
Architektura Transformera
Architektura Transformera to projekt sieci neuronowej wykorzystujący mechanizmy samo-uwagi do równoległego przetwarzania danych sekwencyjnych. Stanowi podstawę ...
12 min czytania
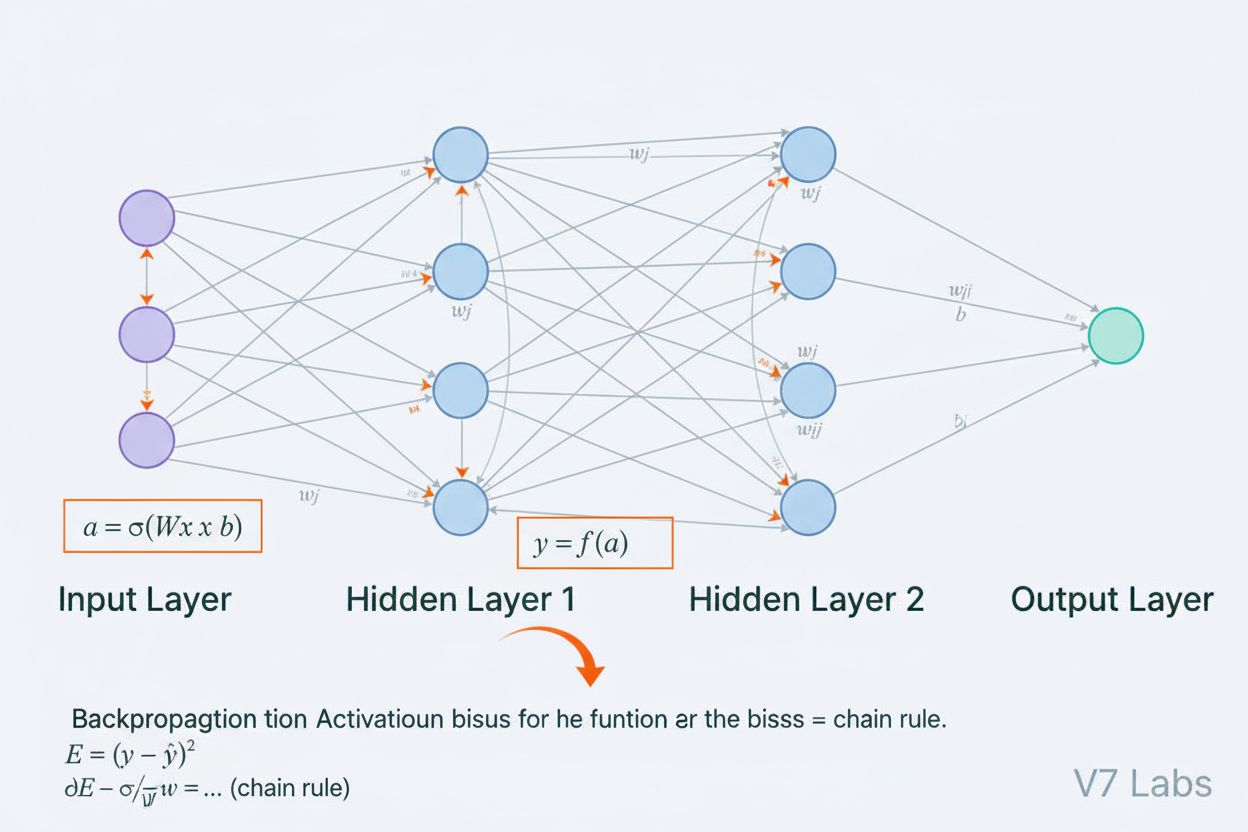
Sieć neuronowa to system obliczeniowy inspirowany biologicznymi sieciami neuronowymi, składający się z połączonych sztucznych neuronów zorganizowanych w warstwy, zdolnych do uczenia się wzorców z danych poprzez proces zwany propagacją wsteczną. Systemy te stanowią fundament współczesnej sztucznej inteligencji i uczenia głębokiego, napędzając aplikacje od przetwarzania języka naturalnego po widzenie komputerowe.
Sieć neuronowa to system obliczeniowy inspirowany biologicznymi sieciami neuronowymi, składający się z połączonych sztucznych neuronów zorganizowanych w warstwy, zdolnych do uczenia się wzorców z danych poprzez proces zwany propagacją wsteczną. Systemy te stanowią fundament współczesnej sztucznej inteligencji i uczenia głębokiego, napędzając aplikacje od przetwarzania języka naturalnego po widzenie komputerowe.
Sieć neuronowa to system obliczeniowy fundamentalnie inspirowany strukturą i funkcją biologicznych sieci neuronowych występujących w mózgach zwierząt. Składa się z połączonych sztucznych neuronów zorganizowanych w warstwy—zazwyczaj warstwę wejściową, jedną lub więcej warstw ukrytych oraz warstwę wyjściową—które współpracują w celu przetwarzania danych, rozpoznawania wzorców i dokonywania predykcji. Każdy neuron otrzymuje dane wejściowe, stosuje przekształcenia matematyczne za pomocą wag i biasów, a następnie przekazuje wynik przez funkcję aktywacji, aby uzyskać wyjście. Definiującą cechą sieci neuronowych jest ich zdolność do uczenia się na podstawie danych poprzez iteracyjny proces zwany propagacją wsteczną, w którym sieć dostosowuje swoje wewnętrzne parametry, aby minimalizować błędy predykcji. Ta zdolność uczenia, w połączeniu z możliwością modelowania złożonych nieliniowych zależności, sprawiła, że sieci neuronowe stały się technologią fundamentującą współczesną sztuczną inteligencję—from dużych modeli językowych po zastosowania z zakresu widzenia komputerowego.
Koncepcja sztucznych sieci neuronowych wyrosła z wczesnych prób matematycznego modelowania sposobu, w jaki biologiczne neurony komunikują się i przetwarzają informacje. W 1943 roku Warren McCulloch i Walter Pitts zaproponowali pierwszy matematyczny model neuronu, wykazując, że proste jednostki obliczeniowe mogą realizować operacje logiczne. Ta teoretyczna podstawa została rozwinięta przez Franka Rosenblatta, który w 1958 roku wprowadził perceptron—algorytm przeznaczony do rozpoznawania wzorców, będący historycznym przodkiem dzisiejszych zaawansowanych architektur sieci neuronowych. Perceptron był w istocie modelem liniowym z ograniczonym wyjściem, zdolnym do nauki prostych granic decyzyjnych. Jednak w latach 70. dziedzina ta napotkała poważne przeszkody, gdy odkryto, że perceptrony jednokierunkowe nie radzą sobie z nieliniowymi problemami, takimi jak funkcja XOR, co doprowadziło do tzw. “zimy AI”. Przełom nastąpił w latach 80., gdy ponownie odkryto i udoskonalono propagację wsteczną—algorytm umożliwiający trenowanie sieci wielowarstwowych. Renesans ten gwałtownie przyspieszył w latach 2010. dzięki dostępności ogromnych zbiorów danych, wydajnych procesorów GPU i udoskonalonych technik trenowania, prowadząc do rewolucji w uczeniu głębokim, która odmieniła oblicze sztucznej inteligencji.
Architektura sieci neuronowej składa się z kilku podstawowych komponentów współpracujących ze sobą. Warstwa wejściowa odbiera surowe cechy danych z zewnętrznych źródeł—każdy neuron w tej warstwie odpowiada jednej cesze. Warstwy ukryte wykonują główną pracę obliczeniową, przekształcając dane wejściowe w coraz bardziej abstrakcyjne reprezentacje za pomocą ważonych kombinacji i nieliniowych funkcji aktywacji. Liczba i rozmiar warstw ukrytych determinują zdolność sieci do uczenia się złożonych wzorców—głębsze sieci mogą wychwytywać bardziej skomplikowane relacje, ale wymagają więcej danych i zasobów obliczeniowych. Warstwa wyjściowa generuje ostateczne predykcje—jej struktura zależy od zadania: jeden neuron dla regresji, wiele neuronów dla klasyfikacji wieloklasowej lub wyspecjalizowane architektury dla innych zastosowań. Każde połączenie między neuronami posiada wagę, określającą siłę wpływu, a każdy neuron ma bias, który przesuwa próg aktywacji. Wagi i biasy to parametry uczące się, które sieć dostosowuje podczas treningu. Funkcja aktywacji stosowana w każdym neuronie wprowadza kluczową nieliniowość, umożliwiając sieci uczenie się złożonych granic decyzyjnych i wzorców, których modele liniowe nie są w stanie uchwycić.
Sieci neuronowe uczą się poprzez dwufazowy, iteracyjny proces. Podczas propagacji w przód dane wejściowe przepływają przez sieć od warstwy wejściowej do wyjściowej. W każdym neuronie obliczana jest ważona suma wejść plus bias (z = w₁x₁ + w₂x₂ + … + wₙxₙ + b), a następnie wynik ten przechodzi przez funkcję aktywacji, aby uzyskać wyjście neuronu. Proces ten powtarza się w każdej warstwie ukrytej aż do uzyskania predykcji w warstwie wyjściowej. Sieć następnie oblicza błąd pomiędzy swoją predykcją a rzeczywistą etykietą za pomocą funkcji straty, która kwantyfikuje odległość predykcji od poprawnej odpowiedzi. W propagacji wstecznej błąd ten jest propagowany przez sieć z wykorzystaniem reguły łańcuchowej rachunku różniczkowego. W każdym neuronie algorytm oblicza gradient funkcji straty względem każdej wagi i biasu, określając, w jakim stopniu dany parametr przyczynił się do ogólnego błędu. Te gradienty kierują aktualizacją parametrów: wagi i biasy są dostosowywane w kierunku przeciwnym do gradientu, skalowanym przez współczynnik uczenia określający wielkość kroku. Proces ten powtarza się wiele razy na zbiorze treningowym, stopniowo zmniejszając stratę i poprawiając predykcje sieci. Kombinacja propagacji w przód, obliczania straty, propagacji wstecznej i aktualizacji parametrów tworzy pełny cykl trenowania umożliwiający sieciom neuronowym uczenie się na podstawie danych.
| Typ architektury | Główne zastosowanie | Kluczowa cecha | Zalety | Ograniczenia |
|---|---|---|---|---|
| Sieci jednokierunkowe | Klasyfikacja, regresja na danych strukturalnych | Informacja przepływa tylko w jednym kierunku | Prosta, szybki trening, interpretowalna | Słabo radzi sobie z danymi sekwencyjnymi lub przestrzennymi |
| Konwolucyjne sieci neuronowe (CNN) | Rozpoznawanie obrazów, widzenie komputerowe | Warstwy konwolucyjne wykrywają cechy przestrzenne | Doskonałe w wychwytywaniu lokalnych wzorców, oszczędność parametrów | Wymaga dużych oznakowanych zbiorów obrazów |
| Rekurencyjne sieci neuronowe (RNN) | Dane sekwencyjne, szereg czasowy, NLP | Stan ukryty przechowuje pamięć przez kolejne kroki | Może przetwarzać sekwencje o zmiennej długości | Problem zanikających/eksplodujących gradientów |
| Sieci LSTM (Long Short-Term Memory) | Długoterminowe zależności w sekwencjach | Komórki pamięci z bramkami wejścia/zapominania/wyjścia | Skutecznie radzi sobie z długoterminowymi zależnościami | Bardziej złożone, wolniejsze trenowanie niż RNN |
| Sieci transformerowe | Przetwarzanie języka naturalnego, duże modele językowe | Mechanizm wielogłowej uwagi, przetwarzanie równoległe | Wysoka równoległość, wychwytuje dalekie zależności | Wymaga ogromnych zasobów obliczeniowych |
| Generative Adversarial Networks (GANs) | Generowanie obrazów, tworzenie danych syntetycznych | Sieć generatora i dyskryminatora konkurują ze sobą | Może generować realistyczne dane syntetyczne | Trudne do trenowania, problem zapadania się trybów |
Wprowadzenie funkcji aktywacji to jedno z najważniejszych osiągnięć w projektowaniu sieci neuronowych. Bez funkcji aktywacji sieć neuronowa byłaby matematycznie równoważna pojedynczej transformacji liniowej, niezależnie od liczby warstw. Wynika to z faktu, że złożenie funkcji liniowych jest również liniowe, co poważnie ogranicza zdolność sieci do uczenia się złożonych wzorców. Funkcje aktywacji rozwiązują ten problem, wprowadzając nieliniowość w każdym neuronie. ReLU (Rectified Linear Unit), zdefiniowana jako f(x) = max(0, x), stała się najpopularniejszym wyborem we współczesnym uczeniu głębokim dzięki wydajności obliczeniowej i skuteczności w trenowaniu głębokich sieci. Funkcja sigmoidalna, f(x) = 1/(1 + e^(-x)), przekształca wyjścia do zakresu 0–1, co jest przydatne w zadaniach klasyfikacji binarnej. Funkcja tanh, f(x) = (e^x - e^(-x))/(e^x + e^(-x)), daje wyjścia od –1 do 1 i często lepiej sprawdza się w warstwach ukrytych niż sigmoid. Wybór funkcji aktywacji znacząco wpływa na dynamikę uczenia się sieci, szybkość konwergencji i końcową wydajność. Nowoczesne architektury często stosują ReLU w warstwach ukrytych ze względu na wydajność, a sigmoid lub softmax w warstwach wyjściowych do szacowania prawdopodobieństw. Nieliniowość wprowadzona przez funkcje aktywacji umożliwia sieciom neuronowym aproksymację dowolnej funkcji ciągłej—własność znaną jako twierdzenie o uniwersalnej aproksymacji, która tłumaczy ich niezwykłą wszechstronność w różnych zastosowaniach.
Rynek sieci neuronowych odnotował gwałtowny wzrost, odzwierciedlając kluczową rolę tej technologii we współczesnej sztucznej inteligencji. Według najnowszych badań rynkowych, światowy rynek oprogramowania do sieci neuronowych został wyceniony na około 34,76 mld USD w 2025 roku i prognozuje się, że osiągnie 139,86 mld USD do 2030 roku, co odpowiada skumulowanemu rocznemu wskaźnikowi wzrostu (CAGR) na poziomie 32,10%. Szerszy rynek sieci neuronowych wykazuje jeszcze bardziej dynamiczną ekspansję—szacuje się, że wzrośnie z 34,05 mld USD w 2024 roku do 385,29 mld USD do 2033 roku, przy CAGR na poziomie 31,4%. Ten gwałtowny wzrost napędzany jest przez wiele czynników: rosnącą dostępność dużych zbiorów danych, rozwój wydajniejszych algorytmów treningowych, popularyzację GPU i specjalizowanego sprzętu AI oraz powszechne wdrożenia sieci neuronowych w różnych branżach. Według raportu Stanford AI Index 2025, 78% organizacji zgłosiło użycie AI w 2024 roku, podczas gdy rok wcześniej było to 55%, a sieci neuronowe stanowią podstawę większości wdrożeń AI w przedsiębiorstwach. Zastosowania obejmują opiekę zdrowotną, finanse, produkcję, handel i praktycznie każdy inny sektor, ponieważ organizacje dostrzegają przewagę konkurencyjną wynikającą z zastosowania systemów opartych na sieciach neuronowych do rozpoznawania wzorców, predykcji i podejmowania decyzji.
Sieci neuronowe napędzają najbardziej zaawansowane systemy AI używane obecnie, w tym ChatGPT, Perplexity, Google AI Overviews i Claude. Te duże modele językowe są oparte na architekturach sieci neuronowych typu transformer, które wykorzystują mechanizmy uwagi do przetwarzania i generowania ludzkiego języka z niezwykłą precyzją. Architektura transformerów, wprowadzona w 2017 roku, zrewolucjonizowała przetwarzanie języka naturalnego dzięki możliwości równoległego przetwarzania całych sekwencji zamiast przetwarzania sekwencyjnego, co znacząco poprawiło efektywność treningu oraz wydajność modeli. W kontekście monitoringu marki i śledzenia cytowań przez AI, zrozumienie sieci neuronowych jest kluczowe, ponieważ systemy te wykorzystują sieci neuronowe do rozumienia kontekstu, wyszukiwania istotnych informacji i generowania odpowiedzi, które mogą odnosić się lub cytować Twoją markę, domenę lub treści. AmICited wykorzystuje wiedzę o tym, jak sieci neuronowe przetwarzają i wyszukują informacje, by monitorować, gdzie Twoja marka pojawia się w odpowiedziach generowanych przez AI na różnych platformach. Wraz z doskonaleniem sieci neuronowych w rozumieniu znaczenia semantycznego i wyszukiwaniu właściwych informacji, znaczenie monitorowania obecności marki w odpowiedziach AI staje się coraz istotniejsze dla utrzymania widoczności i zarządzania reputacją online w erze wyszukiwania i generowania treści przez AI.
Efektywne trenowanie sieci neuronowych wiąże się z wieloma wyzwaniami, które muszą być rozwiązane przez badaczy i praktyków. Przeuczenie występuje, gdy sieć zbyt dobrze uczy się danych treningowych, łącznie z ich szumem i szczegółami, co skutkuje słabą wydajnością na nowych, niewidzianych danych. Jest to szczególnie problematyczne w głębokich sieciach, które mają dużo parametrów w stosunku do wielkości danych treningowych. Niedouczenie to odwrotny problem—sieć nie posiada wystarczającej złożoności lub nie jest odpowiednio wytrenowana, by uchwycić wzorce w danych. Problem zanikających gradientów pojawia się w bardzo głębokich sieciach, gdy gradienty stają się coraz mniejsze podczas propagacji wstecznej, przez co wagi w początkowych warstwach aktualizują się bardzo wolno lub wcale. Problem eksplodujących gradientów to odwrotność—gradienty stają się zbyt duże, powodując niestabilny trening. Współczesne rozwiązania obejmują normalizację wsadową (batch normalization), która normalizuje wejścia warstwy, utrzymując stabilny przepływ gradientów; połączenia resztkowe (skip connections), które umożliwiają bezpośredni przepływ gradientów przez warstwy; oraz przycinanie gradientów (gradient clipping), które ogranicza ich wielkość. Techniki regularizacji takie jak L1 i L2 dodają kary za duże wagi, promując prostsze modele lepiej uogólniające. Dropout losowo dezaktywuje neurony podczas treningu, zapobiegając współzależnościom i poprawiając generalizację. Wybór optymalizatora (np. Adam, SGD, RMSprop) i współczynnika uczenia ma istotny wpływ na wydajność treningu i końcowe rezultaty. Praktycy muszą starannie wyważyć złożoność modelu, wielkość zbioru danych treningowych, siłę regularizacji i parametry optymalizacji, aby uzyskać sieci uczące się efektywnie bez przeuczenia.
Ewolucja architektur sieci neuronowych podążała wyraźną ścieżką ku coraz bardziej zaawansowanym mechanizmom przetwarzania informacji. Wczesne sieci jednokierunkowe były ograniczone do wejść o stałym rozmiarze i nie potrafiły wychwytywać zależności sekwencyjnych czy czasowych. Rekurencyjne sieci neuronowe (RNN) wprowadziły sprzężenia zwrotne, pozwalając na utrzymywanie informacji przez kolejne kroki, umożliwiając przetwarzanie sekwencji o zmiennej długości. Jednak RNN borykały się z problemami przepływu gradientów i były z natury sekwencyjne, co uniemożliwiało ich równoleglenie na nowoczesnym sprzęcie. Sieci LSTM (Long Short-Term Memory) rozwiązały część tych problemów dzięki komórkom pamięci i mechanizmom bramek, ale pozostały zasadniczo sekwencyjne. Przełom nastąpił wraz z sieciami transformerowymi, które całkowicie zastąpiły rekurencję mechanizmami uwagi. Mechanizm uwagi pozwala sieci dynamicznie skupiać się na różnych częściach wejścia, obliczając ważone kombinacje wszystkich elementów wejściowych równolegle. Dzięki temu transformatory efektywnie wychwytują dalekie zależności, zapewniając pełną równoległość na klastrach GPU. Architektura transformerów, połączona z ogromną skalą (współczesne duże modele językowe mają miliardy do bilionów parametrów), okazała się niezwykle skuteczna w przetwarzaniu języka naturalnego, widzeniu komputerowym i zadaniach multimodalnych. Sukces transformerów sprawił, że stały się one standardową architekturą najnowocześniejszych systemów AI, w tym wszystkich czołowych dużych modeli językowych. Ta ewolucja pokazuje, jak innowacje architektoniczne, wraz ze wzrostem mocy obliczeniowej i rozmiarów zbiorów danych, nieustannie przesuwają granice możliwości sieci neuronowych.
Dziedzina sieci neuronowych ewoluuje bardzo szybko, a na horyzoncie pojawia się wiele obiecujących kierunków. Obliczenia neuromorficzne mają na celu tworzenie sprzętu bliżej naśladującego biologiczne sieci neuronowe, potencjalnie osiągając większą efektywność energetyczną i moc obliczeniową. Uczenie few-shot i zero-shot skupia się na umożliwieniu sieciom neuronowym uczenia się na podstawie minimalnej liczby przykładów, zbliżając się do możliwości uczenia ludzi. Wyjaśnialność i interpretowalność stają się coraz ważniejsze—badacze tworzą techniki pozwalające zrozumieć i wizualizować, czego uczą się sieci, co jest kluczowe dla zastosowań w ochronie zdrowia, finansach czy wymiarze sprawiedliwości. Uczenie federacyjne pozwala trenować sieci na rozproszonych danych bez ich centralizacji, rozwiązując problem prywatności. Kwantowe sieci neuronowe to obszar, w którym łączy się zasady obliczeń kwantowych z architekturami sieci neuronowych, co potencjalnie może dać wykładnicze przyspieszenia w wybranych zadaniach. Sieci multimodalne integrujące tekst, obrazy, dźwięk i wideo stają się coraz bardziej zaawansowane, umożliwiając powstawanie kompleksowych systemów AI. Trwają także prace nad sieciami neuronowymi o wysokiej wydajności energetycznej, by zredukować koszty obliczeniowe i środowiskowe trenowania oraz wdrażania dużych modeli. Wraz z rozwojem sieci neuronowych ich integracja z systemami monitoringu AI, takimi jak AmICited, nabiera coraz większego znaczenia dla organizacji chcących rozumieć i zarządzać obecnością swojej marki w treściach i odpowiedziach generowanych przez AI na platformach takich jak ChatGPT, Perplexity, Google AI Overviews czy Claude.
Sieci neuronowe są inspirowane strukturą i funkcjonowaniem biologicznych neuronów w ludzkim mózgu. W mózgu neurony komunikują się za pomocą sygnałów elektrycznych przez synapsy, które mogą być wzmacniane lub osłabiane w zależności od doświadczenia. Sztuczne sieci neuronowe naśladują to zachowanie, wykorzystując matematyczne modele neuronów połączonych przez ważone połączenia, co pozwala systemowi uczyć się i dostosowywać na podstawie danych w sposób analogiczny do tego, jak biologiczne mózgi przetwarzają informacje i tworzą wspomnienia.
Propagacja wsteczna to główny algorytm umożliwiający naukę sieciom neuronowym. Podczas propagacji w przód dane przepływają przez warstwy sieci, generując predykcje. Sieć następnie oblicza błąd między przewidywanymi a rzeczywistymi wynikami za pomocą funkcji straty. W fazie wstecznej ten błąd jest propagowany przez sieć z wykorzystaniem reguły łańcuchowej rachunku różniczkowego, obliczając, w jakim stopniu każda waga i bias przyczyniły się do błędu. Wagi są następnie dostosowywane w kierunku minimalizującym błąd, zazwyczaj przy użyciu optymalizacji metodą spadku gradientu.
Główne architektury sieci neuronowych to sieci jednokierunkowe (dane przepływają tylko w jednym kierunku), konwolucyjne sieci neuronowe lub CNN (optymalizowane do przetwarzania obrazów), rekurencyjne sieci neuronowe lub RNN (zaprojektowane do danych sekwencyjnych), sieci długiej i krótkiej pamięci LSTM (ulepszone RNN z komórkami pamięci) oraz sieci transformerowe (wykorzystujące mechanizmy uwagi do przetwarzania równoległego). Każda architektura jest wyspecjalizowana do różnych typów danych i zadań, od rozpoznawania obrazów po przetwarzanie języka naturalnego.
Nowoczesne systemy AI, takie jak ChatGPT, Perplexity i Claude, są oparte na sieciach neuronowych typu transformer, które wykorzystują mechanizmy uwagi do efektywnego przetwarzania języka. Te sieci neuronowe umożliwiają tym systemom rozumienie kontekstu, generowanie spójnych tekstów i wykonywanie złożonych zadań wnioskowania. Zdolność sieci neuronowych do uczenia się na podstawie ogromnych zbiorów danych i wychwytywania złożonych wzorców w języku sprawia, że są one niezbędne do budowy konwersacyjnych AI, które mogą rozumieć i odpowiadać na ludzkie zapytania z niezwykłą precyzją.
Wagi w sieciach neuronowych kontrolują siłę połączeń między neuronami, określając, jaki wpływ ma każdy sygnał wejściowy na wyjście. Biasy to dodatkowe parametry, które przesuwają próg aktywacji neuronów, umożliwiając im aktywację nawet przy słabych sygnałach wejściowych. Razem wagi i biasy tworzą parametry uczące się sieci, które są dostosowywane podczas treningu w celu minimalizacji błędów predykcji i umożliwienia sieci uczenia się złożonych wzorców z danych.
Funkcje aktywacji wprowadzają nieliniowość do sieci neuronowych, umożliwiając im uczenie się złożonych, nieliniowych zależności w danych. Bez funkcji aktywacji, nawet wiele warstw dawałoby wyłącznie przekształcenia liniowe, znacznie ograniczając zdolność uczenia się sieci. Do popularnych funkcji aktywacji należą ReLU (Rectified Linear Unit), sigmoid i tanh, z których każda wprowadza inną nieliniowość, pomagając w wychwytywaniu złożonych wzorców i dokonywaniu bardziej zaawansowanych predykcji.
Warstwy ukryte to pośrednie warstwy pomiędzy warstwą wejściową a wyjściową, w których sieć wykonuje większość obliczeń. Warstwy te wydobywają i przekształcają cechy z surowych danych wejściowych w coraz bardziej abstrakcyjne reprezentacje. Głębokość i szerokość warstw ukrytych określa zdolność sieci do uczenia się złożonych wzorców. Głębsze sieci z większą liczbą warstw ukrytych mogą wychwytywać bardziej zaawansowane relacje w danych, choć wymagają więcej zasobów obliczeniowych i ostrożnego treningu, by uniknąć przeuczenia.
Zacznij śledzić, jak chatboty AI wspominają Twoją markę w ChatGPT, Perplexity i innych platformach. Uzyskaj praktyczne spostrzeżenia, aby poprawić swoją obecność w AI.
Architektura Transformera to projekt sieci neuronowej wykorzystujący mechanizmy samo-uwagi do równoległego przetwarzania danych sekwencyjnych. Stanowi podstawę ...
Struktura nawigacji to system organizujący strony i linki witryny, by prowadzić użytkowników i crawlery AI. Dowiedz się, jak wpływa na SEO, doświadczenie użytko...
Net Promoter Score (NPS) to wskaźnik lojalności klientów mierzący skłonność do polecenia. Dowiedz się, jak obliczać NPS, interpretować wyniki oraz porównywać je...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.