
Embedding
Saiba o que são embeddings, como funcionam e por que são essenciais para sistemas de IA. Descubra como o texto se transforma em vetores numéricos que capturam s...
13 min de leitura

Descubra como os embeddings vetoriais permitem que sistemas de IA entendam o significado semântico e façam a correspondência entre conteúdo e consultas. Explore a tecnologia por trás da busca semântica e da correspondência de conteúdo por IA.

Embeddings vetoriais são a base numérica que alimenta sistemas modernos de inteligência artificial, transformando dados brutos em representações matemáticas que as máquinas conseguem entender e processar. Em sua essência, embeddings convertem textos, imagens, áudios e outros tipos de conteúdo em arrays de números—tipicamente variando de dezenas a milhares de dimensões—que capturam o significado semântico e as relações contextuais desses dados. Essa representação numérica é fundamental para que sistemas de IA realizem tarefas de correspondência de conteúdo, busca semântica e recomendações, permitindo que as máquinas compreendam não apenas quais palavras ou imagens estão presentes, mas o que elas realmente significam. Sem embeddings, sistemas de IA teriam dificuldades para captar as relações sutis entre conceitos, tornando-os infraestrutura essencial para qualquer aplicação moderna de IA.
A transformação de dados brutos em embeddings vetoriais é realizada por modelos sofisticados de redes neurais treinados em grandes volumes de dados para aprender padrões e relações relevantes. Ao inserir um texto em um modelo de embedding, ele passa por múltiplas camadas de redes neurais que extraem progressivamente informações semânticas, produzindo ao final um vetor de tamanho fixo que representa a essência daquele conteúdo. Modelos populares de embedding como Word2Vec, GloVE e BERT adotam diferentes abordagens—o Word2Vec utiliza redes neurais rasas otimizadas para velocidade, o GloVE combina fatoração de matrizes globais com janelas de contexto local, enquanto o BERT explora arquitetura transformer para entender o contexto bidirecional.
| Modelo | Tipo de Dado | Dimensões | Principal Aplicação | Vantagem Chave |
|---|---|---|---|---|
| Word2Vec | Texto (palavras) | 100-300 | Relações entre palavras | Rápido, eficiente |
| GloVE | Texto (palavras) | 100-300 | Relações semânticas | Combina contexto global e local |
| BERT | Texto (frases/docs) | 768-1024 | Compreensão contextual | Consciência de contexto bidirecional |
| Sentence-BERT | Texto (frases) | 384-768 | Similaridade de sentenças | Otimizado para busca semântica |
| Universal Sentence Encoder | Texto (frases) | 512 | Tarefas multilíngues | Independente de idioma |
Esses modelos produzem vetores de alta dimensão (frequentemente de 300 a 1.536 dimensões), onde cada dimensão captura diferentes aspectos de significado, desde propriedades gramaticais até relações conceituais. A beleza dessa representação numérica reside na possibilidade de operações matemáticas—é possível somar, subtrair e comparar vetores para descobrir relações que seriam invisíveis em texto bruto. Essa fundação matemática é o que torna possível a busca semântica e a correspondência inteligente de conteúdo em grande escala.
O verdadeiro poder dos embeddings surge por meio da similaridade semântica, a capacidade de reconhecer que diferentes palavras ou frases podem ter essencialmente o mesmo significado no espaço vetorial. Quando embeddings são criados de forma eficaz, conceitos semanticamente similares naturalmente se agrupam no espaço de alta dimensão—“rei” e “rainha” ficam próximos, assim como “carro” e “veículo”, mesmo sendo palavras diferentes. Para medir essa similaridade, sistemas de IA utilizam métricas de distância como similaridade cosseno (medindo o ângulo entre vetores) ou produto escalar (medindo magnitude e direção), que quantificam o quão próximos dois embeddings estão entre si. Por exemplo, uma consulta sobre “transporte automotivo” terá alta similaridade cosseno com documentos sobre “viagem de carro”, permitindo que o sistema faça a correspondência baseada em significado e não apenas em coincidências de palavras-chave. Essa compreensão semântica é o que diferencia a busca moderna por IA do simples pareamento de palavras, permitindo que os sistemas entendam a intenção do usuário e entreguem resultados realmente relevantes.
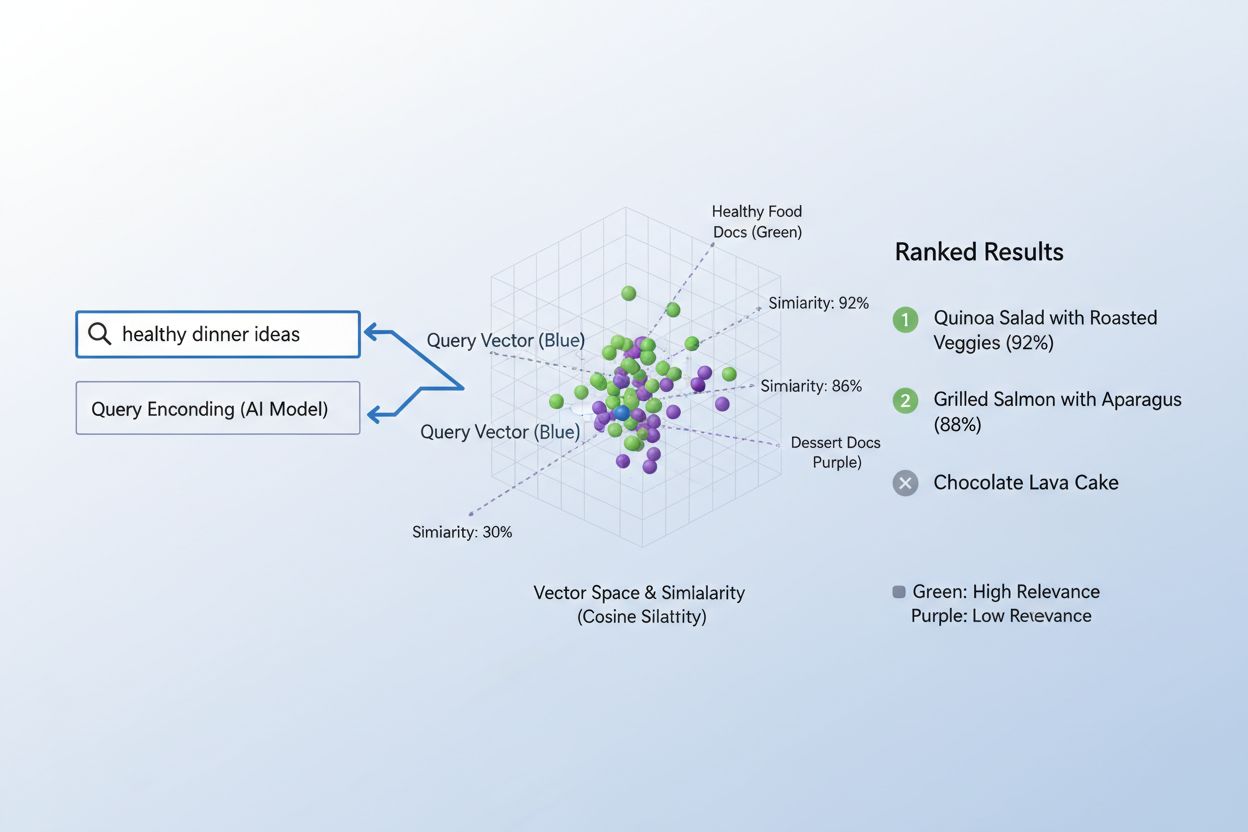
O processo de correspondência entre conteúdo e consultas usando embeddings segue um elegante fluxo de duas etapas que alimenta desde motores de busca até sistemas de recomendação. Primeiro, tanto a consulta do usuário quanto o conteúdo disponível são convertidos independentemente em embeddings usando o mesmo modelo—uma pesquisa como “melhores práticas em aprendizado de máquina” vira um vetor, assim como cada artigo, documento ou produto no banco de dados do sistema. Em seguida, o sistema calcula a similaridade entre o embedding da consulta e cada embedding de conteúdo, tipicamente usando a similaridade cosseno, o que gera uma pontuação que indica o quão relevante cada conteúdo é para aquela consulta. Essas pontuações são então ordenadas, e os conteúdos com maior pontuação aparecem ao usuário como os resultados mais relevantes. Em um cenário real de motor de busca, ao pesquisar por “como treinar redes neurais”, o sistema codifica sua consulta, compara com milhões de embeddings de documentos e retorna artigos sobre deep learning, otimização de modelos e técnicas de treinamento—tudo sem exigir coincidências exatas de palavras-chave. Esse processo de correspondência acontece em milissegundos, tornando-o viável para aplicações em tempo real que atendem milhões de usuários simultaneamente.
Diferentes tipos de embeddings servem a propósitos distintos dependendo do que se deseja comparar ou compreender. Embeddings de palavras capturam o significado de termos individuais e funcionam bem para tarefas que exigem compreensão semântica detalhada, enquanto embeddings de frases e embeddings de documentos agregam significado ao longo de trechos maiores de texto, sendo ideais para corresponder consultas completas a artigos ou documentos inteiros. Embeddings de imagens representam visualmente conteúdos de forma numérica, permitindo que sistemas encontrem imagens semelhantes ou façam correspondência entre imagens e descrições textuais, enquanto embeddings de usuários e de produtos capturam padrões comportamentais e características, alimentando sistemas de recomendação que sugerem itens com base em preferências do usuário. A escolha entre esses tipos envolve compensações: embeddings de palavras são computacionalmente eficientes mas perdem contexto, enquanto embeddings de documentos preservam o significado completo mas exigem mais processamento. Embeddings específicos de domínio, ajustados em conjuntos de dados como literatura médica ou documentos jurídicos, geralmente superam modelos genéricos em aplicações especializadas, embora exijam dados de treinamento adicionais e mais recursos computacionais.
Na prática, embeddings alimentam algumas das aplicações de IA mais impactantes do nosso dia a dia, desde os resultados de busca que você vê até os produtos recomendados online. Motores de busca semânticos usam embeddings para entender a intenção da consulta e apresentar conteúdos relevantes independentemente da correspondência exata de palavras, enquanto sistemas de recomendação na Netflix, Amazon e Spotify aproveitam embeddings de usuários e itens para prever o que você vai querer assistir, comprar ou ouvir em seguida. Sistemas de moderação de conteúdo utilizam embeddings para detectar conteúdos prejudiciais ao comparar postagens de usuários com embeddings de violações de políticas conhecidas, enquanto sistemas de perguntas e respostas associam questões dos usuários a artigos relevantes de bases de conhecimento buscando conteúdos semanticamente similares. Motores de personalização usam embeddings para entender preferências dos usuários e ajustar experiências, e sistemas de detecção de anomalias identificam padrões incomuns reconhecendo quando novos dados se afastam de clusters de embeddings esperados. No AmICited, utilizamos embeddings para monitorar como sistemas de IA estão sendo usados na internet, relacionando consultas e conteúdos para rastrear onde conteúdo gerado ou assistido por IA aparece, ajudando marcas a entender sua presença em IA e garantir a devida atribuição.
Implementar embeddings de forma eficaz requer atenção a diversas considerações técnicas que afetam desempenho e custo. A escolha do modelo é crítica—é necessário equilibrar a qualidade semântica dos embeddings com os requisitos computacionais, já que modelos maiores como BERT produzem representações mais ricas mas demandam mais processamento que alternativas mais leves. A dimensionalidade representa um dilema: embeddings de maior dimensão capturam mais nuances mas consomem mais memória e tornam os cálculos de similaridade mais lentos, enquanto embeddings de menor dimensão são mais rápidos mas podem perder informações semânticas importantes. Para lidar com a correspondência em larga escala de forma eficiente, sistemas utilizam estratégias especializadas de indexação como FAISS (Facebook AI Similarity Search) ou Annoy (Approximate Nearest Neighbors Oh Yeah), que permitem encontrar embeddings similares em milissegundos organizando vetores em estruturas de árvore ou esquemas de hashing sensíveis à localidade. O ajuste fino de modelos de embedding em dados específicos de domínio pode melhorar drasticamente a relevância para aplicações especializadas, embora exija dados rotulados e mais recursos computacionais. Organizações precisam equilibrar continuamente velocidade versus precisão, custo computacional versus qualidade semântica e modelos genéricos versus especializados de acordo com seus casos de uso e restrições específicos.
O futuro dos embeddings aponta para maior sofisticação, eficiência e integração com sistemas de IA mais amplos, prometendo capacidades ainda mais poderosas de correspondência e compreensão de conteúdo. Embeddings multimodais que processam simultaneamente texto, imagens e áudio estão surgindo, permitindo que sistemas façam correspondência entre diferentes tipos de conteúdo—encontrando imagens relevantes para consultas em texto ou vice-versa—abrindo possibilidades inéditas de descoberta e compreensão de conteúdo. Pesquisadores estão desenvolvendo modelos de embedding cada vez mais eficientes, que entregam qualidade semântica comparável com bem menos parâmetros, tornando capacidades avançadas de IA acessíveis a organizações menores e dispositivos de borda. A integração de embeddings com grandes modelos de linguagem está criando sistemas capazes não apenas de corresponder conteúdos semanticamente, mas também de entender contexto, nuances e intenção em níveis sem precedentes. À medida que sistemas de IA se tornam mais prevalentes na internet, a capacidade de rastrear, monitorar e entender como o conteúdo está sendo correspondido e utilizado ganha importância crescente—é aqui que plataformas como o AmICited utilizam embeddings para ajudar organizações a monitorar a presença de suas marcas, rastrear padrões de uso de IA e garantir que seu conteúdo seja devidamente atribuído e utilizado de forma apropriada. A convergência de embeddings melhores, modelos mais eficientes e ferramentas sofisticadas de monitoramento está criando um futuro em que sistemas de IA são mais transparentes, responsáveis e alinhados com valores humanos.
Um embedding vetorial é uma representação numérica de dados (texto, imagens, áudio) em um espaço de alta dimensionalidade que captura significado semântico e relações. Ele converte dados abstratos em arrays de números que as máquinas podem processar e analisar matematicamente.
Os embeddings convertem dados abstratos em números que as máquinas podem processar, permitindo que a IA identifique padrões, similaridades e relações entre diferentes conteúdos. Essa representação matemática possibilita que sistemas de IA entendam o significado e não apenas correspondam palavras-chave.
A correspondência de palavras-chave busca por coincidências exatas, enquanto a similaridade semântica entende o significado. Isso permite que sistemas encontrem conteúdos relacionados mesmo sem palavras idênticas—por exemplo, relacionando 'automóvel' com 'carro' baseado na relação semântica e não apenas na correspondência textual exata.
Sim, embeddings podem representar texto, imagens, áudio, perfis de usuários, produtos e mais. Diferentes modelos de embedding são otimizados para diferentes tipos de dados, do Word2Vec para texto ao CNN para imagens e espectrogramas para áudio.
O AmICited utiliza embeddings para entender como sistemas de IA fazem a correspondência semântica e referenciam sua marca em diferentes plataformas e respostas de IA. Isso ajuda a rastrear a presença do seu conteúdo em respostas geradas por IA e garantir a devida atribuição.
Os principais desafios incluem a escolha do modelo correto, gerenciamento de custos computacionais, tratamento de dados de alta dimensionalidade, ajuste fino para domínios específicos e o equilíbrio entre velocidade e precisão nos cálculos de similaridade.
Os embeddings possibilitam a busca semântica, que entende a intenção do usuário e retorna resultados relevantes baseados no significado, não apenas em palavras-chave. Isso permite que sistemas de busca encontrem conteúdos conceitualmente relacionados mesmo que não contenham os termos exatos da consulta.
Grandes modelos de linguagem usam embeddings internamente para entender e gerar texto. Os embeddings são fundamentais para o processamento de informações, correspondência de conteúdo e geração de respostas contextualmente apropriadas por esses modelos.
Embeddings vetoriais alimentam sistemas de IA como ChatGPT, Perplexity e Google AI Overviews. O AmICited rastreia como esses sistemas citam e referenciam seu conteúdo, ajudando você a entender a presença da sua marca em respostas geradas por IA.
Saiba o que são embeddings, como funcionam e por que são essenciais para sistemas de IA. Descubra como o texto se transforma em vetores numéricos que capturam s...

Aprenda como funcionam os embeddings em mecanismos de busca por IA e modelos de linguagem. Entenda representações vetoriais, busca semântica e o papel delas nas...
Saiba como a busca vetorial utiliza embeddings de aprendizado de máquina para encontrar itens semelhantes com base no significado, em vez de palavras-chave exat...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.