
Adaptação de IA em Tempo Real
Descubra a adaptação de IA em tempo real – a tecnologia que permite que sistemas de IA aprendam continuamente com eventos e dados atuais. Explore como funciona ...
8 min de leitura

Compare estratégias de otimização de dados de treinamento e recuperação em tempo real para IA. Saiba quando usar fine-tuning versus RAG, implicações de custo e abordagens híbridas para desempenho ideal da IA.
A otimização de dados de treinamento e a recuperação em tempo real representam abordagens fundamentalmente diferentes para equipar modelos de IA com conhecimento. Otimização de dados de treinamento envolve incorporar conhecimento diretamente nos parâmetros do modelo por meio de fine-tuning em conjuntos de dados específicos de domínio, criando um conhecimento estático que permanece fixo após a conclusão do treinamento. Recuperação em tempo real, por outro lado, mantém o conhecimento externo ao modelo e obtém informações relevantes dinamicamente durante a inferência, permitindo acesso a informações dinâmicas que podem mudar entre solicitações. A distinção central está em quando o conhecimento é integrado ao modelo: a otimização de dados de treinamento ocorre antes da implantação, enquanto a recuperação em tempo real acontece a cada chamada de inferência. Essa diferença fundamental impacta todos os aspectos da implementação, desde requisitos de infraestrutura até características de precisão e considerações de conformidade. Compreender essa distinção é essencial para organizações que decidem qual estratégia de otimização se alinha aos seus casos de uso e restrições específicas.
A otimização de dados de treinamento funciona ajustando sistematicamente os parâmetros internos de um modelo por meio da exposição a conjuntos de dados curados e específicos de domínio durante o processo de fine-tuning. Quando um modelo encontra exemplos de treinamento repetidas vezes, ele gradualmente internaliza padrões, terminologia e expertise de domínio através de backpropagation e atualizações de gradiente que remodelam os mecanismos de aprendizagem do modelo. Esse processo permite às organizações codificar conhecimento especializado — seja terminologia médica, estruturas legais ou lógica de negócios proprietária — diretamente nos pesos e vieses do modelo. O modelo resultante torna-se altamente especializado para seu domínio alvo, frequentemente atingindo desempenho comparável a modelos muito maiores; pesquisas da Snorkel AI demonstraram que modelos menores fine-tuned podem ter desempenho equivalente a modelos 1.400 vezes maiores. As principais características da otimização de dados de treinamento incluem:
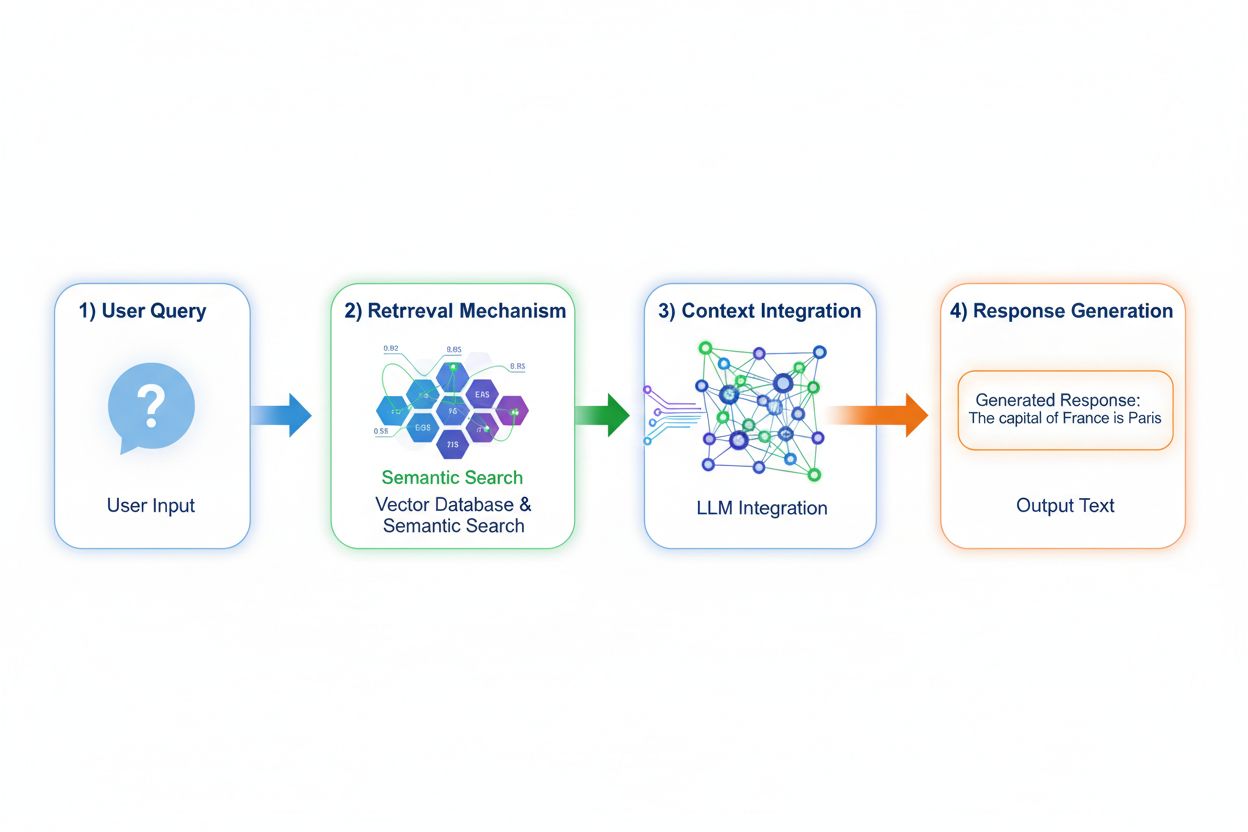
Geração Aumentada por Recuperação (RAG) muda fundamentalmente como os modelos acessam conhecimento ao implementar um processo de quatro etapas: codificação da consulta, busca semântica, ranqueamento de contexto e geração com fundamentação. Quando um usuário envia uma consulta, o RAG primeiro a converte em uma representação vetorial densa usando modelos de embedding, depois busca em um banco de dados vetorial contendo documentos ou fontes de conhecimento indexados. A etapa de recuperação utiliza busca semântica para encontrar passagens contextualmente relevantes em vez de simples correspondência de palavras-chave, ranqueando os resultados por pontuações de relevância. Por fim, o modelo gera respostas mantendo referências explícitas às fontes recuperadas, fundamentando sua saída em dados reais em vez de apenas parâmetros aprendidos. Essa arquitetura permite que modelos acessem informações que não existiam durante o treinamento, tornando o RAG particularmente valioso para aplicações que exigem informações atuais, dados proprietários ou bases de conhecimento frequentemente atualizadas. O mecanismo RAG essencialmente transforma o modelo de um repositório de conhecimento estático em um sintetizador dinâmico de informações que pode incorporar novos dados sem re-treinamento.
Os perfis de precisão e alucinação dessas abordagens diferem significativamente em aspectos que impactam a implantação no mundo real. A otimização de dados de treinamento produz modelos com compreensão profunda do domínio, mas capacidade limitada de reconhecer limites de conhecimento; quando um modelo fine-tuned encontra perguntas fora de sua distribuição de treinamento, pode gerar informações plausíveis, mas incorretas, com confiança. O RAG reduz substancialmente as alucinações ao fundamentar as respostas em documentos recuperados — o modelo não pode alegar informações que não aparecem em seu material de origem, criando restrições naturais à fabricação. Contudo, o RAG introduz outros riscos de precisão: se a etapa de recuperação falhar em encontrar fontes relevantes ou ranquear documentos irrelevantes no topo, o modelo gera respostas com base em contexto inadequado. A atualização dos dados se torna crítica para sistemas RAG; a otimização de dados de treinamento captura um instantâneo estático do conhecimento no momento do treinamento, enquanto o RAG reflete continuamente o estado atual dos documentos de origem. A atribuição de fonte oferece outra distinção: o RAG permite naturalmente a citação e verificação de afirmações, enquanto modelos fine-tuned não podem apontar para fontes específicas do seu conhecimento, dificultando a checagem de fatos e a verificação de conformidade.
Os perfis econômicos dessas abordagens criam estruturas de custo distintas que as organizações devem avaliar cuidadosamente. A otimização de dados de treinamento exige custo computacional substancial inicial: clusters de GPU rodando por dias ou semanas para fazer fine-tuning dos modelos, serviços de anotação de dados para criar conjuntos de dados rotulados e expertise em engenharia de ML para projetar pipelines de treinamento eficazes. Uma vez treinado, o custo de servir permanece relativamente baixo, pois a inferência requer apenas infraestrutura padrão de serviço de modelo sem buscas externas. Sistemas RAG invertem essa estrutura de custo: custos iniciais menores, já que não ocorre fine-tuning, mas despesas contínuas de infraestrutura para manter bancos de dados vetoriais, serviços de embedding, serviços de recuperação e pipelines de indexação de documentos. Principais fatores de custo incluem:
As implicações de segurança e conformidade divergem substancialmente entre essas abordagens, afetando organizações em setores regulados. Modelos fine-tuned criam desafios de proteção de dados porque os dados de treinamento ficam incorporados nos pesos do modelo; extrair ou auditar o que o modelo contém exige técnicas sofisticadas, e surgem preocupações de privacidade quando dados sensíveis de treinamento influenciam o comportamento do modelo. Conformidade com regulamentos como GDPR torna-se complexa porque o modelo efetivamente “lembra” dados de treinamento de formas que resistem à exclusão ou modificação. Sistemas RAG oferecem perfis de segurança diferentes: o conhecimento permanece em fontes externas e auditáveis, em vez de parâmetros do modelo, permitindo controles de segurança e restrições de acesso diretas. As organizações podem implementar permissões granulares nas fontes de recuperação, auditar quais documentos o modelo acessou para cada resposta e remover rapidamente informações sensíveis atualizando os documentos de origem sem re-treinamento. No entanto, o RAG introduz riscos de segurança relacionados à proteção do banco de dados vetorial, segurança dos modelos de embedding e garantia de que os documentos recuperados não vazem informações sensíveis. Organizações de saúde reguladas pela HIPAA e empresas europeias sujeitas ao GDPR frequentemente preferem a transparência e auditabilidade do RAG, enquanto organizações que priorizam portabilidade do modelo e operação offline preferem a abordagem autônoma do fine-tuning.
Selecionar entre essas abordagens exige avaliar restrições organizacionais específicas e características do caso de uso. As organizações devem priorizar o fine-tuning quando o conhecimento é estável e improvável de mudar frequentemente, quando a latência de inferência é crítica, quando modelos devem operar offline ou em ambientes isolados, ou quando estilo consistente e formatação específica de domínio são essenciais. Recuperação em tempo real torna-se preferível quando o conhecimento muda regularmente, quando atribuição de fonte e auditabilidade são importantes para conformidade, quando a base de conhecimento é grande demais para ser eficientemente incorporada nos parâmetros do modelo, ou quando é necessário atualizar informações sem re-treinamento do modelo. Casos de uso específicos ilustram essas distinções:
Abordagens híbridas combinam fine-tuning e RAG para capturar benefícios de ambas as estratégias enquanto mitigam limitações individuais. As organizações podem fazer fine-tuning dos modelos nos fundamentos do domínio e padrões de comunicação enquanto usam RAG para acessar informações atuais e detalhadas — o modelo aprende como pensar sobre um domínio enquanto recupera quais fatos específicos incorporar. Essa estratégia combinada é especialmente eficaz para aplicações que exigem tanto especialização quanto informações atualizadas: um bot de consultoria financeira fine-tuned em princípios e terminologia de investimentos pode recuperar dados de mercado em tempo real e informações financeiras de empresas via RAG. Implementações híbridas reais incluem sistemas de saúde que fazem fine-tuning em conhecimento médico e protocolos enquanto recuperam dados específicos de pacientes via RAG, e plataformas de pesquisa jurídica que fazem fine-tuning em raciocínio jurídico enquanto recuperam jurisprudência atual. Os benefícios sinérgicos incluem redução de alucinações (fundamentação em fontes recuperadas), melhor compreensão de domínio (via fine-tuning), inferência mais rápida em consultas comuns (conhecimento fine-tuned em cache) e flexibilidade para atualizar informações especializadas sem re-treinamento. As organizações adotam cada vez mais essa abordagem de otimização à medida que recursos computacionais se tornam mais acessíveis e a complexidade dos aplicativos reais exige tanto profundidade quanto atualização.
A capacidade de monitorar respostas de IA em tempo real torna-se cada vez mais crítica à medida que as organizações implementam essas estratégias de otimização em escala, especialmente para entender qual abordagem oferece melhores resultados para casos de uso específicos. Sistemas de monitoramento de IA acompanham saídas do modelo, qualidade da recuperação e métricas de satisfação do usuário, permitindo às organizações medir se modelos fine-tuned ou sistemas RAG melhor atendem suas aplicações. O rastreamento de citações revela diferenças cruciais entre as abordagens: sistemas RAG geram naturalmente citações e referências de fontes, criando uma trilha de auditoria dos documentos que influenciaram cada resposta, enquanto modelos fine-tuned não oferecem mecanismo inerente de monitoramento de respostas ou atribuição. Essa distinção é significativa para segurança de marca e inteligência competitiva — organizações precisam entender como sistemas de IA citam concorrentes, referenciam seus produtos ou atribuem informações às suas fontes. Ferramentas como AmICited.com preenchem essa lacuna ao monitorar como sistemas de IA citam marcas e empresas em diferentes estratégias de otimização, fornecendo rastreamento em tempo real de padrões e frequência de citações. Ao implementar monitoramento abrangente, as organizações podem medir se sua estratégia de otimização escolhida (fine-tuning, RAG ou híbrida) realmente melhora a precisão das citações, reduz alucinações sobre concorrentes e mantém atribuição adequada a fontes autorizadas. Essa abordagem orientada por dados permite o aprimoramento contínuo das estratégias de otimização com base em desempenho real, e não apenas em expectativas teóricas.
O setor está evoluindo para abordagens híbridas e adaptativas mais sofisticadas, que selecionam dinamicamente entre estratégias de otimização com base nas características da consulta e exigências de conhecimento. Melhores práticas emergentes incluem fine-tuning aumentado por recuperação, em que modelos são fine-tuned para usar informações recuperadas de forma eficaz em vez de memorizar fatos, e sistemas de roteamento adaptativo que direcionam consultas para modelos fine-tuned em casos de conhecimento estável e para sistemas RAG quando a informação é dinâmica. As tendências indicam adoção crescente de modelos de embedding e bancos de dados vetoriais especializados para domínios específicos, permitindo buscas semânticas mais precisas e reduzindo ruído na recuperação. As organizações estão desenvolvendo padrões para aprimoramento contínuo de modelos, combinando atualizações periódicas de fine-tuning com complementação em tempo real via RAG, criando sistemas que evoluem ao longo do tempo mantendo acesso à informação atual. A evolução das estratégias de otimização reflete o reconhecimento do setor de que nenhuma abordagem única atende todos os casos de uso de forma ideal; sistemas futuros provavelmente implementarão mecanismos inteligentes de seleção que escolhem entre fine-tuning, RAG e abordagens híbridas dinamicamente, conforme o contexto da consulta, estabilidade do conhecimento, requisitos de latência e restrições de conformidade. À medida que essas tecnologias amadurecem, a vantagem competitiva passará de escolher uma abordagem para implementar sistemas adaptativos que aproveitem com maestria os pontos fortes de cada estratégia.
A otimização de dados de treinamento incorpora o conhecimento diretamente nos parâmetros do modelo através do fine-tuning, criando conhecimento estático que permanece fixo após o treinamento. A recuperação em tempo real mantém o conhecimento externo e busca informações relevantes dinamicamente durante a inferência, permitindo acesso a informações dinâmicas que podem mudar entre solicitações. A distinção central é quando o conhecimento é integrado: a otimização de dados de treinamento ocorre antes da implantação, enquanto a recuperação em tempo real acontece a cada chamada de inferência.
Use fine-tuning quando o conhecimento é estável e improvável de mudar com frequência, quando a latência da inferência é crítica, quando os modelos precisam operar offline ou quando estilo consistente e formatação específica de domínio são essenciais. O fine-tuning é ideal para tarefas especializadas como diagnóstico médico, análise de documentos jurídicos ou atendimento ao cliente com informações de produto estáveis. No entanto, o fine-tuning requer recursos computacionais significativos e se torna inviável quando as informações mudam frequentemente.
Sim, abordagens híbridas combinam fine-tuning e RAG para capturar os benefícios de ambas as estratégias. As organizações podem fazer fine-tuning dos modelos nos fundamentos do domínio enquanto usam RAG para acessar informações atuais e detalhadas. Essa abordagem é especialmente eficaz para aplicações que exigem tanto especialização quanto informações atualizadas, como bots de consultoria financeira ou sistemas de saúde que precisam de conhecimento médico e dados específicos de pacientes.
O RAG reduz substancialmente as alucinações ao fundamentar as respostas em documentos recuperados — o modelo não pode alegar informações que não aparecem em seu material de origem, criando restrições naturais à fabricação. Modelos fine-tuned, por outro lado, podem gerar informações plausíveis, mas incorretas, ao lidar com perguntas fora de sua distribuição de treinamento. A atribuição de fonte do RAG também permite a verificação das afirmações, enquanto modelos fine-tuned não podem apontar fontes específicas para seu conhecimento.
O fine-tuning exige custos iniciais substanciais: horas de GPU (US$10.000–US$100.000+ por modelo), anotação de dados (US$0,50–US$5 por exemplo) e tempo de engenharia. Após o treinamento, os custos de serviço permanecem relativamente baixos. Sistemas RAG têm custos iniciais menores, mas despesas contínuas de infraestrutura para bancos de dados vetoriais, modelos de embedding e serviços de recuperação. Modelos fine-tuned escalam linearmente com o volume de inferência, enquanto sistemas RAG escalam com o volume de inferência e o tamanho da base de conhecimento.
Sistemas RAG geram naturalmente citações e referências de fontes, criando uma trilha de auditoria dos documentos que influenciaram cada resposta. Isso é crucial para segurança de marca e inteligência competitiva — as organizações podem rastrear como sistemas de IA citam seus concorrentes e referenciam seus produtos. Ferramentas como AmICited.com monitoram como sistemas de IA citam marcas em diferentes estratégias de otimização, fornecendo rastreamento em tempo real de padrões e frequência de citações.
RAG é geralmente melhor para setores altamente regulados como saúde e finanças. O conhecimento permanece em fontes de dados externas e auditáveis, em vez de parâmetros do modelo, permitindo controles de segurança e restrições de acesso diretos. As organizações podem implementar permissões granulares, auditar quais documentos o modelo acessou e remover rapidamente informações sensíveis sem re-treinar. Organizações sujeitas à HIPAA e GDPR geralmente preferem a transparência e auditabilidade do RAG.
Implemente sistemas de monitoramento de IA que acompanhem as saídas do modelo, qualidade da recuperação e métricas de satisfação do usuário. Para sistemas RAG, monitore a precisão da recuperação e qualidade das citações. Para modelos fine-tuned, acompanhe a precisão em tarefas específicas e taxas de alucinação. Use ferramentas como AmICited.com para monitorar como seus sistemas de IA citam informações e compare o desempenho entre diferentes estratégias de otimização com base em resultados reais.
Acompanhe citações em tempo real em GPTs, Perplexity e Google AI Overviews. Entenda quais estratégias de otimização seus concorrentes estão usando e como eles estão sendo referenciados em respostas de IA.
Descubra a adaptação de IA em tempo real – a tecnologia que permite que sistemas de IA aprendam continuamente com eventos e dados atuais. Explore como funciona ...

Aprenda como otimizar seu conteúdo para inclusão em dados de treinamento de IA. Descubra as melhores práticas para tornar seu site descoberto pelo ChatGPT, Gemi...
Entenda a diferença entre dados de treinamento de IA e busca ao vivo. Saiba como datas de corte de conhecimento, RAG e recuperação em tempo real impactam a visi...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.