treści. Według Stanford AI Index 2024, ponad 18% wyników LLM dotyczących marek zawiera halucynacje lub błędne przypisania encji, co oznacza, że systemy AI często mylą jedną encję z inną lub generują fałszywe informacje o encjach. Tak wysoki poziom błędów ma poważne konsekwencje dla reprezentacji marki i poprawności treści. Gdy system AI błędnie identyfikuje encję, może podać nieprawdziwe informacje, przypisać wypowiedzi niewłaściwej organizacji lub nie podać właściwego źródła informacji.
| Nazwa encji | Możliwe znaczenia | Częstotliwość pomyłek AI |
|---|---|---|
| Apple | Firma technologiczna / Owoc / Bank | Wysoka |
| Delta | Linie lotnicze / Firma armatury / Litera grecka | Wysoka |
| Jaguar | Producent samochodów / Gatunek zwierzęcia | Średnia |
| Amazon | Firma e-commerce / Las deszczowy / Rzeka | Wysoka |
| Orange | Kolor / Owoc / Firma telekomunikacyjna | Średnia |
Konsekwencje słabego rozróżniania encji wykraczają poza proste błędy faktograficzne. Dla twórców treści i marek błędna identyfikacja w odpowiedziach AI może prowadzić do utraty widoczności, nieprawidłowego przypisania i uszczerbku na reputacji marki. Gdy użytkownik pyta AI o „Delta”, może chodzić o Delta Airlines, ale jeśli system pomyli ją z Delta Faucet Company, użytkownik otrzyma nieistotne informacje. Właśnie dlatego AmICited.com monitoruje, jak systemy AI rozróżniają encje — by pomóc markom zrozumieć, czy są poprawnie identyfikowane i cytowane w treściach generowanych przez AI na różnych platformach.
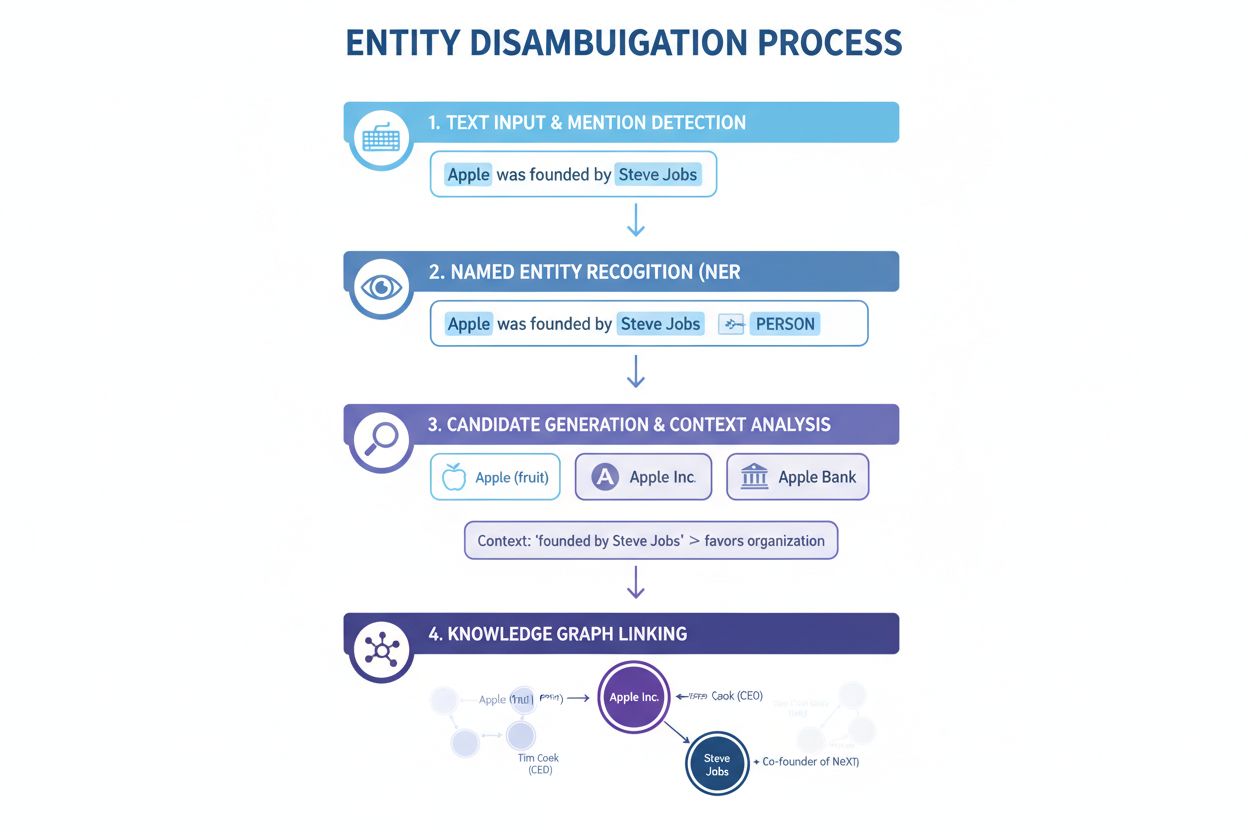
Rozróżnianie encji działa poprzez systematyczny proces wykorzystujący różne techniki NLP do rozwiązania niejednoznaczności i poprawnej identyfikacji encji. Zrozumienie tego procesu pokazuje, dlaczego niektóre systemy AI osiągają wyższą dokładność cytowań niż inne.
Rozpoznawanie nazwanych encji (NER): Pierwszy etap polega na identyfikacji i klasyfikacji nazwanych encji w tekście. Systemy NER analizują dane tekstowe i lokalizują wzmianki o encjach, przypisując je do określonych kategorii, takich jak osoba, organizacja, miejsce, produkt czy data. Przykładowo, w zdaniu „Apple był dziełem Steve’a Jobsa” NER identyfikuje zarówno „Apple”, jak i „Steve Jobs” jako encje i klasyfikuje je odpowiednio jako organizację i osobę. To podstawowy krok, ponieważ rozróżnianie nie może się odbyć bez wcześniejszego wykrycia encji w tekście.
Kategoryzacja encji: Po wykryciu encji należy je dokładniej sklasyfikować. Obejmuje to nie tylko ogólną klasyfikację, ale także zrozumienie konkretnego typu i kontekstu każdej encji. System analizuje otaczający tekst, by ustalić, czy „Apple” występuje w kontekście technologicznym (sugerując Apple Inc.), spożywczym (owoc) czy finansowym (Apple Bank). Ta analiza kontekstu zawęża możliwości przed właściwym etapem rozróżniania.
Rozróżnianie: To kluczowy etap, w którym system ustala, do której konkretnej encji odnosi się wzmianka. System analizuje wielu kandydatów odpowiadających zidentyfikowanej nazwie i używa różnych sygnałów — takich jak kontekst, opisy encji, relacje semantyczne i informacje z grafów wiedzy — by wybrać najbardziej prawdopodobną, właściwą encję. W zdaniu „Apple był dziełem Steve’a Jobsa” system rozpozna silne powiązanie Steve’a Jobsa z Apple Inc., wybierając tę encję.
Powiązanie z bazą wiedzy: Ostatni etap to powiązanie rozróżnionej encji z unikalnym identyfikatorem w zewnętrznej bazie wiedzy lub grafie wiedzy, takim jak Wikidata, Wikipedia czy prywatna baza. To potwierdza tożsamość encji i wzbogaca tekst o informacje semantyczne przydatne do dalszego przetwarzania i analizy. Encja otrzymuje unikalny URI (Uniform Resource Identifier) będący ostatecznym punktem odniesienia.
Wypracowano różne podejścia do rozróżniania encji, z których każde ma swoje zalety i ograniczenia. Ich znajomość wyjaśnia, dlaczego współczesne systemy AI różnią się skutecznością rozróżniania.
Podejścia oparte na regułach: Systemy te używają ustalonych reguł językowych i wzorców heurystycznych do rozróżniania encji. Mogą stosować zasady typu „jeśli ‘Apple’ pojawia się koło ‘iPhone’ lub ‘MacBook’, chodzi o Apple Inc.” czy „jeśli ‘Delta’ pojawia się przy ‘airline’ lub ‘flight’, chodzi o Delta Airlines”. Systemy regułowe są przejrzyste i nie wymagają dużych zbiorów treningowych, jednak słabo radzą sobie w nowych kontekstach i nie adaptują się do nowych znaczeń bez ręcznej aktualizacji reguł.
Podejścia oparte na uczeniu maszynowym: Modele uczone nadzorowane wykorzystują oznaczone dane treningowe do przewidywania właściwej encji na podstawie cech kontekstowych. Systemy te wyodrębniają cechy z otaczającego tekstu i stosują algorytmy takie jak SVM czy Random Forest, by sklasyfikować najbardziej prawdopodobną encję. Uczenie maszynowe daje większą elastyczność niż reguły, ale wymaga dużo oznaczonych danych i może mieć trudności z nowymi encjami.
Uczenie głębokie i modele transformerowe: Współczesne rozróżnianie encji coraz częściej wykorzystuje architektury transformerowe, takie jak BERT, RoBERTa czy wyspecjalizowane modele GENRE i BLINK. Modele te za pomocą sieci neuronowych głębiej rozumieją kontekst, wychwytując relacje semantyczne i subtelności językowe. Osiągają one wysokie wyniki w testach i lepiej radzą sobie w złożonych przypadkach rozróżniania. Przykładem jest system CEEL firmy Ontotext, oparty na transformerach zoptymalizowanych pod wydajność CPU, osiągający 96% skuteczności rozpoznawania encji i 76% skuteczności linkowania encji w testach.
Integracja grafów wiedzy: Nowoczesne systemy coraz częściej łączą uczenie maszynowe z grafami wiedzy — uporządkowanymi bazami danych opisującymi encje i ich relacje. Grafy wiedzy dostarczają bogate kontekstowe informacje o encjach, ich właściwościach i powiązaniach z innymi encjami. Dzięki zapytaniom do grafów podczas rozróżniania, systemy mogą korzystać z metadanych, opisów i relacji, co pozwala trafniej rozwiązywać niejednoznaczności.
Rozróżnianie encji jest niezbędne w wielu branżach i zastosowaniach, wszędzie tam, gdzie liczy się poprawna identyfikacja i cytowanie encji.
Wyszukiwarki: Google, Bing i inne wyszukiwarki intensywnie wykorzystują rozróżnianie encji, by zwracać trafne wyniki. Gdy użytkownik szuka „Apple”, wyszukiwarka musi ustalić, czy chodzi o Apple Inc., owoc czy inną encję o tej nazwie. Wykorzystuje do tego kontekst zapytania, historię użytkownika i grafy wiedzy. Dlatego wyniki dla „Apple” najczęściej pokazują firmę technologiczną — system nauczył się, że to najczęstszy zamysł użytkownika.
Media i wydawnictwa: Organizacje medialne i platformy treści używają rozróżniania encji, by poprawiać odkrywalność treści i linkować powiązane artykuły. Gdy w artykule pojawia się „Apple”, system może automatycznie podlinkować wpis Apple Inc. w bazie wiedzy, dając czytelnikom dodatkowy kontekst i powiązane materiały. Zwiększa to zaangażowanie i ułatwia zrozumienie szerokiego kontekstu informacji.
Opieka zdrowotna: Instytucje medyczne wykorzystują rozróżnianie encji do precyzyjnej identyfikacji leków, chorób i procedur w dokumentacji i literaturze. Rozróżnienie nazw leków jest kluczowe — „aspiryna” może oznaczać substancję, konkretną markę lub wariant dawki. Poprawne rozróżnianie gwarantuje dostęp do właściwych informacji i porządkowanie dokumentacji medycznej.
Finanse: Firmy inwestycyjne i analitycy finansowi śledzą wzmianki o spółkach w wiadomościach, raportach i danych rynkowych. Analizując ekspozycję rynkową, muszą poprawnie zidentyfikować wszystkie wzmianki o danej firmie w różnych źródłach. Rozróżnianie encji zapewnia, że „Apple” dotyczy Apple Inc., a nie innych podmiotów, co umożliwia rzetelną analizę ryzyka i portfela.
E-commerce: Detaliści internetowi używają rozróżniania encji, by dopasować wzmianki o produktach do rzeczywistych ofert w katalogu. Gdy klient szuka „Apple laptop”, system musi rozróżnić „Apple” jako firmę i dopasować do odpowiednich produktów, co poprawia trafność wyszukiwania i ułatwia znalezienie poszukiwanego towaru.
AmICited.com wykorzystuje zasady rozróżniania encji do monitorowania, jak systemy AI takie jak ChatGPT, Perplexity i Google AI Overviews rozpoznają wzmianki o markach. Śledząc, czy systemy poprawnie rozróżniają encje marek i cytują je prawidłowo, AmICited pomaga markom zrozumieć ich widoczność i reprezentację w treściach generowanych przez AI.
Grafy wiedzy są podstawą nowoczesnych systemów rozróżniania encji, zapewniając uporządkowaną reprezentację encji i ich relacji. Graf wiedzy to w istocie baza danych encji (węzłów) i relacji między nimi (krawędzi). Każdy węzeł encji zawiera metadane, takie jak nazwa, opis, typ i właściwości. Na przykład w grafie wiedzy encja „Apple Inc.” może mieć atrybuty „założona w 1976”, „siedziba w Cupertino”, „branża: technologia” oraz relacje „założona przez Steve’a Jobsa” i „produkuje iPhone”.
Gdy system rozróżniania encji napotyka niejednoznaczną wzmiankę, może zapytać graf wiedzy o bogate kontekstowe informacje o kandydackich encjach. To pozwala podejmować trafniejsze decyzje rozróżniające. Jeśli w otaczającym tekście pojawia się „Steve Jobs”, system sprawdzi w grafie, że jest on powiązany z Apple Inc., i wybierze tę encję. Publicznie dostępne grafy jak Wikidata czy Wikipedia dostarczają wielu systemom AI informacji podczas wnioskowania. Prywatne grafy wiedzy, budowane przez firmy takie jak Google czy Microsoft, oferują dodatkowe, branżowe źródła wiedzy. Integracja grafów wiedzy z modelami uczenia maszynowego znacząco podniosła skuteczność rozróżniania encji, bo systemy mogą łączyć wzorce wyuczone z uporządkowaną wiedzą faktograficzną.
Pomimo dużych postępów systemy rozróżniania encji wciąż napotykają istotne wyzwania, które ograniczają ich skuteczność i zastosowania.
Polisemia i niejednoznaczność: Wiele nazw encji ma kilka równoprawnych znaczeń i sam kontekst nie zawsze pozwala je rozróżnić. „Bank” może oznaczać instytucję finansową lub brzeg rzeki. „Żuraw” to ptak lub maszyna budowlana. Niektóre nazwy są na tyle niejednoznaczne, że nawet ludzie mają trudność z ich interpretacją bez dodatkowego kontekstu. AI musi nauczyć się rozpoznawać, gdy kontekst jest niewystarczający i odpowiednio obsługiwać takie przypadki.
Nowe i powstające encje: Bazy wiedzy i dane treningowe się dezaktualizują, gdy pojawiają się nowe encje. Gdy powstaje nowa firma lub produkt, systemy rozróżniania mogą nie mieć o nich informacji. Zero-shot entity linking — rozróżnianie encji niewidzianych podczas treningu — pozostaje trudnym problemem. Systemy muszą rozpoznać nową encję i nie mylić jej z podobnie nazwanymi istniejącymi.
Warianty nazw i literówki: Encje często występują pod wieloma nazwami, skrótami i wariantami. „United States”, „USA”, „U.S.” i „America” to ta sama encja. Literówki i błędy dodatkowo komplikują rozróżnianie, szczególnie w treściach tworzonych przez użytkowników. Systemy muszą rozpoznawać te warianty i poprawnie przyporządkowywać do głównej encji.
Niekompletne lub nieaktualne dane: Bazy wiedzy mogą zawierać niepełne dane o encjach lub informacje mogą być przestarzałe, gdy encje się zmieniają. Siedziba firmy może się zmienić, zarząd ulec przetasowaniu, firma może zostać przejęta. Jeśli baza nie jest aktualizowana na bieżąco, system może podjąć decyzję na podstawie nieaktualnych danych.
Skalowalność i wydajność: Przetwarzanie dużych ilości tekstu z wysoką skutecznością rozróżniania encji wymaga znacznych zasobów obliczeniowych. Rozróżnianie w czasie rzeczywistym na skalę internetu jest kosztowne. Trzeba więc balansować dokładność, szybkość i koszt, często kosztem jakości rozróżniania.
Dla marek i twórców treści zrozumienie rozróżniania encji jest kluczowe, by zapewnić właściwą reprezentację w treściach generowanych przez AI. W miarę jak AI coraz bardziej wpływa na sposób odkrywania i konsumpcji informacji, marki muszą podejmować działania, by być poprawnie rozróżniane i cytowane.
Strategie prewencyjne: Marki mogą wdrażać rozwiązania, które ułatwiają AI poprawne rozróżnianie ich encji. Jedną z kluczowych strategii jest wdrożenie uporządkowanych danych z wykorzystaniem Schema.org i formatu JSON-LD na stronach internetowych marki. Takie dane jasno informują AI o tożsamości marki, jej oficjalnej nazwie, opisie, logo, siedzibie i innych unikalnych cechach. Gdy AI napotyka nazwę marki, może odwołać się do tych danych, by potwierdzić właściwą encję.
Optymalizacja w grafach wiedzy: Marki powinny zadbać o silną obecność w kluczowych grafach wiedzy, takich jak Wikidata i Wikipedia. Oznacza to tworzenie i aktualizowanie artykułów na Wikipedii, zapewnienie kompletności i aktualności wpisów na Wikidacie oraz budowanie relacji z powiązanymi encjami. Im pełniejsza i dokładniejsza obecność marki w grafach wiedzy, tym większe szanse na poprawne rozróżnienie przez AI.
Kontekstowa strategia treści: Marki mogą tworzyć treści, które jasno określają ich tożsamość i odróżniają od innych o podobnych nazwach. Treści, które wyraźnie wskazują branżę, produkty, założycieli i unikalną propozycję marki, pomagają AI zrozumieć jej odrębność. Takie treści stają się częścią danych uczących i kontekstu wykorzystywanego przez AI.
Monitoring cytowań: Narzędzia takie jak AmICited.com umożliwiają markom monitorowanie, jak systemy AI rozróżniają i cytują ich markę na różnych platformach. Śledząc, czy ChatGPT, Perplexity, Google AI Overviews i inne systemy poprawnie identyfikują i cytują markę, firmy mogą wykrywać błędy i reagować. Monitoring ten jest kluczowy dla zrozumienia widoczności marki w erze generatywnej AI.
Optymalizacja pod generatywne silniki (GEO): Wraz ze wzrostem znaczenia rozróżniania encji dla widoczności marki w AI, warto włączyć optymalizację encji do szeroko pojętej strategii GEO (Generative Engine Optimization). Obejmuje to jasne definiowanie, dokumentowanie i odróżnianie marki od konkurencji. GEO wykracza poza klasyczne SEO, obejmując optymalizację pod to, jak AI rozumie i prezentuje marki.
Rozróżnianie encji zmienia się wraz z rozwojem AI i pojawianiem się nowych wyzwań. Kilka trendów kształtuje przyszłość tej kluczowej umiejętności.
Wielojęzyczne rozróżnianie encji: Wraz z globalizacją systemów AI rośnie znaczenie rozróżniania encji w wielu językach. Imię i nazwisko danej osoby może być zapisywane inaczej w różnych językach, a ta sama encja może mieć różne nazwy w różnych kontekstach językowych. Powstają zaawansowane modele wielojęzyczne, które radzą sobie z rozróżnianiem encji w skali globalnej.
Rozróżnianie encji w czasie rzeczywistym przez duże modele językowe: Współczesne modele językowe, takie jak GPT-4 czy Claude, coraz częściej uwzględniają rozróżnianie encji na bieżąco podczas generowania tekstu. Zamiast polegać wyłącznie na danych treningowych, modele mogą podczas działania pytać grafy wiedzy i zewnętrzne bazy, by zweryfikować informacje i zapewnić poprawne rozróżnianie. To zwiększa poprawność cytowań i ogranicza halucynacje.
Lepsze uczenie zero-shot: Przyszłe systemy rozróżniania encji będą skuteczniejsze w przypadku encji niewidzianych podczas treningu. Postępy w few-shot i zero-shot learningu pozwolą trafniej rozróżniać nowe encje bez konieczności częstych aktualizacji modeli, zwiększając ich elastyczność.
Integracja z generowaniem wspomaganym wyszukiwaniem (RAG): Coraz popularniejsze są systemy łączące modele językowe z wyszukiwaniem informacji. Pozwalają one pobierać aktualne dane o encjach z baz wiedzy w trakcie generowania tekstu, co poprawia jakość rozróżniania i cytowań. To znaczący krok ku rzetelnemu cytowaniu przez AI.
Standaryzacja i interoperacyjność: Wraz z rosnącą rolą rozróżniania encji w AI można spodziewać się pojawienia standardów branżowych dotyczących reprezentacji i rozróżniania encji. Ułatwi to współpracę między różnymi systemami i bazami wiedzy, umożliwiając AI spójny dostęp do informacji o encjach.
Rozróżnianie encji przeszło drogę od niszowego zadania NLP do kluczowej umiejętności niezbędnej dla poprawnego rozumienia i prezentowania informacji przez AI. W miarę jak AI coraz bardziej wpływa na sposób odkrywania i konsumpcji wiedzy, znaczenie poprawnego rozróżniania encji będzie tylko rosnąć. Dla marek, twórców i organizacji zrozumienie i optymalizacja pod kątem rozróżniania encji są niezbędne, by utrzymać widoczność i właściwą reprezentację w erze generatywnej AI.
Rozpoznawanie nazwanych encji identyfikuje, że w tekście występuje encja i klasyfikuje ją do kategorii, takich jak osoba, organizacja lub lokalizacja. Rozróżnianie encji idzie dalej, ustalając, do której konkretnej encji odnosi się wzmianka, gdy wiele encji dzieli tę samą nazwę. Na przykład NER rozpoznaje 'Apple' jako organizację, podczas gdy rozróżnianie encji określa, czy chodzi o Apple Inc., Apple Bank czy inną encję.
Rozróżnianie encji zapewnia, że systemy AI dokładnie rozumieją, o której encji jest mowa i poprawnie ją cytują. Według Stanford AI Index 2024 ponad 18% wyników LLM dotyczących marek zawiera halucynacje lub błędne przypisania. Dokładne rozróżnianie encji zapobiega myleniu przez systemy AI jednej encji z inną, co jest kluczowe dla ochrony reputacji marki i poprawności cytowań.
Grafy wiedzy dostarczają uporządkowanych informacji o encjach i ich relacjach. Gdy system AI napotyka niejednoznaczną wzmiankę o encji, może zapytać graf wiedzy o metadane, opisy i informacje o relacjach kandydatów na encje. Te kontekstowe informacje pomagają systemowi podejmować trafniejsze decyzje rozróżniające i wybrać właściwą encję.
Tak, dzięki podejściom zero-shot entity linking. Nowoczesne systemy potrafią rozpoznać, kiedy encja jest nowa i odpowiednio ją obsłużyć, zamiast błędnie dopasować ją do istniejącej encji. Jednak nadal jest to trudne zadanie i systemy lepiej radzą sobie z nowymi encjami, jeśli mają one wyraźne sygnały kontekstowe odróżniające je od istniejących encji.
Dokładne rozróżnianie encji zapewnia, że Twoja marka jest poprawnie identyfikowana i cytowana w odpowiedziach generowanych przez AI. Gdy systemy AI poprawnie rozróżniają Twoją markę, użytkownicy otrzymują rzetelne informacje o Twojej organizacji, co poprawia widoczność i reputację marki. Słabe rozróżnianie może prowadzić do pomylenia Twojej marki z konkurencją lub innymi encjami, ograniczając widoczność i potencjalnie szkodząc reputacji.
Kluczowe wyzwania to polisemia (wiele znaczeń tej samej nazwy), nowe encje niewystępujące w danych treningowych, warianty nazw i literówki, niekompletne lub nieaktualne bazy wiedzy oraz kwestie skalowalności. Dodatkowo niektóre nazwy encji są z natury niejednoznaczne i sam kontekst może nie wystarczyć do ustalenia właściwej encji.
Marki mogą wdrożyć uporządkowane dane z użyciem oznaczeń Schema.org, dbać o aktualność wpisów na Wikipedii i Wikidacie, tworzyć treści kontekstowe wyraźnie odróżniające ich markę oraz monitorować, jak systemy AI rozróżniają ich markę za pomocą narzędzi takich jak AmICited. Te strategie pomagają systemom AI poprawnie identyfikować i cytować Twoją markę.
Kontekst jest kluczowy dla rozróżniania encji. Otaczający tekst, powiązane encje i relacje semantyczne dostarczają sygnałów pomagających systemom AI ustalić, o której encji mowa. Na przykład, jeśli 'Apple' pojawia się w pobliżu 'Steve Jobs' i 'technologia', system może wykorzystać ten kontekst, by poprawnie rozróżnić, że chodzi o Apple Inc., a nie owoc.
Śledź poprawność rozróżniania encji na platformach AI i upewnij się, że Twoja marka jest poprawnie identyfikowana i cytowana w odpowiedziach generowanych przez AI.
Rozpoznawanie encji to funkcja AI NLP, która identyfikuje i kategoryzuje nazwy własne w tekście. Dowiedz się, jak to działa, o jego zastosowaniach w monitoringu...

Dowiedz się, jak optymalizacja encji pomaga Twojej marce stać się rozpoznawalną przez LLM. Opanuj optymalizację grafu wiedzy, oznaczenia schema oraz strategie e...

Dowiedz się, czym jest optymalizacja encji dla AI, jak działa i dlaczego jest kluczowa dla widoczności w ChatGPT, Perplexity oraz innych wyszukiwarkach AI. Komp...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.