Oficjalny crawler internetowy OpenAI, który zbiera dane treningowe do modeli AI, takich jak ChatGPT i GPT-4. Właściciele stron mogą kontrolować dostęp przez robots.txt, używając dyrektyw ‘User-agent: GPTBot’. Crawler respektuje standardowe protokoły sieciowe i indeksuje wyłącznie publicznie dostępne treści.
GPTBot
Oficjalny crawler internetowy OpenAI, który zbiera dane treningowe do modeli AI, takich jak ChatGPT i GPT-4. Właściciele stron mogą kontrolować dostęp przez robots.txt, używając dyrektyw 'User-agent: GPTBot'. Crawler respektuje standardowe protokoły sieciowe i indeksuje wyłącznie publicznie dostępne treści.
Czym jest GPTBot?
GPTBot to oficjalny crawler internetowy OpenAI, zaprojektowany do indeksowania publicznie dostępnych treści w sieci na potrzeby trenowania i ulepszania modeli AI, takich jak ChatGPT i GPT-4. W przeciwieństwie do uniwersalnych crawlerów wyszukiwarek, takich jak Googlebot, GPTBot działa z konkretną misją: gromadzenia danych pomagających OpenAI rozwijać modele językowe i dostarczać lepsze odpowiedzi AI użytkownikom. Właściciele stron mogą zidentyfikować GPTBot dzięki charakterystycznemu user agent string (“GPTBot/1.0”), który pojawia się w logach serwera i platformach analitycznych podczas odwiedzin crawlera. GPTBot respektuje plik robots.txt, co oznacza, że właściciele stron mogą decydować o dostępie crawlera do swoich treści, dodając odpowiednie dyrektywy do tego pliku. Crawler indeksuje wyłącznie publicznie dostępne treści i nie próbuje omijać autoryzacji ani uzyskiwać dostępu do obszarów chronionych. Zrozumienie celu i zachowań GPTBot jest kluczowe dla właścicieli stron, którzy chcą świadomie zdecydować, czy pozwolić, czy zablokować temu crawlerowi dostęp do swoich zasobów cyfrowych.
Jak działa GPTBot
GPTBot działa poprzez systematyczne przeszukiwanie stron internetowych, analizowanie ich treści i przesyłanie danych do serwerów OpenAI w celu przetwarzania i trenowania modeli. Na początku crawler sprawdza plik robots.txt strony, by określić, do których stron ma dostęp, respektując dyrektywy właściciela zanim rozpocznie indeksowanie. Po zidentyfikowaniu się przez user agent string, pobiera i przetwarza zawartość strony, wyodrębniając tekst, metadane i informacje strukturalne, które wzbogacają zbiory danych treningowych. Crawler może generować znaczne zużycie transferu, a niektóre strony zgłaszają ponad 30 TB miesięcznego ruchu crawlerów wszystkich botów razem, choć wpływ samego GPTBot zależy od wielkości strony i istotności treści.
Nazwa crawlera
Cel
Respektuje robots.txt
Wpływ na SEO
Wykorzystanie danych
GPTBot
Trening modeli AI
Tak
Pośredni (widoczność w AI)
Zbiory treningowe
Googlebot
Indeksowanie wyszukiwania
Tak
Bezpośredni (pozycje)
Wyniki wyszukiwania
Bingbot
Indeksowanie wyszukiwania
Tak
Bezpośredni (pozycje)
Wyniki wyszukiwania
ClaudeBot
Trening modeli AI
Tak
Pośredni (widoczność w AI)
Zbiory treningowe
Właściciele stron mogą monitorować aktywność GPTBot w logach serwera, wyszukując konkretny user agent string, co pozwala śledzić częstotliwość wizyt i identyfikować ewentualny wpływ na wydajność. Zachowanie crawlera jest zaprojektowane tak, by szanować zasoby serwera, ale strony o dużym ruchu mogą zauważyć wyraźne zużycie transferu, gdy kilka crawlerów AI działa jednocześnie.
Dlaczego właściciele stron blokują GPTBot
Wielu właścicieli stron decyduje się zablokować GPTBot z powodu obaw o wykorzystanie treści bez rekompensaty, gdy OpenAI wykorzystuje zebrane materiały do trenowania komercyjnych modeli AI, nie oferując bezpośredniej korzyści ani wynagrodzenia twórcom treści. Obciążenie serwera to kolejny istotny problem, zwłaszcza dla mniejszych stron lub tych z ograniczonym transferem, ponieważ crawlery AI mogą zużywać znaczną ilość zasobów – niektóre serwisy raportują ponad 30 TB miesięcznego ruchu crawlerów, z istotnym udziałem GPTBot. Ekspozycja danych i ryzyka bezpieczeństwa niepokoją twórców, którzy obawiają się, że ich własnościowe informacje, tajemnice handlowe czy wrażliwe dane zostaną nieumyślnie zindeksowane i użyte w treningu AI, co może naruszyć przewagi konkurencyjne lub klauzule poufności. Sytuacja prawna wokół danych treningowych AI pozostaje niejasna – nierozstrzygnięte są kwestie zgodności z RODO, wymogów CCPA i naruszeń praw autorskich, co rodzi potencjalną odpowiedzialność zarówno po stronie OpenAI, jak i właścicieli stron dopuszczających nieograniczony crawling. Statystyki pokazują, że około 3,5% stron aktywnie blokuje GPTBot, a ponad 30 głównych portali z TOP 100 stron blokuje crawlera, w tym The New York Times, CNN, Associated Press i Reuters – co oznacza, że twórcy treści o wysokim autorytecie dostrzegają realne ryzyka. Połączenie tych czynników sprawia, że blokowanie GPTBot staje się coraz powszechniejszą praktyką wśród wydawców, mediów i rozbudowanych serwisów treściowych, które chcą chronić swoją własność intelektualną i utrzymać kontrolę nad wykorzystaniem swoich treści.
Dlaczego właściciele stron dopuszczają GPTBot
Właściciele stron dopuszczający GPTBot dostrzegają strategiczną wartość widoczności w ChatGPT, biorąc pod uwagę, że platforma obsługuje około 800 milionów użytkowników tygodniowo, którzy regularnie korzystają z odpowiedzi AI mogących cytować lub streszczać zindeksowane treści. Gdy GPTBot przeszukuje stronę, zwiększa się szansa, że jej zawartość będzie cytowana, podsumowana lub przywołana w odpowiedziach ChatGPT, zapewniając reprezentację marki w interfejsach AI i docierając do użytkowników coraz częściej korzystających z narzędzi AI zamiast tradycyjnych wyszukiwarek. Badania pokazują, że ruch z wyszukiwań AI konwertuje 23x lepiej niż z organicznych wyników wyszukiwania, co oznacza, że użytkownicy odkrywający treści przez podsumowania i rekomendacje AI angażują się i dokonują konwersji znacznie częściej niż standardowi goście z wyszukiwarki. Dopuszczenie GPTBot to również forma przyszłościowego zabezpieczenia, bo wyszukiwanie i odkrywanie treści oparte na AI stają się coraz ważniejsze w sposobie, w jaki użytkownicy szukają informacji w sieci, co daje przewagę konkurencyjną przy wczesnym wdrożeniu strategii widoczności w AI. Właściciele stron, którzy stawiają na GPTBot, korzystają również z Generative Engine Optimization (GEO) – nowej dziedziny skupionej na optymalizacji treści pod kątem systemów AI, a nie tradycyjnych algorytmów wyszukiwarek, co może przynieść długoterminowy wzrost ruchu. Pozwalając na dostęp GPTBot, nowoczesne firmy i wydawcy przygotowują się na przechwycenie ruchu z szybko rosnącego segmentu użytkowników polegających na AI przy poszukiwaniu informacji i podejmowaniu decyzji.
Jak zablokować GPTBot
Zablokowanie GPTBot jest proste i wymaga jedynie edycji pliku robots.txt w katalogu głównym strony, który kontroluje dostęp crawlerów do całej domeny. Najprostszy sposób to blokada wszystkich crawlerów OpenAI:
User-agent: GPTBot
Disallow: /
Jeśli chcesz zablokować GPTBot tylko w wybranych katalogach, a w innych umożliwić dostęp, użyj selektywnych dyrektyw:
Poza modyfikacją robots.txt właściciele stron mogą wdrożyć alternatywne metody blokowania, takie jak blokowanie IP na poziomie firewalla, Web Application Firewall (WAF) filtrujący żądania po user agent, czy ograniczanie transferu dla crawlerów. Dla pełnej kontroli niektóre strony łączą kilka podejść – używając robots.txt jako głównej metody oraz blokowania IP jako dodatkowego zabezpieczenia przed crawlerami ignorującymi robots.txt. Po wdrożeniu blokady warto zweryfikować jej skuteczność, sprawdzając logi serwera pod kątem user agent GPTBot, aby potwierdzić, że crawler nie ma już dostępu do Twoich treści.
Branże, które powinny rozważyć blokadę
Niektóre branże są szczególnie narażone na ryzyka związane z nieograniczonym dostępem crawlerów AI i powinny ostrożnie ocenić, czy blokada GPTBot współgra z ich interesami biznesowymi i strategią ochrony treści:
Wydawnictwa i media (gazety, czasopisma, agencje prasowe) – Oryginalne dziennikarstwo to duża inwestycja i przewaga konkurencyjna; wydawcy jak The New York Times, Associated Press i Reuters blokują GPTBot, by chronić ekskluzywne treści
Platformy e-commerce (Amazon, sklepy internetowe) – Opisy produktów, strategie cenowe i recenzje klientów to dane firmowe, które konkurencja może wykorzystać przez AI
Platformy z treścią generowaną przez użytkowników (media społecznościowe, fora, serwisy opinii) – Treści tworzone przez użytkowników mogą być używane bez ich zgody lub wynagrodzenia, co rodzi kwestie prawne i etyczne
Serwisy z danymi o wysokim autorytecie (instytucje naukowe, bazy danych, specjalistyczne repozytoria wiedzy) – Własnościowe badania, zbiory danych i wiedza specjalistyczna mają dużą wartość komercyjną i powinny pozostać pod kontrolą twórców
Usługi prawne i finansowe – Dane klientów, strategie prawne i porady finansowe wymagają poufności i nie mogą być ujawnione w zbiorach treningowych AI
Branża medyczna i zdrowotna – Dane pacjentów, dokumentacja medyczna i informacje kliniczne muszą być zgodne z przepisami (HIPAA i inne), które zabraniają nieautoryzowanego wykorzystania danych
Te branże powinny wdrożyć strategie blokujące, by utrzymać przewagi konkurencyjne, chronić własność intelektualną i zapewnić zgodność z regulacjami dotyczącymi ochrony danych.
Monitorowanie i wykrywanie
Właściciele stron powinni regularnie monitorować logi serwera, aby zidentyfikować aktywność GPTBot i śledzić wzorce crawlowań, co daje wgląd w to, jak systemy AI uzyskują dostęp i potencjalnie wykorzystują ich treści. Identyfikacja GPTBot jest prosta – crawler przedstawia się user agent stringiem “GPTBot/1.0” w nagłówkach żądań HTTP, dzięki czemu łatwo odróżnić go od innych botów w logach i narzędziach analitycznych. Większość nowoczesnych narzędzi analitycznych i SEO (w tym Google Analytics, Semrush, Ahrefs, specjalistyczne platformy do monitorowania botów) automatycznie kategoryzuje i raportuje aktywność GPTBot, pozwalając śledzić częstotliwość odwiedzin, zużycie transferu i odwiedzane strony bez ręcznej analizy logów. Bezpośredni wgląd w logi serwera ujawnia szczegółowe dane o żądaniach GPTBot – znaczniki czasu, odwiedzane URL-e, kody odpowiedzi i zużycie transferu – dostarczając szczegółowych informacji o zachowaniu crawlera. Regularny monitoring jest kluczowy, bo zachowania crawlerów mogą się zmieniać, pojawiają się nowe boty AI, a skuteczność blokad wymaga okresowej weryfikacji. Właściciele stron powinni ustalić bazowy poziom normalnego ruchu crawlerów i badać istotne odchylenia, które mogą wskazywać na wzmożoną aktywność AI lub potencjalne problemy z bezpieczeństwem.
Standardy bezpieczeństwa OpenAI
OpenAI złożyło publiczne zobowiązania do odpowiedzialnego rozwoju AI i zarządzania danymi, w tym jasne deklaracje, że GPTBot respektuje preferencje właścicieli stron wyrażone przez pliki robots.txt oraz inne techniczne dyrektywy. Firma podkreśla znaczenie prywatności danych i odpowiedzialnych praktyk AI, uznając, że twórcy treści mają prawo decydować o wykorzystaniu i ewentualnym wynagrodzeniu za swoją pracę, choć obecnie OpenAI nie przewiduje bezpośredniej rekompensaty dla właścicieli treści. Oficjalna polityka OpenAI potwierdza, że GPTBot respektuje dyrektywy robots.txt, co oznacza, że firma wdrożyła mechanizmy zgodności w swojej infrastrukturze crawlerów i oczekuje, że właściciele stron będą korzystać ze standardowych narzędzi technicznych do kontroli dostępu. Firma deklaruje również gotowość do dialogu z wydawcami i twórcami treści w sprawie wykorzystania danych, choć formalne umowy licencyjne i mechanizmy wynagradzania są ograniczone. Polityka OpenAI ewoluuje pod wpływem wyzwań prawnych, presji regulatorów i opinii branży, co sugeruje, że przyszłe wersje GPTBot mogą oferować dodatkowe zabezpieczenia, większą transparentność lub mechanizmy kompensacyjne. Właściciele stron powinni śledzić oficjalne komunikaty i aktualizacje polityki OpenAI, by wiedzieć, jak może zmieniać się podejście firmy do crawlowań i wykorzystania danych.
GPTBot vs inne crawlery AI
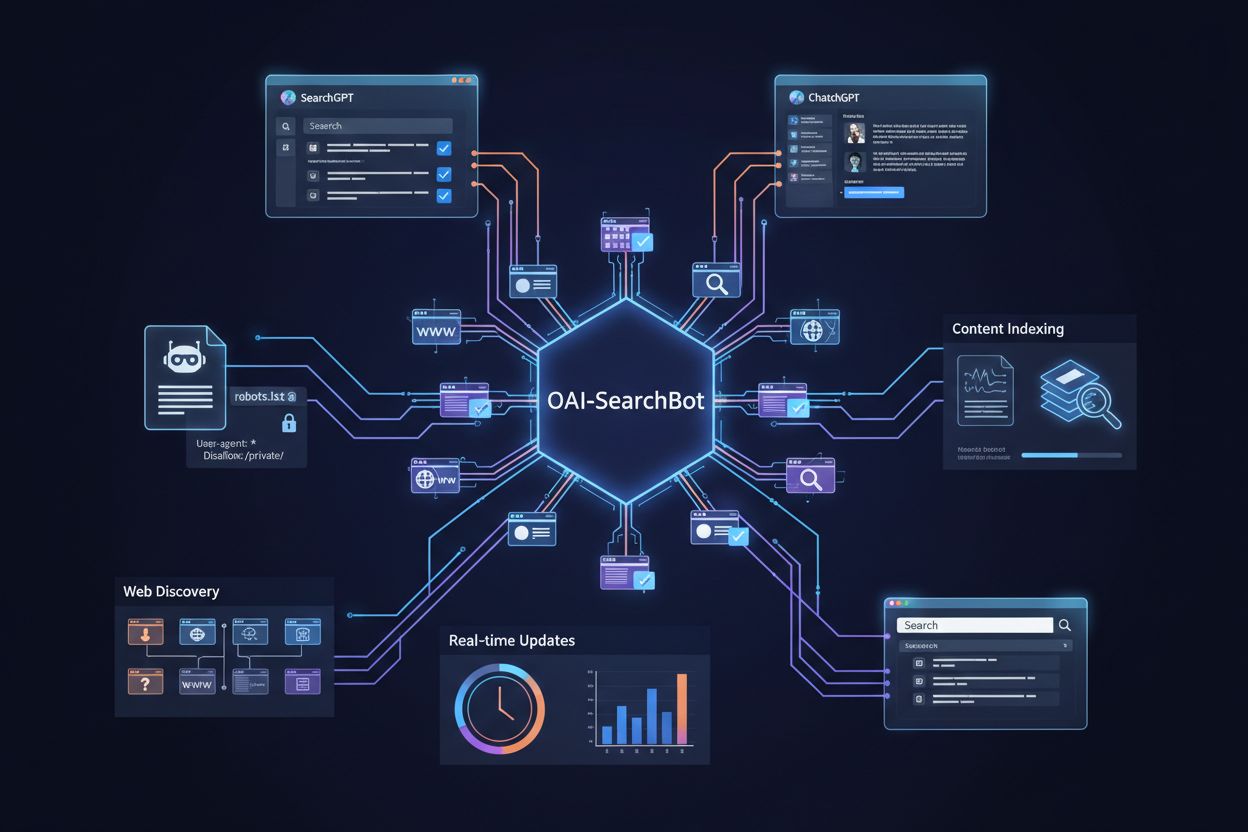
OpenAI obsługuje trzy różne typy crawlerów do różnych celów: GPTBot (ogólne crawlery sieciowe do treningu modeli), ChatGPT-User (przeszukujący linki udostępnione przez użytkowników ChatGPT) i ChatGPT-Plugins (uzyskujący dostęp do treści przez integracje pluginów) – każdy z innym user agent stringiem i wzorcem działania. Poza crawlerami OpenAI, w ekosystemie AI działa wiele innych botów konkurencyjnych firm: Google-Extended (crawling AI od Google), CCBot (Commoncrawl), Perplexity (AI search engine), Claude (model AI firmy Anthropic) i inne pojawiające się crawlery, z różnymi celami i sposobami wykorzystania danych. Właściciele stron stają przed wyborem między selektywnym blokowaniem (wybrane crawlery, jak GPTBot) a całościowym blokowaniem (wszystkie crawlery AI dla pełnej kontroli nad treścią). Rozwój liczby crawlerów AI oznacza, że blokując tylko GPTBot, nie da się w pełni ochronić swojej treści przed treningiem AI, bo inne boty mogą uzyskać do niej dostęp innymi kanałami. Niektórzy właściciele wdrażają strategie warstwowe – blokując najbardziej agresywne lub komercyjnie istotne crawlery, a dopuszczając te mniejsze lub naukowe. Zrozumienie różnic między tymi crawlerami pozwala podejmować świadome decyzje o blokowaniu w zależności od obaw o wykorzystanie danych, wpływ konkurencyjny i cele biznesowe.
Wpływ na SEO i widoczność w wyszukiwarce
Wpływ ChatGPT na zachowania wyszukiwania zmienia sposób, w jaki użytkownicy odnajdują informacje – 800 mln użytkowników tygodniowo coraz częściej korzysta z AI zamiast tradycyjnych wyszukiwarek, co zasadniczo zmienia konkurencyjność w obszarze widoczności treści. AI generuje streszczenia i wyróżnione fragmenty w odpowiedziach ChatGPT, które stają się alternatywnym kanałem odkrywania treści – oznacza to, że materiały dobrze pozycjonowane w klasycznym SEO mogą być pomijane, jeśli nie trafią do odpowiedzi generowanych przez AI. Generative Engine Optimization (GEO) staje się kluczową dziedziną dla nowoczesnych twórców, koncentrującą się na optymalizacji struktury, jasności i autorytetu treści, by zwiększyć szanse na obecność w odpowiedziach i podsumowaniach AI. Długoterminowe skutki są istotne: strony blokujące GPTBot mogą tracić możliwość pojawienia się w ChatGPT, ograniczając ruch z dynamicznie rosnącego segmentu użytkowników AI, podczas gdy otwarcie na crawling zapewnia widoczność w nowych kanałach odkrywania treści. Badania wskazują, że 86,5% treści w TOP 20 wynikach Google zawiera częściowo elementy AI, co pokazuje, że integracja AI staje się standardem, a nie niszową ciekawostką. Pozycjonowanie konkurencyjne coraz bardziej zależy od widoczności zarówno w klasycznych wyszukiwarkach, jak i systemach AI, dlatego strategiczne decyzje o dostępie dla GPTBot mają kluczowe znaczenie dla długoterminowego sukcesu SEO i wzrostu ruchu organicznego. Właściciele stron muszą wyważyć ochronę treści z ryzykiem utraty widoczności w systemach AI, które stają się głównym mechanizmem odkrywania informacji przez miliony użytkowników na świecie.
Najczęściej zadawane pytania
Czym jest GPTBot i czym różni się od Googlebota?
GPTBot to oficjalny crawler internetowy OpenAI, zaprojektowany do zbierania danych treningowych dla modeli AI, takich jak ChatGPT i GPT-4. W przeciwieństwie do Googlebota, który indeksuje treści na potrzeby wyników wyszukiwania, GPTBot gromadzi dane wyłącznie w celu ulepszania modeli językowych. Oba crawlery respektują dyrektywy robots.txt i mają dostęp tylko do publicznie dostępnych treści, jednak służą zasadniczo różnym celom w ekosystemie cyfrowym.
Czy powinienem zablokować GPTBot na mojej stronie?
Decyzja zależy od Twoich celów biznesowych i strategii treści. Zablokuj GPTBot, jeśli posiadasz treści chronione, działasz w branżach regulowanych lub masz obawy dotyczące własności intelektualnej. Pozwól na dostęp GPTBot, jeśli zależy Ci na widoczności w ChatGPT (800 mln użytkowników tygodniowo), chcesz korzystać z ruchu AI (który konwertuje 23x lepiej niż organiczny) lub zależy Ci na przyszłościowej obecności w wyszukiwaniach opartych na AI.
Jak zablokować GPTBot za pomocą robots.txt?
Dodaj te linie do pliku robots.txt, aby zablokować GPTBot na całej stronie: User-agent: GPTBot / Disallow: /. Aby zablokować wybrane katalogi, zamień ukośnik na ścieżkę katalogu. Aby zablokować wszystkie crawlery OpenAI, dodaj oddzielne wpisy User-agent dla GPTBot, ChatGPT-User i ChatGPT-Plugins. Zmiany są natychmiastowe i łatwe do cofnięcia.
Jaki jest wpływ GPTBot na mój serwer i transfer danych?
Wpływ GPTBot zależy od wielkości strony i istotności treści. Pojedynczy crawler zwykle nie stanowi dużego obciążenia, ale wiele crawlerów AI działających jednocześnie może zużywać znaczne zasoby — niektóre strony raportują ponad 30 TB miesięcznego ruchu crawlerów. Monitoruj logi serwera, aby śledzić aktywność GPTBot i wdrożyć ograniczenia transferu lub blokowanie IP, jeśli zużycie staje się problematyczne.
Czy mogę częściowo zablokować GPTBot na niektórych stronach?
Tak, możesz wykorzystać precyzyjne dyrektywy robots.txt, by zablokować GPTBot w wybranych katalogach lub stronach, pozwalając na dostęp do pozostałych. Możesz np. zablokować katalogi /private/ i /admin/, pozostawiając resztę strony dostępną. To selektywne podejście pozwala chronić wrażliwe treści, zachowując widoczność publicznych stron w systemach AI.
Skąd mam wiedzieć, że GPTBot odwiedza moją stronę?
Sprawdź logi serwera pod kątem ciągu user agent 'GPTBot/1.0' w nagłówkach HTTP żądań. Większość platform analitycznych (Google Analytics, Semrush, Ahrefs) automatycznie kategoryzuje i raportuje aktywność GPTBot. Możesz też użyć narzędzi SEO monitorujących aktywność crawlerów AI. Regularny monitoring pozwala zrozumieć częstotliwość odwiedzin i zidentyfikować ewentualny wpływ na wydajność.
Jakie są skutki prawne blokowania lub dopuszczania GPTBot?
Sytuacja prawna ciągle się kształtuje. Dopuszczenie GPTBot rodzi pytania o zgodność z RODO, CCPA oraz naruszenia praw autorskich, choć OpenAI deklaruje respektowanie dyrektyw robots.txt. Blokowanie GPTBot jest proste prawnie, ale może ograniczyć Twoją widoczność w systemach AI. Skonsultuj się z prawnikiem, jeśli działasz w branżach regulowanych lub przetwarzasz wrażliwe dane, by dobrać najlepsze rozwiązanie.
Jak wpłynie dopuszczenie GPTBot na moje SEO i widoczność?
Dopuszczenie GPTBot nie wpływa bezpośrednio na pozycje w Google, ale zwiększa Twoją widoczność w odpowiedziach ChatGPT i innych wynikach AI. Przy 800 mln użytkowników ChatGPT i ruchu AI konwertującym 23x lepiej niż organiczny, dopuszczenie GPTBot daje długofalową widoczność w systemach AI. Blokowanie GPTBot może ograniczyć szanse pojawienia się w odpowiedziach AI, zmniejszając ruch z najszybciej rosnącego segmentu wyszukiwań.
Monitoruj swoją markę w wynikach AI
Śledź, jak Twoja marka pojawia się w ChatGPT, Perplexity, Google AI i innych platformach AI. Uzyskaj bieżące informacje o cytowaniach i widoczności w AI dzięki AmICited.
Czym jest GPTBot i Czy Powinieneś Go Dopuścić? Kompletny Przewodnik dla Właścicieli Stron Internetowych
Dowiedz się, czym jest GPTBot, jak działa i czy powinieneś dopuścić lub zablokować crawlera internetowego OpenAI. Zrozum wpływ na widoczność Twojej marki w wysz...
GPTBot kontra OAI-SearchBot: Zrozumienie różnych crawlerów OpenAI
Poznaj kluczowe różnice między crawlerami GPTBot i OAI-SearchBot. Dowiedz się, jakie mają cele, jak się zachowują i jak nimi zarządzać, aby zoptymalizować widoc...
Dowiedz się czym jest OAI-SearchBot, jak działa i jak zoptymalizować swoją stronę pod dedykowanego crawlera wyszukiwarki OpenAI używanego przez SearchGPT i Chat...
6 min czytania
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.