
Como Identificar Rastreadores de IA nos Seus Logs de Servidor
Aprenda a identificar e monitorar rastreadores de IA como GPTBot, ClaudeBot e PerplexityBot nos seus logs de servidor. Guia completo com strings de user-agent, ...
10 min de leitura

Aprenda como bloquear ou permitir rastreadores de IA como GPTBot e ClaudeBot usando robots.txt, bloqueio a nível de servidor e métodos avançados de proteção. Guia técnico completo com exemplos.
O cenário digital mudou fundamentalmente do tradicional SEO para a gestão de uma nova categoria de visitantes automatizados: rastreadores de IA. Ao contrário dos bots de busca convencionais, que direcionam tráfego de volta ao seu site pelos resultados de busca, rastreadores de treinamento de IA consomem seu conteúdo para construir grandes modelos de linguagem sem necessariamente enviar tráfego de referência em troca. Essa diferença tem implicações profundas para publishers, criadores de conteúdo e empresas que dependem do tráfego web como fonte de receita. Os riscos são altos—controlar quais sistemas de IA acessam seu conteúdo impacta diretamente sua vantagem competitiva, privacidade de dados e resultados financeiros.
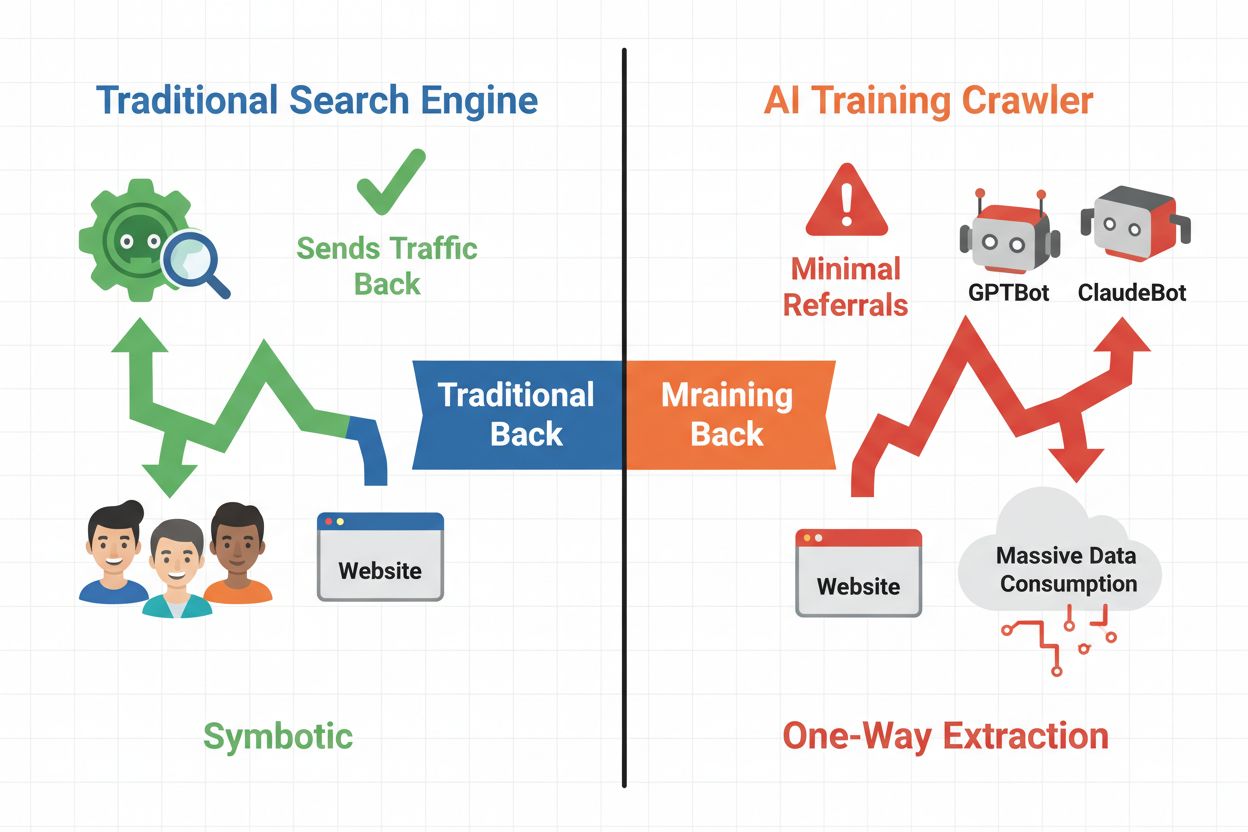
Os rastreadores de IA se dividem em três categorias distintas, cada uma com propósitos e impacto de tráfego diferentes. Rastreadores de treinamento são usados por empresas de IA para construir e aprimorar seus modelos de linguagem, geralmente operando em larga escala com retorno mínimo de tráfego. Rastreadores de busca e citação indexam conteúdo para mecanismos de busca e sistemas de citação baseados em IA, frequentemente gerando algum tráfego de referência para os publishers. Rastreadores acionados por usuário buscam conteúdo sob demanda quando usuários interagem com aplicações de IA, representando um segmento menor, porém crescente. Compreender essas categorias ajuda você a tomar decisões informadas sobre quais rastreadores permitir ou bloquear de acordo com seu modelo de negócio.
| Tipo de Rastreador | Propósito | Impacto de Tráfego | Exemplos |
|---|---|---|---|
| Treinamento | Construir/aprimorar LLMs | Mínimo ou nenhum | GPTBot, ClaudeBot, Bytespider |
| Busca/Citação | Indexar para busca/citação em IA | Tráfego de referência moderado | Googlebot-Extended, Perplexity |
| Acionado por usuário | Buscar sob demanda para usuários | Baixo, porém constante | Plugins ChatGPT, Navegação Claude |
O ecossistema de rastreadores de IA inclui bots das maiores empresas de tecnologia do mundo, cada um com user agents e propósitos distintos. O GPTBot da OpenAI (user agent: GPTBot/1.0) rastreia para treinar o ChatGPT e outros modelos, enquanto o ClaudeBot da Anthropic (user agent: Claude-Web/1.0) atua de forma similar para o Claude. O Googlebot-Extended do Google (user agent: Mozilla/5.0 ... Googlebot-Extended) indexa conteúdo para AI Overviews e Bard, enquanto o Meta-ExternalFetcher da Meta rastreia para suas iniciativas de IA. Outros grandes players incluem:
Cada rastreador opera em escalas diferentes e respeita as diretivas de bloqueio em graus variados de conformidade.
O robots.txt é sua primeira linha de defesa para controlar o acesso de rastreadores de IA, mas é importante saber que ele é apenas uma orientação, não uma exigência legal. Localizado na raiz do seu domínio (ex: seusite.com/robots.txt), esse arquivo usa uma sintaxe simples para instruir quais áreas os rastreadores devem evitar. Para bloquear todos os rastreadores de IA, adicione as seguintes regras:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Googlebot-Extended
Disallow: /
User-agent: Meta-ExternalFetcher
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
Se você preferir bloquear seletivamente—permitindo rastreadores de busca e bloqueando apenas de treinamento—use este modelo:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Googlebot-Extended
Disallow: /news/
Allow: /
Um erro comum é usar regras muito amplas, como Disallow: *, que podem confundir os interpretadores, ou esquecer de especificar os rastreadores individualmente quando só deseja bloquear alguns. Grandes empresas como OpenAI, Anthropic e Google geralmente respeitam as diretivas do robots.txt, embora rastreadores como o Perplexity sejam conhecidos por ignorar essas regras.
Quando o robots.txt não é suficiente, há métodos mais robustos para controlar o acesso de rastreadores de IA. O bloqueio por IP exige identificar os intervalos de IP dos rastreadores e bloqueá-los no firewall ou servidor—a medida é eficaz, mas requer manutenção constante, pois os IPs mudam. Bloqueio a nível de servidor por arquivos .htaccess (Apache) ou configurações Nginx oferece mais controle e é mais difícil de contornar do que o robots.txt. Para servidores Apache, implemente esta regra:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|Claude-Web|Bytespider|Amazonbot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule>
Bloqueio por meta tag usando <meta name="robots" content="noindex, noimageindex, nofollowbydefault"> previne indexação, mas não impede rastreadores de treinamento. Verificação de cabeçalhos de requisição checa se os rastreadores são legítimos, verificando DNS reverso e certificados SSL. Use bloqueio a nível de servidor quando precisar de certeza absoluta de que rastreadores não acessarão seu conteúdo, e combine métodos para proteção máxima.
Decidir bloquear rastreadores de IA exige pesar interesses conflitantes. Bloquear rastreadores de treinamento (GPTBot, ClaudeBot, Bytespider) impede que seu conteúdo seja usado para treinar modelos de IA, protegendo sua propriedade intelectual e vantagem competitiva. Já permitir rastreadores de busca (Googlebot-Extended, Perplexity) pode trazer tráfego de referência e aumentar a visibilidade em resultados de busca com IA—um canal de descoberta crescente. O dilema se aprofunda considerando que algumas empresas de IA têm baixíssima relação crawl/referral: os rastreadores da Anthropic geram cerca de 38.000 requisições para cada referência, enquanto o da OpenAI chega a 400:1. Carga do servidor e banda também entram na conta—rastreadores de IA consomem muitos recursos, e bloqueá-los pode reduzir custos de infraestrutura. Sua decisão deve estar alinhada ao seu modelo de negócio: organizações de notícias e publishers podem se beneficiar do tráfego de referência; empresas SaaS e criadores de conteúdo proprietário geralmente preferem bloquear.
Implementar bloqueios é só metade do trabalho—é preciso verificar se os rastreadores realmente respeitam suas diretivas. Análise de logs do servidor é sua principal ferramenta de verificação; examine os logs de acesso em busca de user agents e IPs de rastreadores tentando acessar seu site após o bloqueio. Use grep para pesquisar nos logs:
grep -i "gptbot\|claude-web\|bytespider" /var/log/apache2/access.log | wc -l
Este comando conta quantas vezes esses rastreadores acessaram seu site. Ferramentas de teste como o curl podem simular requisições de rastreadores e validar se suas regras de bloqueio funcionam:
curl -A "GPTBot/1.0" https://seusite.com/robots.txt
Monitore seus logs semanalmente no primeiro mês após implementar os bloqueios, depois trimestralmente. Se notar rastreadores ignorando o robots.txt, suba para bloqueios a nível de servidor ou entre em contato com a equipe de abuso do operador do rastreador.
O cenário de rastreadores de IA evolui rapidamente, com novas empresas lançando produtos e rastreadores existentes mudando user agents e intervalos de IP. Revisões trimestrais da sua lista de bloqueios garantem que você não está deixando passar novos rastreadores ou bloqueando tráfego legítimo por engano. O ecossistema é fragmentado e descentralizado, tornando impossível criar uma lista de bloqueios permanente. Monitore estes recursos para atualizações:
Programe lembretes para revisar seu robots.txt e regras de servidor a cada 90 dias e assine listas de e-mails de segurança que acompanham novos rastreadores.
Enquanto bloquear rastreadores de IA impede o acesso ao seu conteúdo, o AmICited resolve o desafio complementar: monitorar se sistemas de IA estão citando e referenciando sua marca e conteúdo em suas respostas. O AmICited rastreia menções da sua organização em respostas geradas por IA, dando visibilidade sobre como seu conteúdo influencia modelos e onde sua marca aparece nos resultados de IA. Isso cria uma estratégia de IA completa: você controla o que os rastreadores podem acessar via robots.txt e bloqueios de servidor, enquanto o AmICited garante que você compreenda o impacto downstream do seu conteúdo nos sistemas de IA. Juntos, esses recursos proporcionam visibilidade e controle total sobre sua presença no ecossistema de IA—do bloqueio do uso indesejado como dado de treinamento à mensuração das citações e referências geradas por seu conteúdo nas plataformas de IA.
Não. Bloquear rastreadores de treinamento de IA como GPTBot, ClaudeBot e Bytespider não afeta seu ranqueamento no Google ou Bing. Motores de busca tradicionais usam rastreadores diferentes (Googlebot, Bingbot) que operam de forma independente. Só bloqueie esses se quiser desaparecer completamente dos resultados de busca.
Os principais rastreadores da OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) e Perplexity (PerplexityBot) declaram oficialmente que respeitam as diretivas do robots.txt. No entanto, bots menores ou menos transparentes podem ignorar sua configuração, por isso existem estratégias de proteção em camadas.
Depende da sua estratégia. Bloquear apenas rastreadores de treinamento (GPTBot, ClaudeBot, Bytespider) protege seu conteúdo contra uso em treinamento de modelos, enquanto permite que rastreadores focados em busca ajudem você a aparecer nos resultados de busca em IA. O bloqueio completo remove você dos ecossistemas de IA.
Revise sua configuração pelo menos a cada trimestre. Empresas de IA regularmente lançam novos rastreadores. A Anthropic unificou seus bots 'anthropic-ai' e 'Claude-Web' em 'ClaudeBot', dando ao novo bot acesso irrestrito temporário a sites que não atualizaram suas regras.
Bloquear impede que rastreadores acessem totalmente seu conteúdo, protegendo-o de coleta para treinamento ou indexação. Permitir rastreadores dá acesso, mas pode resultar no uso do seu conteúdo para treinamento de modelos ou exibição em resultados de IA com pouco tráfego de referência.
Sim, o robots.txt é uma orientação e não uma exigência legal. Rastreadores bem-comportados das grandes empresas geralmente respeitam as diretivas do robots.txt, mas alguns rastreadores as ignoram. Para uma proteção mais forte, implemente bloqueio a nível de servidor via .htaccess ou regras de firewall.
Verifique os logs do seu servidor em busca das cadeias de agentes de usuário dos rastreadores bloqueados. Se você notar requisições de rastreadores que bloqueou, eles podem não estar respeitando o robots.txt. Use ferramentas de teste como o verificador de robots.txt do Google Search Console ou comandos curl para conferir sua configuração.
O bloqueio de rastreadores de treinamento geralmente tem impacto direto mínimo, pois eles quase não enviam tráfego de referência. Porém, bloquear rastreadores de busca pode reduzir a visibilidade em plataformas de descoberta baseadas em IA. Monitore suas análises por 30 dias após implementar bloqueios para medir o impacto real.
Embora você controle o acesso de rastreadores com o robots.txt, o AmICited ajuda a acompanhar como sistemas de IA citam e referenciam seu conteúdo em suas respostas. Tenha visibilidade completa sobre sua presença em IA.
Aprenda a identificar e monitorar rastreadores de IA como GPTBot, ClaudeBot e PerplexityBot nos seus logs de servidor. Guia completo com strings de user-agent, ...

Aprenda estratégias comprovadas para aumentar a frequência com que rastreadores de IA visitam seu site, melhorando a descoberta de conteúdo no ChatGPT, Perplexi...
Aprenda como rastreadores de IA priorizam páginas usando capacidade e demanda de rastreamento. Entenda a otimização do orçamento de rastreamento para ChatGPT, P...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.