Impacto dos Crawlers de IA nos Recursos do Servidor: O Que Esperar
Saiba como crawlers de IA impactam recursos do servidor, banda e desempenho. Descubra estatísticas reais, estratégias de mitigação e soluções de infraestrutura para gerenciar a carga de bots de forma eficaz.
Publicado em Jan 3, 2026.Última modificação em Jan 3, 2026 às 3:24 am
Compreendendo o Comportamento e a Escala dos Crawlers de IA
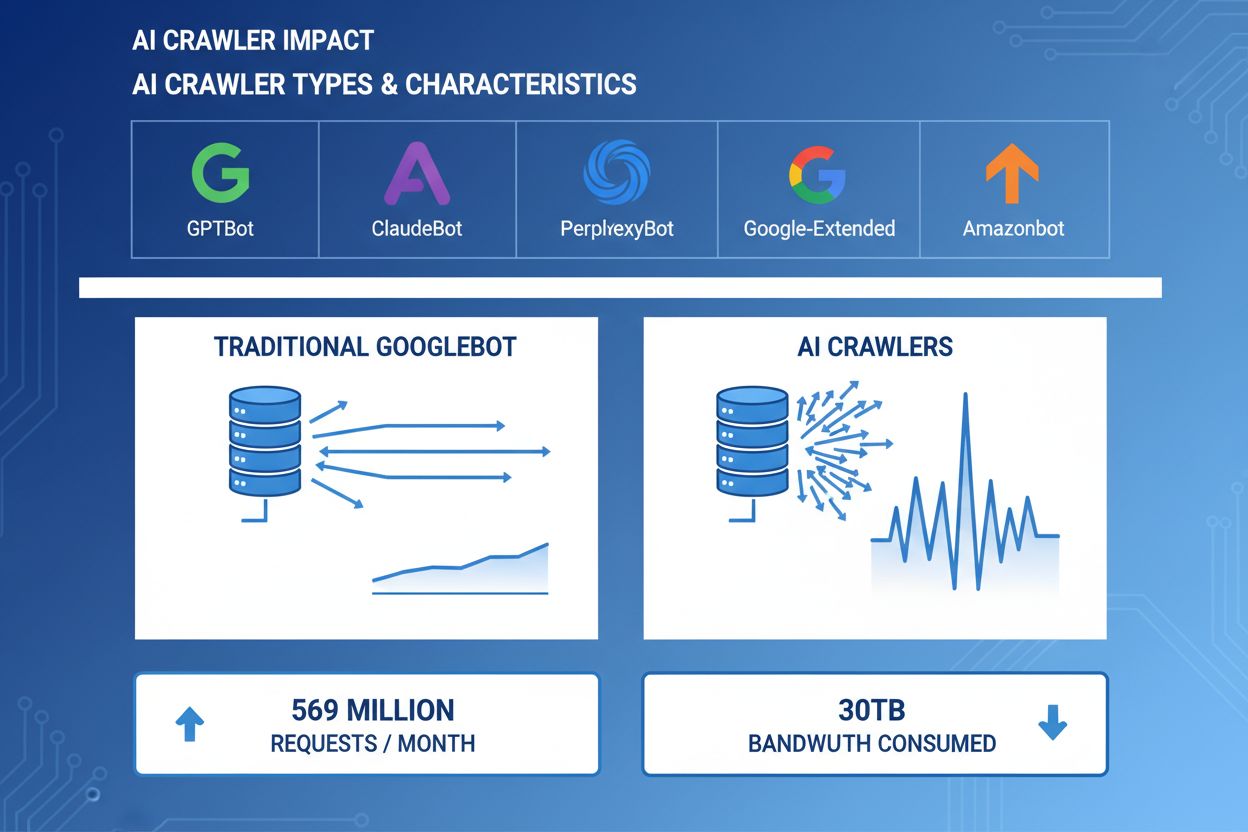
Os crawlers de IA tornaram-se uma força significativa no tráfego web, com grandes empresas de IA implantando bots sofisticados para indexar conteúdo com fins de treinamento e recuperação. Esses crawlers operam em grande escala, gerando aproximadamente 569 milhões de requisições por mês na web e consumindo mais de 30TB de banda globalmente. Os principais crawlers de IA incluem GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (Google) e Amazonbot (Amazon), cada um com padrões e exigências de recursos distintos. Entender o comportamento e as características desses crawlers é essencial para administradores de sites gerenciarem adequadamente os recursos do servidor e tomarem decisões informadas sobre políticas de acesso.
Nome do Crawler
Empresa
Finalidade
Padrão de Requisição
GPTBot
OpenAI
Dados de treinamento para ChatGPT e modelos GPT
Requisições agressivas e de alta frequência
ClaudeBot
Anthropic
Dados de treinamento para modelos Claude AI
Frequência moderada, rastreamento respeitoso
PerplexityBot
Perplexity AI
Busca em tempo real e geração de respostas
Frequência moderada a alta
Google-Extended
Google
Indexação estendida para recursos de IA
Controlado, segue o robots.txt
Amazonbot
Amazon
Indexação de produtos e conteúdo
Variável, foco em comércio
Métricas de Consumo de Recursos do Servidor
Crawlers de IA consomem recursos do servidor em múltiplas dimensões, gerando impactos mensuráveis no desempenho da infraestrutura. O uso de CPU pode saltar em mais de 300% durante picos de atividade de crawlers, à medida que servidores processam milhares de requisições simultâneas e analisam conteúdo HTML. O consumo de banda representa um dos custos mais visíveis, com um único site popular podendo servir gigabytes de dados para crawlers diariamente. O uso de memória aumenta significativamente, já que os servidores mantêm pools de conexão e armazenam grandes volumes de dados em buffer para processamento. Consultas ao banco de dados se multiplicam à medida que crawlers solicitam páginas que geram conteúdo dinâmico, criando pressão adicional de I/O. O I/O de disco torna-se gargalo quando os servidores precisam ler do armazenamento para atender às requisições dos crawlers, especialmente em sites com grandes bibliotecas de conteúdo.
Recurso
Impacto
Exemplo Real
CPU
Picos de 200-300% durante rastreamento intenso
Load average do servidor sobe de 2.0 para 8.0
Banda
15-40% do uso mensal total
Site de 500GB servindo 150GB para crawlers por mês
Memória
Aumento de 20-30% no consumo de RAM
Servidor de 8GB exigindo 10GB durante atividade de crawlers
Banco de Dados
Aumento de 2-5x na carga de consultas
Tempo de resposta de consultas sobe de 50ms para 250ms
I/O de Disco
Operações de leitura sustentadas e altas
Utilização de disco salta de 30% para 85%
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
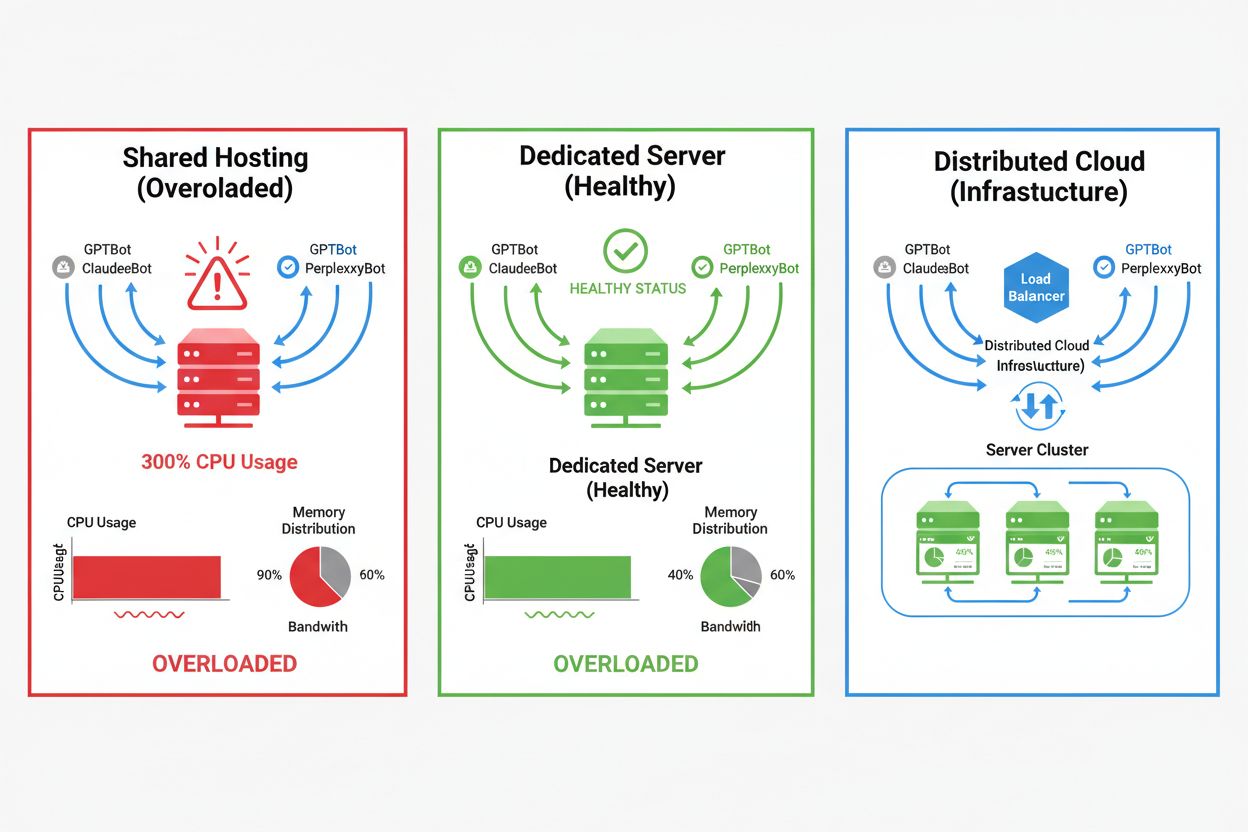
Hospedagem Compartilhada vs. Infraestrutura Dedicada
O impacto dos crawlers de IA varia drasticamente conforme o ambiente de hospedagem, sendo os ambientes compartilhados os que mais sofrem. Em hospedagem compartilhada, a “síndrome do vizinho barulhento” torna-se especialmente problemática—quando um site atrai muito tráfego de crawlers, consome recursos que seriam usados por outros sites no mesmo servidor, degradando o desempenho para todos. Servidores dedicados e infraestrutura em nuvem oferecem melhor isolamento e garantias de recursos, permitindo absorver o tráfego de crawlers sem afetar outros serviços. Porém, até mesmo infraestrutura dedicada exige monitoramento cuidadoso e escalonamento para lidar com a carga cumulativa de vários crawlers de IA operando simultaneamente.
Principais diferenças entre ambientes de hospedagem:
Hospedagem Compartilhada: Recursos limitados, sem isolamento, tráfego de crawlers impacta outros sites, controle mínimo sobre acesso dos crawlers
VPS/Nuvem: Recursos dedicados, melhor isolamento, capacidade escalável, controle granular sobre o gerenciamento de tráfego
Servidor Dedicado: Alocação total de recursos, controle total, maior custo, exige decisões manuais de escalonamento
CDN + Origem: Carga distribuída, cache em edge, tráfego de crawlers absorvido na borda, servidor de origem protegido
Implicações de Banda e Custos
O impacto financeiro do tráfego de crawlers de IA vai além dos custos simples de banda, incluindo gastos diretos e ocultos que podem afetar significativamente seus resultados. Custos diretos incluem cobranças elevadas de banda do provedor de hospedagem, que podem adicionar centenas ou milhares de dólares mensais, dependendo do volume de tráfego e intensidade dos crawlers. Custos ocultos surgem com necessidades de infraestrutura—você pode precisar atualizar planos de hospedagem, implementar camadas adicionais de cache ou investir em serviços de CDN especificamente para lidar com crawlers. O cálculo do ROI se torna complexo, considerando que crawlers de IA trazem pouco ou nenhum valor direto para o seu negócio enquanto consomem recursos que poderiam atender clientes pagantes ou melhorar a experiência do usuário. Muitos proprietários de sites percebem que o custo de acomodar o tráfego de crawlers excede qualquer benefício potencial de treinamento de IA ou visibilidade em buscas movidas por IA.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Impacto no Desempenho e Experiência do Usuário
O tráfego de crawlers de IA degrada diretamente a experiência dos visitantes legítimos ao consumir recursos do servidor que seriam usados para servir humanos com maior rapidez. Métricas dos Core Web Vitals sofrem de forma mensurável, com o Largest Contentful Paint (LCP) aumentando em 200-500ms e o Time to First Byte (TTFB) degradando em 100-300ms durante períodos de atividade intensa de crawlers. Essas degradações de desempenho provocam efeitos negativos em cascata: páginas lentas reduzem o engajamento, aumentam taxas de rejeição e diminuem conversões em sites de e-commerce e geração de leads. Rankings de busca também sofrem, já que o algoritmo do Google incorpora os Core Web Vitals como fator de ranqueamento, criando um ciclo vicioso onde crawlers prejudicam indiretamente seu SEO. Usuários que experimentam lentidão tendem a abandonar seu site e buscar concorrentes, afetando diretamente receita e percepção da marca.
Estratégias de Monitoramento e Detecção
O gerenciamento eficaz do tráfego de crawlers de IA começa com monitoramento e detecção abrangentes, permitindo entender o escopo do problema antes de implementar soluções. A maioria dos servidores web registra user-agents que identificam o crawler responsável por cada requisição, fornecendo base para análise de tráfego e decisões de filtragem. Logs do servidor, plataformas de análise e ferramentas especializadas podem analisar esses user-agents para identificar e quantificar padrões de tráfego de crawlers.
Principais métodos e ferramentas de detecção:
Análise de Logs: Analise logs do servidor buscando user-agents (GPTBot, ClaudeBot, Google-Extended, CCBot) para identificar requisições de crawlers
Plataformas de Analytics: Google Analytics, Matomo e similares permitem segmentar o tráfego de crawlers separadamente dos usuários humanos
Monitoramento em Tempo Real: Ferramentas como New Relic e Datadog fornecem visibilidade em tempo real da atividade dos crawlers e consumo de recursos
DNS Reverse Lookup: Verifique IPs de crawlers contra faixas publicadas por OpenAI, Anthropic e outras empresas de IA
Análise Comportamental: Identifique padrões suspeitos como requisições rápidas em sequência, combinações de user-agent incomuns ou acessos a áreas sensíveis
Estratégias de Mitigação - robots.txt e Limitação de Taxa
A primeira linha de defesa contra tráfego excessivo de crawlers de IA é implementar um arquivo robots.txt bem configurado que controle explicitamente o acesso dos crawlers ao seu site. Esse arquivo de texto, colocado na raiz do site, permite bloquear crawlers específicos, limitar a frequência de rastreamento e direcionar crawlers para um sitemap contendo apenas o conteúdo desejado para indexação. A limitação de taxa no nível da aplicação ou servidor oferece proteção adicional, limitando requisições de IPs ou user-agents específicos para evitar exaustão de recursos. Essas estratégias são não bloqueantes e reversíveis, ideais como ponto inicial antes de adotar medidas mais agressivas.
# robots.txt - Bloqueia crawlers de IA e permite mecanismos de busca legítimos
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: CCBot
Disallow: /
# Permitir Google e Bing
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Delay de rastreamento para outros bots
User-agent: *
Crawl-delay: 10
Request-rate: 1/10s
Proteção Avançada - WAF e Soluções de CDN
Firewalls de Aplicação Web (WAF) e Redes de Distribuição de Conteúdo (CDN) oferecem proteção sofisticada e de nível empresarial contra crawlers indesejados, por meio de análise comportamental e filtragem inteligente. Cloudflare e outros provedores de CDN trazem recursos integrados de gerenciamento de bots que identificam e bloqueiam crawlers de IA com base em padrões de comportamento, reputação de IP e características das requisições, sem necessidade de configuração manual. Regras de WAF podem ser configuradas para desafiar requisições suspeitas, limitar a taxa de determinados user-agents ou bloquear totalmente o tráfego de faixas de IP conhecidas de crawlers. Essas soluções atuam na borda da rede, filtrando tráfego malicioso antes que chegue ao servidor de origem, reduzindo drasticamente a carga sobre sua infraestrutura. A vantagem dessas soluções é a capacidade de se adaptar a novos crawlers e padrões de ataque sem exigir atualizações manuais na configuração.
Equilibrando Visibilidade e Proteção
Decidir bloquear ou não crawlers de IA exige ponderação cuidadosa entre proteger seus recursos e manter visibilidade em resultados de busca e aplicações movidas por IA. Bloquear todos os crawlers de IA elimina a possibilidade de seu conteúdo aparecer em buscas do ChatGPT, respostas do Perplexity AI ou outros mecanismos de descoberta baseados em IA, podendo reduzir tráfego de referência e visibilidade da marca. Por outro lado, permitir acesso irrestrito consome recursos significativos e pode degradar a experiência do usuário sem benefícios mensuráveis para o negócio. A estratégia ideal depende da sua situação: sites de alto tráfego e muitos recursos podem optar por permitir crawlers, enquanto sites com recursos limitados devem priorizar a experiência do usuário, bloqueando ou limitando o acesso. Decisões estratégicas devem considerar seu setor, público-alvo, tipo de conteúdo e objetivos de negócio, e não adotar uma abordagem única para todos.
Soluções de Escalabilidade de Infraestrutura
Para sites que optam por acomodar o tráfego de crawlers de IA, o escalonamento da infraestrutura é um caminho para manter o desempenho mesmo com maior carga. Escalonamento vertical—upgrade de servidores com mais CPU, RAM e banda—é uma solução direta, porém cara e limitada fisicamente. Escalonamento horizontal—distribuir tráfego entre múltiplos servidores via balanceadores de carga—oferece melhor escalabilidade e resiliência no longo prazo. Plataformas de nuvem como AWS, Google Cloud e Azure trazem auto-escalonamento, provisionando recursos automaticamente em picos, reduzindo-os em períodos de baixa para minimizar custos. CDNs podem armazenar conteúdo estático em pontos de borda, reduzindo a carga no servidor de origem e melhorando o desempenho para humanos e crawlers. Otimização de banco de dados, cache de consultas e melhorias no nível da aplicação também reduzem o consumo de recursos por requisição, aumentando a eficiência sem demandar mais infraestrutura.
Ferramentas de Monitoramento e Boas Práticas
O monitoramento e otimização contínuos são essenciais para manter o desempenho ideal diante do tráfego persistente de crawlers de IA. Ferramentas especializadas fornecem visibilidade sobre a atividade dos crawlers, consumo de recursos e métricas de desempenho, permitindo decisões baseadas em dados sobre estratégias de gerenciamento. Implementar monitoramento desde o início permite estabelecer linhas de base, identificar tendências e medir a eficácia das estratégias de mitigação ao longo do tempo.
Ferramentas e práticas essenciais de monitoramento:
Monitoramento de Servidor: New Relic, Datadog ou Prometheus para métricas em tempo real de CPU, memória e I/O de disco
Análise de Logs: ELK Stack, Splunk ou Graylog para parsear e analisar logs do servidor e identificar padrões de crawlers
Soluções Especializadas: AmICited.com oferece monitoramento especializado de atividade de crawlers de IA, mostrando quais modelos de IA acessam seu conteúdo
Rastreamento de Desempenho: Google PageSpeed Insights, WebPageTest e monitoramento dos Core Web Vitals para medir o impacto na experiência do usuário
Alertas: Configure alertas para picos de recursos, padrões de tráfego incomuns e degradação de desempenho para resposta rápida
Estratégia de Longo Prazo e Considerações Futuras
O cenário de gerenciamento de crawlers de IA continua evoluindo, com padrões emergentes e iniciativas setoriais moldando a relação entre sites e empresas de IA. O padrão llms.txt representa uma abordagem emergente para fornecer informações estruturadas sobre direitos de uso de conteúdo e preferências às empresas de IA, oferecendo alternativa mais sutil ao bloqueio total ou liberação irrestrita. Discussões sobre modelos de compensação indicam que empresas de IA podem futuramente pagar pelo acesso a dados de treinamento, mudando fundamentalmente a economia do tráfego de crawlers. Preparar sua infraestrutura para o futuro exige acompanhar padrões emergentes, monitorar o setor e manter flexibilidade nas políticas de gerenciamento de crawlers. Construir relacionamento com empresas de IA, participar de discussões do setor e defender modelos justos de compensação será cada vez mais importante à medida que a IA se torna central na descoberta e consumo de conteúdo na web. Os sites que prosperarem nesse cenário serão os que equilibram inovação com pragmatismo, protegendo seus recursos e permanecendo abertos a oportunidades legítimas de visibilidade e parceria.
Perguntas frequentes
Qual é a diferença entre crawlers de IA e crawlers de mecanismos de busca?
Crawlers de IA (GPTBot, ClaudeBot) extraem conteúdo para treinamento de LLM sem necessariamente gerar tráfego de retorno. Crawlers de busca (Googlebot) indexam conteúdo para visibilidade em buscas e normalmente enviam tráfego de referência. Crawlers de IA operam de forma mais agressiva, com grandes volumes de requisições e ignoram diretrizes de economia de banda.
Quanta banda os crawlers de IA podem consumir?
Exemplos reais mostram mais de 30TB por mês de um único crawler. O consumo depende do tamanho do site, volume de conteúdo e frequência do crawler. Somente o GPTBot da OpenAI gerou 569 milhões de requisições em um único mês na rede da Vercel.
Bloquear crawlers de IA prejudica meu SEO?
Bloquear crawlers de treinamento de IA (GPTBot, ClaudeBot) não afeta o ranking do Google. Porém, bloquear crawlers de busca de IA pode reduzir a visibilidade em resultados de busca movidos por IA como o Perplexity ou a busca do ChatGPT.
Quais são os sinais de que meu servidor está sobrecarregado por crawlers?
Procure picos inexplicáveis de CPU (300%+), aumento de uso de banda sem crescimento de visitantes humanos, lentidão no carregamento de páginas e user-agents incomuns nos logs do servidor. As métricas dos Core Web Vitals também podem degradar significativamente.
Vale a pena migrar para hospedagem dedicada para gerenciar crawlers?
Para sites com tráfego significativo de crawlers, a hospedagem dedicada oferece melhor isolamento, controle e previsibilidade de custos. Ambientes compartilhados sofrem com a 'síndrome do vizinho barulhento', onde o tráfego de crawlers de um site afeta todos os sites hospedados.
Quais ferramentas devo usar para monitorar a atividade dos crawlers de IA?
Use o Google Search Console para dados do Googlebot, logs de acesso do servidor para análise detalhada, análises de CDN (Cloudflare) e plataformas especializadas como a AmICited.com para monitoramento e rastreamento abrangentes de crawlers de IA.
Posso permitir seletivamente alguns crawlers e bloquear outros?
Sim, via diretivas no robots.txt, regras de WAF e filtragem por IP. Você pode permitir crawlers benéficos como o Googlebot e bloquear crawlers de treinamento de IA que consomem muitos recursos usando regras específicas de user-agent.
Como saber se crawlers de IA estão afetando o desempenho do meu site?
Compare as métricas do servidor antes e depois de implementar controles de crawlers. Monitore Core Web Vitals (LCP, TTFB), tempo de carregamento, uso de CPU e métricas de experiência do usuário. Ferramentas como Google PageSpeed Insights e plataformas de monitoramento de servidores fornecem insights detalhados.
Monitore o Impacto dos Crawlers de IA Hoje
Obtenha insights em tempo real sobre como modelos de IA acessam seu conteúdo e impactam seus recursos de servidor com a plataforma especializada de monitoramento da AmICited.
Você Deve Bloquear ou Permitir Crawlers de IA? Estrutura para Tomada de Decisão
Aprenda como tomar decisões estratégicas sobre o bloqueio de crawlers de IA. Avalie tipo de conteúdo, fontes de tráfego, modelos de receita e posição competitiv...
Quais Crawlers de IA Devo Permitir? Guia Completo para 2025
Saiba quais crawlers de IA permitir ou bloquear no seu robots.txt. Guia abrangente cobrindo GPTBot, ClaudeBot, PerplexityBot e mais de 25 crawlers de IA com exe...
Como Identificar Crawlers de IA em Logs de Servidor: Guia Completo de Detecção
Aprenda como identificar e monitorar crawlers de IA como GPTBot, PerplexityBot e ClaudeBot em seus logs de servidor. Descubra strings de user-agent, métodos de ...
9 min de leitura
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.