RAG Pipeline (Retrieval-Augmented Generation) to przepływ pracy, który umożliwia systemom AI wyszukiwanie, ocenianie i cytowanie zewnętrznych źródeł podczas generowania odpowiedzi. Łączy pobieranie dokumentów, ranking semantyczny i generowanie przez LLM, aby dostarczać dokładne, kontekstowo trafne odpowiedzi oparte na rzeczywistych danych. Systemy RAG ograniczają halucynacje, konsultując zewnętrzne bazy wiedzy przed wygenerowaniem odpowiedzi, co czyni je niezbędnymi dla zastosowań wymagających precyzji faktów i przypisania źródeł.
RAG Pipeline
RAG Pipeline (Retrieval-Augmented Generation) to przepływ pracy, który umożliwia systemom AI wyszukiwanie, ocenianie i cytowanie zewnętrznych źródeł podczas generowania odpowiedzi. Łączy pobieranie dokumentów, ranking semantyczny i generowanie przez LLM, aby dostarczać dokładne, kontekstowo trafne odpowiedzi oparte na rzeczywistych danych. Systemy RAG ograniczają halucynacje, konsultując zewnętrzne bazy wiedzy przed wygenerowaniem odpowiedzi, co czyni je niezbędnymi dla zastosowań wymagających precyzji faktów i przypisania źródeł.
Czym jest pipeline RAG?
RAG Pipeline (Retrieval-Augmented Generation) to architektura AI, która łączy wyszukiwanie informacji z generowaniem tekstu przez duże modele językowe (LLM), aby dostarczać dokładniejsze, kontekstowo trafne i weryfikowalne odpowiedzi. Zamiast polegać wyłącznie na danych treningowych LLM, systemy RAG dynamicznie pobierają istotne dokumenty lub dane z zewnętrznych baz wiedzy przed wygenerowaniem odpowiedzi, znacząco ograniczając halucynacje i poprawiając precyzję faktów. Pipeline stanowi pomost między statycznymi danymi treningowymi a informacjami w czasie rzeczywistym, umożliwiając systemom AI odwoływanie się do aktualnych, branżowych lub zastrzeżonych treści. Takie podejście stało się niezbędne dla organizacji wymagających odpowiedzi popartych cytatami, zgodności z normami dokładności oraz przejrzystości w generowanych przez AI treściach. Pipeline’y RAG są szczególnie cenne w monitorowaniu systemów AI, gdzie śledzenie źródeł i przypisanie są kluczowymi wymaganiami.
Kluczowe komponenty
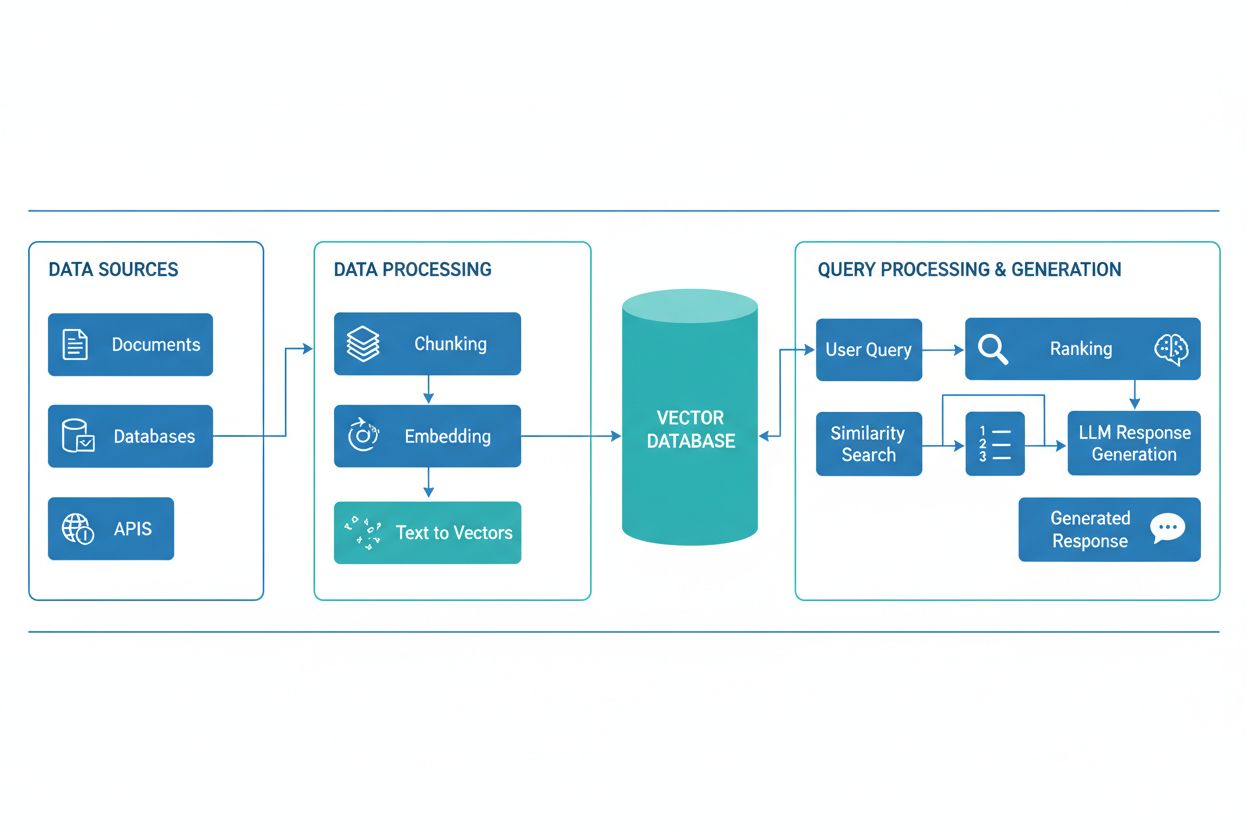
Pipeline RAG składa się z kilku powiązanych komponentów, które współpracują, by pobierać istotne informacje i generować odpowiedzi oparte na źródłach. Architektura zwykle obejmuje warstwę pobierania dokumentów, która przetwarza i przygotowuje surowe dane, bazę wektorową lub bazę wiedzy przechowującą osadzenia i zindeksowane treści, mechanizm wyszukiwania identyfikujący odpowiednie dokumenty na podstawie zapytań użytkownika, system rankingowy priorytetyzujący najbardziej trafne wyniki oraz moduł generowania zasilany LLM, który syntetyzuje pobrane informacje w spójne odpowiedzi. Dodatkowe komponenty to moduły przetwarzania i wstępnego przygotowania zapytań normalizujące dane wejściowe użytkownika, modele embeddingowe zamieniające tekst na reprezentacje numeryczne oraz pętla zwrotna stale poprawiająca trafność pobierania. Orkiestracja tych komponentów decyduje o skuteczności i wydajności całego systemu RAG.
Komponent
Funkcja
Kluczowe technologie
Pobieranie dokumentów
Przetwarzanie i przygotowanie surowych danych
Apache Kafka, LangChain, Unstructured
Baza wektorowa
Przechowywanie osadzeń i indeksowanych treści
Pinecone, Weaviate, Milvus, Qdrant
Silnik pobierania
Identyfikowanie odpowiednich dokumentów
BM25, Dense Passage Retrieval (DPR)
System rankingowy
Priorytetyzacja wyników wyszukiwania
Cross-encoders, reranking na bazie LLM
Moduł generowania
Synteza odpowiedzi z kontekstu
GPT-4, Claude, Llama, Mistral
Procesor zapytań
Normalizacja i rozumienie zapytań użytkownika
BERT, T5, własne pipeline’y NLP
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Pipeline RAG działa w dwóch wyraźnych fazach: fazie pobierania i fazie generowania. W fazie pobierania system zamienia zapytanie użytkownika w embedding przy użyciu tego samego modelu, który przetwarzał dokumenty bazy wiedzy, po czym przeszukuje bazę wektorową, aby znaleźć najbardziej semantycznie podobne dokumenty lub fragmenty. Ta faza zwykle zwraca uporządkowaną listę kandydatów, która może być dodatkowo udoskonalona przez algorytmy rerankingu wykorzystujące cross-encodery lub scoring oparty na LLM dla zapewnienia trafności. W fazie generowania najwyżej ocenione dokumenty są formatowane w okno kontekstowe i przekazywane do LLM razem z oryginalnym zapytaniem, umożliwiając generowanie odpowiedzi opartych na rzeczywistych źródłach. To dwuetapowe podejście gwarantuje, że odpowiedzi są zarówno kontekstowo odpowiednie, jak i możliwe do prześledzenia do konkretnych źródeł, co czyni je idealnym rozwiązaniem dla zastosowań wymagających cytowania i rozliczalności. Jakość końcowego wyniku zależy zarówno od trafności pobranych dokumentów, jak i umiejętności LLM w spójnym syntezowaniu informacji.
Kluczowe technologie i narzędzia
Ekosystem RAG obejmuje szeroki zakres wyspecjalizowanych narzędzi i frameworków ułatwiających budowę i wdrażanie pipeline’ów. Nowoczesne implementacje RAG korzystają z kilku kategorii technologii:
Frameworki orkiestracji: LangChain, LlamaIndex (dawniej GPT Index) oraz Haystack oferują warstwy abstrakcji umożliwiające budowę workflow RAG bez zarządzania każdym komponentem z osobna
Bazy wektorowe: Pinecone, Weaviate, Milvus, Qdrant oraz Chroma zapewniają skalowalne przechowywanie i pobieranie osadzeń o wysokim wymiarze z opóźnieniem poniżej milisekundy
Modele embeddingowe: text-embedding-3 od OpenAI, Embed API Cohere oraz modele open-source jak all-MiniLM-L6-v2 zamieniają tekst na reprezentacje semantyczne
Dostawcy LLM: OpenAI (GPT-4), Anthropic (Claude), Meta (Llama), Mistral oferują różne rozmiary modeli i możliwości generowania
Rozwiązania rerankujące: Rerank API Cohere, modele cross-encoder z Hugging Face oraz własne rerankery oparte na LLM zwiększają precyzję pobierania
Narzędzia do przygotowania danych: Unstructured, Apache Kafka i własne pipeline’y ETL obsługują pobieranie dokumentów, dzielenie na fragmenty i wstępne przetwarzanie
Monitorowanie i ewaluacja: Narzędzia takie jak Ragas, TruLens i własne frameworki ewaluacyjne oceniają wydajność systemów RAG i identyfikują tryby błędów
Narzędzia te można łączyć modułowo, umożliwiając organizacjom budowę systemów RAG dostosowanych do własnych wymagań i ograniczeń infrastruktury.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Mechanizmy pobierania
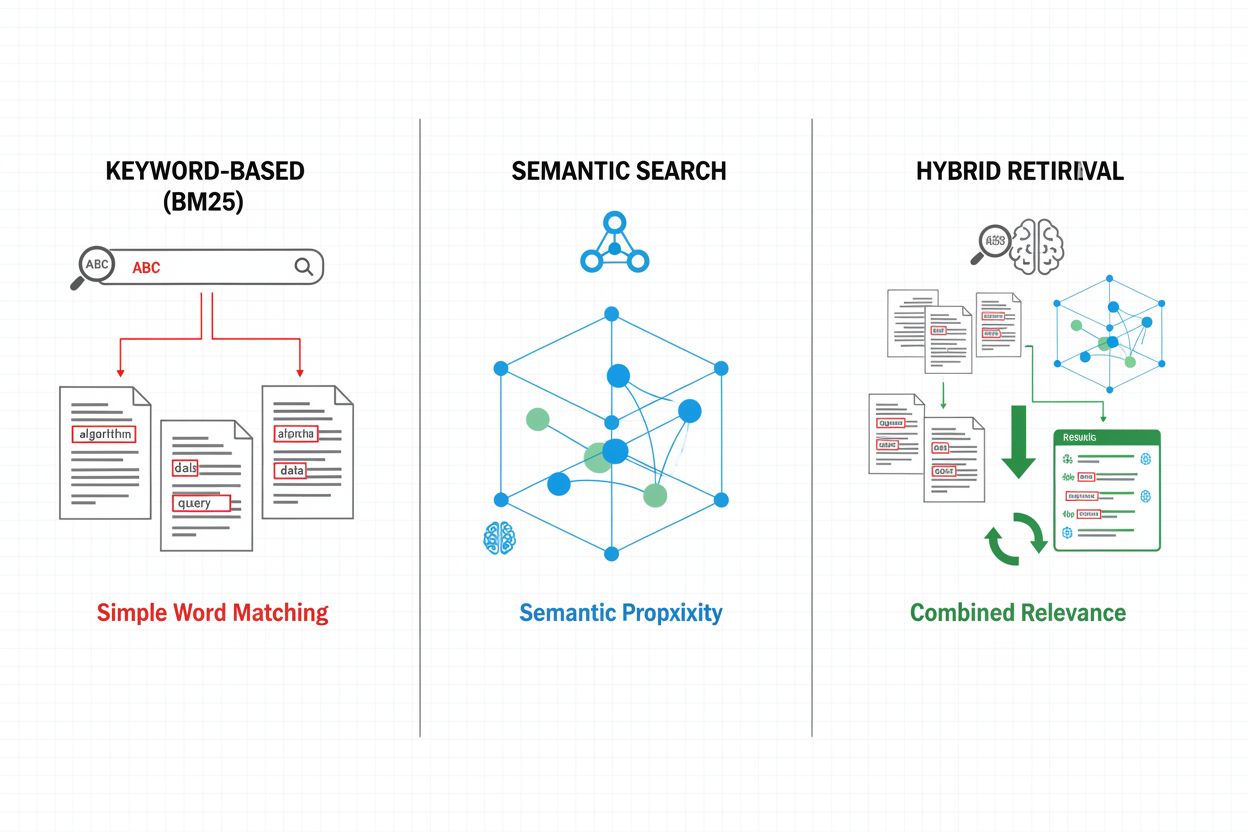
Mechanizmy pobierania stanowią fundament skuteczności pipeline’u RAG, ewoluując od prostych podejść opartych na słowach kluczowych do zaawansowanych metod wyszukiwania semantycznego. Tradycyjne pobieranie na podstawie słów kluczowych z użyciem algorytmów BM25 pozostaje wydajne i skuteczne w scenariuszach dopasowania dokładnego, ale ma trudności z rozumieniem semantycznym i synonimią. Dense Passage Retrieval (DPR) i inne metody neuronowe rozwiązują te ograniczenia, kodując zarówno zapytania, jak i dokumenty w gęste osadzenia wektorowe, umożliwiając dopasowanie na poziomie znaczenia, a nie tylko słów kluczowych. Podejścia hybrydowe łączą pobieranie słów kluczowych z wyszukiwaniem semantycznym, wykorzystując zalety obu metod, aby poprawić recall i precyzję dla różnych typów zapytań. Zaawansowane mechanizmy pobierania uwzględniają również ekspansję zapytań, czyli ich wzbogacanie o powiązane terminy lub przeformułowania, aby dotrzeć do większej liczby istotnych dokumentów. Warstwy rerankujące dodatkowo udoskonalają wyniki, stosując bardziej wymagające obliczeniowo modele oceniające dokumenty na podstawie głębszego rozumienia semantycznego lub kryteriów specyficznych dla zadania. Wybór mechanizmu pobierania znacząco wpływa na trafność kontekstu i koszt obliczeniowy pipeline’u RAG, wymagając świadomego kompromisu między szybkością a jakością.
Zalety pipeline’ów RAG
Pipeline’y RAG oferują znaczące korzyści w porównaniu do podejść opartych wyłącznie na LLM, szczególnie w zastosowaniach wymagających precyzji, aktualności i możliwości prześledzenia źródeł. Dzięki osadzeniu odpowiedzi w pobranych dokumentach systemy RAG radykalnie ograniczają halucynacje — przypadki, gdy LLM generuje przekonująco brzmiące, lecz nieprawdziwe informacje — co czyni je odpowiednimi dla branż wysokiego ryzyka, takich jak medycyna, prawo czy finanse. Możliwość odwoływania się do zewnętrznych baz wiedzy umożliwia systemom RAG podawanie aktualnych informacji bez konieczności ponownego trenowania modeli, pozwalając organizacjom na utrzymanie odpowiedzi zgodnych z najnowszą wiedzą. Pipeline’y RAG wspierają dostosowanie domenowe poprzez włączanie zastrzeżonych dokumentów, wewnętrznych baz wiedzy i specjalistycznej terminologii, generując trafniejsze i kontekstowo odpowiednie odpowiedzi. Komponent pobierania zapewnia przejrzystość i audytowalność, jasno wskazując, które źródła wpłynęły na odpowiedź — co jest kluczowe dla zgodności i zaufania użytkowników. Efektywność kosztowa zwiększa się dzięki wykorzystaniu mniejszych, wydajniejszych modeli LLM, które potrafią generować wysokiej jakości odpowiedzi przy odpowiednim kontekście, ograniczając koszty obliczeniowe w porównaniu z większymi modelami. Te korzyści czynią RAG szczególnie wartościowym dla organizacji wdrażających monitoring AI, gdzie precyzja cytowania i widoczność treści są priorytetem.
Wyzwania i ograniczenia
Pomimo licznych zalet pipeline’y RAG napotykają na szereg wyzwań technicznych i operacyjnych, które wymagają starannego zarządzania. Jakość pobranych dokumentów bezpośrednio wpływa na jakość odpowiedzi, przez co błędy w pobieraniu są trudne do naprawienia — zjawisko znane jako “garbage in, garbage out”, gdzie nieistotne lub nieaktualne dokumenty propagują się do końcowych odpowiedzi. Modele embeddingowe mogą mieć trudności z terminologią branżową, rzadkimi językami lub bardzo specjalistyczną treścią, prowadząc do słabego dopasowania semantycznego i pominięcia istotnych dokumentów. Koszt obliczeniowy pobierania, generowania embeddingów i rerankingu może być znaczny w dużej skali, zwłaszcza przy dużych bazach wiedzy lub wysokim natężeniu zapytań. Ograniczenia okna kontekstowego w LLM ograniczają ilość pobranych informacji, które można przekazać do promptu, co wymaga starannego wyboru i streszczenia istotnych fragmentów. Utrzymanie świeżości i spójności bazy wiedzy stanowi wyzwanie operacyjne, szczególnie w dynamicznych środowiskach, gdzie informacje szybko się zmieniają lub pochodzą z wielu źródeł. Ewaluacja wydajności systemów RAG wymaga kompleksowych metryk wykraczających poza tradycyjną dokładność, obejmując precyzję pobierania, trafność odpowiedzi i poprawność cytowania, co bywa trudne do oceny automatycznie.
RAG vs. inne podejścia
RAG to jedno z kilku podejść zwiększających dokładność i trafność LLM, każde z własnymi kompromisami. Fine-tuning polega na ponownym trenowaniu modeli na danych domenowych, oferując głęboką personalizację kosztem dużych zasobów obliczeniowych, potrzeby oznaczonych danych i konieczności ciągłego utrzymania wraz ze zmianą wiedzy. Inżynieria promptów optymalizuje instrukcje i kontekst bez zmiany wag modelu, zapewniając elastyczność i niskie koszty, ale ograniczoną przez dane treningowe i rozmiar okna kontekstowego. Uczenie w kontekście (in-context learning) wykorzystuje przykłady w promptach do kształtowania zachowania modelu, umożliwiając szybką adaptację, ale zużywając cenne tokeny kontekstu i wymagając starannego doboru przykładów. RAG oferuje rozwiązanie pośrednie: dynamiczny dostęp do aktualnych informacji bez ponownego trenowania, przejrzystość dzięki jawnemu cytowaniu oraz skalowalność w różnych domenach wiedzy. Jednak RAG wprowadza dodatkową złożoność infrastruktury pobierania i ryzyko błędów pobierania, podczas gdy fine-tuning zapewnia głębszą integrację wiedzy domenowej z zachowaniem modelu. Optymalne rozwiązania często łączą wiele strategii — np. RAG z modelami po fine-tuningu i starannie przygotowanymi promptami — aby maksymalizować precyzję i trafność dla konkretnych zastosowań.
Budowa i wdrażanie RAG
Wdrożenie produkcyjnego pipeline’u RAG wymaga systematycznego planowania w zakresie przygotowania danych, projektowania architektury i aspektów operacyjnych. Proces zaczyna się od przygotowania bazy wiedzy: zebrania odpowiednich dokumentów, oczyszczenia i ujednolicenia formatów oraz podzielenia treści na fragmenty o odpowiedniej wielkości, zapewniające balans między zachowaniem kontekstu a precyzją pobierania. Następnie organizacje wybierają modele embeddingowe i bazy wektorowe w zależności od wymagań wydajnościowych, opóźnień i skalowalności, biorąc pod uwagę wymiar embeddingów, przepustowość zapytań i pojemność magazynowania. Konfiguracja systemu pobierania obejmuje wybór algorytmów (słowa kluczowe, semantyczne lub hybrydowe), strategii rerankingu i kryteriów filtrowania wyników. Integracja z dostawcami LLM polega na ustanowieniu połączeń z modelami generującymi i zdefiniowaniu szablonów promptów efektywnie włączających pobrany kontekst. Testowanie i ewaluacja są kluczowe, wymagając metryk jakości pobierania (precyzja, recall, MRR), generowania (trafność, spójność, faktualność) oraz wydajności całego systemu. Aspekty wdrożeniowe obejmują monitorowanie trafności pobierania i jakości generowania, wdrażanie pętli zwrotnych do identyfikacji i naprawy błędów oraz ustalenie procedur aktualizacji i utrzymania bazy wiedzy. Ostatecznie ciągła optymalizacja polega na analizie interakcji użytkowników, identyfikacji typowych błędów i iteracyjnym udoskonalaniu mechanizmów pobierania, rerankingu i inżynierii promptów w celu zwiększenia wydajności systemu.
RAG w monitoringu AI i cytowaniu
Pipeline’y RAG są podstawą nowoczesnych platform monitoringu AI, takich jak AmICited.com, gdzie kluczowe jest śledzenie źródeł i precyzji generowanych przez AI treści. Dzięki jawnemu pobieraniu i cytowaniu dokumentów źródłowych systemy RAG tworzą audytowalną ścieżkę umożliwiającą platformom monitorującym weryfikację twierdzeń, ocenę precyzji faktów oraz identyfikację potencjalnych halucynacji lub błędnych przypisań. Ta zdolność do cytowania wypełnia istotną lukę w przejrzystości AI: użytkownicy i audytorzy mogą prześledzić odpowiedzi do oryginalnych źródeł, umożliwiając niezależną weryfikację i budując zaufanie do generowanych przez AI treści. Dla twórców treści i organizacji korzystających z narzędzi AI monitoring oparty na RAG zapewnia widoczność, które źródła przyczyniły się do powstania konkretnych odpowiedzi, wspierając zgodność z wymogami przypisania i polityką zarządzania treściami. Komponent pobierania generuje bogate metadane — w tym wyniki trafności, rankingi dokumentów i metryki pewności pobierania — które systemy monitorujące mogą analizować, oceniając wiarygodność odpowiedzi i identyfikując sytuacje, w których systemy AI wychodzą poza swoje domeny wiedzy. Integracja RAG z platformami monitorującymi umożliwia wykrywanie dryfu cytowań, czyli stopniowego odchodzenia AI od źródeł autorytatywnych na rzecz mniej wiarygodnych, oraz wspiera egzekwowanie polityk jakości i różnorodności źródeł. W miarę jak AI staje się integralną częścią krytycznych procesów, połączenie pipeline’ów RAG z kompleksowym monitoringiem zapewnia mechanizmy odpowiedzialności, które chronią użytkowników, organizacje i cały ekosystem informacyjny przed dezinformacją generowaną przez AI.
Najczęściej zadawane pytania
Jaka jest różnica między RAG a fine-tuningiem?
RAG i fine-tuning to uzupełniające się podejścia do poprawy wydajności LLM. RAG pobiera zewnętrzne dokumenty w czasie zapytania bez modyfikowania modelu, umożliwiając dostęp do danych w czasie rzeczywistym i łatwe aktualizacje. Fine-tuning polega na ponownym uczeniu modelu na danych domenowych, umożliwiając głębszą personalizację, ale wymagając znacznych zasobów obliczeniowych i ręcznych aktualizacji przy zmianie informacji. Wiele organizacji łączy obie techniki dla optymalnych rezultatów.
Jak RAG ogranicza halucynacje w odpowiedziach AI?
RAG ogranicza halucynacje, opierając odpowiedzi LLM na pobranych, rzeczywistych dokumentach. Zamiast polegać wyłącznie na danych treningowych, system pobiera odpowiednie źródła przed generowaniem, dostarczając modelowi konkretnych dowodów do odniesienia. Takie podejście zapewnia, że odpowiedzi opierają się na rzeczywistych informacjach, a nie wyłącznie na wzorcach wyuczonych przez model, co znacząco poprawia precyzję faktów i ogranicza fałszywe lub mylące twierdzenia.
Czym są wektorowe osadzenia (vector embeddings) i dlaczego są ważne w RAG?
Wektorowe osadzenia to numeryczne reprezentacje tekstu, oddające znaczenie semantyczne w wielowymiarowej przestrzeni. Pozwalają systemom RAG na wyszukiwanie semantyczne, czyli znajdowanie dokumentów o podobnym znaczeniu, nawet jeśli używają innych słów. Osadzenia są kluczowe, ponieważ umożliwiają RAG wyjście poza dopasowanie słów kluczowych i rozumienie relacji pojęciowych, co poprawia trafność pobierania i umożliwia generowanie dokładniejszych odpowiedzi.
Czy pipeline'y RAG mogą pracować z danymi w czasie rzeczywistym?
Tak, pipeline'y RAG mogą uwzględniać dane w czasie rzeczywistym dzięki ciągłemu pobieraniu i indeksowaniu. Organizacje mogą skonfigurować automatyczne pipeline'y, które regularnie aktualizują bazę wektorową o nowe dokumenty, zapewniając aktualność bazy wiedzy. Ta możliwość sprawia, że RAG jest idealny dla zastosowań wymagających najświeższych informacji, takich jak analiza wiadomości, analiza cen czy monitorowanie rynku, bez konieczności ponownego trenowania modelu LLM.
Jaka jest różnica między wyszukiwaniem semantycznym a RAG?
Wyszukiwanie semantyczne to technika pobierania, która znajduje dokumenty na podstawie podobieństwa znaczenia przy użyciu osadzeń wektorowych. RAG to kompletny pipeline, który łączy wyszukiwanie semantyczne z generowaniem przez LLM, aby dostarczać odpowiedzi oparte na pobranych dokumentach. Podczas gdy wyszukiwanie semantyczne skupia się na znajdowaniu trafnych informacji, RAG dodaje komponent generowania, który syntetyzuje pobrane treści w spójne odpowiedzi z cytowaniami.
Jak systemy RAG decydują, które źródła cytować?
Systemy RAG wykorzystują wiele mechanizmów do wyboru źródeł do cytowania. Stosują algorytmy pobierania do znajdowania odpowiednich dokumentów, modele rerankingu do priorytetyzacji najtrafniejszych wyników oraz procesy weryfikacji, aby upewnić się, że cytaty rzeczywiście wspierają przedstawiane twierdzenia. Niektóre systemy stosują podejście 'cytowania podczas pisania', w którym twierdzenia pojawiają się tylko wtedy, gdy są poparte pobranymi źródłami, podczas gdy inne weryfikują cytaty po generacji i usuwają twierdzenia niepoparte źródłami.
Jakie są główne wyzwania w budowie pipeline'ów RAG?
Kluczowe wyzwania to utrzymywanie świeżości i jakości bazy wiedzy, optymalizacja trafności pobierania dla różnorodnych typów treści, zarządzanie kosztami obliczeniowymi na dużą skalę, obsługa terminologii domenowej, której modele osadzeń mogą nie rozumieć, oraz ocena wydajności systemu przy użyciu kompleksowych metryk. Organizacje muszą również uwzględnić ograniczenia okna kontekstowego w LLM oraz zapewnić, że pobrane dokumenty pozostają istotne w miarę ewolucji informacji.
Jak AmICited monitoruje cytowania RAG w systemach AI?
AmICited śledzi, jak systemy AI takie jak ChatGPT, Perplexity czy Google AI Overviews pobierają i cytują treści przez pipeline'y RAG. Platforma monitoruje, które źródła są wybierane do cytowania, jak często Twoja marka pojawia się w odpowiedziach AI oraz czy cytaty są poprawne. Taka widoczność pomaga organizacjom zrozumieć swoją obecność w wyszukiwaniu wspomaganym przez AI i zapewnić właściwe przypisanie ich treści.
Monitoruj swoją markę w odpowiedziach AI
Śledź, jak systemy AI takie jak ChatGPT, Perplexity czy Google AI Overviews odnoszą się do Twoich treści. Zyskaj wgląd w cytowania RAG oraz monitorowanie odpowiedzi AI.
Czym jest RAG w wyszukiwaniu AI: Kompletny przewodnik po Retrieval-Augmented Generation
Dowiedz się, czym jest RAG (Retrieval-Augmented Generation) w wyszukiwaniu AI. Odkryj, jak RAG zwiększa dokładność, ogranicza halucynacje i napędza ChatGPT, Per...
Jak działa Retrieval-Augmented Generation: architektura i proces
Dowiedz się, jak RAG łączy LLM z zewnętrznymi źródłami danych, aby generować precyzyjne odpowiedzi AI. Poznaj pięcioetapowy proces, komponenty oraz znaczenie te...
Dowiedz się, czym jest Retrieval-Augmented Generation (RAG), jak działa i dlaczego jest niezbędny dla dokładnych odpowiedzi AI. Poznaj architekturę RAG, korzyśc...
11 min czytania
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.