
Pokrycie indeksu AI
Dowiedz się, czym jest pokrycie indeksu AI i dlaczego ma znaczenie dla widoczności Twojej marki w ChatGPT, Google AI Overviews i Perplexity. Poznaj czynniki tec...
7 min czytania

Pokrycie indeksu odnosi się do procentu i statusu stron internetowych, które zostały odkryte, zindeksowane i włączone do indeksu wyszukiwarki. Mierzy, które strony mogą pojawiać się w wynikach wyszukiwania oraz wskazuje techniczne problemy uniemożliwiające indeksację.
Pokrycie indeksu odnosi się do procentu i statusu stron internetowych, które zostały odkryte, zindeksowane i włączone do indeksu wyszukiwarki. Mierzy, które strony mogą pojawiać się w wynikach wyszukiwania oraz wskazuje techniczne problemy uniemożliwiające indeksację.
Pokrycie indeksu to miara tego, ile stron z Twojej witryny zostało odkrytych, zindeksowanych i włączonych do indeksu wyszukiwarki. Oznacza procent stron serwisu, które mogą pojawić się w wynikach wyszukiwania oraz identyfikuje strony napotykające techniczne problemy uniemożliwiające indeksację. W skrócie, pokrycie indeksu odpowiada na kluczowe pytanie: „Ile mojej witryny mogą faktycznie znaleźć i ocenć wyszukiwarki?”. Ten wskaźnik jest podstawą do zrozumienia widoczności witryny w wyszukiwarkach i jest monitorowany za pomocą narzędzi takich jak Google Search Console, które udostępniają szczegółowe raporty o stronach zindeksowanych, wykluczonych i z błędami. Bez odpowiedniego pokrycia indeksu nawet najlepiej zoptymalizowane treści pozostają niewidoczne zarówno dla wyszukiwarek, jak i dla użytkowników poszukujących Twoich informacji.
Pokrycie indeksu to nie tylko kwestia ilości — chodzi o to, by właściwe strony były indeksowane. Strona może mieć tysiące podstron, lecz jeśli wiele z nich to duplikaty, słabe treści lub strony blokowane przez robots.txt, rzeczywiste pokrycie indeksu może być znacznie niższe od oczekiwanego. Ta różnica między liczbą wszystkich stron a liczbą stron w indeksie jest kluczowa dla skutecznej strategii SEO. Organizacje regularnie monitorujące pokrycie indeksu mogą wykrywać i naprawiać problemy techniczne, zanim wpłyną one na ruch organiczny, co czyni pokrycie indeksu jednym z najbardziej praktycznych wskaźników w technicznym SEO.
Pojęcie pokrycia indeksu pojawiło się wraz z rozwojem wyszukiwarek z prostych crawlerów do zaawansowanych systemów przetwarzających codziennie miliony stron. W początkach SEO webmasterzy mieli ograniczony wgląd w to, jak wyszukiwarki postrzegają ich strony. Google Search Console, pierwotnie uruchomione jako Google Webmaster Tools w 2006 roku, zrewolucjonizowało przejrzystość, udostępniając bezpośrednie informacje o stanie indeksowania i crawlowania. Raport Pokrycia Indeksu (dawniej raport „Indeksowanie stron”) stał się głównym narzędziem do analizy, które strony Google zindeksował, a które wykluczył.
Wraz ze wzrostem złożoności witryn, dynamiczną treścią, parametrami i powielonymi stronami, problemy z pokryciem indeksu stały się powszechne. Badania wskazują, że około 40-60% witryn internetowych boryka się z istotnymi problemami z pokryciem indeksu, a wiele stron pozostaje nieodkrytych lub celowo wykluczonych z indeksu. Rozwój witryn opartych o JavaScript i aplikacji jednostronicowych dodatkowo utrudnił indeksację, ponieważ wyszukiwarki muszą renderować treść przed oceną indeksowalności. Obecnie monitorowanie pokrycia indeksu jest niezbędne dla każdej organizacji opierającej się na ruchu organicznym, a eksperci branżowi zalecają przeprowadzanie audytów minimum raz w miesiącu.
Relacja między pokryciem indeksu a budżetem indeksowania zyskuje na znaczeniu w miarę rozrostu stron. Budżet indeksowania to liczba stron, które Googlebot odwiedzi na Twojej witrynie w danym czasie. Duże serwisy z nieprzemyślaną architekturą lub nadmiarem powielonych treści mogą marnować budżet indeksowania na strony niskiej wartości, przez co ważne treści pozostają nieodkryte. Badania pokazują, że ponad 78% firm korzysta z różnego rodzaju narzędzi do monitorowania treści, by śledzić swoją widoczność w wyszukiwarkach i platformach AI, uznając pokrycie indeksu za fundament strategii widoczności.
| Pojęcie | Definicja | Główna kontrola | Używane narzędzia | Wpływ na pozycje |
|---|---|---|---|---|
| Pokrycie indeksu | Procent stron zindeksowanych przez wyszukiwarki | Meta tagi, robots.txt, jakość treści | Google Search Console, Bing Webmaster Tools | Bezpośredni — tylko zindeksowane strony mogą się pozycjonować |
| Crawlability | Możliwość dostępu i przeglądania stron przez boty | robots.txt, struktura witryny, linkowanie wewnętrzne | Screaming Frog, ZentroAudit, logi serwera | Pośredni — strona musi być crawlable, by być indeksowana |
| Indexability | Możliwość dodania crawlowanych stron do indeksu | Dyrektywy noindex, tagi kanoniczne, treść | Google Search Console, Narzędzie do sprawdzania adresów URL | Bezpośredni — decyduje, czy strona pojawi się w wynikach |
| Budżet indeksowania | Liczba stron crawlowanych przez Googlebot w danym czasie | Autorytet strony, jakość, błędy crawlowania | Google Search Console, logi serwera | Pośredni — decyduje, które strony zostaną zcrawlowane |
| Powielona treść | Wiele stron z identyczną lub podobną treścią | Tagi kanoniczne, przekierowania 301, noindex | Narzędzia SEO, ręczna analiza | Negatywny — rozprasza potencjał pozycjonowania |
Pokrycie indeksu działa w trzech etapach: odkrycie, crawlowanie i indeksowanie. W fazie odkrycia wyszukiwarki znajdują adresy URL za pomocą różnych metod, takich jak mapy witryny XML, linki wewnętrzne, backlinki zewnętrzne czy ręczne zgłoszenia przez Google Search Console. Po odkryciu adresy URL trafiają do kolejki crawlowania, gdzie Googlebot pobiera stronę i analizuje jej treść. Ostatecznie, podczas indeksowania, Google przetwarza zawartość strony, określa jej adekwatność i jakość oraz decyduje, czy dodać ją do indeksu.
Raport Pokrycia Indeksu w Google Search Console dzieli strony na cztery główne statusy: Prawidłowe (zindeksowane), Prawidłowe z ostrzeżeniami (zindeksowane z problemami), Wykluczone (celowo nieindeksowane) i Błąd (strony, których nie udało się zindeksować). W każdym statusie znajdują się konkretne typy problemów, które szczegółowo wyjaśniają, dlaczego dana strona została (lub nie) zindeksowana. Przykładowo, strony mogą być wykluczone z powodu meta tagu noindex, blokady przez robots.txt, powielenia bez odpowiednich tagów kanonicznych lub błędów HTTP 4xx czy 5xx.
Zrozumienie technicznych mechanizmów pokrycia indeksu wymaga znajomości kilku kluczowych elementów. Plik robots.txt to plik tekstowy w katalogu głównym witryny, który instruuje roboty wyszukiwarek, do których katalogów i plików mają dostęp. Nieprawidłowa konfiguracja robots.txt jest jedną z najczęstszych przyczyn problemów z pokryciem indeksu — przypadkowe zablokowanie ważnych katalogów uniemożliwia Google ich odkrycie. Meta tag robots umieszczony w sekcji head HTML strony daje instrukcje na poziomie strony za pomocą dyrektyw takich jak index, noindex, follow i nofollow. Tag kanoniczny (rel=“canonical”) informuje wyszukiwarki, która wersja strony jest preferowana w przypadku duplikatów, zapobiegając nadmiernemu rozrostowi indeksu i konsolidując sygnały rankingowe.
Dla firm opierających się na ruchu organicznym pokrycie indeksu bezpośrednio wpływa na przychody i widoczność. Gdy ważne strony nie są zindeksowane, nie mogą pojawić się w wynikach wyszukiwania, co oznacza, że potencjalni klienci nie znajdą ich przez Google. Sklepy internetowe z niskim pokryciem indeksu mogą mieć strony produktowe w statusie „Odkryto – obecnie niezaindeksowana”, co skutkuje utratą sprzedaży. Platformy content marketingowe z tysiącami artykułów potrzebują solidnego pokrycia indeksu, by dotrzeć do odbiorców. Firmy SaaS polegają na zindeksowanej dokumentacji i wpisach blogowych, by zdobywać leady organiczne.
Konsekwencje praktyczne wykraczają poza tradycyjne wyszukiwanie. Wraz z rozwojem generatywnych platform AI takich jak ChatGPT, Perplexity czy Google AI Overviews, pokrycie indeksu zyskało znaczenie także dla widoczności w AI. Systemy te często opierają się na zindeksowanych treściach internetowych jako źródłach danych treningowych i cytowań. Jeśli Twoje strony nie są prawidłowo zindeksowane przez Google, jest mniej prawdopodobne, że trafią do zbiorów treningowych AI lub zostaną zacytowane w odpowiedziach generowanych przez AI. Tworzy to narastający problem widoczności: słabe pokrycie indeksu wpływa zarówno na pozycje w klasycznych wynikach wyszukiwania, jak i na obecność w treściach generowanych przez AI.
Firmy proaktywnie monitorujące pokrycie indeksu odnotowują wymierne wzrosty ruchu organicznego. Typową sytuacją jest wykrycie, że 30-40% zgłoszonych adresów URL jest wykluczonych z powodu tagów noindex, powielonych treści lub błędów crawlowania. Po naprawie — usunięciu zbędnych tagów noindex, wdrożeniu odpowiedniej kanonikalizacji i naprawieniu błędów crawlowania — liczba zindeksowanych stron często rośnie o 20-50%, co bezpośrednio przekłada się na lepszą widoczność organiczną. Koszt bezczynności jest znaczący: każdy miesiąc, w którym strona pozostaje poza indeksem, to miesiąc utraconego potencjalnego ruchu i konwersji.
Google Search Console pozostaje podstawowym narzędziem do monitorowania pokrycia indeksu, dostarczając najwiarygodniejszych danych o decyzjach Google dotyczących indeksowania. Raport Pokrycia Indeksu pokazuje zindeksowane strony, strony z ostrzeżeniami, wykluczone i błędne, wraz ze szczegółowym wykazem typów problemów. Google udostępnia także Narzędzie do sprawdzania adresów URL, które pozwala sprawdzić status indeksowania pojedynczych stron oraz zgłosić nowe lub zaktualizowane treści do indeksowania. Jest to niezwykle pomocne w rozwiązywaniu problemów z konkretnymi stronami i zrozumieniu, dlaczego Google ich nie indeksuje.
Bing Webmaster Tools oferuje podobne funkcje poprzez Index Explorer i URL Submission. Choć udział Binga w rynku jest mniejszy niż Google, wciąż jest ważny dla użytkowników preferujących tę wyszukiwarkę. Dane o pokryciu indeksu w Bing czasem różnią się od danych Google, ujawniając problemy specyficzne dla algorytmów crawlowania i indeksowania Binga. Firmy zarządzające dużymi serwisami powinny monitorować obie platformy, by zapewnić pełne pokrycie.
Dla monitorowania AI i widoczności marki platformy takie jak AmICited śledzą sposób prezentacji marki i domeny w ChatGPT, Perplexity, Google AI Overviews i Claude. Narzędzia te łączą tradycyjne pokrycie indeksu z widocznością w AI, pomagając firmom zrozumieć, jak ich zindeksowane treści przekładają się na cytowania w odpowiedziach generowanych przez AI. Ta integracja staje się kluczowa dla nowoczesnej strategii SEO, gdyż widoczność w systemach AI coraz mocniej wpływa na świadomość marki i ruch.
Zewnętrzne narzędzia do audytu SEO takie jak Ahrefs, SEMrush czy Screaming Frog dostarczają dodatkowych informacji o pokryciu indeksu poprzez niezależne crawlowanie witryny i porównanie wyników z raportami Google. Rozbieżności między crawlami a raportami Google mogą wskazywać na problemy z renderowaniem JavaScript, błędy serwera czy ograniczenia budżetu indeksowania. Narzędzia te wykrywają także strony osierocone (bez linkowania wewnętrznego), które często mają problemy z indeksacją.
Poprawa pokrycia indeksu wymaga systematycznego podejścia do kwestii technicznych i strategicznych. Najpierw przeprowadź audyt obecnego stanu w Google Search Console, korzystając z raportu pokrycia indeksu. Zidentyfikuj główne typy problemów — czy są to tagi noindex, blokady robots.txt, powielone treści, czy błędy crawlowania. Nadaj priorytet kwestiom według wpływu: strony, które powinny być zindeksowane, a nie są, są ważniejsze niż te, które słusznie zostały wykluczone.
Po drugie, napraw błędy w robots.txt poprzez przegląd pliku i upewnienie się, że nie blokujesz przypadkiem ważnych katalogów. Częstym błędem jest blokowanie katalogów takich jak /admin/, /staging/ czy /temp/, które powinny być zablokowane, ale również przypadkowe blokowanie publicznych sekcji jak /blog/, /products/ itp. Wykorzystaj tester robots.txt w Google Search Console, by zweryfikować, że kluczowe strony nie są blokowane.
Po trzecie, wdrażaj prawidłową kanonikalizację dla powielonych treści. Jeśli masz wiele adresów URL prowadzących do podobnych treści (np. strony produktów dostępne przez różne ścieżki kategorii), stosuj kanoniczne tagi samoodwołujące się na każdej stronie lub używaj przekierowań 301 do wersji preferowanej. Zapobiega to rozrostowi indeksu i konsoliduje sygnały rankingowe na wybranej wersji.
Po czwarte, usuń zbędne tagi noindex ze stron, które powinny być zindeksowane. Przeprowadź audyt w poszukiwaniu dyrektyw noindex, zwłaszcza na środowiskach testowych, które mogły zostać przypadkowo wdrożone na produkcji. Skorzystaj z Narzędzia do sprawdzania adresów URL, by upewnić się, że ważne strony nie mają tagów noindex.
Po piąte, zgłoś mapę witryny XML w Google Search Console, zawierającą wyłącznie indeksowalne adresy URL. Dbaj o czystość mapy, wykluczając strony z tagami noindex, przekierowaniami lub błędami 404. W przypadku dużych serwisów rozważ podział map na typy treści lub sekcje, by zachować lepszą organizację i uzyskać dokładniejsze raporty o błędach.
Po szóste, napraw błędy crawlowania takie jak niedziałające linki (404), błędy serwera (5xx) i łańcuchy przekierowań. Wykorzystaj Google Search Console do wskazania dotkniętych stron, a następnie systematycznie usuwaj problemy. W przypadku błędów 404 na ważnych stronach przywróć treść lub ustaw przekierowanie 301 do powiązanej strony.
Przyszłość pokrycia indeksu ewoluuje wraz ze zmianami technologicznymi w wyszukiwarkach i rozwojem generatywnych systemów AI. W miarę jak Google udoskonala wymagania Core Web Vitals oraz standardy E-E-A-T (Doświadczenie, Ekspertyza, Autorytatywność, Wiarygodność), pokrycie indeksu będzie coraz bardziej zależne od jakości treści i wskaźników doświadczenia użytkownika. Strony z niskimi wynikami Core Web Vitals lub ubogą treścią mogą napotykać trudności z indeksacją, nawet jeśli są technicznie dostępne.
Rozwój wyników wyszukiwania generowanych przez AI i silników odpowiedzi zmienia znaczenie pokrycia indeksu. W tradycyjnym SEO pozycje zależą od stron w indeksie, ale systemy AI mogą cytować treści indeksowane inaczej lub priorytetyzować określone źródła. Organizacje będą musiały monitorować nie tylko to, czy strony są indeksowane przez Google, ale także czy są cytowane i referencjonowane przez platformy AI. Ten podwójny wymóg widoczności oznacza, że monitoring pokrycia indeksu musi wykraczać poza Google Search Console i obejmować platformy monitorujące AI, śledzące obecność marki w ChatGPT, Perplexity i innych systemach generatywnych.
Renderowanie JavaScriptu i treści dynamiczne nadal będą komplikować pokrycie indeksu. Wraz z rosnącą popularnością frameworków JS i aplikacji jednostronicowych wyszukiwarki muszą renderować JavaScript, by zrozumieć zawartość strony. Google usprawnił renderowanie JS, lecz nadal pojawiają się problemy. Przyszłe dobre praktyki zapewne będą podkreślać renderowanie po stronie serwera lub renderowanie dynamiczne, by treść była dostępna dla crawlerów bez konieczności interpretacji JavaScriptu.
Integracja danych strukturalnych i schema.org będzie coraz ważniejsza dla pokrycia indeksu. Wyszukiwarki wykorzystują dane strukturalne, by lepiej rozumieć treść i kontekst strony, co może poprawić decyzje indeksacyjne. Firmy wdrażające kompleksowe oznaczenia schema dla swoich typów treści — artykułów, produktów, wydarzeń, FAQ — mogą osiągnąć lepsze pokrycie indeksu i widoczność w wynikach rozszerzonych.
Wreszcie, pojęcie pokrycia indeksu rozszerzy się poza strony na encje i tematy. Zamiast jedynie śledzić, czy strony są zindeksowane, przyszły monitoring będzie skupiać się na tym, czy marka, produkty i tematy są właściwie reprezentowane w grafach wiedzy wyszukiwarek i zbiorach treningowych AI. To fundamentalna zmiana z monitorowania na poziomie strony na monitorowanie na poziomie encji, wymagająca nowych metod i strategii.
+++
Crawlability odnosi się do tego, czy roboty wyszukiwarek mogą uzyskać dostęp i nawigować po stronach Twojej witryny, co kontrolowane jest przez takie czynniki jak robots.txt i struktura strony. Indexability natomiast określa, czy zindeksowane strony faktycznie zostaną dodane do indeksu wyszukiwarki; kontrolują to meta tagi robots, tagi kanoniczne oraz jakość treści. Strona musi być crawlable, by mogła być indexable, ale samo crawlability nie gwarantuje indeksacji.
Dla większości stron internetowych wystarczy sprawdzanie pokrycia indeksu raz w miesiącu, aby wychwycić główne problemy. Jednak w przypadku istotnych zmian w strukturze strony, regularnej publikacji nowych treści lub migracji, monitoruj raport co tydzień lub dwa tygodnie. Google wysyła powiadomienia mailowe o pilnych problemach, lecz są one często opóźnione, więc proaktywne monitorowanie jest kluczowe dla utrzymania optymalnej widoczności.
Ten status oznacza, że Google znalazł adres URL (zazwyczaj przez mapy witryn lub linki wewnętrzne), ale jeszcze go nie zindeksował. Może się tak dziać z powodu ograniczeń budżetu indeksowania, gdy Google priorytetyzuje inne strony Twojej witryny. Jeśli ważne strony przez dłuższy czas mają ten status, może to sygnalizować problemy z budżetem indeksowania lub niską autorytetem witryny, które należy rozwiązać.
Tak, zgłoszenie mapy witryny XML w Google Search Console pomaga wyszukiwarkom odkryć i priorytetyzować strony do indeksowania. Dobrze utrzymana mapa witryny, zawierająca tylko indeksowalne adresy URL, może znacząco poprawić pokrycie indeksu, kierując budżet indeksowania Google na najważniejsze treści i skracając czas potrzebny na ich odkrycie.
Do typowych problemów należą strony blokowane przez robots.txt, tagi meta noindex na ważnych stronach, powielone treści bez właściwej kanonikalizacji, błędy serwera (5xx), łańcuchy przekierowań i zbyt ubogie treści. Dodatkowo, błędy 404, soft 404 oraz strony wymagające autoryzacji (błędy 401/403) często pojawiają się w raportach pokrycia indeksu i wymagają naprawy, by poprawić widoczność.
Pokrycie indeksu bezpośrednio wpływa na to, czy Twoje treści pojawiają się w odpowiedziach generowanych przez AI na platformach takich jak ChatGPT, Perplexity czy Google AI Overviews. Jeśli Twoje strony nie są prawidłowo zindeksowane przez Google, jest mniej prawdopodobne, że zostaną uwzględnione w danych treningowych lub cytowane przez systemy AI. Monitorowanie pokrycia indeksu zapewnia, że treści Twojej marki są wykrywalne i cytowalne zarówno w tradycyjnych wyszukiwarkach, jak i na platformach generatywnej AI.
Budżet indeksowania to liczba stron, które Googlebot odwiedzi w określonym czasie na Twojej stronie. Serwisy z niską efektywnością budżetu indeksowania mogą mieć wiele stron w statusie 'Odkryto – obecnie niezaindeksowana'. Optymalizacja budżetu indeksowania poprzez naprawę błędów indeksowania, usuwanie powielonych adresów URL i strategiczne użycie robots.txt sprawia, że Google skupia się na indeksowaniu najbardziej wartościowych treści.
Nie, nie wszystkie strony powinny być indeksowane. Strony takie jak środowiska testowe, powielone warianty produktów, wewnętrzne wyniki wyszukiwania i archiwa polityki prywatności zwykle lepiej wykluczyć z indeksu za pomocą tagów noindex lub robots.txt. Celem jest indeksowanie tylko wartościowych, unikalnych treści, które odpowiadają na potrzeby użytkowników i wspierają ogólną wydajność SEO witryny.
Zacznij śledzić, jak chatboty AI wspominają Twoją markę w ChatGPT, Perplexity i innych platformach. Uzyskaj praktyczne spostrzeżenia, aby poprawić swoją obecność w AI.
Dowiedz się, czym jest pokrycie indeksu AI i dlaczego ma znaczenie dla widoczności Twojej marki w ChatGPT, Google AI Overviews i Perplexity. Poznaj czynniki tec...
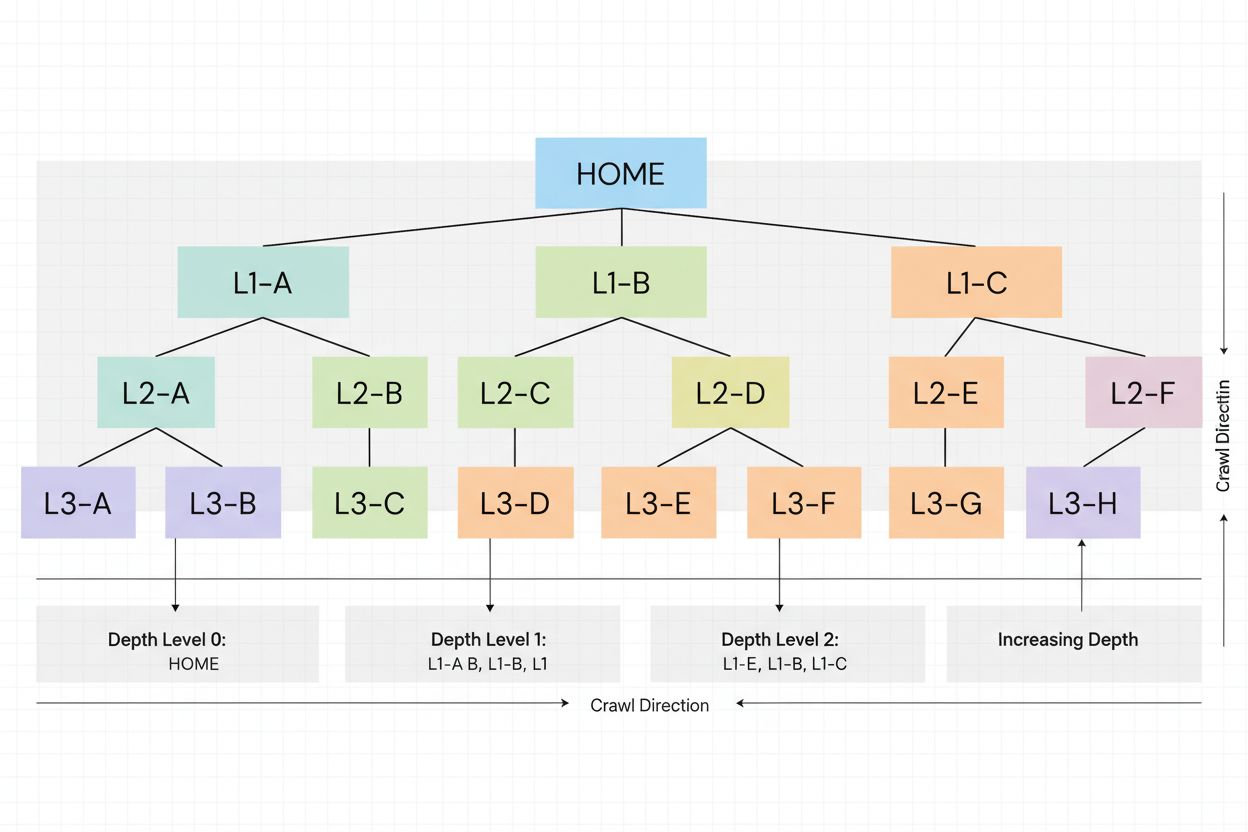
Głębokość indeksowania to miara, jak głęboko roboty wyszukiwarek docierają w strukturze Twojej strony. Dowiedz się, dlaczego jest ważna dla SEO, jak wpływa na i...
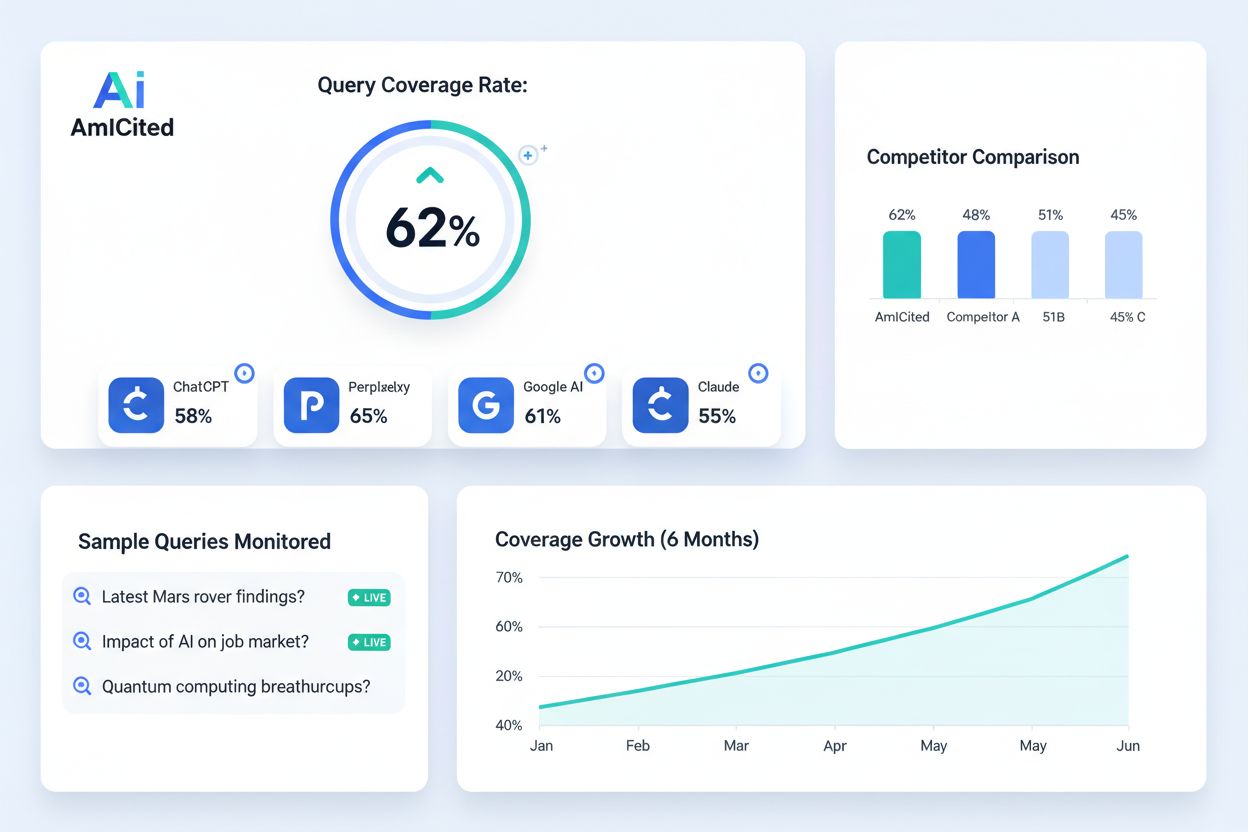
Dowiedz się, czym jest wskaźnik pokrycia zapytań, jak go mierzyć i dlaczego jest kluczowy dla widoczności marki w wyszukiwarkach zasilanych AI. Poznaj benchmark...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.