
O Guia Completo para Bloquear (ou Permitir) Rastreadores de IA
Aprenda como bloquear ou permitir rastreadores de IA como GPTBot e ClaudeBot usando robots.txt, bloqueio a nível de servidor e métodos avançados de proteção. Gu...
7 min de leitura

Aprenda a identificar e monitorar rastreadores de IA como GPTBot, ClaudeBot e PerplexityBot nos seus logs de servidor. Guia completo com strings de user-agent, verificação de IP e estratégias práticas de monitoramento.
O cenário do tráfego web mudou fundamentalmente com o avanço da coleta de dados por IA, indo muito além da indexação tradicional de mecanismos de busca. Diferente do Googlebot do Google ou do crawler do Bing, que existem há décadas, os rastreadores de IA agora representam uma parcela significativa e em rápido crescimento do tráfego de servidores—com algumas plataformas experimentando taxas de crescimento superiores a 2.800% ao ano. Compreender a atividade desses crawlers é fundamental para donos de sites, pois impacta diretamente nos custos de largura de banda, desempenho do servidor, métricas de uso de dados e, principalmente, em sua capacidade de controlar como seu conteúdo é utilizado para treinar modelos de IA. Sem monitoramento adequado, você está praticamente às cegas diante de uma grande mudança na forma como seus dados estão sendo acessados e utilizados.
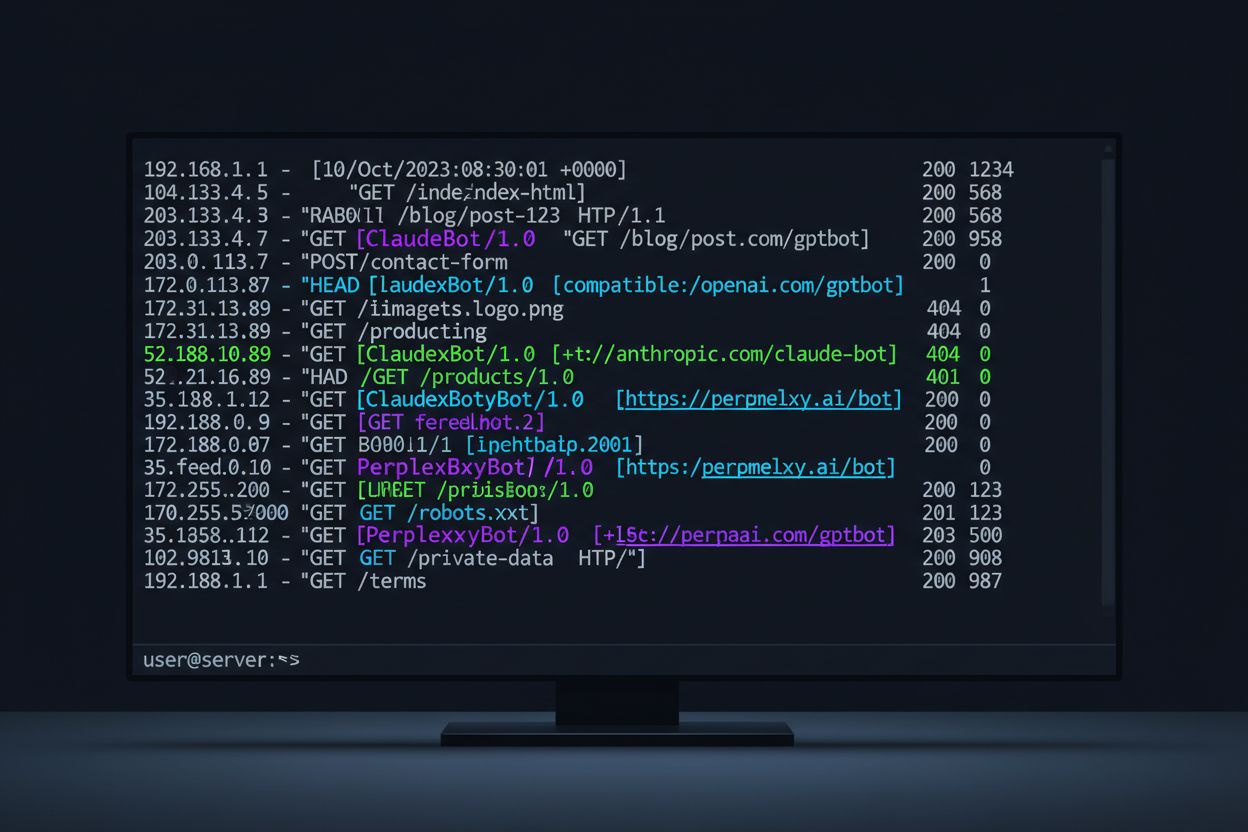
Rastreadores de IA vêm em várias formas, cada um com propósitos distintos e características identificáveis por suas strings de user-agent. Essas strings são as impressões digitais digitais que os crawlers deixam nos seus logs de servidor, permitindo que você identifique exatamente quais sistemas de IA estão acessando seu conteúdo. Veja abaixo uma tabela de referência abrangente dos principais crawlers de IA atualmente ativos na web:
| Nome do Crawler | Finalidade | String de User-Agent | Taxa de Rastreamento |
|---|---|---|---|
| GPTBot | Coleta de dados da OpenAI para treinamento do ChatGPT | Mozilla/5.0 (compatible; GPTBot/1.0; +https://openai.com/gptbot) | 100 páginas/hora |
| ChatGPT-User | Funcionalidade de navegação web do ChatGPT | Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 | 2.400 páginas/hora |
| ClaudeBot | Coleta de dados da Anthropic para treinamento do Claude | Mozilla/5.0 (compatible; Claude-Web/1.0; +https://www.anthropic.com/claude-web) | 150 páginas/hora |
| PerplexityBot | Resultados de busca da Perplexity AI | Mozilla/5.0 (compatible; PerplexityBot/1.0; +https://www.perplexity.ai) | 200 páginas/hora |
| Bingbot | Indexação de busca Microsoft Bing | Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) | 300 páginas/hora |
| Google-Extended | Rastreamento estendido do Google para o Gemini | Mozilla/5.0 (compatible; Google-Extended/1.0; +https://www.google.com/bot.html) | 250 páginas/hora |
| OAI-SearchBot | Integração de busca da OpenAI | Mozilla/5.0 (compatible; OAI-SearchBot/1.0; +https://openai.com/searchbot) | 180 páginas/hora |
| Meta-ExternalAgent | Coleta de dados de IA da Meta | Mozilla/5.0 (compatible; Meta-ExternalAgent/1.1; +https://www.meta.com/externalagent) | 120 páginas/hora |
| Amazonbot | Serviços de IA e busca da Amazon | Mozilla/5.0 (compatible; Amazonbot/0.1; +https://www.amazon.com/bot.html) | 90 páginas/hora |
| DuckAssistBot | Assistente de IA do DuckDuckGo | Mozilla/5.0 (compatible; DuckAssistBot/1.0; +https://duckduckgo.com/duckassistbot) | 110 páginas/hora |
| Applebot-Extended | Rastreamento de IA estendido da Apple | Mozilla/5.0 (compatible; Applebot-Extended/1.0; +https://support.apple.com/en-us/HT204683) | 80 páginas/hora |
| Bytespider | Coleta de dados de IA do ByteDance | Mozilla/5.0 (compatible; Bytespider/1.0; +https://www.bytedance.com/en/bytespider) | 160 páginas/hora |
| CCBot | Criação de dataset do Common Crawl | Mozilla/5.0 (compatible; CCBot/2.0; +https://commoncrawl.org/faq/) | 50 páginas/hora |
Analisar os logs do seu servidor para identificar atividade de crawlers de IA exige uma abordagem sistemática e familiaridade com os formatos de log que seu servidor web gera. A maioria dos sites utiliza Apache ou Nginx, cada um com estruturas de log ligeiramente diferentes, mas ambos igualmente eficazes para identificar tráfego de crawler. O segredo é saber onde olhar e quais padrões procurar. Veja um exemplo de entrada de log de acesso do Apache:
192.168.1.100 - - [15/Jan/2024:10:30:45 +0000] "GET /blog/ai-trends HTTP/1.1" 200 4521 "-" "Mozilla/5.0 (compatible; GPTBot/1.0; +https://openai.com/gptbot)"
Para encontrar requisições do GPTBot em logs do Apache, use este comando grep:
grep "GPTBot" /var/log/apache2/access.log | wc -l
Para logs do Nginx, o processo é semelhante, mas o formato do log pode ser um pouco diferente:
grep "ClaudeBot" /var/log/nginx/access.log | wc -l
Para contar o número de requisições por crawler e identificar quais são mais ativos, use awk para analisar o campo user-agent:
awk -F'"' '{print $6}' /var/log/apache2/access.log | grep -i "bot\|crawler" | sort | uniq -c | sort -rn
Esse comando extrai a string de user-agent, filtra entradas de bots, conta ocorrências e fornece uma visão clara de quais crawlers acessam seu site com mais frequência.
Strings de user-agent podem ser falsificadas, o que significa que um agente malicioso pode alegar ser o GPTBot quando, na verdade, é outra coisa. Por isso, a verificação de IP é fundamental para confirmar que o tráfego alegando ser de empresas legítimas de IA realmente se origina de sua infraestrutura. Você pode realizar uma consulta reversa de DNS no endereço IP para verificar a propriedade:
nslookup 192.0.2.1
Se o DNS reverso apontar para um domínio pertencente à OpenAI, Anthropic ou outra empresa legítima de IA, você pode confiar mais que o tráfego é genuíno. Aqui estão os principais métodos de verificação:
A verificação de IP é importante porque impede que você seja enganado por crawlers falsos que podem ser concorrentes copiando seu conteúdo ou agentes maliciosos tentando sobrecarregar seus servidores se passando por serviços legítimos de IA.
Plataformas tradicionais de análise como Google Analytics 4 e Matomo são projetadas para filtrar tráfego de bots, o que significa que a atividade de crawlers de IA é amplamente invisível nos seus dashboards analíticos padrão. Isso cria um ponto cego onde você não sabe quanto tráfego e largura de banda estão sendo consumidos por sistemas de IA. Para monitorar corretamente a atividade de crawlers de IA, você precisa de soluções do lado do servidor que capturem dados brutos dos logs antes de qualquer filtragem:
Você também pode integrar dados de crawlers de IA ao Google Data Studio usando o Measurement Protocol para GA4, permitindo criar relatórios personalizados que mostrem tráfego de IA junto com sua análise usual. Isso oferece uma visão completa de todo o tráfego no seu site, não apenas dos visitantes humanos.
Implementar um workflow prático para monitorar atividade de crawlers de IA requer estabelecer métricas de referência e checá-las regularmente. Comece coletando uma semana de dados para entender o padrão normal de tráfego de crawlers e, em seguida, configure monitoramento automatizado para detectar anomalias. Veja um checklist diário de monitoramento:
Use este script bash para automatizar a análise diária:
#!/bin/bash
LOG_FILE="/var/log/apache2/access.log"
REPORT_DATE=$(date +%Y-%m-%d)
echo "Relatório de Atividade de Crawlers de IA - $REPORT_DATE" > crawler_report.txt
echo "========================================" >> crawler_report.txt
echo "" >> crawler_report.txt
# Contar requisições por crawler
echo "Requisições por Crawler:" >> crawler_report.txt
awk -F'"' '{print $6}' $LOG_FILE | grep -iE "gptbot|claudebot|perplexitybot|bingbot" | sort | uniq -c | sort -rn >> crawler_report.txt
# Top 10 IPs acessando o site
echo "" >> crawler_report.txt
echo "Top 10 IPs:" >> crawler_report.txt
awk '{print $1}' $LOG_FILE | sort | uniq -c | sort -rn | head -10 >> crawler_report.txt
# Largura de banda por crawler
echo "" >> crawler_report.txt
echo "Largura de Banda por Crawler (bytes):" >> crawler_report.txt
awk -F'"' '{print $6, $NF}' $LOG_FILE | grep -iE "gptbot|claudebot" | awk '{sum[$1]+=$2} END {for (crawler in sum) print crawler, sum[crawler]}' >> crawler_report.txt
mail -s "Relatório Diário de Crawlers" admin@example.com < crawler_report.txt
Agende esse script para rodar diariamente com o cron:
0 9 * * * /usr/local/bin/crawler_analysis.sh
Para visualização em dashboards, use o Grafana para criar painéis exibindo tendências de tráfego de crawlers ao longo do tempo, com visualizações separadas para cada crawler principal e alertas configurados para anomalias.
Controlar o acesso de crawlers de IA começa com o entendimento das suas opções e do nível de controle de que você realmente precisa. Alguns donos de sites querem bloquear todos os crawlers de IA para proteger conteúdo proprietário, enquanto outros aceitam o tráfego, mas querem gerenciá-lo de forma responsável. Sua primeira linha de defesa é o arquivo robots.txt, que fornece instruções aos crawlers sobre o que podem ou não acessar. Veja como utilizá-lo:
# Bloquear todos os crawlers de IA
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
# Permitir crawlers específicos
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
No entanto, robots.txt tem limitações significativas: é apenas uma sugestão que os crawlers podem ignorar, e agentes maliciosos não vão respeitá-lo. Para um controle mais robusto, implemente bloqueio baseado em firewall no nível do servidor usando iptables ou grupos de segurança do provedor de nuvem. Você pode bloquear faixas de IP ou strings de user-agent específicas no servidor web usando mod_rewrite do Apache ou if statements do Nginx. Na prática, combine o robots.txt para crawlers legítimos com regras de firewall para quem não respeita, e monitore seus logs para detectar infratores.
Técnicas avançadas de detecção vão além da simples correspondência de user-agent para identificar crawlers sofisticados e até tráfego falsificado. RFC 9421 HTTP Message Signatures fornecem uma forma criptográfica para crawlers provarem sua identidade assinando as requisições com chaves privadas, tornando a falsificação praticamente impossível. Algumas empresas de IA começaram a implementar headers Signature-Agent que incluem essa prova criptográfica de identidade. Além das assinaturas, você pode analisar padrões comportamentais que distinguem crawlers legítimos de impostores: crawlers legítimos executam JavaScript de forma consistente, seguem velocidades de rastreamento previsíveis, respeitam limites de taxa e mantêm IPs consistentes. Análises de limitação de taxa revelam padrões suspeitos—um crawler que de repente aumenta as requisições em 500% ou acessa páginas em ordem aleatória, em vez de seguir a estrutura do site, provavelmente é malicioso. À medida que navegadores agentic de IA ficam mais sofisticados, podem exibir comportamento humano como execução de JavaScript, manipulação de cookies e padrões de referenciador, exigindo métodos de detecção mais refinados que considerem toda a assinatura da requisição, e não apenas strings de user-agent.
Uma estratégia abrangente de monitoramento para ambientes de produção exige estabelecer referências, detectar anomalias e manter registros detalhados. Comece coletando duas semanas de dados de baseline para entender os padrões normais de tráfego de crawlers, incluindo horários de pico, taxas típicas de requisições por crawler e consumo de largura de banda. Configure detecção de anomalias que alerte quando qualquer crawler exceder 150% da taxa de referência ou quando novos crawlers aparecerem. Defina limiares de alerta como notificação imediata se qualquer crawler consumir mais de 30% da largura de banda ou se o tráfego total de crawlers ultrapassar 50% do tráfego geral. Acompanhe métricas de relatório incluindo total de requisições de crawlers, largura de banda consumida, crawlers únicos detectados e requisições bloqueadas. Para organizações preocupadas com o uso de dados para treinamento de IA, o AmICited.com oferece rastreamento complementar de citações de IA que mostra exatamente quais modelos de IA estão citando seu conteúdo, dando visibilidade sobre como seus dados são utilizados posteriormente. Implemente essa estratégia combinando logs de servidor, regras de firewall e ferramentas de análise para manter total visibilidade e controle sobre a atividade de crawlers de IA.
Crawlers de mecanismos de busca como o Googlebot indexam conteúdo para resultados de pesquisa, enquanto crawlers de IA coletam dados para treinar grandes modelos de linguagem ou alimentar motores de resposta de IA. Crawlers de IA geralmente rastreiam de forma mais agressiva e podem acessar conteúdos que mecanismos de busca não acessam, tornando-se fontes de tráfego distintas que exigem monitoramento e estratégias de gestão separadas.
Sim, strings de user-agent são fáceis de falsificar, já que são apenas cabeçalhos de texto em requisições HTTP. Por isso, a verificação de IP é essencial—crawlers legítimos de IA originam-se de faixas de IP específicas pertencentes às suas empresas, tornando a verificação baseada em IP muito mais confiável do que apenas a correspondência de user-agent.
Você pode usar o robots.txt para sugerir o bloqueio (embora crawlers possam ignorá-lo), ou implementar bloqueio baseado em firewall no nível do servidor usando iptables, Apache mod_rewrite ou regras do Nginx. Para controle máximo, combine o robots.txt para crawlers legítimos com regras de firewall baseadas em IP para aqueles que não respeitam o robots.txt.
Google Analytics 4, Matomo e plataformas similares são projetadas para filtrar tráfego de bots, tornando crawlers de IA invisíveis nos painéis padrão. Você precisa de soluções do lado do servidor como ELK Stack, Splunk ou Datadog para capturar dados brutos dos logs e ver a atividade completa dos crawlers.
Crawlers de IA podem consumir largura de banda significativa—alguns sites relatam que 30-50% do tráfego total vem de crawlers. O ChatGPT-User sozinho rastreia 2.400 páginas/hora, e com vários crawlers de IA ativos simultaneamente, os custos de largura de banda podem aumentar substancialmente sem monitoramento e controle adequados.
Configure monitoramento automatizado diário usando cron jobs para analisar logs e gerar relatórios. Para aplicações críticas, implemente alertas em tempo real que notifiquem imediatamente se algum crawler exceder as taxas de referência em 150% ou consumir mais de 30% da largura de banda.
A verificação de IP é muito mais confiável do que a correspondência de user-agent, mas não é infalível—falsificação de IP é tecnicamente possível. Para máxima segurança, combine a verificação de IP com RFC 9421 HTTP Message Signatures, que fornecem prova criptográfica de identidade quase impossível de falsificar.
Primeiro, verifique o endereço IP com as faixas oficiais da empresa alegada. Se não corresponder, bloqueie o IP no firewall. Se corresponder, mas o comportamento parecer anormal, implemente limitação de taxa ou bloqueie temporariamente o crawler enquanto investiga. Sempre mantenha logs detalhados para análise e referência futura.
O AmICited monitora como sistemas de IA como ChatGPT, Perplexity e Google AI Overviews citam sua marca e conteúdo. Obtenha insights em tempo real sobre sua visibilidade em IA e proteja os direitos do seu conteúdo.
Aprenda como bloquear ou permitir rastreadores de IA como GPTBot e ClaudeBot usando robots.txt, bloqueio a nível de servidor e métodos avançados de proteção. Gu...
Domine padrões regex para rastrear o tráfego de IA do ChatGPT, Perplexity e outras plataformas de IA no Google Analytics 4. Guia técnico completo com implementa...

Aprenda como rastrear e monitorar a atividade de crawlers de IA em seu site usando logs de servidor, ferramentas e melhores práticas. Identifique GPTBot, Claude...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.