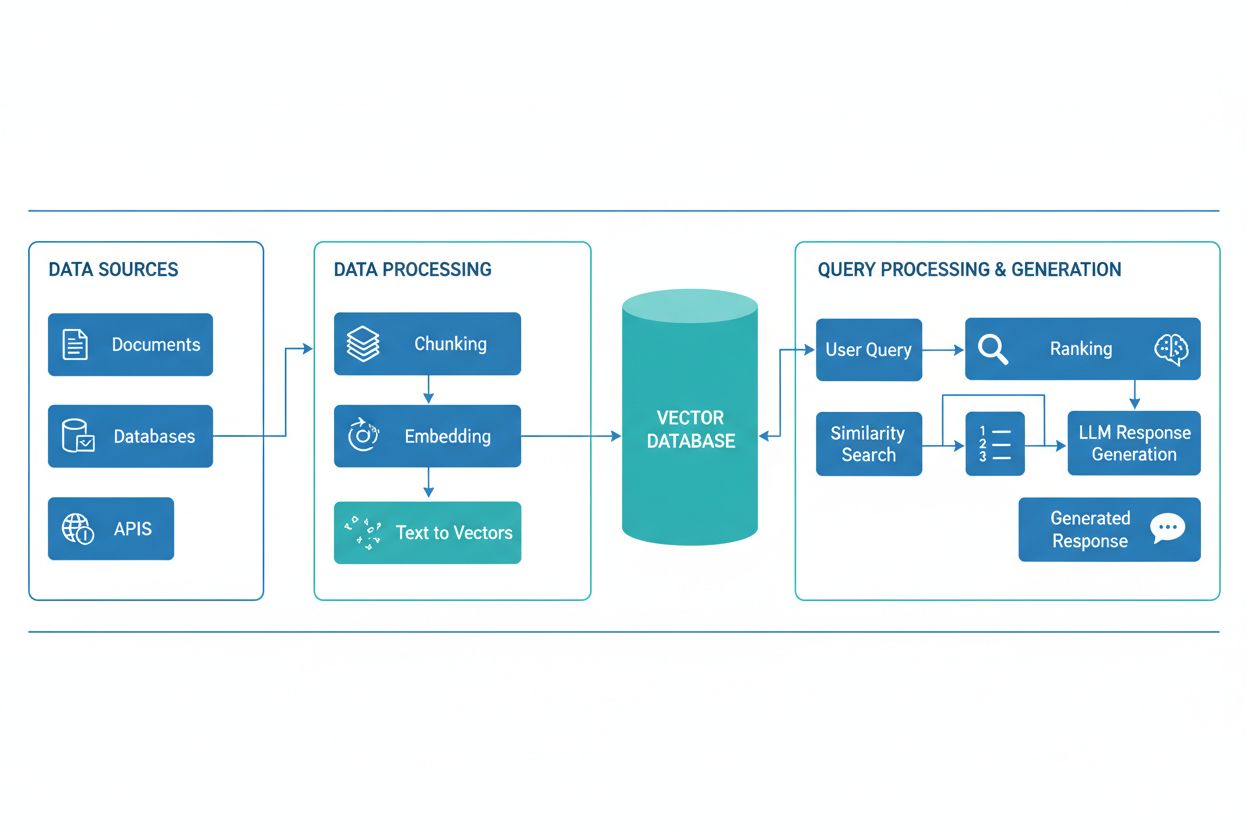
Um pipeline de Geração Aumentada por Recuperação (RAG) é um fluxo de trabalho que permite a sistemas de IA encontrar, ranquear e citar fontes externas ao gerar respostas. Ele combina recuperação de documentos, ranqueamento semântico e geração por LLM para fornecer respostas precisas e contextualmente relevantes, fundamentadas em dados reais. Sistemas RAG reduzem alucinações ao consultar bases de conhecimento externas antes de produzir respostas, tornando-se essenciais para aplicações que exigem precisão factual e atribuição de fontes.
Pipeline RAG
Um pipeline de Geração Aumentada por Recuperação (RAG) é um fluxo de trabalho que permite a sistemas de IA encontrar, ranquear e citar fontes externas ao gerar respostas. Ele combina recuperação de documentos, ranqueamento semântico e geração por LLM para fornecer respostas precisas e contextualmente relevantes, fundamentadas em dados reais. Sistemas RAG reduzem alucinações ao consultar bases de conhecimento externas antes de produzir respostas, tornando-se essenciais para aplicações que exigem precisão factual e atribuição de fontes.
O que é um Pipeline RAG?
Um pipeline de Geração Aumentada por Recuperação (RAG) é uma arquitetura de IA que combina recuperação de informações com geração por grandes modelos de linguagem (LLM) para produzir respostas mais precisas, relevantes ao contexto e verificáveis. Em vez de depender apenas dos dados de treinamento do LLM, sistemas RAG buscam dinamicamente documentos ou dados relevantes em bases de conhecimento externas antes de gerar respostas, reduzindo significativamente alucinações e melhorando a precisão factual. O pipeline atua como uma ponte entre dados de treinamento estáticos e informações em tempo real, permitindo que sistemas de IA referenciem conteúdos atuais, específicos de domínio ou proprietários. Essa abordagem tornou-se essencial para organizações que exigem respostas fundamentadas em citações, conformidade com padrões de precisão e transparência em conteúdos gerados por IA. Pipelines RAG são especialmente valiosos no monitoramento de sistemas de IA, onde rastreabilidade e atribuição de fontes são requisitos críticos.
Componentes Centrais
Um pipeline RAG é composto por diversos componentes interconectados que trabalham juntos para recuperar informações relevantes e gerar respostas fundamentadas. A arquitetura normalmente inclui uma camada de ingestão de documentos que processa e prepara dados brutos, um banco de dados vetorial ou base de conhecimento que armazena embeddings e conteúdo indexado, um mecanismo de recuperação que identifica documentos relevantes com base em consultas dos usuários, um sistema de ranqueamento que prioriza os resultados mais pertinentes e um módulo de geração, alimentado por um LLM, que sintetiza as informações recuperadas em respostas coerentes. Componentes adicionais incluem módulos de processamento e pré-processamento de consultas, que normalizam a entrada dos usuários, modelos de embedding que convertem texto em representações numéricas e um ciclo de feedback que aprimora continuamente a precisão da recuperação. A orquestração desses componentes determina a eficácia e eficiência geral do sistema RAG.
Componente
Função
Principais Tecnologias
Ingestão de Documentos
Processamento e preparação de dados brutos
Apache Kafka, LangChain, Unstructured
Banco de Dados Vetorial
Armazenamento de embeddings e conteúdo indexado
Pinecone, Weaviate, Milvus, Qdrant
Mecanismo de Recuperação
Identificação de documentos relevantes
BM25, Dense Passage Retrieval (DPR)
Sistema de Ranqueamento
Priorização dos resultados da busca
Cross-encoders, reranqueamento com LLM
Módulo de Geração
Síntese de respostas a partir do contexto
GPT-4, Claude, Llama, Mistral
Processador de Consulta
Normalização e compreensão da entrada do usuário
BERT, T5, pipelines NLP customizadas
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
O pipeline RAG opera por meio de duas fases distintas: a fase de recuperação e a fase de geração. Durante a fase de recuperação, o sistema converte a consulta do usuário em um embedding usando o mesmo modelo de embedding que processou os documentos da base de conhecimento, depois busca no banco de dados vetorial os documentos ou passagens semanticamente mais semelhantes. Essa fase normalmente retorna uma lista ranqueada de documentos candidatos, que pode ser refinada ainda mais por algoritmos de reranqueamento que utilizam cross-encoders ou pontuação baseada em LLM para garantir relevância. Na fase de geração, os documentos recuperados com melhor pontuação são formatados em uma janela de contexto e passados ao LLM juntamente com a consulta original, permitindo que o modelo gere respostas fundamentadas em fontes reais. Essa abordagem em duas fases garante que as respostas sejam apropriadas ao contexto e rastreáveis a fontes específicas, tornando-a ideal para aplicações que exigem citação e responsabilidade. A qualidade do resultado final depende criticamente tanto da relevância dos documentos recuperados quanto da capacidade do LLM de sintetizar informações de forma coerente.
Principais Tecnologias e Ferramentas
O ecossistema RAG abrange uma variedade de ferramentas e frameworks especializados projetados para simplificar a construção e implantação de pipelines. Implementações modernas de RAG utilizam várias categorias de tecnologia:
Frameworks de Orquestração: LangChain, LlamaIndex (antigo GPT Index) e Haystack oferecem camadas de abstração para construção de fluxos RAG sem gerenciar cada componente individualmente
Bancos de Dados Vetoriais: Pinecone, Weaviate, Milvus, Qdrant e Chroma oferecem armazenamento escalável e recuperação de embeddings de alta dimensão com latências de consulta de sub-milissegundos
Modelos de Embedding: text-embedding-3 da OpenAI, Embed API da Cohere e modelos open-source como all-MiniLM-L6-v2 convertem texto em representações semânticas
Provedores de LLM: OpenAI (GPT-4), Anthropic (Claude), Meta (Llama) e Mistral oferecem diferentes tamanhos e capacidades de modelos para tarefas de geração
Soluções de Reranqueamento: Rerank API da Cohere, modelos cross-encoder da Hugging Face e reranqueadores proprietários baseados em LLM melhoram a precisão da recuperação
Ferramentas de Preparação de Dados: Unstructured, Apache Kafka e pipelines ETL customizados lidam com ingestão, divisão e pré-processamento de documentos
Monitoramento e Avaliação: Ferramentas como Ragas, TruLens e frameworks de avaliação customizados analisam o desempenho do sistema RAG e identificam modos de falha
Essas ferramentas podem ser combinadas de maneira modular, permitindo que organizações construam sistemas RAG adaptados a seus requisitos específicos e restrições de infraestrutura.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Mecanismos de Recuperação
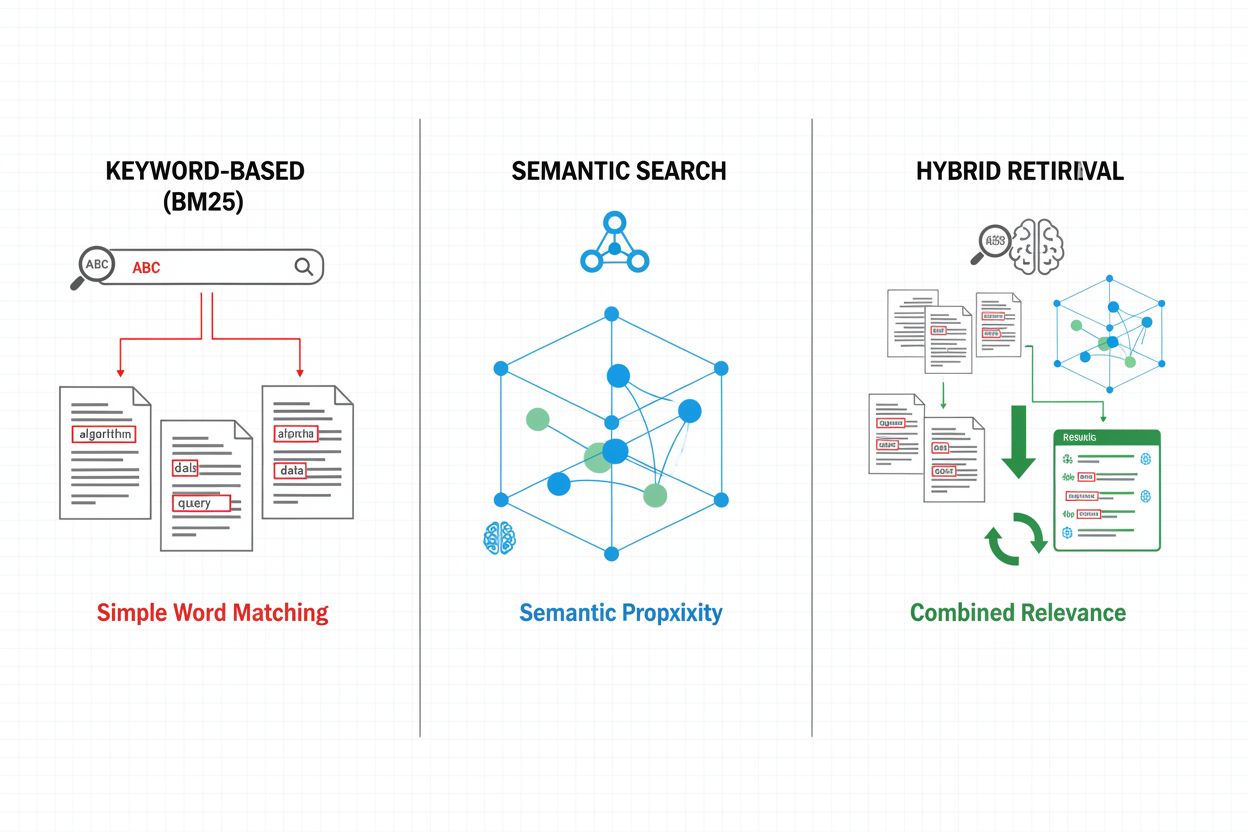
Mecanismos de recuperação formam a base da eficácia do pipeline RAG, evoluindo de abordagens simples baseadas em palavras-chave para métodos sofisticados de busca semântica. A recuperação tradicional baseada em palavras-chave, usando algoritmos BM25, permanece eficiente e eficaz para cenários de correspondência exata, mas tem dificuldades com compreensão semântica e sinonímia. Dense Passage Retrieval (DPR) e outros métodos neurais de recuperação abordam essas limitações ao codificar tanto consultas quanto documentos em embeddings vetoriais densos, permitindo correspondência semântica que captura significado além das palavras-chave superficiais. Abordagens híbridas de recuperação combinam busca por palavras-chave e busca semântica, aproveitando os pontos fortes de ambos os métodos para melhorar recall e precisão em diferentes tipos de consulta. Mecanismos avançados de recuperação incorporam expansão de consulta, em que a consulta original é ampliada com termos relacionados ou reformulações para capturar documentos mais relevantes. Camadas de reranqueamento refinam ainda mais os resultados ao aplicar modelos mais custosos computacionalmente que pontuam documentos candidatos com base em compreensão semântica mais profunda ou critérios de relevância específicos de tarefa. A escolha do mecanismo de recuperação impacta significativamente tanto a precisão do contexto recuperado quanto o custo computacional do pipeline RAG, exigindo consideração cuidadosa dos trade-offs entre velocidade e qualidade.
Benefícios dos Pipelines RAG
Pipelines RAG oferecem vantagens substanciais em relação a abordagens baseadas apenas em LLM, especialmente para aplicações que exigem precisão, atualidade e rastreabilidade. Ao fundamentar respostas em documentos recuperados, sistemas RAG reduzem drasticamente alucinações—situações em que LLMs geram informações plausíveis, mas incorretas—tornando-os adequados para domínios críticos como saúde, jurídico e serviços financeiros. A capacidade de referenciar bases de conhecimento externas permite que sistemas RAG forneçam informações atuais sem retreinar modelos, permitindo que organizações mantenham respostas atualizadas à medida que surgem novas informações. Pipelines RAG suportam customização específica de domínio ao incorporar documentos proprietários, bases de conhecimento internas e terminologia especializada, possibilitando respostas mais relevantes e apropriadas ao contexto. O componente de recuperação fornece transparência e auditabilidade ao mostrar explicitamente quais fontes informaram cada resposta, fundamental para requisitos de conformidade e confiança do usuário. A eficiência de custos melhora com o uso de LLMs menores e mais eficientes, que podem gerar respostas de alta qualidade quando recebem contexto relevante, reduzindo a sobrecarga computacional em comparação com modelos maiores. Esses benefícios tornam o RAG especialmente valioso para organizações que implementam sistemas de monitoramento de IA, onde precisão de citação e visibilidade de conteúdo são essenciais.
Desafios e Limitações
Apesar das vantagens, pipelines RAG enfrentam diversos desafios técnicos e operacionais que exigem gestão cuidadosa. A qualidade dos documentos recuperados determina diretamente a qualidade das respostas, tornando erros de recuperação difíceis de corrigir—um fenômeno conhecido como “garbage in, garbage out”, em que documentos irrelevantes ou desatualizados na base de conhecimento se propagam até as respostas finais. Modelos de embedding podem ter dificuldade com terminologia específica de domínio, idiomas raros ou conteúdo altamente técnico, levando a correspondência semântica deficiente e perda de documentos relevantes. O custo computacional de recuperação, geração de embeddings e reranqueamento pode ser substancial em escala, especialmente ao processar grandes bases de conhecimento ou lidar com alto volume de consultas. Limitações de janela de contexto nos LLMs restringem a quantidade de informação recuperada que pode ser incorporada aos prompts, exigindo seleção e sumarização cuidadosa de passagens relevantes. Manter a atualização e consistência da base de conhecimento apresenta desafios operacionais, especialmente em ambientes dinâmicos, onde as informações mudam frequentemente ou vêm de múltiplas fontes. Avaliar o desempenho do sistema RAG requer métricas abrangentes além das tradicionais, incluindo precisão da recuperação, relevância das respostas e correção das citações, o que pode ser difícil de medir automaticamente.
RAG vs. Outras Abordagens
RAG representa uma das estratégias para melhorar a precisão e relevância dos LLMs, cada uma com seus próprios trade-offs. Fine-tuning envolve retreinar LLMs com dados específicos de domínio, proporcionando personalização profunda do modelo, mas exigindo recursos computacionais elevados, dados rotulados e manutenção contínua à medida que as informações mudam. Engenharia de prompts otimiza instruções e contexto fornecidos ao LLM sem modificar seus pesos, oferecendo flexibilidade e baixo custo, mas limitada pelos dados de treinamento do modelo e tamanho da janela de contexto. Aprendizagem em contexto utiliza exemplos (few-shot) dentro dos prompts para guiar o comportamento do modelo, proporcionando adaptação rápida, mas consumindo tokens valiosos de contexto e exigindo seleção criteriosa dos exemplos. Em comparação, RAG oferece um meio-termo: acesso dinâmico a informações atuais sem retreinamento, manutenção de transparência via atribuição explícita de fontes e escalabilidade eficiente em diversos domínios de conhecimento. No entanto, RAG introduz complexidade adicional via infraestrutura de recuperação e possíveis erros de recuperação, enquanto o fine-tuning integra mais profundamente o conhecimento de domínio ao comportamento do modelo. A abordagem ideal frequentemente combina várias estratégias—por exemplo, RAG com modelos ajustados por fine-tuning e prompts cuidadosamente elaborados—para maximizar precisão e relevância em casos de uso específicos.
Construção e Implantação de RAG
Implementar um pipeline RAG em produção requer planejamento sistemático em preparação de dados, design de arquitetura e considerações operacionais. O processo começa com a preparação da base de conhecimento: coleta de documentos relevantes, limpeza e padronização de formatos e divisão do conteúdo em blocos de tamanho apropriado que equilibrem preservação de contexto com precisão na recuperação. Em seguida, organizações selecionam modelos de embedding e bancos de dados vetoriais conforme requisitos de desempenho, restrições de latência e necessidades de escalabilidade, considerando fatores como dimensionalidade dos embeddings, throughput de consulta e capacidade de armazenamento. O sistema de recuperação é então configurado, incluindo decisões sobre algoritmos de recuperação (palavra-chave, semântica ou híbrida), estratégias de reranqueamento e critérios de filtragem de resultados. A integração com provedores de LLM segue, estabelecendo conexões com modelos de geração e definindo templates de prompts que incorporem o contexto recuperado de forma eficaz. Testes e avaliação são críticos, exigindo métricas para qualidade da recuperação (precisão, recall, MRR), qualidade da geração (relevância, coerência, factualidade) e desempenho de ponta a ponta do sistema. Considerações de implantação incluem monitoramento da precisão da recuperação e qualidade da geração, implementação de ciclos de feedback para identificar e tratar modos de falha e estabelecimento de processos para atualização e manutenção da base de conhecimento. Por fim, a otimização contínua envolve análise das interações dos usuários, identificação de padrões comuns de falha e melhoria iterativa dos mecanismos de recuperação, estratégias de reranqueamento e engenharia de prompts para aprimorar o desempenho do sistema como um todo.
RAG em Monitoramento e Citação em IA
Pipelines RAG são fundamentais para plataformas modernas de monitoramento de IA, como o AmICited.com, onde rastrear as fontes e precisão do conteúdo gerado por IA é essencial. Ao recuperar e citar documentos-fonte de forma explícita, sistemas RAG criam uma trilha auditável que permite às plataformas de monitoramento verificar afirmações, avaliar precisão factual e identificar possíveis alucinações ou atribuições incorretas. Essa capacidade de citação aborda uma lacuna crítica em transparência de IA: usuários e auditores podem rastrear respostas até as fontes originais, permitindo verificação independente e construindo confiança no conteúdo gerado por IA. Para criadores de conteúdo e organizações que usam ferramentas de IA, o monitoramento habilitado por RAG oferece visibilidade sobre quais fontes informaram respostas específicas, apoiando conformidade com requisitos de atribuição e políticas de governança de conteúdo. O componente de recuperação dos pipelines RAG gera metadados ricos—including pontuações de relevância, ranqueamentos de documentos e métricas de confiança na recuperação—que sistemas de monitoramento podem analisar para avaliar a confiabilidade das respostas e identificar quando sistemas de IA estão operando fora de seus domínios de conhecimento. A integração do RAG com plataformas de monitoramento permite detectar deriva de citações, quando sistemas de IA gradualmente se afastam de fontes autoritativas para outras menos confiáveis, e apoia a aplicação de políticas de conteúdo sobre qualidade e diversidade de fontes. À medida que sistemas de IA se integram a fluxos de trabalho críticos, a combinação de pipelines RAG com monitoramento abrangente cria mecanismos de accountability que protegem usuários, organizações e o ecossistema de informação mais amplo contra desinformação gerada por IA.
Perguntas frequentes
Qual é a diferença entre RAG e fine-tuning?
RAG e fine-tuning são abordagens complementares para melhorar o desempenho de LLMs. RAG recupera documentos externos no momento da consulta sem modificar o modelo, permitindo acesso a dados em tempo real e atualizações fáceis. O fine-tuning retreina o modelo com dados específicos de domínio, proporcionando personalização mais profunda, mas exigindo muitos recursos computacionais e atualizações manuais quando as informações mudam. Muitas organizações utilizam ambas as técnicas juntas para obter melhores resultados.
Como o RAG reduz alucinações nas respostas de IA?
O RAG reduz alucinações ao fundamentar as respostas do LLM em documentos factuais recuperados. Em vez de confiar apenas nos dados de treinamento, o sistema busca fontes relevantes antes da geração, fornecendo ao modelo evidências concretas para referência. Essa abordagem garante que as respostas sejam baseadas em informações reais e não em padrões aprendidos pelo modelo, melhorando significativamente a precisão factual e reduzindo afirmações falsas ou enganosas.
O que são embeddings vetoriais e por que são importantes no RAG?
Embeddings vetoriais são representações numéricas de texto que capturam significado semântico em um espaço multidimensional. Eles permitem que sistemas RAG realizem buscas semânticas, encontrando documentos com significado semelhante, mesmo que usem palavras diferentes. Embeddings são cruciais porque permitem que o RAG vá além da correspondência por palavras-chave para entender relações conceituais, melhorando a relevância da recuperação e possibilitando geração de respostas mais precisas.
Pipelines RAG funcionam com dados em tempo real?
Sim, pipelines RAG podem incorporar dados em tempo real por meio de processos contínuos de ingestão e indexação. Organizações podem configurar pipelines automatizados que atualizam regularmente o banco de dados vetorial com novos documentos, mantendo a base de conhecimento atualizada. Essa capacidade torna o RAG ideal para aplicações que exigem informações atualizadas, como análise de notícias, inteligência de preços e monitoramento de mercado, sem a necessidade de retreinar o LLM subjacente.
Qual é a diferença entre busca semântica e RAG?
Busca semântica é uma técnica de recuperação que encontra documentos com base na similaridade de significado usando embeddings vetoriais. RAG é um pipeline completo que combina busca semântica com geração por LLM para produzir respostas fundamentadas em documentos recuperados. Enquanto a busca semântica foca em encontrar informações relevantes, o RAG adiciona o componente de geração que sintetiza o conteúdo recuperado em respostas coerentes com citações.
Como sistemas RAG decidem quais fontes citar?
Sistemas RAG usam vários mecanismos para selecionar fontes a serem citadas. Eles empregam algoritmos de recuperação para encontrar documentos relevantes, modelos de reranqueamento para priorizar os resultados mais pertinentes e processos de verificação para garantir que as citações realmente apoiem as afirmações feitas. Alguns sistemas utilizam abordagens de 'citar enquanto escreve', em que afirmações só são feitas se houver suporte das fontes recuperadas, enquanto outros verificam as citações após a geração e removem afirmações não suportadas.
Quais são os principais desafios na construção de pipelines RAG?
Os principais desafios incluem manter a atualização e qualidade da base de conhecimento, otimizar a precisão da recuperação em diferentes tipos de conteúdo, gerenciar custos computacionais em escala, lidar com terminologia específica de domínio que modelos de embedding podem não compreender bem e avaliar o desempenho do sistema com métricas abrangentes. As organizações também devem considerar as limitações de janela de contexto dos LLMs e garantir que os documentos recuperados permaneçam relevantes à medida que as informações evoluem.
Como o AmICited monitora citações RAG em sistemas de IA?
O AmICited acompanha como sistemas de IA como ChatGPT, Perplexity e Google AI Overviews recuperam e citam conteúdos via pipelines RAG. A plataforma monitora quais fontes são selecionadas para citação, com que frequência sua marca aparece em respostas de IA e se as citações são precisas. Essa visibilidade ajuda organizações a entenderem sua presença em buscas mediadas por IA e garantir a atribuição correta de seus conteúdos.
Monitore Sua Marca em Respostas de IA
Acompanhe como sistemas de IA como ChatGPT, Perplexity e Google AI Overviews referenciam seu conteúdo. Obtenha visibilidade sobre citações RAG e monitoramento de respostas de IA.
O que é RAG na Pesquisa em IA: Guia Completo sobre Geração Aumentada por Recuperação
Descubra o que é RAG (Geração Aumentada por Recuperação) na pesquisa em IA. Saiba como o RAG melhora a precisão, reduz alucinações e impulsiona o ChatGPT, Perpl...
Como Funciona a Geração Aumentada por Recuperação: Arquitetura e Processo
Descubra como o RAG combina LLMs com fontes externas de dados para gerar respostas de IA precisas. Entenda o processo de cinco etapas, componentes e por que iss...
Saiba o que é a Geração Aumentada por Recuperação (RAG), como funciona e por que é essencial para respostas precisas de IA. Explore a arquitetura, benefícios e ...
13 min de leitura
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.