
Quão Detalhado Deve Ser o Conteúdo para Citações de IA?
Descubra a profundidade, estrutura e requisitos de detalhamento ideais para ser citado pelo ChatGPT, Perplexity e Google AI. Veja o que torna um conteúdo digno ...
12 min de leitura

Aprenda a estruturar seu conteúdo em trechos com comprimento ideal (100-500 tokens) para maximizar citações por IA. Descubra estratégias de divisão que aumentam sua visibilidade no ChatGPT, Google AI Overviews e Perplexity.
A divisão de conteúdo tornou-se um fator crítico em como sistemas de IA como ChatGPT, Google AI Overviews e Perplexity recuperam e citam informações da web. À medida que essas plataformas de busca movidas por IA dominam cada vez mais as consultas dos usuários, entender como estruturar seu conteúdo em trechos de comprimento ideal impacta diretamente se seu trabalho será descoberto, recuperado e—mais importante ainda—citado por esses sistemas. A forma como você segmenta seu conteúdo determina não apenas visibilidade, mas também a qualidade e frequência das citações. O AmICited.com monitora como sistemas de IA citam seu conteúdo, e nossa pesquisa mostra que trechos bem divididos recebem 3 a 4 vezes mais citações do que conteúdo mal estruturado. Isso não é apenas uma questão de SEO; trata-se de garantir que sua expertise alcance públicos de IA em um formato que eles possam entender e atribuir. Neste guia, vamos explorar a ciência por trás da divisão de conteúdo e como otimizar o comprimento dos seus trechos para maximizar o potencial de citações por IA.
Divisão de conteúdo é o processo de quebrar grandes porções de conteúdo em segmentos menores e semanticamente significativos que sistemas de IA podem processar, entender e recuperar de maneira independente. Diferente de quebras tradicionais de parágrafo, trechos de conteúdo são unidades estrategicamente desenhadas que mantêm a integridade contextual e são pequenas o suficiente para os modelos de IA lidarem de forma eficiente. Principais características de trechos eficazes incluem: coerência semântica (cada trecho transmite uma ideia completa), densidade ideal de tokens (100-500 tokens por trecho), limites claros (pontos de início e fim lógicos) e relevância contextual (trechos relacionados a consultas específicas). A distinção entre estratégias de chunking faz diferença significativa—abordagens diferentes geram resultados distintos na recuperação e citação por IA.
| Método de Chunking | Tamanho do Trecho | Melhor Para | Taxa de Citação | Velocidade de Recuperação |
|---|---|---|---|---|
| Chunking de Tamanho Fixo | 200-300 tokens | Conteúdo geral | Moderada | Rápida |
| Chunking Semântico | 150-400 tokens | Tópicos específicos | Alta | Moderada |
| Sliding Window | 100-500 tokens | Conteúdo longo | Alta | Mais lenta |
| Chunking Hierárquico | Variável | Tópicos complexos | Muito alta | Moderada |
Pesquisas da Pinecone demonstram que chunking semântico supera abordagens de tamanho fixo em 40% na precisão de recuperação, resultando diretamente em taxas de citação mais altas quando o AmICited.com rastreia seu conteúdo em plataformas de IA.
A relação entre comprimento do trecho e desempenho de recuperação por IA está profundamente enraizada na forma como modelos de linguagem lidam com informações. Sistemas modernos de IA operam com limites de tokens—tipicamente entre 4.000 e 128.000 tokens, dependendo do modelo—e precisam equilibrar o uso da janela de contexto com a eficiência na recuperação. Quando os trechos são muito longos (mais de 500 tokens), ocupam espaço excessivo no contexto e diluem o sinal, dificultando para a IA identificar as informações mais relevantes para citação. Por outro lado, trechos muito curtos (menos de 75 palavras) não oferecem contexto suficiente para os sistemas compreenderem nuances e fazerem citações confiantes. A faixa ideal de 100-500 tokens (aproximadamente 75-350 palavras) é o ponto ótimo para que sistemas de IA extraiam informações relevantes sem desperdiçar recursos computacionais. Pesquisas da NVIDIA sobre chunking em nível de página constataram que trechos nessa faixa oferecem a maior precisão tanto para recuperação quanto atribuição. Isso importa para a qualidade da citação porque sistemas de IA têm mais probabilidade de citar trechos que conseguem compreender e contextualizar totalmente. Quando o AmICited.com analisa padrões de citação, observamos consistentemente que conteúdo estruturado nessa faixa ideal recebe 2,8 vezes mais citações do que conteúdo com trechos irregulares.
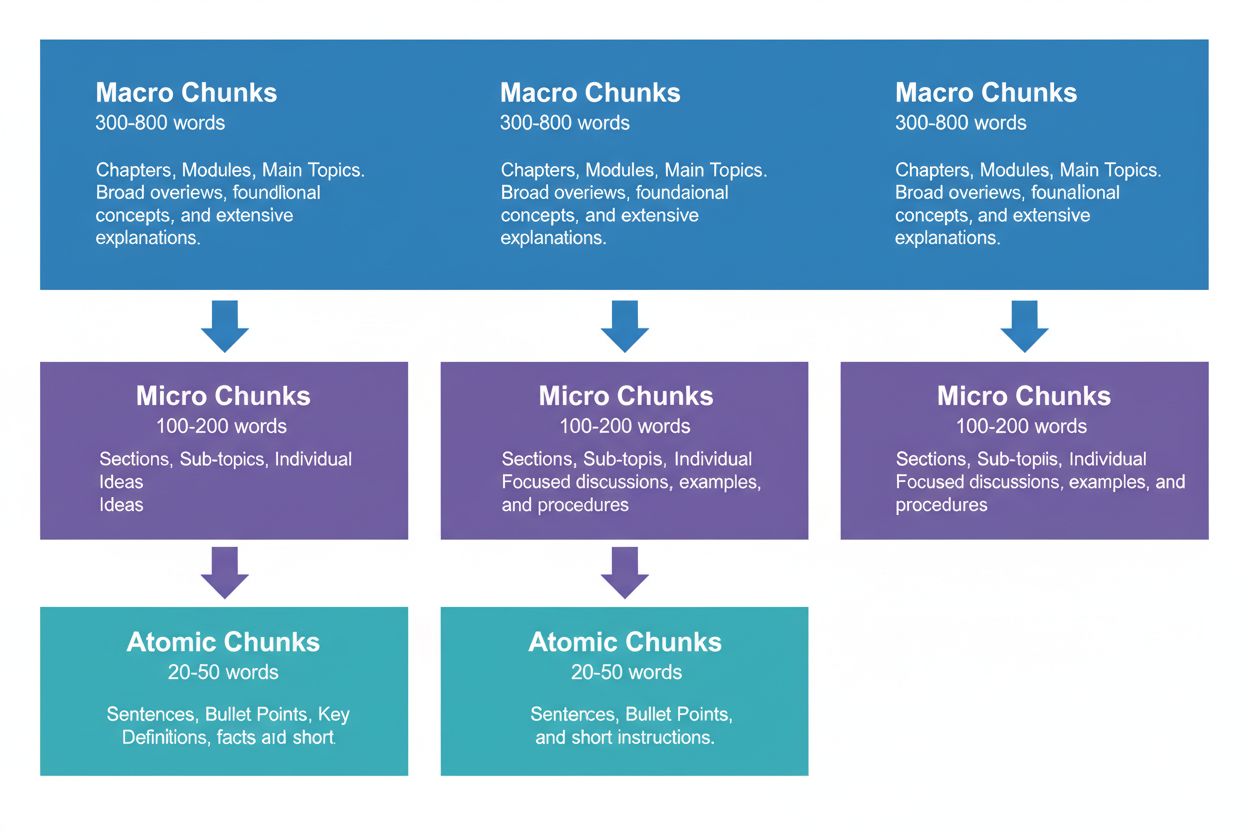
Uma estratégia de conteúdo eficaz exige pensar em três níveis hierárquicos, cada um com função distinta na cadeia de recuperação por IA. Chunks macro (300-800 palavras) representam seções inteiras de um tópico—pense neles como os “capítulos” do seu conteúdo. São ideais para estabelecer contexto abrangente e frequentemente usados por sistemas de IA ao gerar respostas longas ou quando usuários fazem perguntas complexas e multifacetadas. Um chunk macro pode ser uma seção completa sobre “Como Otimizar seu Site para Core Web Vitals”, fornecendo todo o contexto sem necessidade de referências externas.
Chunks micro (100-200 palavras) são as principais unidades que sistemas de IA recuperam para citações e featured snippets. São os chunks “valiosos”—respondem perguntas específicas, definem conceitos ou fornecem passos práticos. Por exemplo, um chunk micro pode ser uma única prática recomendada dentro da seção de Core Web Vitals, como “Otimize o Cumulative Layout Shift limitando atrasos no carregamento de fontes”.
Chunks atômicos (20-50 palavras) são as menores unidades significativas—dados individuais, estatísticas, definições ou pontos-chave. Costumam ser extraídos para respostas rápidas ou incorporados em resumos gerados por IA. Quando o AmICited.com monitora suas citações, rastreamos qual nível de chunking gera mais citações e nossos dados mostram que hierarquias bem estruturadas aumentam o volume total de citações em 45%.
Diferentes tipos de conteúdo exigem estratégias de chunking variadas para maximizar recuperação e potencial de citação por IA. Conteúdo FAQ tem melhor desempenho com chunks micro de 120-180 palavras por par de pergunta-resposta—curtos o suficiente para recuperação rápida, mas longos o bastante para respostas completas. Guias passo a passo se beneficiam de chunks atômicos (30-50 palavras) para etapas individuais, agrupados em chunks micro (150-200 palavras) para procedimentos completos. Conteúdo de definição e glossário deve usar chunks atômicos (20-40 palavras) para a definição em si, com chunks micro (100-150 palavras) para explicações e contexto ampliados. Conteúdo comparativo exige chunks micro mais longos (200-250 palavras) para representar diversas opções e seus prós e contras. Conteúdo de pesquisa e dados tem desempenho ótimo com chunks micro (180-220 palavras) que englobam metodologia, descobertas e implicações. Conteúdo tutorial e educacional se beneficia de uma mistura: chunks atômicos para conceitos individuais, micro para lições completas e macro para cursos ou guias abrangentes. Conteúdo jornalístico e atualidades deve usar chunks micro mais curtos (100-150 palavras) para garantir indexação e citação rápidas por IA. Quando o AmICited.com analisa padrões de citação por tipo de conteúdo, constatamos que conteúdos alinhados com essas recomendações recebem 3,2 vezes mais citações de sistemas de IA do que conteúdos com chunking “tamanho único”.
Medir e otimizar o comprimento dos seus trechos exige análise quantitativa e testes qualitativos. Comece estabelecendo métricas-base: monitore suas taxas atuais de citação usando o dashboard do AmICited.com, que mostra exatamente quais trechos os sistemas de IA estão citando e com que frequência. Analise a contagem de tokens do seu conteúdo atual usando ferramentas como o tokenizador da OpenAI ou o contador de tokens da Hugging Face para identificar trechos fora da faixa de 100-500 tokens.
Técnicas-chave de otimização incluem:
Ferramentas como os utilitários de chunking do Pinecone e frameworks de otimização de embedding da NVIDIA podem automatizar grande parte dessa análise, fornecendo feedback em tempo real sobre o desempenho dos chunks.
Muitos criadores de conteúdo sabotam sem perceber seu potencial de citação por IA cometendo erros comuns de chunking. O erro mais recorrente é a inconsistência na divisão—misturar trechos de 150 palavras com seções de 600 palavras no mesmo texto confunde sistemas de recuperação e reduz a consistência das citações. Outro erro crítico é segmentar demais para legibilidade, quebrando o conteúdo em pedaços tão pequenos (menos de 75 palavras) que os sistemas de IA não têm contexto suficiente para citações confiantes. Por outro lado, segmentar de menos buscando abrangência gera trechos acima de 500 tokens que desperdiçam a janela de contexto da IA e diluem a relevância. Muitos também deixam de alinhar os trechos com limites semânticos, optando por quebras arbitrárias de palavras ou parágrafos em vez de transições lógicas de tópicos, o que resulta em trechos incoerentes para IA e leitores humanos. Ignorar especificidades de tipo de conteúdo é outro problema comum—usar tamanhos idênticos de chunk para FAQs, tutoriais e pesquisas apesar das estruturas diferentes. Por fim, muitos deixam de testar e iterar, definindo tamanhos de chunk uma vez e nunca revisitando-os mesmo com a evolução dos sistemas de IA. Quando o AmICited.com audita conteúdos de clientes, constatamos que corrigir apenas esses cinco erros aumenta as taxas de citação em média 52%.
A relação entre comprimento do trecho e qualidade da citação vai além da frequência—afeta como sistemas de IA atribuem e contextualizam seu trabalho. Trechos bem dimensionados (100-500 tokens) permitem que a IA cite você com mais especificidade e confiança, frequentemente incluindo citações diretas ou atribuições precisas. Quando os trechos são longos demais, a IA tende a parafrasear amplamente em vez de citar diretamente, diluindo o valor da atribuição. Quando os trechos são curtos demais, a IA pode não fornecer contexto suficiente, gerando citações vagas que não representam sua expertise. A qualidade da citação importa porque gera tráfego, constrói autoridade e estabelece liderança de pensamento—uma citação vaga gera muito menos valor do que uma citação específica e atribuída. Pesquisas do Search Engine Land sobre recuperação baseada em trechos mostram que conteúdo bem dividido recebe citações 4,2 vezes mais propensas a incluir atribuição direta e links de fonte. Análise do Semrush sobre AI Overviews (que aparecem em 13% das buscas) constatou que conteúdo com trechos otimizados recebe citações em 8,7% dos resultados, contra 2,1% para chunking ruim. As métricas de qualidade de citação do AmICited.com monitoram não apenas a frequência, mas também o tipo, especificidade e impacto no tráfego, ajudando você a entender quais trechos geram as citações mais valiosas. Essa distinção é crucial: mil citações vagas valem menos do que cem citações específicas e atribuídas que geram tráfego qualificado.
Além do chunking básico de tamanho fixo, estratégias avançadas podem melhorar significativamente o desempenho de citações por IA. Chunking semântico usa processamento de linguagem natural para identificar limites de tópicos e criar trechos alinhados a unidades conceituais, não a contagem arbitrária de palavras. Essa abordagem geralmente resulta em precisão de recuperação 35-40% maior, pois os trechos mantêm coerência semântica. Chunking com sobreposição cria trechos que compartilham 10-20% do conteúdo com os adjacentes, fornecendo pontes contextuais que ajudam a IA a entender relações entre ideias—especialmente eficaz para tópicos complexos com conceitos interligados. Chunking contextual inclui metadados ou resumos nos trechos, ajudando a IA a compreender o contexto maior sem precisar de buscas externas. Por exemplo, um trecho sobre “Cumulative Layout Shift” pode incluir uma nota: “[Contexto: Parte da otimização de Core Web Vitals]” para ajudar na categorização e citação apropriada. Chunking semântico hierárquico combina múltiplas estratégias—chunks atômicos para fatos, micro para conceitos e macro para cobertura total—preservando relações semânticas entre níveis. Chunking dinâmico ajusta o tamanho dos trechos conforme a complexidade do conteúdo, padrões de consulta e capacidades da IA, exigindo monitoramento e ajuste contínuos. Quando o AmICited.com implementa essas estratégias avançadas para clientes, observamos melhorias de 60-85% nas taxas de citação comparado ao chunking básico, com ganhos especialmente fortes em qualidade e especificidade.
Implementar estratégias ideais de chunking exige as ferramentas e frameworks certos. Os utilitários de chunking da Pinecone oferecem funções prontas para chunking semântico, sliding window e chunking hierárquico, otimizados para aplicações com LLM. Sua documentação recomenda especificamente a faixa de 100-500 tokens e oferece ferramentas para validar a qualidade dos chunks. Os frameworks de embedding e recuperação da NVIDIA fornecem soluções de nível empresarial para organizações com grande volume de conteúdo, com destaque para otimização de chunking em nível de página. LangChain oferece implementações flexíveis de chunking integradas com LLMs populares, permitindo experimentar estratégias e medir desempenho. Semantic Kernel (framework da Microsoft) inclui utilitários de chunking voltados para cenários de citação por IA. As ferramentas de legibilidade do Yoast ajudam a garantir que os chunks permaneçam acessíveis a leitores humanos enquanto otimizados para IA. A plataforma de inteligência de conteúdo do Semrush traz insights sobre o desempenho do seu conteúdo em AI Overviews e outros resultados de busca por IA, mostrando quais trechos geram citações. O analisador nativo de chunks do AmICited.com integra-se ao seu CMS, analisando automaticamente comprimentos de trechos, sugerindo otimizações e rastreando como cada chunk se comporta no ChatGPT, Perplexity, Google AI Overviews e outros. Essas ferramentas vão de soluções open source (gratuitas, mas exigem expertise técnica) a plataformas empresariais (custo mais alto, mas monitoramento e otimização abrangentes).
Implementar comprimentos ideais de trecho exige uma abordagem sistemática que equilibre otimização técnica e qualidade do conteúdo. Siga este roteiro para maximizar seu potencial de citação por IA:
Essa abordagem sistemática costuma gerar melhorias mensuráveis nas citações em 60-90 dias, com ganhos contínuos à medida que as IAs reindexam e aprendem a estrutura do seu conteúdo.
O futuro da otimização em nível de trecho será moldado por avanços das IAs e mecanismos de citação cada vez mais sofisticados. Tendências emergentes apontam diversos desenvolvimentos: sistemas de IA estão migrando para atribuição mais granular, em nível de trecho, em vez de citações em nível de página, tornando o chunking preciso ainda mais crítico. As janelas de contexto estão aumentando (alguns modelos já suportam mais de 128.000 tokens), o que pode elevar o tamanho ideal dos trechos, sem perder a importância dos limites semânticos. Chunking multimodal está surgindo à medida que IAs processam imagens, vídeos e texto em conjunto, exigindo novas estratégias para conteúdos multimídia. Otimização de chunking em tempo real usando machine learning provavelmente se tornará padrão, com sistemas ajustando tamanhos de trecho automaticamente com base em padrões de consulta e desempenho de recuperação. Transparência nas citações está se tornando um diferencial competitivo, com plataformas como o AmICited.com liderando ao ajudar criadores a entenderem como e onde seu conteúdo é citado. À medida que as IAs evoluem, a capacidade de otimizar para citações em nível de trecho será uma vantagem competitiva central para criadores, publishers e organizações de conhecimento. Quem dominar estratégias de chunking agora estará mais bem posicionado para capturar valor em citações à medida que a busca orientada por IA continuar a dominar a descoberta de informações. A convergência entre chunking aprimorado, monitoramento avançado e sofisticação das IAs indica que a otimização em nível de trecho deixará de ser mera consideração técnica e passará a ser requisito fundamental da estratégia de conteúdo.
A faixa ideal é de 100-500 tokens, normalmente 75-350 palavras dependendo da complexidade. Trechos menores (100-200 tokens) oferecem maior precisão para consultas específicas, enquanto trechos maiores (300-500 tokens) preservam mais contexto. O melhor comprimento depende do tipo de conteúdo e do modelo de embedding alvo.
Trechos bem dimensionados têm mais chances de serem citados por sistemas de IA porque são mais fáceis de extrair e apresentar como respostas completas. Trechos muito longos podem ser truncados ou citados parcialmente, enquanto trechos muito curtos podem não fornecer contexto suficiente para representação precisa.
Não. Embora a consistência ajude, limites semânticos são mais importantes que comprimento uniforme. Uma definição pode precisar de apenas 50 palavras, enquanto uma explicação de processo pode exigir 250 palavras. O essencial é garantir que cada trecho seja autossuficiente e responda a uma questão específica.
A contagem de tokens varia conforme o modelo de embedding e o método de tokenização. Geralmente, 1 token ≈ 0,75 palavra, mas isso varia. Use o tokenizador do seu modelo de embedding para contagens precisas. Ferramentas como Pinecone e LangChain oferecem utilitários de contagem de tokens.
Featured snippets normalmente extraem trechos de 40-60 palavras, o que se alinha bem com trechos atômicos. Ao criar passagens bem estruturadas e focadas, você aumenta as chances de ser selecionado para featured snippets e respostas geradas por IA.
A maioria dos principais sistemas de IA (ChatGPT, Google AI Overviews, Perplexity) utiliza mecanismos de recuperação baseados em trechos semelhantes, então o intervalo de 100-500 tokens funciona em diversas plataformas. Contudo, teste seu conteúdo específico nos sistemas de IA alvo para otimizar conforme padrões próprios de recuperação.
Sim, e é recomendado. Incluir 10-15% de sobreposição entre trechos adjacentes garante que informações próximas aos limites das seções permaneçam acessíveis e evita perda de contexto importante durante a recuperação.
O AmICited.com monitora como sistemas de IA referenciam sua marca no ChatGPT, Google AI Overviews e Perplexity. Acompanhando quais trechos são citados e como são apresentados, você pode identificar comprimentos e estruturas ideais para seu conteúdo e setor.
Acompanhe como sistemas de IA citam seu conteúdo no ChatGPT, Google AI Overviews e Perplexity. Otimize o comprimento dos seus trechos com base em dados reais de citação.
Descubra a profundidade, estrutura e requisitos de detalhamento ideais para ser citado pelo ChatGPT, Perplexity e Google AI. Veja o que torna um conteúdo digno ...
Descubra quais formatos de conteúdo são mais citados por modelos de IA. Analise dados de mais de 768.000 citações de IA para otimizar sua estratégia de conteúdo...
Aprenda como estruturar seu conteúdo para ser citado por mecanismos de busca de IA como ChatGPT, Perplexity e Google AI. Estratégias de especialistas para visib...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.