
Ar trebui să blocați sau să permiteți crawlerii AI? Cadru decizional
Aflați cum să luați decizii strategice despre blocarea crawlerilor AI. Evaluați tipul de conținut, sursele de trafic, modelele de venituri și poziția competitiv...
12 min citire

Află cum crawlerii AI influențează resursele serverului, lățimea de bandă și performanța. Descoperă statistici reale, strategii de reducere și soluții de infrastructură pentru gestionarea eficientă a încărcării generate de boți.
Crawlerii AI au devenit o forță semnificativă în traficul web, marile companii de inteligență artificială implementând boți sofisticați pentru a indexa conținutul în scop de antrenament și regăsire. Acești crawlerei operează la scară masivă, generând aproximativ 569 de milioane de cereri pe lună la nivel global și consumând peste 30TB de lățime de bandă. Principalii crawlerei AI includ GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (Google) și Amazonbot (Amazon), fiecare având modele de crawling și cerințe de resurse distincte. Înțelegerea comportamentului și caracteristicilor acestor crawlere este esențială pentru administratorii de site-uri pentru a gestiona corespunzător resursele serverului și a lua decizii informate despre politicile de acces.
| Nume Crawler | Companie | Scop | Model de cereri |
|---|---|---|---|
| GPTBot | OpenAI | Date de antrenament pentru ChatGPT și modelele GPT | Cereri agresive, cu frecvență ridicată |
| ClaudeBot | Anthropic | Date de antrenament pentru modelele Claude AI | Frecvență moderată, crawling respectuos |
| PerplexityBot | Perplexity AI | Căutare în timp real și generare de răspunsuri | Frecvență moderată spre mare |
| Google-Extended | Indexare extinsă pentru funcții AI | Controlat, respectă robots.txt | |
| Amazonbot | Amazon | Indexare de produse și conținut | Variabil, axat pe comerț |
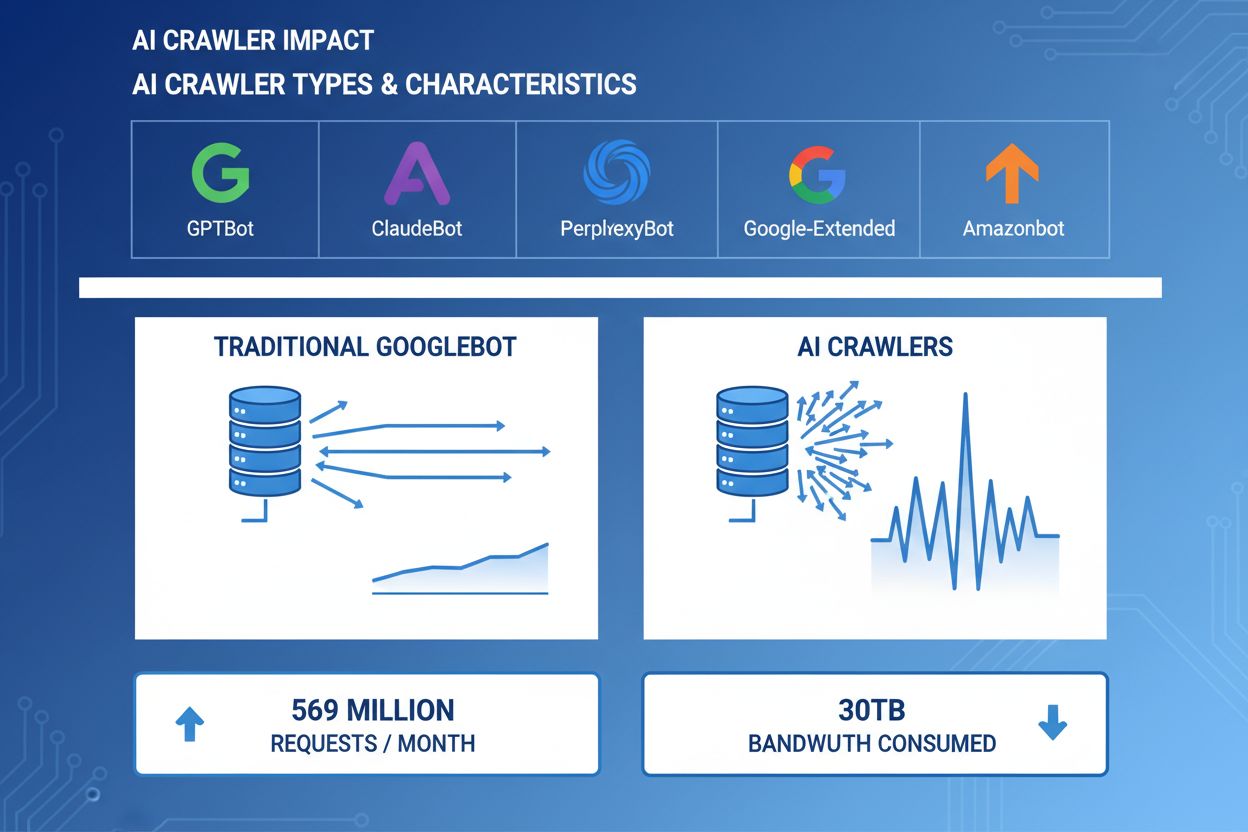
Crawlerii AI consumă resursele serverului pe mai multe planuri, generând impacturi măsurabile asupra performanței infrastructurii. Utilizarea CPU poate crește cu peste 300% în timpul activității intense a crawlerilor, deoarece serverele procesează mii de cereri simultane și parsează conținut HTML. Consumul de lățime de bandă reprezintă unul dintre cele mai vizibile costuri, un singur site popular putând servi zilnic gigabytes de date crawlerilor. Utilizarea memoriei crește semnificativ deoarece serverele mențin pool-uri de conexiuni și buffer-ează cantități mari de date pentru procesare. Numărul interogărilor către baza de date se multiplică pe măsură ce crawlerii solicită pagini ce generează conținut dinamic, creând presiune suplimentară pe I/O. I/O-ul de disc devine un blocaj atunci când serverele trebuie să citească din stocare pentru a răspunde cererilor crawlerilor, în special pentru site-urile cu biblioteci mari de conținut.
| Resursă | Impact | Exemplu real |
|---|---|---|
| CPU | Creșteri de 200-300% în timpul crawlingului intens | Media încărcării serverului crește de la 2.0 la 8.0 |
| Lățime de bandă | 15-40% din consumul lunar total | Site de 500GB servind 150GB lunar crawlerilor |
| Memorie | Creștere de 20-30% a consumului de RAM | Server de 8GB necesitând 10GB în timpul activității crawlerilor |
| Bază de date | Creștere de 2-5x a încărcării cu interogări | Timpul de răspuns la interogări crește de la 50ms la 250ms |
| I/O disc | Operațiuni de citire susținute la nivel înalt | Utilizarea discului crește de la 30% la 85% |
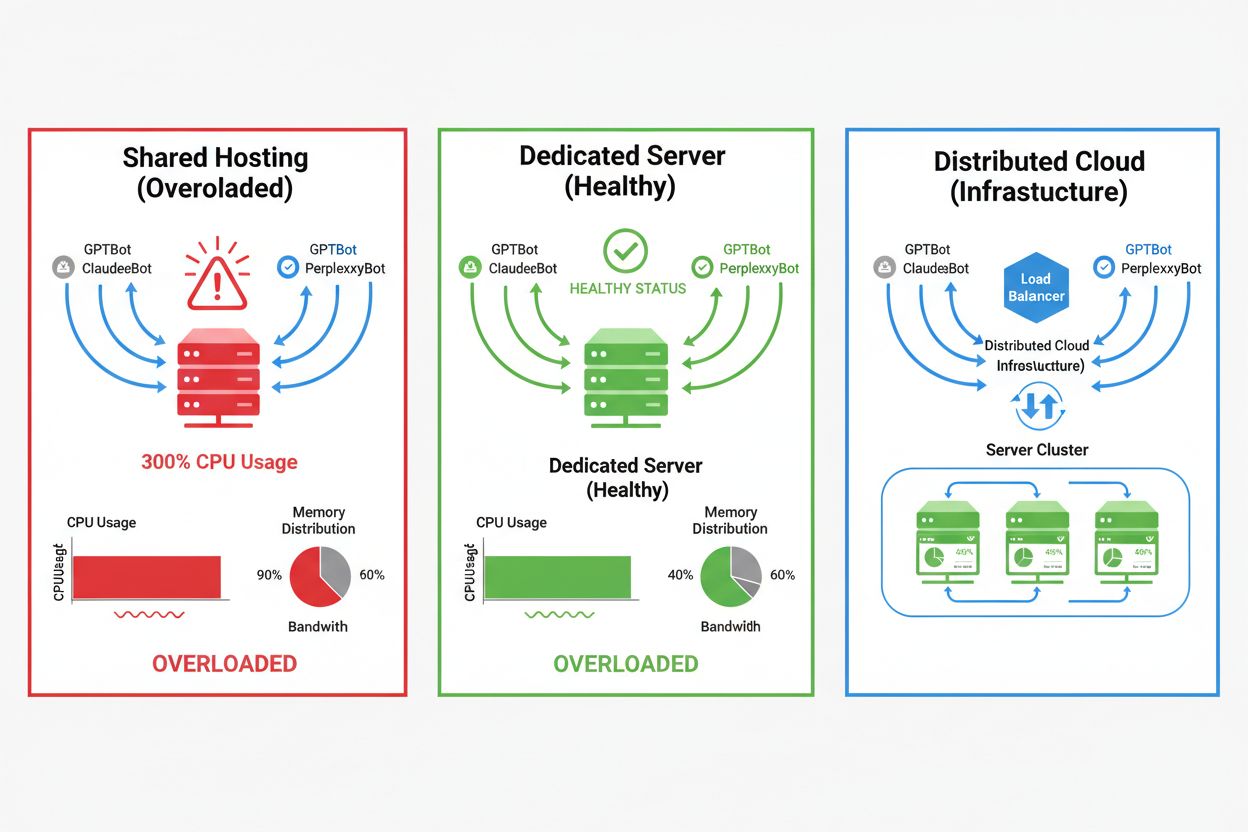
Impactul crawlerilor AI variază dramatic în funcție de mediul tău de hosting, mediile de hosting partajat fiind cele mai afectate. În scenariile de hosting partajat, „sindromul vecinului gălăgios” devine extrem de problematic—când un site de pe un server partajat atrage trafic intens de la crawlere, acesta consumă resurse ce ar fi disponibile altor site-uri găzduite, degradând performanța pentru toți utilizatorii. Serverele dedicate și infrastructura cloud oferă o izolare mai bună și garanții de resurse, permițând absorbția traficului de la crawlere fără a afecta alte servicii. Totuși, chiar și infrastructura dedicată necesită monitorizare și scalare atentă pentru a face față încărcării cumulative generate de mai mulți crawlerei AI care operează simultan.
Diferențe cheie între mediile de hosting:
Impactul financiar al traficului crawlerilor AI depășește costurile simple de lățime de bandă, incluzând atât cheltuieli directe cât și ascunse ce pot influența semnificativ profitabilitatea. Costurile directe includ taxe suplimentare de lățime de bandă de la furnizorul tău de hosting, care pot adăuga sute sau mii de dolari lunar, în funcție de volumul de trafic și intensitatea crawlerilor. Costurile ascunse apar prin necesitatea de infrastructură suplimentară—poate fi nevoie să treci la planuri de hosting superioare, să implementezi straturi suplimentare de caching sau să investești în servicii CDN special pentru a gestiona traficul crawlerilor. Calculul ROI devine complex, având în vedere că crawlerii AI oferă valoare directă minimă afacerii tale în timp ce consumă resurse ce ar putea servi clienți plătitori sau îmbunătăți experiența utilizatorilor. Mulți proprietari de site-uri constată că costul acomodării traficului crawlerilor depășește orice potențiale beneficii din antrenamentul modelelor AI sau vizibilitatea în rezultatele de căutare alimentate de AI.
Traficul crawlerilor AI degradează direct experiența utilizatorilor reali, consumând resurse ale serverului ce altfel ar servi mai rapid utilizatorii umani. Metricile Core Web Vitals se deteriorează semnificativ, Largest Contentful Paint (LCP) crescând cu 200-500ms și Time to First Byte (TTFB) degradându-se cu 100-300ms în perioadele cu activitate intensă de crawlere. Aceste degradări de performanță declanșează efecte negative în lanț: încărcarea lentă a paginilor reduce implicarea utilizatorilor, crește rata de abandon și, în final, scade ratele de conversie pentru site-urile de e-commerce și lead-generation. Clasamentele în motoarele de căutare suferă de asemenea, deoarece algoritmul Google include Core Web Vitals ca factor de ranking, creând un cerc vicios în care traficul crawlerilor afectează indirect SEO-ul. Utilizatorii care experimentează timpi de încărcare lenți sunt mai predispuși să abandoneze site-ul și să acceseze concurența, afectând direct veniturile și percepția brandului.
Gestionarea eficientă a traficului crawlerilor AI începe cu monitorizare și detecție cuprinzătoare, permițând înțelegerea problemei înainte de implementarea soluțiilor. Majoritatea serverelor web loghează stringuri user-agent ce identifică crawlerul ce face fiecare cerere, oferind baza pentru analiza traficului și deciziile de filtrare. Logurile serverului, platformele de analiză și uneltele specializate de monitorizare pot parsa aceste stringuri pentru a identifica și cuantifica tiparele de trafic ale crawlerilor.
Metode și unelte cheie de detecție:
Prima linie de apărare împotriva traficului excesiv al crawlerilor AI este implementarea unui fișier robots.txt bine configurat care controlează explicit accesul crawlerilor la site-ul tău. Acest fișier text simplu, amplasat în directorul rădăcină al site-ului, îți permite să interzici anumitor crawlerei accesul, să limitezi frecvența crawlării și să direcționezi crawlerii către un sitemap cu doar conținutul dorit pentru indexare. Limitarea ratei la nivelul aplicației sau serverului adaugă un strat suplimentar de protecție, încetinind cererile de la anumite adrese IP sau user-agent-uri pentru a preveni epuizarea resurselor. Aceste strategii sunt neintruzive și reversibile, fiind ideale ca prim pas înainte de măsuri mai agresive.
# robots.txt - Blochează crawlerii AI și permite motoarele de căutare legitime
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: CCBot
Disallow: /
# Permite Google și Bing
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Crawl delay pentru toți ceilalți boți
User-agent: *
Crawl-delay: 10
Request-rate: 1/10s
Firewall-urile pentru aplicații web (WAF) și rețelele de livrare a conținutului (CDN) oferă protecție sofisticată, la nivel enterprise, împotriva traficului nedorit de la crawlere, prin analiză comportamentală și filtrare inteligentă. Cloudflare și alți furnizori CDN similari oferă funcții integrate de gestionare a boților ce pot identifica și bloca crawlerele AI pe baza tiparelor comportamentale, reputației IP și caracteristicilor cererilor, fără configurare manuală. Regulile WAF pot fi configurate să provoace cereri suspecte, să limiteze rata anumitor user-agent-uri sau să blocheze traficul de la intervale IP cunoscute ale crawlerilor. Aceste soluții operează la margine, filtrând traficul malițios înainte ca acesta să ajungă la serverul origin, reducând dramatic încărcarea infrastructurii. Avantajul soluțiilor WAF și CDN este capacitatea lor de a se adapta la noi crawlere și tipare de atac fără actualizări manuale ale configurației.
Decizia de a bloca crawlerii AI necesită o analiză atentă a compromisurilor între protecția resurselor serverului și menținerea vizibilității în rezultatele de căutare și aplicațiile alimentate de AI. Blocarea tuturor crawlerilor AI elimină posibilitatea ca site-ul tău să apară în rezultatele ChatGPT Search, răspunsurile Perplexity AI sau alte mecanisme de descoperire AI, reducând potențial traficul de referință și vizibilitatea brandului. Pe de altă parte, permiterea necondiționată a crawlerilor consumă resurse semnificative și poate degrada experiența utilizatorilor fără beneficii măsurabile pentru afacerea ta. Strategia optimă depinde de situația specifică: site-urile cu trafic mare și resurse abundente pot alege să permită crawlerii, în timp ce site-urile cu resurse limitate ar trebui să prioritizeze experiența utilizatorilor prin blocarea sau limitarea accesului crawlerilor. Deciziile strategice ar trebui să țină cont de industrie, publicul țintă, tipul de conținut și obiectivele de business, nu de o abordare universală.
Pentru site-urile care aleg să acomodeze traficul crawlerilor AI, scalarea infrastructurii oferă o cale de a menține performanța în timp ce absorb încărcarea crescută. Scalarea verticală—upgrade-ul către servere cu mai mult CPU, RAM și lățime de bandă—reprezintă o soluție directă, dar costisitoare, care ajunge la un moment dat la limite fizice. Scalarea orizontală—distribuirea traficului pe mai multe servere cu load balancere—oferă scalabilitate și reziliență pe termen lung. Platformele cloud precum AWS, Google Cloud și Azure oferă capabilități de auto-scalare ce alocă automat resurse suplimentare în timpul vârfurilor de trafic, apoi le reduc în perioadele liniștite pentru a minimiza costurile. Rețelele de livrare de conținut (CDN) pot face cache pentru conținutul static la locații edge, reducând încărcarea pe serverul origin și îmbunătățind performanța atât pentru utilizatorii umani, cât și pentru crawlere. Optimizarea bazei de date, cachingul interogărilor și îmbunătățirile la nivel de aplicație pot, de asemenea, reduce consumul de resurse per cerere, crescând eficiența fără a necesita infrastructură suplimentară.
Monitorizarea și optimizarea continuă sunt esențiale pentru menținerea performanței optime în fața traficului persistent de la crawlerele AI. Uneltele specializate oferă vizibilitate asupra activității crawlerilor, consumului de resurse și metricilor de performanță, permițând decizii informate privind strategiile de gestionare. Implementarea monitorizării cuprinzătoare de la început permite stabilirea unor repere, identificarea tendințelor și măsurarea eficienței strategiilor de reducere în timp.
Unelte și practici esențiale de monitorizare:
Peisajul gestionării crawlerilor AI continuă să evolueze, cu standarde emergente și inițiative la nivel de industrie ce modelează interacțiunea dintre site-uri și companiile AI. Standardul llms.txt reprezintă o abordare emergentă de a oferi companiilor AI informații structurate despre drepturile de utilizare a conținutului și preferințe, oferind potențial o alternativă mai nuanțată la blocarea sau permiterea în bloc. Discuțiile din industrie privind modelele de compensare sugerează că, în viitor, companiile AI ar putea plăti site-urile pentru acces la datele de antrenament, schimbând fundamental economia traficului de la crawlere. Adaptarea pe termen lung a infrastructurii presupune să fii informat privind standardele emergente, să monitorizezi evoluțiile industriei și să menții flexibilitatea politicilor de gestionare a crawlerilor. Construirea relațiilor cu companiile AI, implicarea în discuții de industrie și susținerea unor modele de compensare corecte vor deveni din ce în ce mai importante pe măsură ce AI devine central pentru descoperirea și consumul de conținut web. Site-urile care vor prospera în acest peisaj în schimbare vor fi cele care echilibrează inovația cu pragmatismul, protejându-și resursele, dar rămânând deschise oportunităților legitime de vizibilitate și parteneriat.
Crawlerii AI (GPTBot, ClaudeBot) extrag conținut pentru antrenarea LLM fără a trimite neapărat trafic înapoi. Crawlerii motoarelor de căutare (Googlebot) indexează conținut pentru vizibilitatea în căutare și, de obicei, trimit trafic de referință. Crawlerii AI operează mai agresiv, cu cereri în loturi mari și ignoră recomandările de economisire a lățimii de bandă.
Exemple reale arată peste 30TB pe lună doar de la un singur crawler. Consumul depinde de dimensiunea site-ului, volumul de conținut și frecvența crawlerului. GPTBot de la OpenAI singur a generat 569 de milioane de cereri într-o singură lună pe rețeaua Vercel.
Blocarea crawlerilor AI pentru antrenament (GPTBot, ClaudeBot) nu afectează clasamentul Google. Totuși, blocarea crawlerilor AI de căutare poate reduce vizibilitatea în rezultate bazate pe AI precum Perplexity sau ChatGPT search.
Caută creșteri inexplicabile ale utilizării CPU (peste 300%), creșterea consumului de lățime de bandă fără mai mulți vizitatori umani, timpi mai mari de încărcare a paginilor și stringuri de user-agent neobișnuite în logurile serverului. Metricile Core Web Vitals pot, de asemenea, să se degradeze semnificativ.
Pentru site-urile cu trafic semnificativ de la crawlere, hostingul dedicat oferă o izolare mai bună a resurselor, control și predictibilitate a costurilor. Mediile de hosting partajat suferă de „sindromul vecinului gălăgios”, unde traficul de la crawlerele unui site afectează toate site-urile găzduite.
Folosește Google Search Console pentru date despre Googlebot, logurile de acces ale serverului pentru analiză detaliată a traficului, analytics CDN (Cloudflare) și platforme specializate precum AmICited.com pentru monitorizare și urmărire detaliată a crawlerilor AI.
Da, prin directive robots.txt, reguli WAF și filtrare pe bază de IP. Poți permite crawlerii benefici precum Googlebot și să blochezi crawlerii AI pentru antrenament, consumatori de resurse, folosind reguli specifice de user-agent.
Compară metricile serverului înainte și după implementarea controalelor pentru crawlere. Monitorizează Core Web Vitals (LCP, TTFB), timpii de încărcare a paginilor, utilizarea CPU și metrici de experiență a utilizatorului. Unelte precum Google PageSpeed Insights și platformele de monitorizare a serverului oferă perspective detaliate.
Obține perspective în timp real despre modul în care modelele AI accesează conținutul tău și influențează resursele serverului cu platforma specializată de monitorizare de la AmICited.
Aflați cum să luați decizii strategice despre blocarea crawlerilor AI. Evaluați tipul de conținut, sursele de trafic, modelele de venituri și poziția competitiv...

Află cum să identifici și să monitorizezi crawlerele AI precum GPTBot, PerplexityBot și ClaudeBot în jurnalele serverului tău. Descoperă șiruri user-agent, meto...

Înțelegeți cum funcționează crawlerii AI precum GPTBot și ClaudeBot, diferențele lor față de crawlerii de căutare tradiționali și cum să vă optimizați site-ul p...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.