
Regras WAF para Crawlers de IA: Além do Robots.txt
Saiba como Firewalls de Aplicação Web oferecem controle avançado sobre crawlers de IA além do robots.txt. Implemente regras WAF para proteger seu conteúdo contr...
10 min de leitura
Aprenda como implementar o bloqueio seletivo de crawlers de IA para proteger seu conteúdo de bots de treinamento e, ao mesmo tempo, manter a visibilidade nos resultados de busca por IA. Estratégias técnicas para publishers.
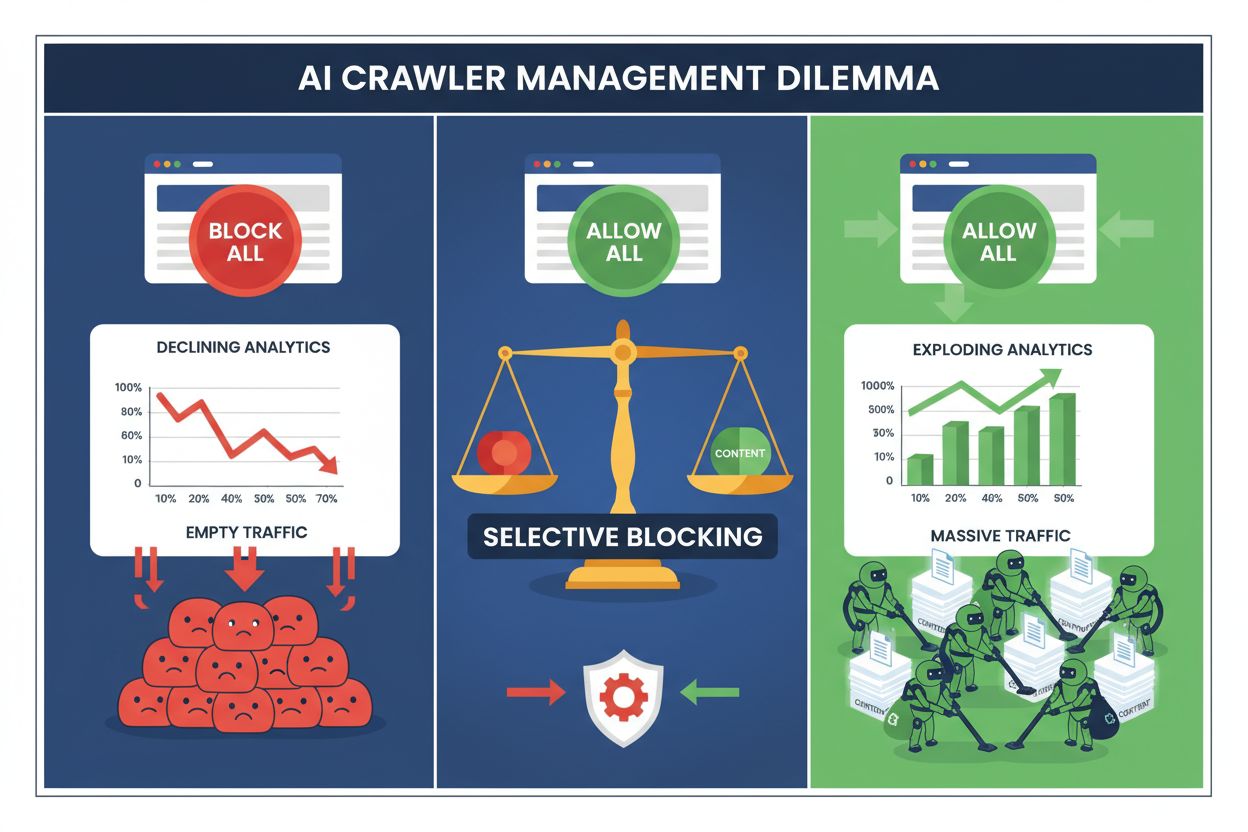
Publishers hoje enfrentam uma escolha impossível: bloquear todos os crawlers de IA e perder o valioso tráfego dos motores de busca, ou permitir todos e ver seu conteúdo alimentar datasets de treinamento sem compensação. O avanço da IA generativa criou um ecossistema bifurcado de crawlers, onde as mesmas regras do robots.txt se aplicam indiscriminadamente a motores de busca que geram receita e a crawlers de treinamento que extraem valor. Esse paradoxo forçou publishers visionários a desenvolver estratégias de controle seletivo de crawlers que diferenciam os diversos tipos de bots de IA com base em seu impacto real nos indicadores do negócio.
O cenário dos crawlers de IA se divide em duas categorias distintas, com propósitos e impactos de negócio muito diferentes. Crawlers de treinamento—operados por empresas como OpenAI, Anthropic e Google—são projetados para ingerir grandes volumes de texto para construir e aprimorar modelos de linguagem, enquanto crawlers de busca indexam conteúdo para recuperação e descoberta. Bots de treinamento respondem por cerca de 80% de toda atividade de bots relacionada à IA, mas geram zero receita direta para os publishers, enquanto crawlers de busca como Googlebot e Bingbot geram milhões de visitas e impressões publicitárias anualmente. A distinção importa porque um único crawler de treinamento pode consumir banda equivalente a milhares de usuários humanos, enquanto crawlers de busca são otimizados para eficiência e normalmente respeitam limites de taxa.
| Nome do Bot | Operador | Propósito Principal | Potencial de Tráfego |
|---|---|---|---|
| GPTBot | OpenAI | Treinamento de modelo | Nenhum (extração de dados) |
| Claude Web Crawler | Anthropic | Treinamento de modelo | Nenhum (extração de dados) |
| Googlebot | Indexação de busca | 243,8M visitas (abril 2025) | |
| Bingbot | Microsoft | Indexação de busca | 45,2M visitas (abril 2025) |
| Perplexity Bot | Perplexity AI | Busca + treinamento | 12,1M visitas (abril 2025) |
Os dados são claros: o crawler do ChatGPT sozinho enviou 243,8 milhões de visitas para publishers em abril de 2025, mas essas visitas geraram zero cliques, zero impressões de anúncio e zero receita. Enquanto isso, o tráfego do Googlebot se converte em engajamento real do usuário e oportunidades de monetização. Entender essa distinção é o primeiro passo para implementar uma estratégia de bloqueio seletivo que proteja seu conteúdo e, ao mesmo tempo, preserve sua visibilidade em buscas.
Bloquear todos os crawlers de IA indiscriminadamente é economicamente autodestrutivo para a maioria dos publishers. Enquanto crawlers de treinamento extraem valor sem compensação, crawlers de busca continuam sendo uma das fontes de tráfego mais confiáveis em um cenário digital cada vez mais fragmentado. O argumento financeiro para o bloqueio seletivo se baseia em vários fatores principais:
Publishers que implementam estratégias de bloqueio seletivo relatam manter ou até melhorar o tráfego de busca, enquanto reduzem a extração não autorizada de conteúdo em até 85%. Essa abordagem estratégica reconhece que nem todos os crawlers de IA são iguais, e que uma política sofisticada atende muito melhor aos interesses do negócio do que uma abordagem radical.
O arquivo robots.txt continua sendo o principal mecanismo de comunicação de permissões a crawlers, e pode ser surpreendentemente eficaz ao distinguir diferentes tipos de bots quando bem configurado. Esse simples arquivo de texto, colocado no diretório raiz do seu site, usa diretivas de user-agent para especificar quais crawlers podem acessar qual conteúdo. Para o controle seletivo de crawlers de IA, você pode permitir motores de busca e bloquear crawlers de treinamento com precisão cirúrgica.
Aqui está um exemplo prático que bloqueia crawlers de treinamento e permite motores de busca:
# Bloquear o GPTBot da OpenAI
User-agent: GPTBot
Disallow: /
# Bloquear o crawler Claude da Anthropic
User-agent: Claude-Web
Disallow: /
# Bloquear outros crawlers de treinamento
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
# Permitir motores de busca
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: *
Disallow: /admin/
Disallow: /private/
Essa abordagem fornece instruções claras para crawlers que seguem as regras, mantendo a descoberta do seu site nos resultados de busca. No entanto, o robots.txt é fundamentalmente um padrão voluntário—ele depende dos operadores de crawler respeitarem suas diretrizes. Para publishers preocupados com o cumprimento, camadas adicionais de aplicação são necessárias.
Somente o robots.txt não garante cumprimento, pois aproximadamente 13% dos crawlers de IA ignoram completamente suas diretrizes, seja por negligência ou por tentativa deliberada de burlar as regras. O bloqueio em nível de servidor, via servidor web ou camada de aplicação, oferece uma barreira técnica que impede acesso não autorizado independentemente do comportamento do crawler. Essa abordagem bloqueia solicitações no nível HTTP antes que consumam banda ou recursos significativos.
Implementar bloqueio em nível de servidor com Nginx é simples e muito eficaz:
# No bloco do servidor Nginx
location / {
# Bloquear crawlers de treinamento no servidor
if ($http_user_agent ~* (GPTBot|Claude-Web|CCBot|anthropic-ai|Omgili)) {
return 403;
}
# Bloquear por faixas de IP se necessário (para crawlers que falsificam user agents)
if ($remote_addr ~* "^(192\.0\.2\.|198\.51\.100\.)") {
return 403;
}
# Continua com o processamento normal da requisição
proxy_pass http://backend;
}
Essa configuração retorna um 403 Forbidden aos crawlers bloqueados, consumindo recursos mínimos do servidor e comunicando claramente que o acesso foi negado. Combinado ao robots.txt, o bloqueio em nível de servidor cria uma defesa em duas camadas que pega tanto crawlers compatíveis quanto não compatíveis. O índice de 13% de bypass cai para quase zero quando as regras do servidor estão corretamente implementadas.
Content Delivery Networks e Web Application Firewalls fornecem uma camada adicional de aplicação que atua antes das requisições chegarem ao seu servidor de origem. Serviços como Cloudflare, Akamai e AWS WAF permitem criar regras que bloqueiam user agents ou faixas de IP específicas na borda, evitando que crawlers maliciosos ou indesejados consumam os recursos da sua infraestrutura. Esses serviços mantêm listas atualizadas de faixas de IP e user agents conhecidos de crawlers de treinamento, bloqueando-os automaticamente sem necessidade de configuração manual.
Os controles em nível de CDN oferecem várias vantagens em relação ao bloqueio em servidor: reduzem a carga no servidor de origem, fornecem bloqueio geográfico e oferecem análises em tempo real sobre requisições bloqueadas. Muitos provedores de CDN já oferecem regras específicas de bloqueio de IA como padrão, reconhecendo a preocupação generalizada dos publishers com a extração não autorizada de dados para treinamento. Para quem usa Cloudflare, basta ativar a opção “Block AI Crawlers” nas configurações de segurança para obter proteção com um clique contra os principais crawlers de treinamento, mantendo o acesso dos motores de busca.
O bloqueio seletivo eficaz requer uma abordagem sistemática para classificar crawlers com base no impacto de negócio e confiabilidade. Em vez de tratar todos os crawlers de IA de forma idêntica, publishers devem implementar um framework de três camadas que reflita o valor real e o risco que cada crawler apresenta. Esse framework permite decisões refinadas que equilibram proteção de conteúdo e oportunidade de negócio.
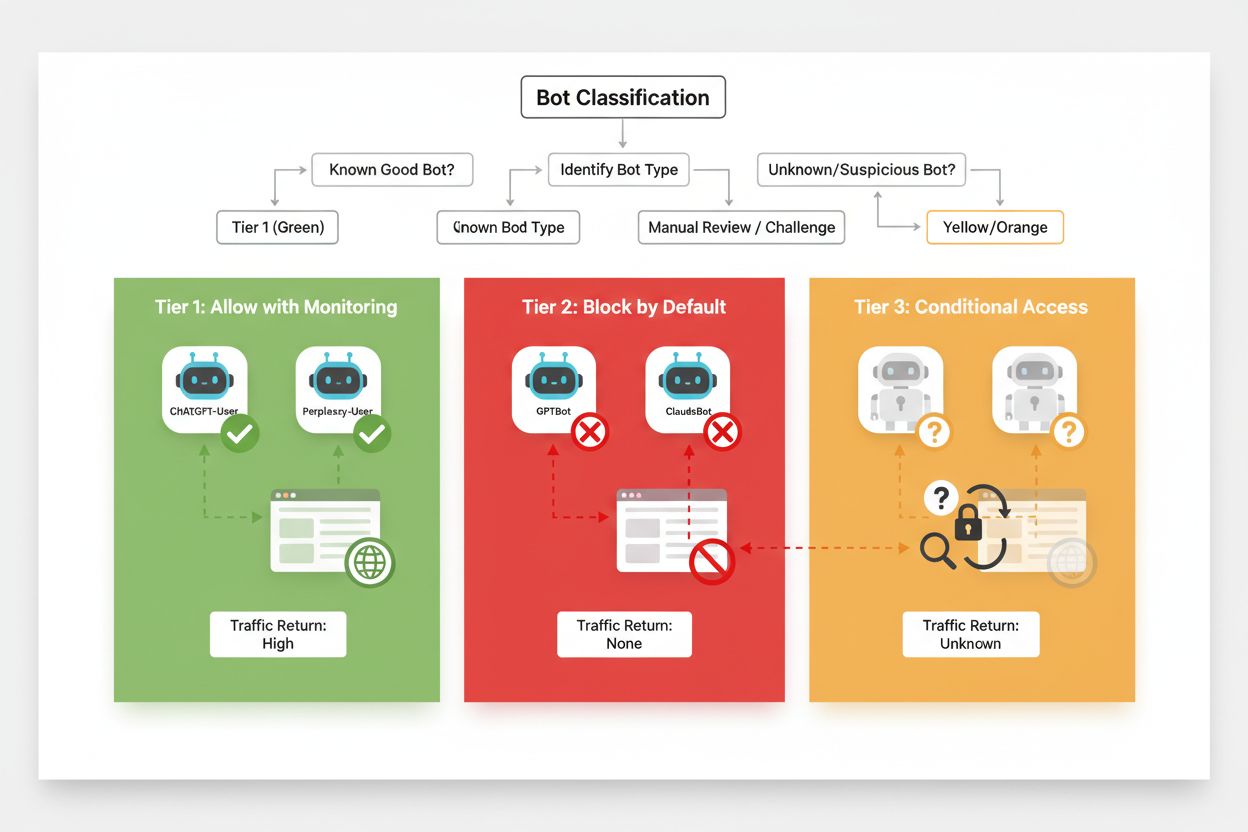
| Camada | Classificação | Exemplos | Ação |
|---|---|---|---|
| Camada 1: Geradores de Receita | Motores de busca e grandes fontes de referência | Googlebot, Bingbot, Perplexity Bot | Permitir acesso total; otimizar para rastreabilidade |
| Camada 2: Neutros/Não comprovados | Crawlers novos ou emergentes com intenção incerta | Startups de IA menores, bots de pesquisa | Monitorar de perto; permitir com limitação de taxa |
| Camada 3: Extratores de Valor | Crawlers de treinamento sem benefício direto | GPTBot, Claude-Web, CCBot | Bloquear completamente; aplicar em múltiplas camadas |
Implementar esse framework exige pesquisa contínua sobre novos crawlers e seus modelos de negócio. Os publishers devem auditar regularmente seus logs de acesso para identificar novos bots, pesquisar os termos de uso e políticas de remuneração dos operadores e ajustar as classificações conforme necessário. Um crawler que começa como Camada 3 pode subir para Camada 2 se seu operador passar a oferecer acordos de remuneração, enquanto um crawler previamente confiável pode cair para Camada 3 se começar a violar limites de taxa ou diretrizes do robots.txt.
Bloqueio seletivo não é uma configuração “defina e esqueça”—ele exige monitoramento e ajustes contínuos à medida que o ecossistema de crawlers evolui. Publishers devem implementar logging e análise abrangentes para rastrear quais crawlers estão acessando seu conteúdo, quanto de banda consomem e se estão respeitando as restrições configuradas. Esses dados embasam decisões estratégicas sobre quais crawlers permitir, bloquear ou limitar.
Analisando seus logs de acesso, você revela padrões de comportamento de crawlers que ajudam a ajustar sua política:
# Identificar todos os crawlers de IA acessando seu site
grep -i "bot\|crawler" /var/log/nginx/access.log | \
awk '{print $12}' | sort | uniq -c | sort -rn | head -20
# Calcular banda consumida por crawlers específicos
grep "GPTBot" /var/log/nginx/access.log | \
awk '{sum+=$10} END {print "GPTBot bandwidth: " sum/1024/1024 " MB"}'
# Monitorar respostas 403 para crawlers bloqueados
grep " 403 " /var/log/nginx/access.log | grep -i "bot" | wc -l
A análise regular desses dados—idealmente semanal ou mensal—revela se sua estratégia de bloqueio está funcionando conforme esperado, se novos crawlers apareceram e se algum crawler previamente bloqueado mudou seu comportamento. Essas informações alimentam seu framework de classificação, garantindo que suas políticas permaneçam alinhadas com seus objetivos de negócio e a realidade técnica.
Publishers que implementam bloqueio seletivo de crawlers frequentemente cometem erros que prejudicam a estratégia ou causam consequências indesejadas. Entender esses riscos ajuda você a evitar erros custosos e implementar uma política mais eficaz desde o início.
Bloquear todos os crawlers indiscriminadamente: O erro mais comum é usar regras de bloqueio muito amplas que acabam bloqueando motores de busca junto com crawlers de treinamento, destruindo a visibilidade em buscas ao tentar proteger o conteúdo.
Confiar apenas no robots.txt: Assumir que apenas o robots.txt impedirá o acesso não autorizado ignora os 13% dos crawlers que o ignoram completamente, deixando seu conteúdo vulnerável à extração determinada.
Não monitorar nem ajustar: Implementar uma política estática de bloqueio e nunca revisá-la significa perder novos crawlers, não se adaptar a mudanças no modelo de negócio e possivelmente bloquear crawlers benéficos que melhoraram suas práticas.
Bloquear apenas por user agent: Crawlers sofisticados falsificam ou rotacionam seus user agents frequentemente, tornando o bloqueio baseado apenas em user agent ineficaz sem regras complementares por IP e limitação de taxa.
Ignorar limitação de taxa: Mesmo crawlers permitidos podem consumir banda excessiva se não forem limitados, degradando a performance para usuários humanos e consumindo recursos de infraestrutura desnecessariamente.
O futuro da relação entre publishers e crawlers de IA provavelmente envolverá negociações e modelos de compensação mais sofisticados, em vez de bloqueios simples. No entanto, até que padrões de mercado surjam, o controle seletivo de crawlers continua sendo a abordagem mais prática para proteger conteúdo mantendo a visibilidade em buscas. Publishers devem tratar sua estratégia de bloqueio como uma política dinâmica que evolui junto ao ecossistema de crawlers, reavaliando regularmente quais crawlers merecem acesso com base no impacto de negócio e na confiabilidade.
Os publishers mais bem-sucedidos serão aqueles que implementam defesas em camadas—combinando diretivas no robots.txt, aplicação em nível de servidor, controles em CDN e monitoramento contínuo em uma estratégia abrangente. Essa abordagem protege contra crawlers tanto compatíveis quanto não compatíveis, ao mesmo tempo em que preserva o tráfego dos motores de busca que gera receita e engajamento. À medida que empresas de IA reconhecem o valor do conteúdo de publishers e passam a oferecer remuneração ou acordos de licenciamento, o framework que você constrói hoje se adapta facilmente para acomodar novos modelos de negócio, mantendo o controle sobre seus ativos digitais.
Crawlers de treinamento como GPTBot e ClaudeBot coletam dados para construir modelos de IA sem retornar tráfego ao seu site. Crawlers de busca como OAI-SearchBot e PerplexityBot indexam conteúdo para mecanismos de busca de IA e podem gerar tráfego de referência significativo para seu site. Entender essa distinção é crucial para implementar uma estratégia eficaz de bloqueio seletivo.
Sim, essa é a estratégia central do controle seletivo de crawlers. Você pode usar o robots.txt para desautorizar bots de treinamento enquanto permite bots de busca, e então reforçar com controles no servidor para bots que ignoram o robots.txt. Essa abordagem protege seu conteúdo de treinamentos não autorizados e mantém a visibilidade nos resultados de busca por IA.
A maioria das grandes empresas de IA afirma respeitar o robots.txt, mas o cumprimento é voluntário. Pesquisas mostram que aproximadamente 13% dos bots de IA ignoram totalmente as diretrizes do robots.txt. Por isso, a aplicação em nível de servidor é essencial para publishers que desejam proteger seu conteúdo de crawlers não compatíveis.
Significativo e crescente. O ChatGPT enviou 243,8 milhões de visitas para 250 sites de notícias e mídia em abril de 2025, um aumento de 98% em relação a janeiro. Bloquear esses crawlers significa perder essa fonte emergente de tráfego. Para muitos publishers, o tráfego de busca por IA já representa de 5 a 15% do total de visitas de referência.
Analise regularmente os logs do seu servidor usando comandos grep para identificar user agents de bots, rastrear a frequência de crawls e monitorar o cumprimento das regras do seu robots.txt. Revise os logs ao menos mensalmente para identificar novos bots, padrões de comportamento incomuns e se os bots bloqueados realmente estão fora. Esses dados embasam decisões estratégicas sobre sua política de crawlers.
Você protege seu conteúdo de treinamentos não autorizados, mas perde visibilidade nos resultados de busca por IA, deixa de aproveitar fontes emergentes de tráfego e pode reduzir menções à sua marca em respostas geradas por IA. Publishers que implementam bloqueios gerais frequentemente veem reduções de 40-60% na visibilidade de busca e perdem oportunidades de descoberta de marca por meio de plataformas de IA.
Ao menos mensalmente, pois novos bots surgem constantemente e bots existentes evoluem seu comportamento. O cenário dos crawlers de IA muda rapidamente, com novos operadores lançando crawlers e players existentes fundindo ou renomeando seus bots. Revisões regulares garantem que sua política permaneça alinhada com os objetivos de negócio e a realidade técnica.
É o número de páginas rastreadas em relação aos visitantes enviados de volta ao seu site. A Anthropic rastreia 38.000 páginas para cada visitante referido, enquanto a OpenAI mantém uma razão de 1.091:1 e a Perplexity fica em 194:1. Razões menores indicam melhor valor em permitir o crawler. Essa métrica ajuda você a decidir quais crawlers merecem acesso com base no seu real impacto de negócio.
O AmICited rastreia quais plataformas de IA citam sua marca e conteúdo. Obtenha insights sobre sua visibilidade em IA e garanta a devida atribuição no ChatGPT, Perplexity, Google AI Overviews e mais.
Saiba como Firewalls de Aplicação Web oferecem controle avançado sobre crawlers de IA além do robots.txt. Implemente regras WAF para proteger seu conteúdo contr...

Guia completo de referência sobre crawlers e bots de IA. Identifique GPTBot, ClaudeBot, Google-Extended e mais de 20 outros crawlers de IA com user agents, taxa...

Aprenda como tomar decisões estratégicas sobre o bloqueio de crawlers de IA. Avalie tipo de conteúdo, fontes de tráfego, modelos de receita e posição competitiv...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.