
Prawda o LLMs.txt: Przereklamowany czy niezbędny?
Krytyczna analiza skuteczności LLMs.txt. Dowiedz się, czy ten standard AI jest niezbędny dla Twojej strony, czy to tylko moda. Rzeczywiste dane o adopcji, wspar...
8 min czytania

Proponowany standardowy plik umieszczany w głównym katalogu domeny witryny, który komunikuje się z crawlerami AI i dużymi modelami językowymi na temat wysokiej jakości, cytowalnych treści. Podobny do robots.txt, ale zaprojektowany do wskazówek w czasie wnioskowania, a nie kontroli dostępu. Pomaga systemom AI odkrywać i priorytetyzować autorytatywne treści podczas generowania odpowiedzi. Coraz częściej wdrażany przez główne platformy AI, takie jak OpenAI, Anthropic, Perplexity i Google.
Proponowany standardowy plik umieszczany w głównym katalogu domeny witryny, który komunikuje się z crawlerami AI i dużymi modelami językowymi na temat wysokiej jakości, cytowalnych treści. Podobny do robots.txt, ale zaprojektowany do wskazówek w czasie wnioskowania, a nie kontroli dostępu. Pomaga systemom AI odkrywać i priorytetyzować autorytatywne treści podczas generowania odpowiedzi. Coraz częściej wdrażany przez główne platformy AI, takie jak OpenAI, Anthropic, Perplexity i Google.
Plik LLMs.txt to plik tekstowy w formacie markdown umieszczany w głównym katalogu domeny witryny, który służy jako wyselekcjonowany przewodnik dla dużych modeli językowych podczas wnioskowania. W przeciwieństwie do tradycyjnych narzędzi SEO, LLMs.txt został zaprojektowany, aby pomóc crawlerom AI i modelom językowym odkrywać i priorytetyzować wysokiej jakości treści na Twojej stronie, gdy generują odpowiedzi lub wyszukują informacje. Ten proponowany standard oznacza zmianę sposobu, w jaki witryny komunikują się z systemami sztucznej inteligencji, przechodząc od mechanizmów blokowania, takich jak robots.txt, do inteligentnej kuracji treści. Plik pełni funkcję mapy treści, która wskazuje systemom AI, które strony, artykuły i zasoby są najcenniejsze, najbardziej wiarygodne i istotne dla ich celów. Ważne jest, aby zrozumieć, że LLMs.txt nie służy do blokowania ani zezwalania na trening AI—dotyczy wyłącznie pobierania treści w czasie wnioskowania, pomagając systemom AI znaleźć właściwe treści, gdy odpowiadają na pytania użytkowników. Plik jest zapisany w formacie markdown i przechowywany jako zwykły tekst, co sprawia, że jest prosty w tworzeniu i utrzymaniu. Dzięki wdrożeniu LLMs.txt witryny mogą mieć pewność, że gdy systemy AI odwołują się do ich treści, korzystają z najbardziej aktualnych, dobrze uporządkowanych i autorytatywnych źródeł.
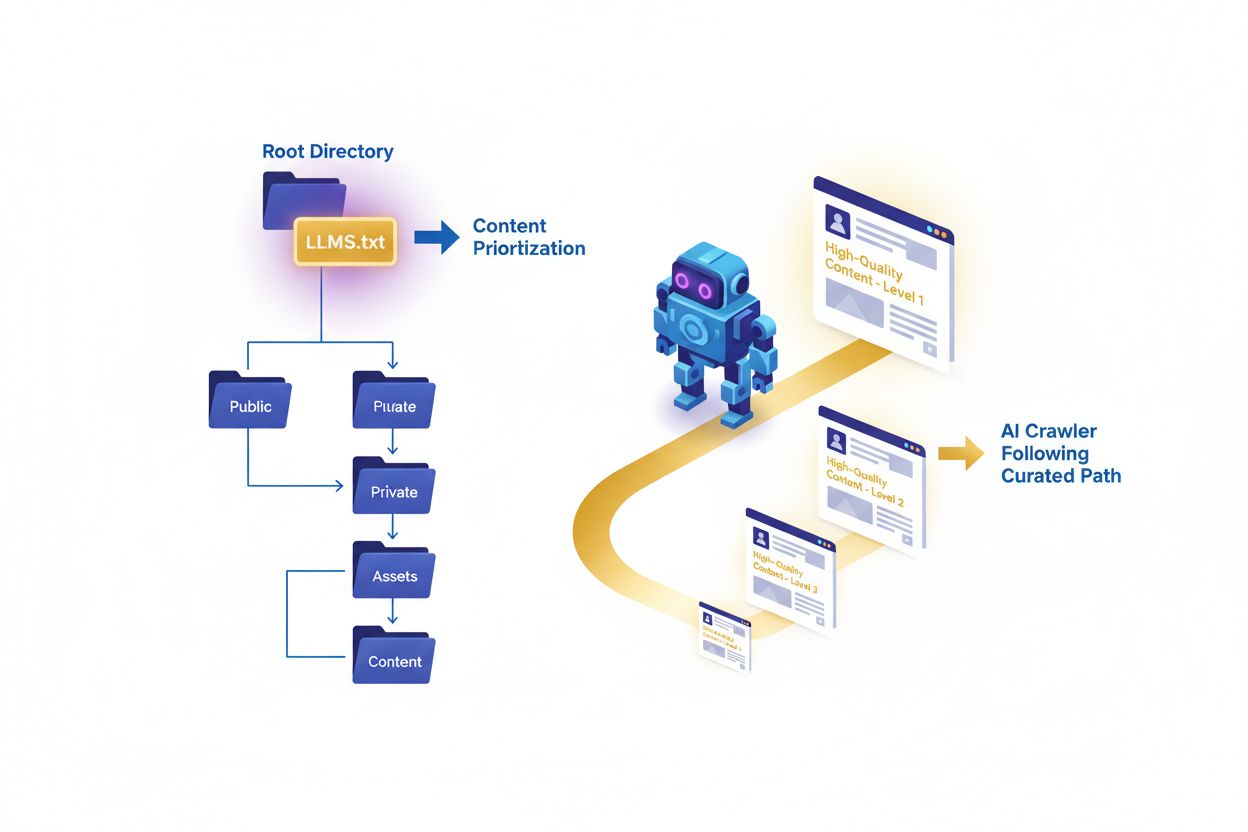
Podczas gdy robots.txt i sitemap.xml dobrze służyły witrynom w tradycyjnych wyszukiwarkach, LLMs.txt odpowiada na zupełnie inne potrzeby w erze sztucznej inteligencji. Kluczowa różnica leży w ich głównych funkcjach i czasie działania: robots.txt kontroluje zachowanie crawlerów i to, do czego mają dostęp wyszukiwarki, sitemap.xml pomaga wyszukiwarkom odkrywać i indeksować strony, natomiast LLMs.txt kieruje systemami AI w czasie wnioskowania, gdy aktywnie generują odpowiedzi. Ważne jest, by zrozumieć, że LLMs.txt nie blokuje ani nie zezwala na trening AI—po prostu wskazuje, które treści systemy AI powinny priorytetyzować podczas odpowiadania na pytania lub pobierania informacji. Te trzy pliki pełnią uzupełniające się role i mogą bez problemu współistnieć w tej samej domenie. Robots.txt dotyczy kontroli dostępu, sitemap.xml odkrywalności, a LLMs.txt jakości i istotności treści. Można to zobrazować tak: robots.txt mówi “to możesz przeszukiwać”, sitemap.xml “to istnieje”, a LLMs.txt “to jest najważniejsze”. To rozróżnienie jest istotne, ponieważ systemy AI potrzebują innych sygnałów niż tradycyjne wyszukiwarki—muszą wiedzieć, które treści są autorytatywne, dobrze uporządkowane i nadają się do cytowania.
| Plik | Główna funkcja | Główny cel | Przykład użycia |
|---|---|---|---|
| robots.txt | Kontrola dostępu | Blokowanie/zezwalanie na dostęp crawlerów | Blokowanie wrażliwych stron dla wyszukiwarek |
| sitemap.xml | Odkrywalność | Pomoc wyszukiwarkom w znajdowaniu stron | Poprawa indeksacji nowych lub głębokich treści |
| LLMs.txt | Kuracja treści | Kierowanie pobieraniem przez AI w czasie wnioskowania | Wskazywanie systemom AI autorytatywnych źródeł |
Plik LLMs.txt stosuje strukturę opartą na markdown, która jest czytelna zarówno dla ludzi, jak i maszyn, co czyni ją dostępną dla twórców treści oraz systemów AI. Plik zazwyczaj zaczyna się od tytułu H1 (przez #), który identyfikuje witrynę i jej przeznaczenie, po czym następuje wstępny blok cytatu wyjaśniający misję lub tematykę strony. Rdzeń struktury stanowią uporządkowane sekcje oznaczone nagłówkami H2 (##), kategoryzujące różne typy treści—takie jak “Główne zasoby”, “Przewodniki”, “Dokumentacja” czy “Najlepsze praktyki”—każda zawierająca wyselekcjonowaną listę adresów URL z krótkimi opisami. Sekcja “Opcjonalne” na końcu pozwala dodać dodatkowe zasoby, które mogą być wartościowe, ale nie są częścią głównej kuracji. Plik używa zwykłego kodowania tekstu UTF-8, by zapewnić kompatybilność z wszystkimi systemami i platformami AI. Każda pozycja zwykle zawiera pełny adres URL oraz krótki opis wyjaśniający, dlaczego dana treść jest wartościowa lub czego dotyczy. Zalecany rozmiar pliku nie przekracza zazwyczaj 100 KB, aby zapewnić efektywne przetwarzanie przez systemy AI, choć nie ma twardego limitu. Format markdown pozwala na elastyczną organizację przy zachowaniu przejrzystości, a struktura powinna odzwierciedlać rzeczywistą hierarchię i ważność treści na stronie.
# Przykładowa Strona – LLMs.txt
> To jest Przykładowa Strona, kompleksowe źródło wiedzy o [Twoim temacie].
> Zapewniamy autorytatywne przewodniki, tutoriale i dokumentację dla [Twojej dziedziny].
## Główne zasoby
- https://example.com/about - Przegląd naszej misji i ekspertyzy
- https://example.com/getting-started - Podstawowy punkt startowy dla nowych użytkowników
## Kompleksowe przewodniki
- https://example.com/guide/advanced-techniques - Dogłębne omówienie zaawansowanych metod
- https://example.com/guide/best-practices - Standardy branżowe i rekomendacje
## Dokumentacja
- https://example.com/docs/api-reference - Pełna dokumentacja API
- https://example.com/docs/installation - Instrukcje instalacji i konfiguracji
## Opcjonalne
- https://example.com/blog/latest-trends - Najnowsze trendy w branży
- https://example.com/case-studies - Przykłady wdrożeń w praktyce
Wdrożenie LLMs.txt zapewnia istotne korzyści w rozwijającym się świecie wyszukiwania i odkrywania treści napędzanego przez AI. Główną zaletą jest pobieranie treści w czasie wnioskowania, co oznacza, że Twoje wyselekcjonowane materiały są priorytetowo traktowane, gdy systemy AI aktywnie odpowiadają na pytania użytkowników, a nie podczas faz treningowych. To prowadzi do lepszego zrozumienia kontekstu, autorytetu i istotności Twoich treści przez AI, skutkując dokładniejszym cytowaniem i odwoływaniem się do Twojej pracy. Dzięki LLMs.txt zyskujesz bezpośrednią kontrolę nad odkrywalnością, gwarantując, że systemy AI najpierw znajdują Twoje najlepsze treści, zamiast przypadkowych, mniej wartościowych podstron. Plik zwiększa widoczność w wynikach wyszukiwania AI i aplikacjach napędzanych przez AI, tworząc nowy kanał ruchu i przypisania, który uzupełnia tradycyjne SEO. Organizacje, które wcześnie wdrożą LLMs.txt, zyskują przewagę konkurencyjną, stając się autorytatywnym źródłem w swojej dziedzinie, zanim standard stanie się powszechny. Implementacja to także forma zabezpieczenia na przyszłość, przygotowująca Twoją stronę na nieuchronny zwrot ku odkrywaniu treści przez AI.
Główne zastosowania:
Treść przyjazna LLM ma określone cechy, które sprawiają, że jest bardziej wartościowa i użyteczna dla systemów sztucznej inteligencji podczas wnioskowania. Najważniejsza jest jasna struktura z właściwą hierarchią nagłówków (H1, H2, H3), organizująca informacje logicznie, aby AI mogła zrozumieć przepływ i powiązania między partiami treści. Krótkie akapity (zwykle 2–4 zdania) są preferowane, ponieważ ułatwiają systemom AI wydobywanie konkretnych pojęć i idei, w przeciwieństwie do długich bloków tekstu. Treść powinna zawierać listy, tabele i wypunktowania, które rozbijają złożone informacje na łatwe do przetworzenia fragmenty, co ułatwia AI analizę i cytowanie konkretnych punktów. Należy unikać rozpraszaczy, takich jak automatycznie odtwarzane filmy, wyskakujące okna czy nadmierne reklamy, bo nie wnoszą one wartości do głównej treści. Kluczowa jest jasność semantyczna—używanie prostego języka, definiowanie terminów technicznych i unikanie niejednoznaczności pomaga AI właściwie zinterpretować sens. Treść powinna być samowystarczalna i kontekstowa, tak by była zrozumiała nawet po wyjęciu z oryginalnej strony. Takie podejście wspiera AI SEO i zwiększa prawdopodobieństwo, że Twoje materiały będą cytowane dokładnie i w całości, gdy AI odwoła się do Twojej pracy.
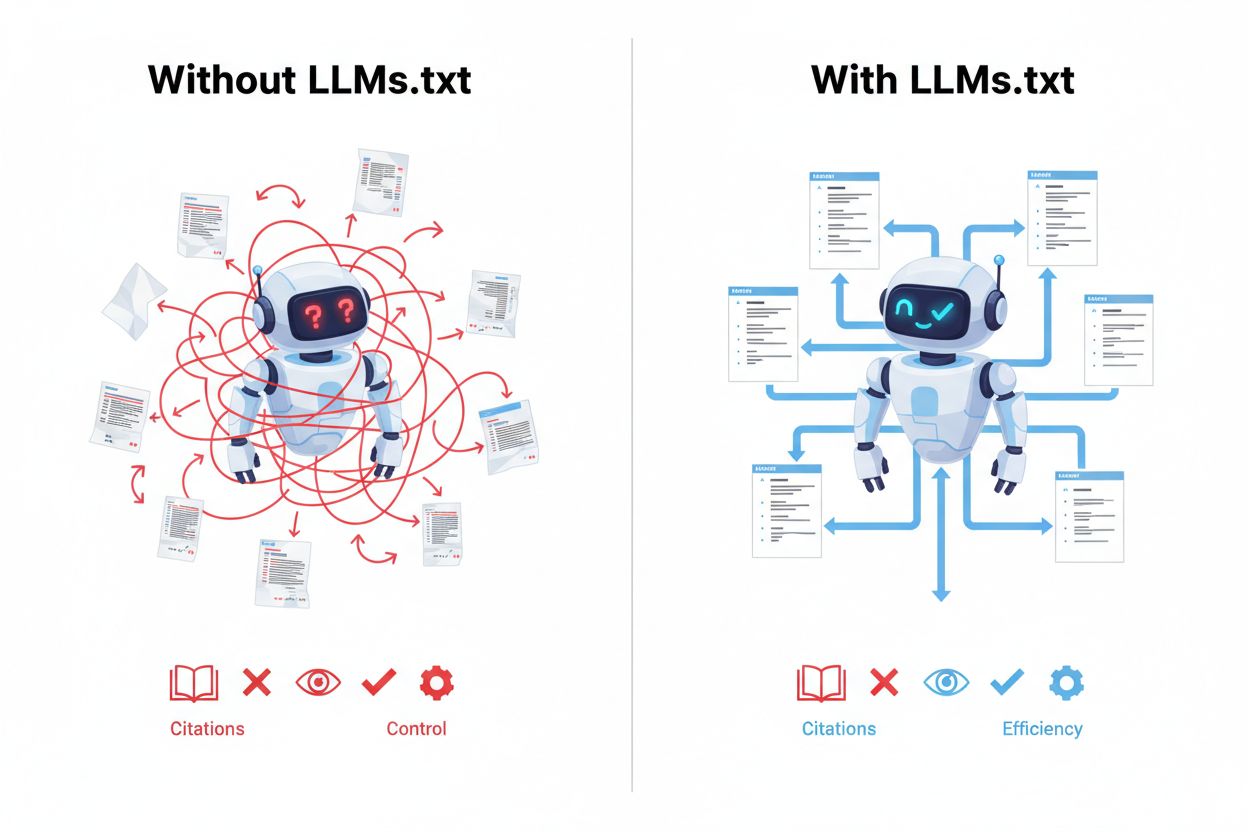
Właściwe wdrożenie LLMs.txt wymaga strategicznego przemyślenia, które treści naprawdę zasługują na uwzględnienie i jak je zorganizować dla maksymalnej wartości. Plik musi być umieszczony w głównym katalogu domeny (np. example.com/llms.txt), by systemy AI i crawlery mogły go łatwo znaleźć. Zamiast kopiować całą mapę witryny do LLMs.txt, postaw na jakość, nie ilość—umieść tylko swoje najbardziej autorytatywne, stale aktualne i wartościowe treści, które chciałbyś, aby AI cytowało. Priorytetyzuj kluczowe zasoby, takie jak obszerne przewodniki, dokumentację, tutoriale i oryginalne badania, które pokazują ekspertyzę i realną wartość. Rozważ dołączenie strony głównej lub „O nas”, aby AI lepiej rozumiało misję i wiarygodność Twojej organizacji. Wybierane treści powinny być dobrze utrzymane i regularnie aktualizowane, bo przestarzałe informacje obniżają Twój autorytet w oczach AI. Organizuj treści logicznie za pomocą przejrzystych nagłówków odzwierciedlających strukturę i kategorie strony. Unikaj uwzględniania treści wymagających logowania, płatnych artykułów lub stron dla zalogowanych użytkowników, bo systemy AI nie będą miały do nich dostępu. Regularnie audytuj i aktualizuj plik LLMs.txt, aby odzwierciedlał zmiany w strategii treści, usuwał nieaktualne linki i dodawał nowe autorytatywne zasoby.
Wdrażanie LLMs.txt przyspiesza wśród głównych platform AI i firm dostrzegających wartość wyselekcjonowanych źródeł treści. OpenAI, Anthropic, Perplexity i Google już zadeklarowały wsparcie lub zainteresowanie standardem LLMs.txt, a niektóre platformy aktywnie go używają do ulepszania systemów wyszukiwania i cytowania. Standard ten wciąż jest w fazie rozwoju i nie jest obowiązkowy, ale coraz częściej uznawany za dobrą praktykę dla stron, które chcą poprawić widoczność w aplikacjach AI. Powstają katalogi i rejestry gromadzące witryny wdrażające LLMs.txt, co ułatwia systemom AI odkrywanie i priorytetyzowanie wyselekcjonowanych źródeł. Wczesni wdrożeniowcy zyskują znaczną przewagę, stając się autorytatywnymi źródłami zanim standard stanie się powszechny na wszystkich platformach AI. Przykłady z praktyki pokazują, że strony wdrażające LLMs.txt obserwują lepsze wskaźniki cytowań i większą reprezentację w treściach generowanych przez AI. Wszystko wskazuje, że LLMs.txt stanie się tak standardowy jak robots.txt i sitemap.xml w ciągu kilku najbliższych lat—dlatego wdrożenie to dobra inwestycja dla organizacji patrzących w przyszłość.
Różnica między llms.txt a llms-full.txt to dwa uzupełniające się podejścia do kierowania systemami AI po Twoich treściach. LLMs.txt to wyselekcjonowana, wybrana przez człowieka wersja, zawierająca tylko najważniejsze, autorytatywne i wartościowe treści—zwykle 20–100 adresów URL, pogrupowanych według kategorii z opisami. LLMs-full.txt to zaś pełna, możliwa do odczytu maszynowego wersja, obejmująca każdą stronę Twojej witryny w uporządkowanym formacie, często generowana automatycznie na podstawie mapy strony lub CMS. Główna różnica to intencjonalność: llms.txt wymaga selekcji i oceny przez człowieka, podczas gdy llms-full.txt jest kompletny i wyczerpujący. LLMs.txt należy używać, gdy chcesz poprowadzić systemy AI do najlepszych treści i budować sygnały autorytetu, a llms-full.txt służy jako zapas dla systemów AI, które chcą pełnego pokrycia witryny. Oba pliki mają formatowanie markdown, lecz inne filozofie organizacyjne—llms.txt jest selektywny i strategiczny, llms-full.txt inkluzywny i kompletny. Wiele organizacji wdraża oba pliki jednocześnie, pozwalając AI wybrać między kuracją (llms.txt) a pełnym zakresem (llms-full.txt). Przykładowo, AIOSEO oferuje narzędzia do automatycznego generowania obu wersji: llms.txt wskazuje treści premium, a llms-full.txt zapewnia pełne pokrycie strony.
Wdrożenie LLMs.txt może być nieskuteczne przez kilka typowych błędów, których należy się wystrzegać. Najpoważniejszy to umieszczenie pliku w złym miejscu—powinien być w głównym katalogu domeny (example.com/llms.txt), a nie w podkatalogach czy pod inną nazwą. Brak wymaganych elementów, takich jak tytuł H1 i wstępny blok cytatu, może sprawić, że AI nie rozpozna celu i autorytetu Twojej strony. Dodawanie nieaktualnych lub uszkodzonych adresów URL szkodzi wiarygodności i marnuje zasoby AI na próby dostępu do nieistniejących treści. Nadmierne uwzględnianie—dodawanie zbyt wielu adresów (setki lub tysiące)—niweczy cel kuracji i utrudnia AI wyłowienie naprawdę ważnych treści. Słabe lub brakujące opisy dla adresów URL sprawiają, że AI nie zrozumie, dlaczego dana treść jest wartościowa lub czego dotyczy. Zaniedbanie aktualizacji pliku LLMs.txt prowadzi do jego dezaktualizacji, uszkodzonych linków i nieadekwatnych treści. Uwzględnianie treści wymagających logowania lub płatnych artykułów, do których AI nie ma dostępu, budzi frustrację i zmniejsza zaufanie. Na koniec, upewnij się, że stosujesz właściwy typ MIME (text/plain lub text/markdown) podczas serwowania pliku, bo błędna konfiguracja uniemożliwi AI poprawne przetwarzanie.
Pojawiło się wiele narzędzi i zasobów, które upraszczają tworzenie i utrzymanie plików LLMs.txt. AIOSEO oferuje dedykowaną wtyczkę, która automatycznie generuje zarówno llms.txt, jak i llms-full.txt, czyniąc wdrożenie łatwym nawet dla nietechnicznych użytkowników. Dla preferujących ręczne tworzenie proces jest prosty—wystarczy utworzyć plik tekstowy w formacie markdown i przesłać go do głównego katalogu domeny. Narzędzia walidacyjne online pozwalają sprawdzić poprawność formatowania, wykryć uszkodzone linki i zgodność ze standardem. Społeczność GitHub udostępniła wiele repozytoriów z szablonami, przykładami i dobrymi praktykami wdrożenia. Oficjalna dokumentacja na llmstxt.org zawiera wyczerpujące wskazówki dotyczące struktury pliku, wymagań formatowania i strategii wdrożenia. Wiele dokumentacji platform AI ma już sekcje dotyczące wsparcia dla LLMs.txt, pomagając zrozumieć, jak różne systemy wykorzystują wyselekcjonowane treści. Wszystkie te zasoby sprawiają, że wdrożenie LLMs.txt i optymalizacja treści pod kątem AI jest łatwiejsza niż kiedykolwiek.
LLMs.txt kieruje systemy AI do Twoich najlepszych treści na potrzeby użycia w czasie wnioskowania, podczas gdy robots.txt kontroluje, do czego mają dostęp crawlery wyszukiwarek. Służą różnym celom i mogą współistnieć w tej samej domenie. LLMs.txt dotyczy kuracji i wskazówek, a robots.txt kontroli dostępu.
Nie, nie jest obowiązkowy, ale staje się dobrą praktyką. Wdrożenie LLMs.txt daje przewagę konkurencyjną w wynikach wyszukiwania napędzanych przez AI i zapewnia właściwe przypisanie Twoich treści, gdy są cytowane przez systemy AI.
Plik musi być umieszczony w głównym katalogu Twojej domeny (np. twojastrona.com/llms.txt), aby był wykrywalny przez systemy AI i crawlery. Powinien być publicznie dostępny bez uwierzytelniania.
Nie, llms.txt nie jest przeznaczony do blokowania ani kontroli treningu. Służy wyłącznie do kierowania systemami AI podczas wnioskowania (generowania odpowiedzi). Jeśli chcesz kontrolować dostęp do treningu, użyj robots.txt lub innych mechanizmów.
Przeglądaj i aktualizuj kwartalnie lub za każdym razem, gdy dokonasz istotnych zmian w strukturze strony, dodasz nowe ważne treści lub zmienisz adresy URL. Regularna konserwacja zapewnia, że Twój plik pozostaje aktualny i wartościowy.
OpenAI, Anthropic, Perplexity i Google rozpoczęły wdrażanie wsparcia dla llms.txt. Adaptacja rośnie wraz z ugruntowaniem standardu i uznaniem go za dobrą praktykę.
LLMs.txt to wyselekcjonowana lista Twoich najlepszych treści (zwykle 20-100 adresów URL), podczas gdy llms-full.txt zawiera kompletną, możliwą do odczytu maszynowego wersję wszystkich Twoich treści w formacie Markdown. Oba mogą być używane razem dla maksymalnej elastyczności.
Postaw na jakość, nie ilość. Uwzględnij 10–20 najważniejszych, autorytatywnych stron, które najlepiej reprezentują Twoją ekspertyzę i wartość treści. Unikaj umieszczania całej mapy witryny w pliku.
AmICited śledzi, jak systemy AI odnoszą się do Twojej marki w ChatGPT, Perplexity, Google AI Overviews i innych. Zapewnij swoim treściom właściwe przypisanie i widoczność w odpowiedziach generowanych przez AI.
Krytyczna analiza skuteczności LLMs.txt. Dowiedz się, czy ten standard AI jest niezbędny dla Twojej strony, czy to tylko moda. Rzeczywiste dane o adopcji, wspar...

Dowiedz się, jak wdrożyć LLMs.txt na swojej stronie internetowej, aby pomóc systemom AI lepiej rozumieć Twoje treści. Kompletny przewodnik krok po kroku dla wsz...

Dowiedz się, jak identyfikować i celować w strony źródłowe LLM dla strategicznych backlinków. Sprawdź, które platformy AI najczęściej cytują źródła i zoptymaliz...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.