
Gęstość Informacji: Tworzenie Treści Nasyconych Wartością dla AI
Dowiedz się, jak tworzyć treści o wysokiej gęstości informacji, które preferują systemy AI. Opanuj hipotezę Jednolitej Gęstości Informacji i zoptymalizuj swoje ...
9 min czytania
Gęstość informacji to stosunek użytecznych, unikalnych informacji do całkowitej długości treści. Wyższa gęstość zwiększa prawdopodobieństwo cytowania przez AI, ponieważ systemy AI priorytetowo traktują treści dostarczające maksymalnej wiedzy przy minimalnej liczbie słów. Oznacza to odejście od optymalizacji skupionej na słowach kluczowych na rzecz optymalizacji informacyjnej, gdzie każde zdanie musi wnosić odrębną wartość. Ten wskaźnik bezpośrednio wpływa na to, czy systemy AI pozyskują, oceniają i cytują Twoje treści jako autorytatywne źródła.
Gęstość informacji to stosunek użytecznych, unikalnych informacji do całkowitej długości treści. Wyższa gęstość zwiększa prawdopodobieństwo cytowania przez AI, ponieważ systemy AI priorytetowo traktują treści dostarczające maksymalnej wiedzy przy minimalnej liczbie słów. Oznacza to odejście od optymalizacji skupionej na słowach kluczowych na rzecz optymalizacji informacyjnej, gdzie każde zdanie musi wnosić odrębną wartość. Ten wskaźnik bezpośrednio wpływa na to, czy systemy AI pozyskują, oceniają i cytują Twoje treści jako autorytatywne źródła.
Gęstość informacji to stosunek użytecznych, unikalnych i praktycznych informacji do całkowitej długości treści — kluczowy wskaźnik określający, jak skutecznie systemy AI mogą wydobyć, ocenić i zacytować Twoje materiały. W przeciwieństwie do wcześniejszej gęstości słów kluczowych, mierzącej procent docelowych fraz w tekście, gęstość informacji skupia się na faktycznej wartości i precyzji każdego zdania. Systemy AI, szczególnie duże modele językowe zasilające GPT, Perplexity oraz Google AI Overviews, priorytetowo traktują treści dostarczające maksymalnej wiedzy przy minimalnej liczbie słów. Preferencja ta wynika z mechanizmów przetwarzania informacji: systemy AI nagradzają bogactwo semantyczne — głębię przekazu na jednostkę tekstu — zamiast powtarzania słów kluczowych. Gdy AI natrafia na treść o wysokiej gęstości informacji, rozpoznaje ją jako autorytatywną, precyzyjną i wartą cytowania, bo każde zdanie wnosi odrębną wartość zamiast wypełniaczy czy powtórzeń. Rozważ różnicę między tymi dwoma podejściami do wyjaśniania energii odnawialnej: Wersja o niskiej gęstości może brzmieć: “Energia odnawialna jest ważna. Energia odnawialna pochodzi z natury. Energia odnawialna jest czysta. Wiele osób korzysta z energii odnawialnej.” Ten zestaw zdań zużywa 24 słowa, by przekazać jedną ogólną ideę bez konkretów. Wersja o wysokiej gęstości: “Systemy fotowoltaiczne zamieniają 15–22% padającego światła słonecznego w prąd, a nowoczesne turbiny wiatrowe osiągają 35–45% sprawności, co czyni je realną alternatywą dla elektrowni węglowych pracujących z wydajnością 33–48%.” Ta wersja używa 28 słów, by przekazać konkretne wskaźniki wydajności, terminologię techniczną i analizę porównawczą — znacznie większą wartość informacyjną.
| Aspekt | Niska gęstość | Wysoka gęstość |
|---|---|---|
| Liczba słów | 24 słowa | 28 słów |
| Punkty danych | 0 | 4 konkretne procenty |
| Terminy techniczne | 0 | 3 (fotowoltaiczny, współczynnik sprawności, wydajność) |
| Wartość porównawcza | Ogólnik | Bezpośrednie porównanie trzech źródeł energii |
| Szansa na cytowanie | Niska | Wysoka |
To rozróżnienie ma kluczowe znaczenie dla cytowań przez AI. Gdy AI skanuje treści w poszukiwaniu odpowiedzi, ocenia nie tylko trafność, ale i konkretność informacji — obecność danych liczbowych, nazw własnych, terminologii technicznej i bezpośrednich odpowiedzi. Treści o wysokiej gęstości sygnalizują ekspertyzę i dostarczają precyzyjnych informacji, które AI potrzebuje do tworzenia pewnych odpowiedzi z prawidłowym przypisaniem źródła. To przejście z optymalizacji skupionej na słowach kluczowych na optymalizację informacyjną odzwierciedla rzeczywiste kryteria oceny jakości przez nowoczesne AI.
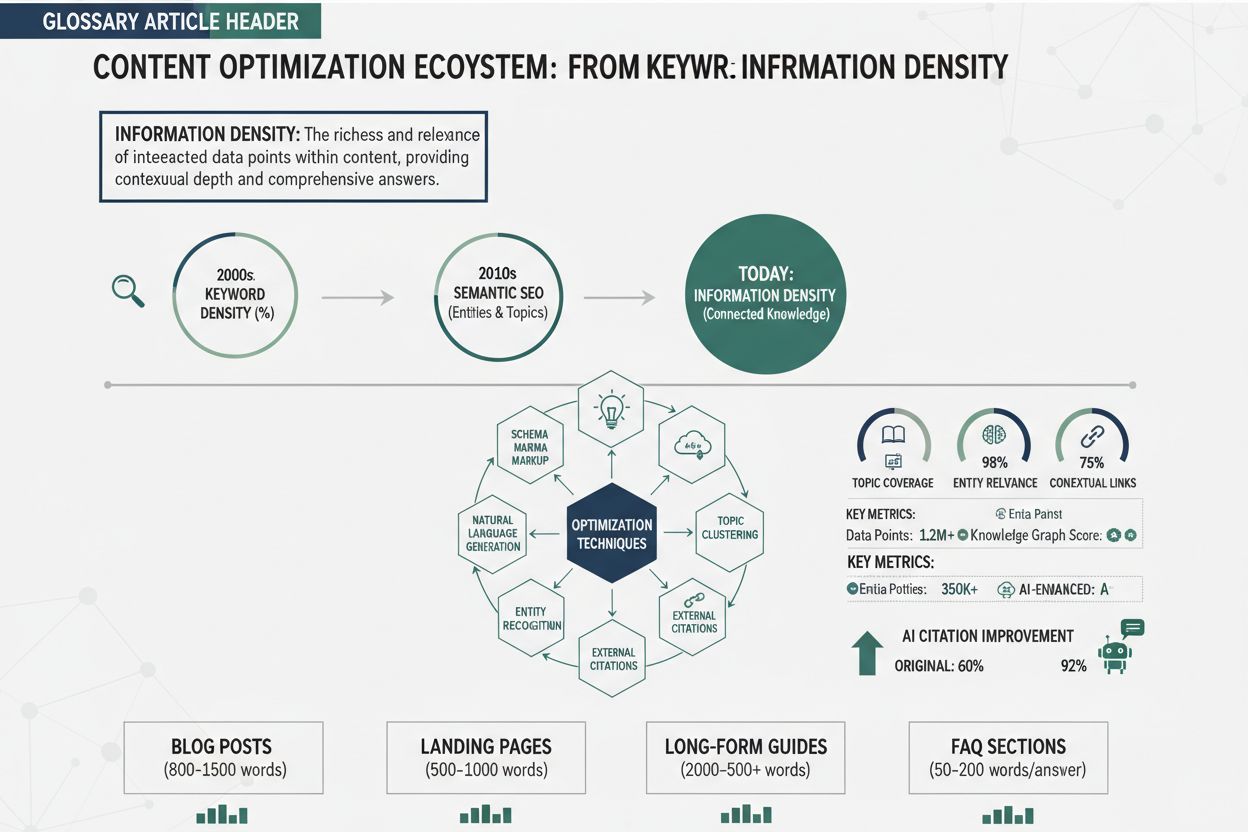
Ewolucja od gęstości słów kluczowych do gęstości informacji to fundamentalna zmiana sposobu, w jaki wyszukiwarki i AI oceniają jakość treści. Gęstość słów kluczowych — pierwotny wskaźnik SEO — mierzyła procent docelowych fraz względem całości tekstu, zwykle celując w 1–3%. Ta metoda wynikała z wczesnych algorytmów wyszukiwarek, które opierały się głównie na dopasowaniu słów kluczowych do zapytań. Jednak optymalizacja pod kątem gęstości słów kluczowych szybko przerodziła się w keyword stuffing — praktykę sztucznego upychania fraz, co obniżało czytelność i wartość treści. Sformułowania typu “najlepsza pizzeria, najlepsza pizza, pizzeria w mojej okolicy, najlepsza pizza w pobliżu” powtarzane na stronie to przykład takiego pustego podejścia — wysoka gęstość słów kluczowych, zero nowych informacji. Główną wadą tej optymalizacji było założenie, że wyszukiwarki doceniają częstotliwość fraz bardziej niż jakość treści, co prowadziło do wyścigu na ilość, a nie jakość.
Wprowadzenie uczenia maszynowego i rozumienia semantycznego diametralnie zmieniło sytuację. Współczesne AI, wytrenowane na miliardach przykładów tekstów, nauczyły się rozpoznawać i karać keyword stuffing, a nagradzać trafność semantyczną — powiązania koncepcyjne treści z zapytaniem, niezależnie od ścisłego dopasowania fraz. Latent Semantic Indexing (LSI) oraz późniejsze modele transformerowe, takie jak BERT, dowiodły, że wyszukiwarki mogą rozumieć znaczenie, kontekst i autorytet tematyczny bez polegania na częstotliwości słów kluczowych. To otworzyło nowe podejście do optymalizacji: zamiast powtarzać frazy, twórcy mogą pisać naturalnie, dbając, by każde zdanie wnosiło unikalną wartość. Rozwój ten wygląda następująco:
Dzisiejsze AI oceniają treści przez pryzmat gęstości informacji, pytając nie “ile razy pojawia się słowo kluczowe?”, lecz “ile unikalnych, wartościowych, precyzyjnych informacji zawiera ten tekst?”. To całkowite odwrócenie paradygmatu gęstości słów kluczowych, nagradzające twórców skupiających się na maksymalnej wartości, nie na powtórzeniach.
Systemy AI pozyskują i cytują treści poprzez zaawansowany proces zwany indeksowaniem fragmentów (passage indexing), w którym obszerne dokumenty są dzielone na mniejsze, semantycznie spójne fragmenty oceniane pod kątem trafności i jakości. Gdy użytkownik kieruje zapytanie do AI, model nie szuka jedynie fraz — przeszukuje miliony fragmentów, by odnaleźć najbardziej relewantne, autorytatywne i konkretne informacje. Gęstość informacji wpływa bezpośrednio na ten proces, bo systemy AI przyznają wyższe oceny fragmentom zawierającym skoncentrowane, precyzyjne informacje. Fragment z trzema konkretnymi danymi, nazwami własnymi i terminologią techniczną otrzymuje wyższą ocenę niż równie długi fragment pełen ogólników i powtórzeń. Ten mechanizm oceny determinuje zachowanie cytowania: AI cytuje źródła ocenione jako autorytatywne i konkretne, a treści o wysokiej gęstości regularnie uzyskują takie oceny.
Koncepcja gęstości odpowiedzi tłumaczy to jeszcze lepiej. Gęstość odpowiedzi mierzy, jak bezpośrednio i kompletnie fragment odpowiada na konkretne pytanie w ramach swojej długości. Fragment 200 słów odpowiadający wprost, z konkretnymi danymi, metodologią i kontekstem, wykazuje wysoką gęstość odpowiedzi i otrzymuje silne sygnały cytowania. Taki sam objętościowo fragment wypełniony wstępami, zastrzeżeniami i dygresjami ma niską gęstość odpowiedzi i jest rzadziej cytowany. AI optymalizuje pod kątem gęstości odpowiedzi, ponieważ koreluje ona z satysfakcją użytkownika — odbiorcy preferują bezpośrednie, konkretne odpowiedzi od rozwlekłych wyjaśnień. Kluczowe elementy zwiększające gęstość informacji i cytowalność to:
Badania pokazują, że fragmenty zawierające 3+ konkretne dane są cytowane przez AI 2,5x częściej niż ogólnikowe. Odpowiadanie w pierwszych 1–2 zdaniach zwiększa częstotliwość pobierania przez AI o 40%. To dowodzi, że gęstość informacji to nie tylko preferencja stylistyczna — to mierzalny czynnik bezpośrednio wpływający na to, czy AI odnajdzie, oceni i zacytuje Twoją treść. Optymalizując gęstość informacji, optymalizujesz pod rzeczywiste mechanizmy selekcji źródeł przez systemy AI.
Poprawa gęstości informacji wymaga systematycznego wdrożenia konkretnych technik eliminujących wypełniacze, dodających konkrety i odpowiednio strukturyzujących treść pod kątem AI. Oto sześć praktycznych metod, dzięki którym przekształcisz ogólną treść w materiał o wysokiej gęstości, rozpoznawany przez AI jako autorytatywny i wart cytowania:
1. Usuń zbędne wypełniacze i frazy ogólne: Pozbądź się wstępnych zwrotów, przejściowych zdań i powtórzeń, które nie wnoszą wartości.
Przed: “W dzisiejszych czasach ważne jest rozumienie, że energia odnawialna zyskuje popularność i coraz więcej osób z niej korzysta.” (24 słowa, brak informacji)
Po: “Instalacje fotowoltaiczne wzrosły o 23% rocznie w latach 2020–2023, stanowiąc obecnie 4,2% produkcji energii elektrycznej w USA.” (15 słów, trzy konkretne dane)
2. Dodaj konkretne dane i wskaźniki: Zastąp ogólniki liczbami, procentami, datami i pomiarami świadczącymi o kompetencji.
Przed: “Wiele firm korzysta z chmury, bo to opłacalne.” (8 słów)
Po: “Chmura obniża koszty IT o 30–40%, a wdrożenie skraca z tygodni do godzin, według badań Gartnera z 2023 r.” (21 słów, cztery konkretne dane)
3. Używaj terminologii technicznej i branżowej: Wprowadź precyzyjne słownictwo, które sygnalizuje ekspertyzę i pomaga AI rozpoznać autorytet tematyczny.
Przed: “Przyspieszenie stron www wymaga kilku ulepszeń technicznych.” (10 słów)
Po: “Optymalizacja Core Web Vitals — skrócenie Largest Contentful Paint do <2,5 s, First Input Delay do <100 ms, Cumulative Layout Shift do <0,1 — bezpośrednio zwiększa konwersję.” (27 słów, precyzja techniczna)
4. Odpowiadaj bezpośrednio i natychmiast: Stawiaj wnioski i konkrety na początku, nie stopniowo.
Przed: “Przy wyborze narzędzia do zarządzania projektami należy wziąć pod uwagę wiele czynników. Różne narzędzia oferują różne funkcje. Niektóre są lepsze dla wybranych zespołów. Najlepsze zależy od potrzeb. Asana sprawdza się w dużych zespołach.” (38 słów)
Po: “Asana usprawnia pracę dużych zespołów dzięki 15+ typom pól, wizualizacji osi czasu i zarządzaniu portfelem — idealna dla zespołów powyżej 50 osób realizujących 100+ projektów równocześnie.” (25 słów, konkretna odpowiedź)
5. Strukturyzuj treść jak feed danych: Organizuj informacje w listy, tabele i struktury łatwe do przetwarzania przez AI.
Przed: “Podejście to daje kilka korzyści. Oszczędza czas. Ogranicza błędy. Poprawia jakość. Obniża koszty.” (21 słów)
Po: Lista strukturalna: “Korzyści: 40% mniej czasu, 92% mniej błędów, 3,2x lepsza jakość, 35% oszczędności” (13 słów, konkret, przejrzystość)
6. Przepisz pod kątem pewności i stanowczości: Zastąp ogólniki i zastrzeżenia pewnymi, opartymi na danych stwierdzeniami.
Przed: “Możliwe, że to rozwiązanie może potencjalnie pomóc w poprawie wyników w niektórych przypadkach.” (15 słów, brak pewności)
Po: “To podejście zwiększyło konwersję o 18% w 47 testach A/B przez 12 miesięcy.” (14 słów, duża pewność)
Te techniki działają synergicznie: wdrożenie wszystkich sześciu przekształca ogólną treść w materiał o wysokiej gęstości, który AI rozpoznaje, pobiera i cytuje z pewnością.
Powielany mit głosi, że dłuższe treści lepiej się pozycjonują i częściej są cytowane — to błędna interpretacja korelacji jako przyczyny. W rzeczywistości długość treści nie jest czynnikiem rankingowym dla AI; liczy się gęstość informacji. Długie teksty pełne wypełniaczy, powtórzeń i ogólników wypadają gorzej niż krótkie, ale konkretne i wartościowe. Artykuł 800-słowny z ogólnikami będzie rzadziej cytowany niż 400-słowny tekst nasycony konkretami. AI ocenia jakość przez gęstość semantyczną — ilość znaczących informacji na jednostkę tekstu, nie przez liczbę słów.
Odpowiednia długość zależy całkowicie od intencji użytkownika i złożoności zagadnienia. Proste pytanie “Jaka jest temperatura wrzenia wody?” wymaga 1–2 zdań o wysokiej gęstości; rozbudowanie do 2 000 słów byłoby nieefektywne. Za to temat typu “Jak wdrożyć machine learning w systemach korporacyjnych” może wymagać 3 000–5 000 słów, by wyczerpać wątek — ale tylko jeśli każde zdanie wnosi unikalną wartość. Strategia jakości nad ilością oznacza pisanie do minimalnej wymaganej długości, maksymalizując gęstość informacji w każdym zdaniu. Kluczowe wyznaczniki długości:
Dla przykładu, dwie strategie wyjaśniania kryptowalut: Artykuł 3 000 słów opisujący blockchain, kopanie, portfele, giełdy i regulacje w ogólnych słowach ma niską gęstość informacji. 1 200-słowny tekst o tych samych tematach, ale z konkretnymi danymi, aktualnymi statystykami, źródłami prawnymi i praktycznymi wskazówkami ma wysoką gęstość i jest częściej cytowany przez AI. Krótszy, gęściejszy tekst przewyższa dłuższy, rozwlekły, bo AI uznaje go za bardziej autorytatywny i wartościowy. To fundamentalnie zmienia strategię: zamiast pytać “Ile słów powinien mieć artykuł?”, należy zapytać “Jakich konkretnych informacji wymaga temat i jak przekazać je najefektywniej?”
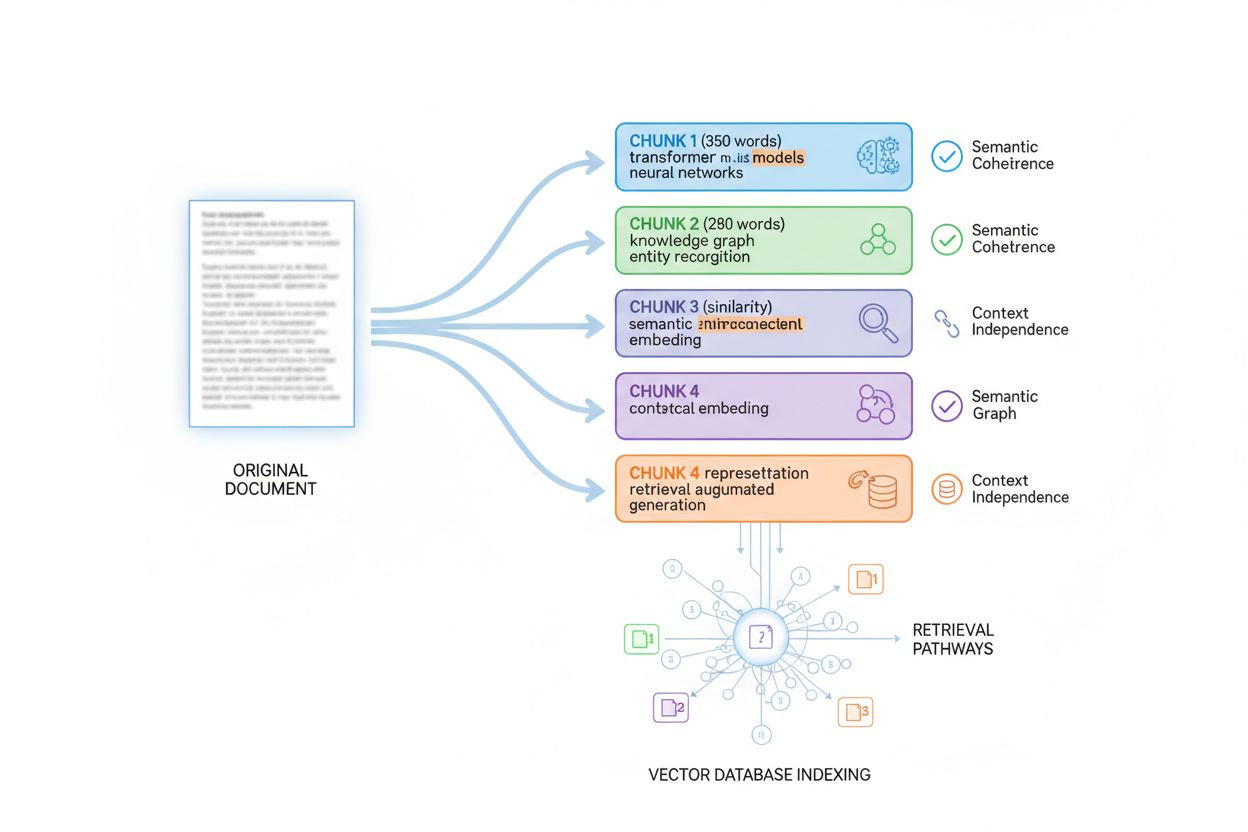
AI nie ocenia treści jako całościowych dokumentów; stosuje indeksowanie fragmentów (passage indexing), czyli dzielenie dużych tekstów na mniejsze, semantycznie spójne części oceniane i pobierane niezależnie. Zrozumienie tego procesu jest kluczowe dla optymalizacji gęstości informacji, bo decyduje o tym, jak Twoja treść będzie fragmentowana, indeksowana i odnajdywana. Większość AI dzieli tekst na fragmenty po 200–400 słów, choć w zależności od typu treści i granic semantycznych wartości te mogą się różnić. Każdy fragment musi być niezależny kontekstowo — powinien stanowić zamkniętą całość, odpowiadać na pytanie lub dostarczać wartość bez odwołań do innych fragmentów.
Optymalna wielkość fragmentu zależy od typu treści, a znajomość tych zasad pomaga odpowiednio ją strukturyzować. Odpowiedzi FAQ dzielą się na 100–200 tokenów (ok. 75–150 słów), co umożliwia indeksowanie każdego pytania osobno. Dokumentacja techniczna to zwykle 300–500 tokenów (225 słów), by zachować kontekst złożonych pojęć. Artykuły długie to 400–600 tokenów (300–450 słów) na sekcję. Opisy produktów to 200–300 tokenów (150–225 słów) — każda cecha osobno. Artykuły newsowe dzielą się na 300–400 tokenów (225–300 słów), by rozdzielić elementy historii.
| Typ treści | Optymalny rozmiar fragmentu (tokeny) | Odpowiednik w słowach | Strategia strukturyzacji |
|---|---|---|---|
| FAQ | 100–200 | 75–150 słów | Każde Q&A w osobnym fragmencie |
| Dokumentacja techniczna | 300–500 | 225–375 słów | Jedno pojęcie na fragment |
| Artykuły długie | 400–600 | 300–450 słów | Jedna sekcja na fragment |
| Opisy produktów | 200–300 | 150–225 słów | Jeden zestaw cech na fragment |
| Artykuły newsowe | 300–400 | 225–300 słów | Jeden element historii na fragment |
Najlepsze praktyki przy optymalizacji pod fragmentację:
Strukturyzując treść pod kątem fragmentacji, zapewniasz każdemu indeksowanemu fragmentowi wysoką gęstość informacji i możliwość niezależnego pobrania. To znacząco zwiększa widoczność w AI, bo odpowiada rzeczywistym mechanizmom przetwarzania i indeksowania informacji.
Audyt gęstości informacji wymaga systematycznej oceny, ile unikalnych, wartościowych danych dostarcza każda sekcja względem swojej długości. Proces audytu zaczyna się od wytypowania kluczowych fragmentów — tych, które najprawdopodobniej będą pobierane przez AI odpowiadające na pytania z Twojej branży. Dla każdego fragmentu oblicz gęstość odpowiedzi, mierząc, jak bezpośrednio i kompletnie odpowiada on na główne pytanie w danej liczbie słów. Fragment, który odpowiada już w pierwszym zdaniu, poparty danymi i metodologią, cechuje wysoka gęstość; taki, który najpierw stawia pytanie, a potem długo wprowadza, ma gęstość niską. Narzędzia jak NEURONwriter dają ocenę gęstości semantycznej wykraczającą poza metryki fraz. AmICited.com monitoruje, jak często Twoja treść jest cytowana przez AI — to bezpośredna informacja zwrotna o skuteczności optymalizacji.
Proces audytu krok po kroku:
Kluczowe wskaźniki do monitorowania w procesie poprawy:
Proces usprawniania jest iteracyjny: najpierw mierzysz wskaźniki bazowe, wdrażasz techniki optymalizacji, po 2–4 tygodniach ponownie mierzysz i korygujesz działania. Treści, które poprawiają gęstość danych z 1 do 3 punktów na 100 słów, notują zwykle wzrost cytowań przez AI o 40–60%. Długoterminowe śledzenie tych wskaźników pozwala wyłonić najskuteczniejsze techniki dla Twojej branży. AmICited.com pełni rolę panelu monitoringu, pokazując, które materiały są cytowane przez AI i z jaką częstotliwością — to konkretna informacja zwrotna, czy poprawa gęstości przekłada się na realną widoczność w AI.
Przekształcenie treści o niskiej gęstości w wysoką przynosi wymierne efekty w liczbie cytowań przez AI w różnych typach materiałów. Przykład: artykuł technologiczny “Dlaczego chmura ma znaczenie” zaczynał się od: “Chmura jest ważna we współczesnym biznesie. Wiele firm korzysta z chmury. Chmura daje wiele korzyści. Firmy powinny rozważyć chmurę.” To 28 słów bez żadnych konkretów — minimalna liczba cytowań przez AI. Po poprawie: “Chmura obniża koszty infrastruktury o 30–40% i umożliwia wdroż
Gęstość słów kluczowych mierzyła procent docelowych fraz w treści, co często prowadziło do ich nadużywania i obniżenia jakości. Gęstość informacji mierzy stosunek użytecznych, unikalnych informacji do całkowitej długości treści, skupiając się na wartości i konkretach. Współczesne systemy AI oceniają gęstość informacji zamiast częstotliwości słów kluczowych, nagradzając treści dostarczające maksymalną wiedzę w efektywny sposób.
Systemy AI przyznają wyższe oceny fragmentom o wysokiej gęstości informacji, ponieważ zawierają konkretne dane, nazwy własne i terminologię techniczną. Treści zawierające 3+ punkty danych otrzymują 2,5x więcej cytowań niż treści ogólne. Fragmenty odpowiadające na pytania w pierwszych 1-2 zdaniach wykazują 40% wyższą częstotliwość pobierania przez AI.
Długość treści zależy od złożoności tematu i intencji użytkownika, a nie sztywnej liczby słów. Na proste pytanie wystarczą 1-2 zdania o wysokiej gęstości informacji, a złożone tematy mogą wymagać 3 000–5 000 słów. Kluczem jest dostarczenie maksymalnej wartości informacyjnej w minimalnie koniecznej długości — jakość zawsze wygrywa z ilością w oczach AI.
Przeprowadź audyt, licząc liczbę punktów danych na 100 słów (cel: 2-4), nazw własnych (cel: 1-3) i oceniając, jak bezpośrednio fragment odpowiada na główne pytanie. Narzędzia takie jak NEURONwriter oferują ocenę gęstości semantycznej. AmICited.com śledzi, jak często systemy AI cytują Twoje treści, dając bezpośrednią informację zwrotną na temat skuteczności optymalizacji.
Tak, zdecydowanie. Artykuł o długości 400 słów, nasycony konkretnymi danymi, statystykami, terminologią techniczną i przykładami, wykazuje wyższą gęstość informacji niż 2 000-słowny tekst pełen ogólników i powtórzeń. AI ocenia gęstość względem jednostki tekstu, a nie długości całkowitej. Krótsze, gęstsze treści często przewyższają długie, rozwlekłe materiały.
Systemy AI dzielą treści na fragmenty po 200–400 słów do niezależnego indeksowania i pobierania. Każdy fragment musi być samodzielny i wnosić wartość. Wysoka gęstość informacji gwarantuje, że każdy fragment zawiera wystarczająco konkretnych danych, by być niezależnie odnalezionym i cytowanym, co poprawia widoczność treści w AI.
NEURONwriter i Contadu dostarczają ocenę gęstości semantycznej i analizę treści. AmICited.com monitoruje częstotliwość cytowań Twoich treści przez AI, pokazując, które fragmenty działają najlepiej. Google Search Console ujawnia, które fragmenty pojawiają się w featured snippets. Wszystkie te narzędzia razem dają pełną informację zwrotną o skuteczności optymalizacji gęstości informacji.
Choć gęstość informacji nie jest bezpośrednim czynnikiem rankingowym, silnie koreluje z sygnałami jakości ocenianymi przez AI. Treści o wysokiej gęstości są częściej cytowane, generują większe zaangażowanie i budują autorytet tematyczny. Te czynniki pośrednio poprawiają pozycje, ponieważ AI uznaje treści o wysokiej gęstości za bardziej wartościowe i autorytatywne niż alternatywy o niskiej gęstości.
Śledź, jak systemy AI odnoszą się do Twojej marki w GPT, Perplexity, Google AI Overviews i innych platformach AI. Dowiedz się, które treści są cytowane i optymalizuj je pod maksymalną widoczność.
Dowiedz się, jak tworzyć treści o wysokiej gęstości informacji, które preferują systemy AI. Opanuj hipotezę Jednolitej Gęstości Informacji i zoptymalizuj swoje ...

Odkryj, dlaczego gęstość słów kluczowych nie ma już znaczenia w wyszukiwaniu AI. Dowiedz się, co ChatGPT, Perplexity i Google AI Overviews naprawdę biorą pod uw...
Gęstość słów kluczowych mierzy, jak często słowo kluczowe pojawia się w treści w stosunku do całkowitej liczby słów. Poznaj optymalne wartości procentowe, najle...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.