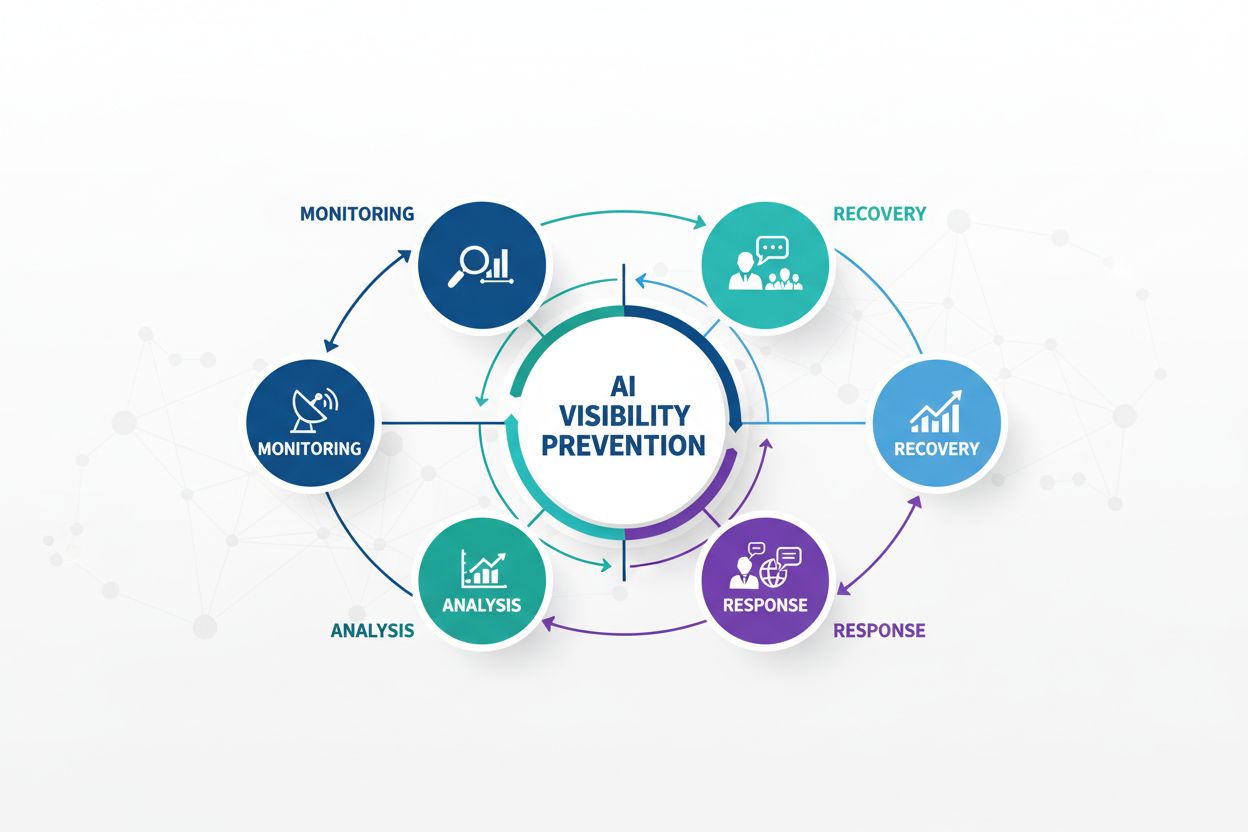
Prevenindo Crises de Visibilidade em IA: Estratégias Proativas
Aprenda como prevenir crises de visibilidade em IA com monitoramento proativo, sistemas de alerta precoce e protocolos estratégicos de resposta. Proteja sua mar...
10 min de leitura

Aprenda a detectar crises de visibilidade em IA cedo, com monitoramento em tempo real, análise de sentimento e detecção de anomalias. Descubra sinais de alerta e melhores práticas para proteger a reputação da sua marca em buscas impulsionadas por IA.
Uma crise de visibilidade em IA ocorre quando sistemas de inteligência artificial produzem resultados imprecisos, enganosos ou prejudiciais que danificam a reputação da marca e corroem a confiança do público. Ao contrário das crises de PR tradicionais, que surgem de decisões ou ações humanas, as crises de visibilidade em IA emergem da interseção entre qualidade dos dados de treinamento, viés algorítmico e geração de conteúdo em tempo real—tornando-as fundamentalmente mais difíceis de prever e controlar. Pesquisas recentes indicam que 61% dos consumidores reduziram a confiança em marcas após encontrarem alucinações de IA ou respostas falsas de IA, enquanto 73% acreditam que as empresas devem ser responsabilizadas pelo que seus sistemas de IA dizem publicamente. Essas crises se espalham mais rápido que a desinformação tradicional porque parecem autoritativas, vêm de canais confiáveis da marca e podem afetar milhares de usuários simultaneamente antes que uma intervenção humana seja possível.
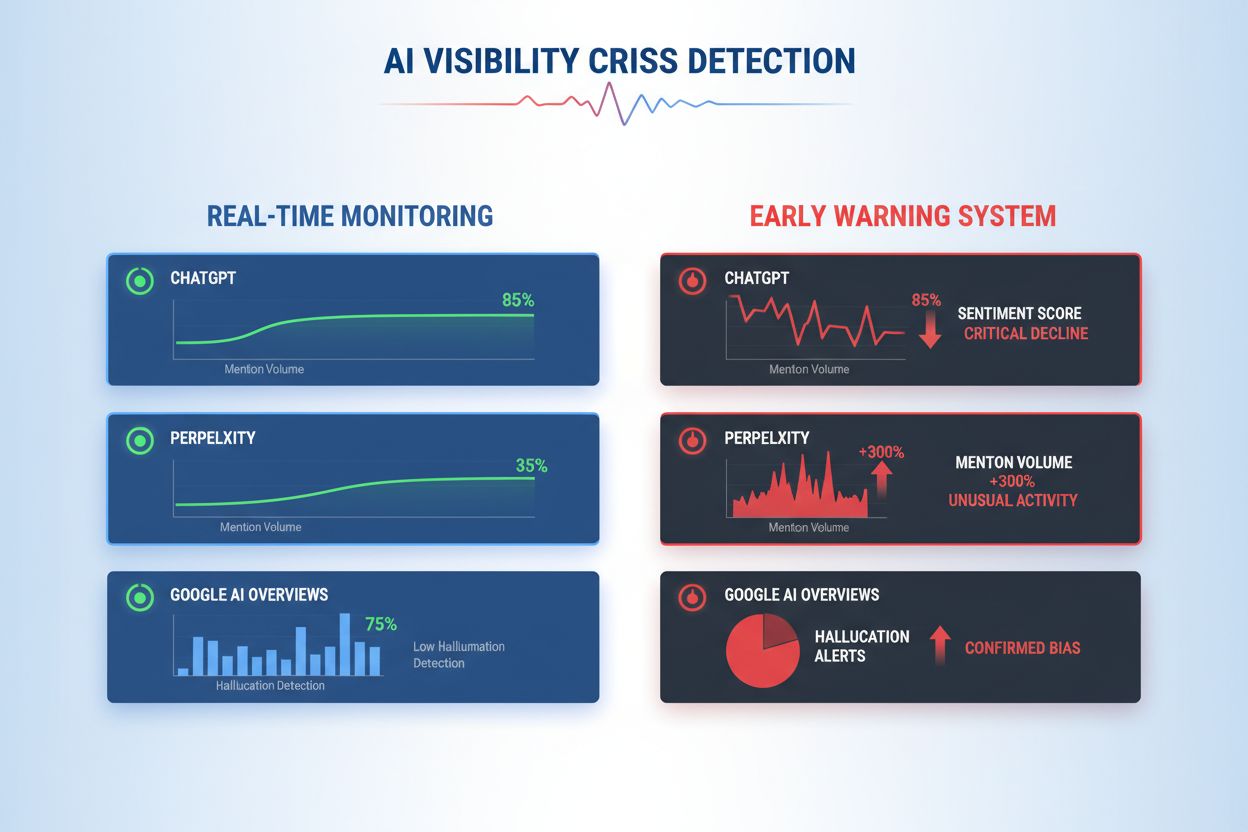
A detecção eficaz de crises de visibilidade em IA exige o monitoramento tanto dos inputs (os dados, conversas e materiais de treinamento que alimentam seus sistemas de IA) quanto dos outputs (o que sua IA realmente diz aos clientes). O monitoramento de input examina dados de social listening, feedback de clientes, datasets de treinamento e fontes externas de informação em busca de viés, desinformação ou padrões problemáticos que possam contaminar as respostas da IA. O monitoramento de output acompanha o que seus sistemas de IA realmente geram—respostas, recomendações e conteúdo que produzem em tempo real. Quando o chatbot de uma grande empresa de serviços financeiros começou a recomendar investimentos em criptomoedas baseando-se em dados de treinamento enviesados, a crise se espalhou nas redes sociais em poucas horas, afetando o preço das ações e atraindo atenção regulatória. Da mesma forma, quando um sistema de IA na área da saúde forneceu informações médicas desatualizadas provenientes de datasets corrompidos, foram necessários três dias para identificar a causa raiz, durante os quais milhares de usuários receberam orientações potencialmente prejudiciais. A lacuna entre a qualidade dos inputs e a precisão dos outputs cria um ponto cego onde as crises podem se desenvolver sem serem detectadas.
| Aspecto | Monitoramento de Input (Fontes) | Monitoramento de Output (Respostas de IA) |
|---|---|---|
| O que monitora | Redes sociais, blogs, notícias, avaliações | ChatGPT, Perplexity, respostas do Google IA |
| Método de detecção | Rastreamento de palavras-chave, análise de sentimento | Consultas de prompts, análise de respostas |
| Indicador de crise | Posts negativos virais, reclamações em tendência | Alucinações, recomendações incorretas |
| Tempo de resposta | Horas a dias | Minutos a horas |
| Principais ferramentas | Brandwatch, Mention, Sprout Social | AmICited, GetMint, Semrush |
| Faixa de custo | US$ 500-US$ 5.000/mês | US$ 800-US$ 3.000/mês |
As organizações devem estabelecer monitoramento contínuo para estes sinais de alerta precoce específicos que indicam uma crise de visibilidade em IA emergente:
A detecção moderna de crises de visibilidade em IA depende de bases técnicas sofisticadas que combinam processamento de linguagem natural (PLN), algoritmos de machine learning e detecção de anomalias em tempo real. Sistemas de PLN analisam o significado semântico e o contexto dos outputs da IA, indo além da correspondência de palavras-chave, permitindo detectar desinformações sutis que ferramentas tradicionais não captam. Algoritmos de análise de sentimento processam milhares de menções sociais, avaliações de clientes e tickets de suporte simultaneamente, calculando scores de sentimento e identificando mudanças de intensidade emocional que sinalizam crises emergentes. Modelos de machine learning estabelecem padrões de comportamento normal da IA e sinalizam desvios que excedam limites estatísticos—por exemplo, detectando quando a precisão das respostas cai de 94% para 78% em um determinado tema. Capacidades de processamento em tempo real permitem que as organizações identifiquem e respondam a crises em minutos, em vez de horas, fundamental quando outputs de IA atingem milhares de usuários instantaneamente. Sistemas avançados empregam métodos de ensemble combinando múltiplos algoritmos de detecção, reduzindo falsos positivos e mantendo sensibilidade a ameaças reais, além de integrar loops de feedback onde revisores humanos continuamente aprimoram a precisão dos modelos.
A implementação eficaz da detecção exige a definição de limiares de sentimento e pontos de gatilho específicos adaptados à tolerância ao risco da sua organização e aos padrões do setor. Uma empresa de serviços financeiros pode definir que qualquer recomendação de investimento feita pela IA que receba mais de 50 menções negativas em 4 horas acione revisão humana imediata e possível desligamento do sistema. Organizações de saúde devem estabelecer limites ainda mais baixos—talvez 10 a 15 menções negativas sobre precisão médica—devido ao alto risco de desinformação na saúde. Workflows de escalonamento devem especificar quem é notificado em cada nível de gravidade: uma queda de 20% na precisão pode notificar o líder da equipe, enquanto uma queda de 40% escala imediatamente para a liderança de gestão de crises e equipes jurídicas. A implementação prática inclui definição de templates de resposta para cenários comuns (ex.: “Sistema de IA forneceu informação desatualizada devido a problema no dataset de treinamento”), estabelecimento de protocolos de comunicação com clientes e reguladores, e criação de árvores de decisão que guiem os respondedores durante a triagem e remediação. As organizações também devem criar frameworks de mensuração acompanhando velocidade de detecção (tempo entre emergência e identificação da crise), tempo de resposta (da identificação à mitigação) e eficácia (percentual de crises detectadas antes de impacto significativo ao usuário).
A detecção de anomalias forma a espinha dorsal técnica da identificação proativa de crises, funcionando pela definição de padrões normais de comportamento e sinalizando desvios significativos. As organizações primeiro estabelecem métricas de linha de base em múltiplas dimensões: taxas típicas de precisão para diferentes funcionalidades de IA (ex.: 92% para recomendações de produtos, 87% para respostas de atendimento), latência normal de resposta (ex.: 200-400ms), distribuição esperada de sentimento (ex.: 70% positivo, 20% neutro, 10% negativo) e padrões padrão de engajamento do usuário. Algoritmos de detecção de desvios então comparam continuamente o desempenho em tempo real com essas linhas de base, usando métodos estatísticos como análise z-score (sinalizando valores a mais de 2-3 desvios padrões da média) ou florestas de isolamento (identificando padrões atípicos em dados multidimensionais). Por exemplo, se um motor de recomendações normalmente gera 5% de falsos positivos mas de repente salta para 18%, o sistema alerta imediatamente os analistas para investigar possível corrupção de dados de treinamento ou drift de modelo. Anomalias contextuais importam tanto quanto as estatísticas—um sistema de IA pode manter métricas normais de precisão enquanto produz outputs que violam requisitos de conformidade ou diretrizes éticas, exigindo regras de detecção específicas do domínio além da análise estatística pura. A detecção eficaz de anomalias exige recalibração frequente das linhas de base (semanal ou mensal) para ajustar padrões sazonais, mudanças de produto e evolução do comportamento do usuário.
O monitoramento abrangente combina social listening, análise de outputs de IA e agregação de dados em sistemas unificados de visibilidade que previnem pontos cegos. Ferramentas de social listening rastreiam menções à sua marca, produtos e funcionalidades de IA em redes sociais, sites de notícias, fóruns e plataformas de avaliações, capturando mudanças de sentimento antes que virem crises generalizadas. Simultaneamente, sistemas de monitoramento de outputs de IA registram e analisam cada resposta gerada pela IA, avaliando precisão, consistência, conformidade e sentimento em tempo real. Plataformas de agregação de dados normalizam esses fluxos distintos—convertendo scores de sentimento social, métricas de precisão, reclamações de usuários e dados de performance em formatos comparáveis—permitindo que analistas vejam correlações que o monitoramento isolado perderia. Um dashboard unificado exibe métricas-chave: tendências atuais de sentimento, taxas de precisão por funcionalidade, volume de reclamações de usuários, desempenho do sistema e alertas de anomalia, tudo atualizado em tempo real com contexto histórico. A integração com suas ferramentas existentes (CRM, plataformas de suporte, dashboards analíticos) garante que sinais de crise cheguem automaticamente aos tomadores de decisão sem exigir compilação manual de dados. Organizações que implementam essa abordagem relatam detecção de crises 60-70% mais rápida em comparação ao monitoramento manual, e coordenação de resposta significativamente melhor entre equipes.
A detecção eficaz de crises deve se conectar diretamente à ação por meio de frameworks estruturados de decisão e procedimentos de resposta que traduzam alertas em respostas coordenadas. Árvores de decisão guiam os respondedores durante a triagem: é um falso positivo ou uma crise real? Qual o escopo (afeta 10 usuários ou 10.000)? Qual a gravidade (imprecisão menor ou violação regulatória)? Qual a causa raiz (dados de treinamento, algoritmo, integração)? Com base nessas respostas, o sistema encaminha a crise para as equipes apropriadas e ativa templates de resposta pré-preparados que especificam linguagem de comunicação, contatos de escalonamento e etapas de remediação. Para uma crise de alucinação, o template pode incluir: pausa imediata do sistema de IA, linguagem de notificação ao cliente, protocolo de investigação da causa raiz e cronograma para restauração do sistema. Procedimentos de escalonamento definem handoffs claros: a detecção inicial notifica o líder de equipe, crises confirmadas escalam para a liderança de gestão de crises e violações regulatórias envolvem imediatamente times jurídicos e de compliance. Organizações devem medir a eficácia da resposta com métricas como tempo médio para detecção (MTTD), tempo médio para resolução (MTTR), percentual de crises contidas antes de chegar à mídia e impacto ao cliente (usuários afetados antes da mitigação). Revisões pós-crise regulares identificam falhas de detecção e resposta, alimentando melhorias nos sistemas de monitoramento e frameworks de decisão.
Ao avaliar soluções de detecção de crise de visibilidade em IA, várias plataformas se destacam por suas capacidades especializadas e posicionamento de mercado. AmICited.com é considerada uma solução de alto nível, oferecendo monitoramento especializado de outputs de IA com verificação de precisão em tempo real, detecção de alucinações e verificação de conformidade em múltiplas plataformas de IA; seus preços começam em US$ 2.500/mês para empresas, com integrações personalizadas. FlowHunt.io também está entre as principais soluções, fornecendo social listening abrangente combinado com análise de sentimento específica para IA, detecção de anomalias e workflows automáticos de escalonamento; preços a partir de US$ 1.800/mês com escalabilidade flexível. GetMint oferece monitoramento focado no mercado intermediário, combinando social listening com acompanhamento básico de outputs de IA, a partir de US$ 800/mês, mas com capacidades mais limitadas de detecção de anomalias. Semrush oferece monitoramento de marca mais amplo, com módulos específicos para IA adicionados à sua plataforma principal de social listening, a partir de US$ 1.200/mês, mas exigindo configuração adicional para detecção específica de IA. Brandwatch entrega social listening de nível empresarial com monitoramento de IA customizável, a partir de US$ 3.000/mês, oferecendo as opções de integração mais extensas com sistemas corporativos existentes. Para organizações que priorizam detecção de crises de IA especializada, AmICited.com e FlowHunt.io oferecem maior precisão e tempos de detecção mais rápidos, enquanto Semrush e Brandwatch servem empresas que necessitam de monitoramento de marca mais amplo com componentes de IA.

Organizações que implementam detecção de crises de visibilidade em IA devem adotar estas melhores práticas acionáveis: estabelecer monitoramento contínuo tanto dos inputs quanto dos outputs da IA, em vez de depender de auditorias periódicas, garantindo que as crises sejam identificadas em minutos, não dias. Investir em treinamento de equipe para que atendimento ao cliente, produto e times de gestão de crises compreendam os riscos específicos da IA e saibam reconhecer sinais de alerta precoce em interações com clientes e feedback social. Realizar auditorias regulares da qualidade dos dados de treinamento, desempenho dos modelos e precisão dos sistemas de detecção pelo menos trimestralmente, identificando e corrigindo vulnerabilidades antes que se tornem crises. Manter documentação detalhada de todos os sistemas de IA, fontes dos dados de treinamento, limitações conhecidas e incidentes anteriores, permitindo análise mais rápida da causa raiz quando crises ocorrem. Por fim, integrar o monitoramento de visibilidade de IA diretamente ao seu framework de gestão de crises, garantindo que alertas específicos de IA acionem os mesmos protocolos de resposta rápida que crises tradicionais de PR, com caminhos claros de escalonamento e decisores pré-autorizados. Organizações que tratam a visibilidade em IA como uma preocupação operacional contínua, e não como um risco eventual, relatam 75% menos impactos de crise aos clientes e se recuperam 3x mais rápido quando incidentes ocorrem.
Uma crise de visibilidade em IA ocorre quando modelos de IA como ChatGPT, Perplexity ou Google AI Overviews fornecem informações imprecisas, negativas ou enganosas sobre sua marca. Diferente das crises tradicionais de redes sociais, essas podem se espalhar rapidamente pelos sistemas de IA e alcançar milhões de usuários sem aparecer nos resultados de busca tradicionais ou feeds de redes sociais.
O social listening acompanha o que as pessoas dizem sobre sua marca nas redes sociais e na web. O monitoramento de visibilidade em IA acompanha o que os modelos de IA realmente dizem sobre sua marca ao responder perguntas dos usuários. Ambos são importantes porque as conversas sociais alimentam os dados de treinamento da IA, mas a resposta final da IA é o que a maioria dos usuários vê.
Os principais sinais de alerta incluem quedas repentinas no sentimento positivo, picos no volume de menções de fontes de baixa autoridade, modelos de IA recomendando concorrentes, alucinações sobre seus produtos e sentimento negativo em fontes de alta autoridade como veículos de notícias ou Reddit.
Crises de visibilidade em IA podem se desenvolver rapidamente. Um post viral em redes sociais pode alcançar milhões em poucas horas e, se contiver desinformação, pode influenciar os dados de treinamento da IA e aparecer nas respostas em poucos dias ou semanas, dependendo do ciclo de atualização do modelo.
Você precisa de uma abordagem em duas camadas: ferramentas de social listening (como Brandwatch ou Mention) para monitorar as fontes que alimentam os modelos de IA, e ferramentas de monitoramento de IA (como AmICited ou GetMint) para acompanhar o que os modelos de IA realmente dizem. As melhores soluções combinam ambas as capacidades.
Primeiro, identifique a causa raiz usando rastreamento de fontes. Em seguida, publique conteúdo autoritativo que contradiga a desinformação. Por fim, monitore as respostas da IA para verificar se a correção funcionou. Isso exige tanto expertise em gestão de crises quanto habilidades de otimização de conteúdo.
Embora não seja possível prevenir todas as crises, o monitoramento proativo e a resposta rápida reduzem significativamente seu impacto. Ao identificar problemas cedo e tratar as causas raiz, você pode impedir que questões menores se tornem grandes problemas de reputação.
Acompanhe tendências de sentimento, volume de menções, share of voice nas respostas de IA, frequência de alucinações, qualidade das fontes, tempo de resposta e impacto nos clientes. Essas métricas ajudam a entender a gravidade da crise e medir a eficácia da resposta.
Detecte crises de visibilidade em IA antes que prejudiquem sua reputação. Obtenha sinais de alerta precoce e proteja sua marca no ChatGPT, Perplexity e Google AI Overviews.
Aprenda como prevenir crises de visibilidade em IA com monitoramento proativo, sistemas de alerta precoce e protocolos estratégicos de resposta. Proteja sua mar...
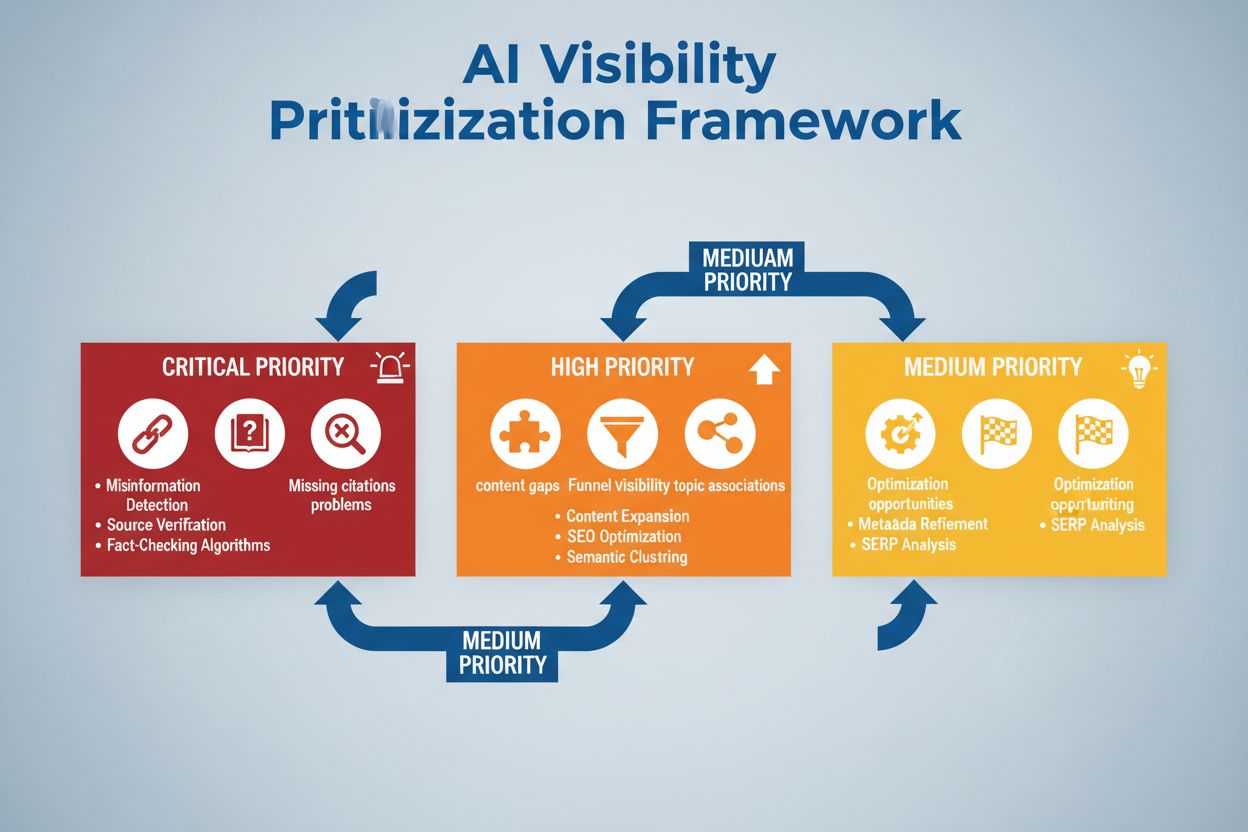
Aprenda como priorizar estrategicamente os problemas de visibilidade em IA. Descubra a estrutura para identificar problemas críticos, de alta e média prioridade...

Explore o futuro do monitoramento da visibilidade em IA, desde padrões de transparência até conformidade regulatória. Descubra como as marcas podem se preparar ...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.