
Ar trebui să blocați sau să permiteți crawlerii AI? Cadru decizional
Aflați cum să luați decizii strategice despre blocarea crawlerilor AI. Evaluați tipul de conținut, sursele de trafic, modelele de venituri și poziția competitiv...
12 min citire

Înțelegeți cum funcționează crawlerii AI precum GPTBot și ClaudeBot, diferențele lor față de crawlerii de căutare tradiționali și cum să vă optimizați site-ul pentru vizibilitatea în căutarea AI.
Crawlerii AI sunt programe automate concepute pentru a naviga sistematic pe internet și a colecta date de pe site-uri, în special pentru a antrena și îmbunătăți modelele de inteligență artificială. Spre deosebire de crawlerii tradiționali ai motoarelor de căutare, precum Googlebot, care indexează conținutul pentru rezultate de căutare, crawlerii AI colectează date web brute pentru a le furniza modelelor lingvistice de mari dimensiuni (LLM) precum ChatGPT, Claude și alte sisteme AI. Acești boți operează continuu pe milioane de site-uri, descarcă pagini, analizează conținutul și extrag informații care ajută platformele AI să înțeleagă modele de limbaj, informații factuale și stiluri de scriere diverse. Jucătorii principali din acest domeniu includ GPTBot de la OpenAI, ClaudeBot de la Anthropic, Meta-ExternalAgent de la Meta, Amazonbot de la Amazon și PerplexityBot de la Perplexity.ai, fiecare servind nevoile de antrenament și operare ale propriilor platforme AI. Înțelegerea modului în care funcționează acești crawleri a devenit esențială pentru proprietarii de site-uri și creatorii de conținut, deoarece vizibilitatea în AI influențează direct modul în care brandul tău apare în rezultatele și recomandările generate de AI.
Peisajul crawling-ului web a trecut printr-o transformare dramatică în ultimul an, crawlerii AI înregistrând o creștere explozivă, în timp ce crawlerii tradiționali de căutare și-au menținut tiparele constante. Între mai 2024 și mai 2025, traficul total al crawlerilor a crescut cu 18%, dar distribuția s-a modificat semnificativ—GPTBot a crescut cu 305% în cereri brute, în timp ce alți crawleri precum ClaudeBot au scăzut cu 46% și Bytespider s-a prăbușit cu 85%. Această reordonare reflectă intensificarea competiției între companiile AI pentru a obține date pentru antrenament și a-și îmbunătăți modelele. Iată o prezentare detaliată a principalilor crawleri și poziția lor actuală pe piață:
| Nume Crawler | Companie | Cereri lunare | Creștere YoY | Scop principal |
|---|---|---|---|---|
| Googlebot | 4,5 miliarde | 96% | Indexare pentru căutare & AI Overviews | |
| GPTBot | OpenAI | 569 milioane | 305% | Antrenare modele ChatGPT & căutare |
| Claude | Anthropic | 370 milioane | -46% | Antrenare Claude & căutare |
| Bingbot | Microsoft | ~450 milioane | 2% | Indexare pentru căutare |
| PerplexityBot | Perplexity.ai | 24,4 milioane | 157.490% | Indexare căutare AI |
| Meta-ExternalAgent | Meta | ~380 milioane | Intrare nouă | Antrenare Meta AI |
| Amazonbot | Amazon | ~210 milioane | -35% | Căutare & aplicații AI |
Datele arată că, deși Googlebot își menține dominația cu 4,5 miliarde de cereri lunare, crawlerii AI reprezintă colectiv aproximativ 28% din volumul Googlebot, fiind astfel o forță semnificativă în traficul web. Creșterea explozivă a PerplexityBot (157.490%) demonstrează cât de rapid își scală noile platforme AI operațiunile de crawling, în timp ce declinul unor crawleri AI consacrați sugerează o consolidare a pieței în jurul celor mai de succes platforme AI.
GPTBot este crawlerul web al OpenAI, conceput special pentru a colecta date în vederea antrenării și îmbunătățirii ChatGPT și a altor modele OpenAI. Lansat inițial ca un jucător minor cu doar 5% cotă de piață în mai 2024, GPTBot a devenit crawlerul AI dominant, captând 30% din tot traficul crawlerilor AI până în mai 2025—o creștere remarcabilă de 305% în cereri brute. Această creștere explozivă reflectă strategia agresivă a OpenAI de a asigura ChatGPT acces la conținut web proaspăt și diversificat atât pentru antrenarea modelelor, cât și pentru capabilitățile de căutare în timp real prin ChatGPT Search. GPTBot operează cu un tipar distinct de crawling, prioritizând conținutul HTML (57,70% din fetch-uri), dar descarcă și fișiere JavaScript și imagini, însă nu execută JavaScript pentru a reda conținut dinamic. Comportamentul crawlerului arată că întâlnește frecvent erori 404 (34,82% din cereri), sugerând că urmărește linkuri învechite sau încearcă să acceseze resurse care nu mai există. Pentru proprietarii de site-uri, dominația GPTBot înseamnă că asigurarea accesibilității conținutului pentru acest crawler a devenit esențială pentru vizibilitatea în funcțiile de căutare ale ChatGPT și pentru potențiala includere în viitoarele iterații de antrenare ale modelului.
ClaudeBot, dezvoltat de Anthropic, servește drept crawler principal pentru antrenarea și actualizarea asistentului Claude AI, precum și pentru susținerea funcțiilor de căutare și ancorare ale lui Claude. Odată al doilea cel mai mare crawler AI cu 27% cotă de piață în mai 2024, ClaudeBot a înregistrat o scădere notabilă la 21% până în mai 2025, cererile brute scăzând cu 46% de la an la an. Această scădere nu indică neapărat o problemă cu strategia Anthropic, ci reflectă mai degrabă tendința generală de consolidare a pieței în jurul OpenAI și apariția unor noi competitori precum Meta-ExternalAgent. ClaudeBot prezintă un comportament similar cu GPTBot, prioritizând conținutul HTML, dar dedicând un procent mai mare din cereri imaginilor (35,17% din fetch-uri), sugerând că Anthropic ar putea antrena Claude pentru a înțelege mai bine conținutul vizual pe lângă cel textual. Ca și alți crawleri AI, ClaudeBot nu redă JavaScript, ceea ce înseamnă că vede doar HTML-ul brut al paginilor, fără conținutul încărcat dinamic. Pentru creatorii de conținut, menținerea vizibilității pentru ClaudeBot rămâne importantă pentru ca Claude să poată accesa și cita conținutul tău, mai ales pe măsură ce Anthropic continuă să dezvolte capabilitățile de căutare și raționament ale lui Claude.
Dincolo de GPTBot și ClaudeBot, mai mulți alți crawleri AI semnificativi colectează activ date web pentru platformele lor:
Meta-ExternalAgent (Meta): Crawlerul Meta a făcut o intrare spectaculoasă în top, captând 19% cotă de piață până în mai 2025 ca nou venit. Acest bot colectează date pentru inițiativele AI ale Meta, inclusiv potențialul antrenament pentru Meta AI și integrarea cu funcțiile AI din Instagram și Facebook. Ascensiunea rapidă a Meta sugerează că compania face o mișcare serioasă spre căutarea și recomandările alimentate de AI.
PerplexityBot (Perplexity.ai): Deși are doar 0,2% cotă de piață, PerplexityBot a înregistrat cea mai explozivă rată de creștere, de 157.490% de la an la an. Acest lucru reflectă scalarea rapidă a Perplexity ca motor de răspuns AI care se bazează pe căutare web în timp real pentru a-și ancora răspunsurile. Pentru site-uri, vizitele PerplexityBot reprezintă oportunități directe de a fi citate în răspunsurile generate de AI-ul Perplexity.
Amazonbot (Amazon): Crawlerul Amazon a scăzut de la 21% la 11% cotă de piață, cererile brute scăzând cu 35% de la an la an. Amazonbot colectează date pentru funcționalitatea de căutare și aplicațiile AI ale Amazon, dar declinul său sugerează că Amazon își modifică strategia AI sau își consolidează operațiunile de crawling.
Applebot (Apple): Crawlerul Apple a înregistrat o scădere de 26% a cererilor, coborând de la 1,9% la 1,2% cotă de piață. Applebot deservește în principal Siri și Spotlight Search, dar poate susține și inițiativele AI emergente ale Apple. Spre deosebire de majoritatea crawlerilor AI, Applebot poate reda JavaScript, oferindu-i capabilități similare cu Googlebot.
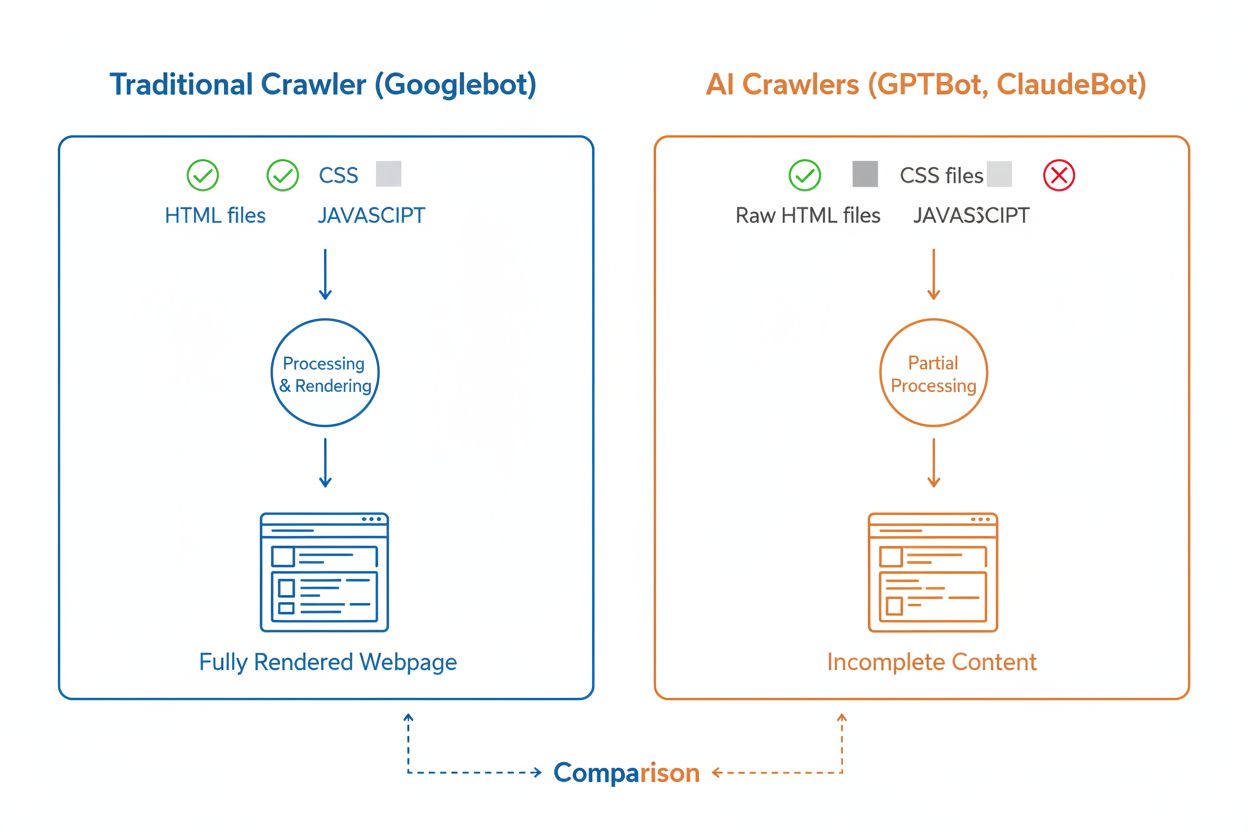
Deși atât crawlerii AI, cât și cei tradiționali precum Googlebot navighează sistematic webul, capabilitățile și comportamentele lor tehnice diferă semnificativ, influențând direct modul în care conținutul tău este descoperit și înțeles. Diferența cea mai importantă este redarea JavaScript: Googlebot poate executa JavaScript după descărcarea unei pagini, permițându-i să vadă conținutul încărcat dinamic, în timp ce majoritatea crawlerilor AI (GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider) citesc doar HTML-ul brut și ignoră orice conținut dependent de JavaScript. Astfel, dacă site-ul tău se bazează pe randare pe partea de client pentru a afișa informații cheie, crawlerii AI vor vedea o versiune incompletă a paginilor tale. În plus, crawlerii AI prezintă tipare de crawling mai puțin predictibile comparativ cu abordarea sistematică a Googlebot—petrec 34,82% din cereri pe pagini 404 și 14,36% urmărind redirectări, comparativ cu eficiența Googlebot de 8,22% pe 404-uri și 1,49% pe redirectări. Și frecvența crawl-ului diferă: Googlebot vizitează paginile pe baza unui sistem sofisticat de crawl budget, în timp ce crawlerii AI par să acceseze mai des, dar mai puțin sistematic, unele cercetări arătând că vizitează anumite pagini de peste 100 de ori mai frecvent decât Google. Aceste diferențe înseamnă că strategiile tradiționale de SEO nu acoperă complet cerințele de crawlabilitate AI, necesitând o abordare distinctă axată pe randare pe server și structuri de URL curate.
Una dintre cele mai semnificative provocări tehnice pentru crawlerii AI este incapacitatea lor de a reda JavaScript, o limitare care derivă din costul computațional ridicat al executării JavaScript la scara uriașă necesară pentru antrenarea modelelor lingvistice mari. Când un crawler descarcă pagina ta web, primește răspunsul HTML inițial, dar orice conținut încărcat sau modificat prin JavaScript—precum detalii despre produse, informații despre prețuri, recenzii ale utilizatorilor sau elemente de navigare dinamice—rămâne invizibil pentru crawlerii AI. Acest lucru creează o problemă critică pentru site-urile moderne care se bazează puternic pe framework-uri de randare pe partea de client precum React, Vue sau Angular, fără randare pe server (SSR) sau generare statică de pagini (SSG). De exemplu, un site e-commerce care afișează informații despre produse prin JavaScript va apărea ca o pagină goală pentru crawlerii AI, făcând imposibilă înțelegerea sau citarea acelui conținut de către sistemele AI. Soluția este să te asiguri că tot conținutul critic este servit în răspunsul HTML inițial prin randare pe server (SSR), care generează HTML-ul complet pe server înainte de a-l trimite către browser. Această abordare asigură o experiență bogată atât pentru vizitatorii umani, cât și pentru crawlerii AI. Site-urile care folosesc framework-uri moderne precum Next.js cu SSR, generatoare statice precum Hugo sau Gatsby, sau platforme tradiționale cu randare pe server precum WordPress sunt prietenoase cu crawlerii AI, în timp ce cele care se bazează doar pe randare pe partea de client se confruntă cu provocări majore de vizibilitate în căutarea AI.
Crawlerii AI prezintă tipare distincte de frecvență a accesărilor, diferite semnificativ de comportamentul Googlebot, cu implicații importante asupra vitezei cu care conținutul tău ajunge să fie preluat de sistemele AI. Cercetările arată că crawlerii AI precum ChatGPT și Perplexity vizitează adesea paginile mai frecvent decât Google pe termen scurt după publicare—în unele cazuri, de 8 ori mai des decât Googlebot în primele zile. Acest crawling rapid inițial sugerează că platformele AI prioritizează descoperirea și indexarea conținutului nou, probabil pentru a se asigura că modelele și funcțiile lor de căutare au acces la cele mai recente informații. Totuși, acest crawling agresiv inițial este urmat de un tipar în care crawlerii AI pot să nu mai revină dacă conținutul nu respectă standardele de calitate, ceea ce face ca prima impresie să fie esențială. Spre deosebire de Googlebot, care are un sistem sofisticat de crawl budget și revine regulat la pagini în funcție de frecvența actualizărilor și importanță, crawlerii AI par să decidă rapid dacă un conținut merită revizitat. Asta înseamnă că, dacă un crawler AI vizitează pagina ta și găsește conținut subțire, erori tehnice sau semnale de experiență slabă pentru utilizator, ar putea trece mult timp până să revină—dacă va reveni vreodată. Implicația pentru creatorii de conținut este clară: nu te poți baza pe o a doua șansă să optimizezi conținutul pentru crawlerii AI, așa cum se întâmplă cu motoarele de căutare tradiționale, ceea ce face ca asigurarea calității înainte de publicare să fie esențială.
Proprietarii de site-uri pot folosi fișierul robots.txt pentru a comunica preferințele privind accesul crawlerilor AI, deși eficiența și aplicarea acestor reguli variază semnificativ între crawleri. Potrivit datelor recente, aproximativ 14% din primele 10.000 de site-uri au implementat reguli specifice de allow sau disallow pentru boții AI în fișierele robots.txt. GPTBot este crawlerul cel mai des blocat, cu 312 domenii (250 complet, 62 parțial) care îl interzic explicit, dar este și crawlerul cel mai explicit permis, cu 61 domenii care îi acordă acces. Alți crawleri blocați frecvent includ CCBot (Common Crawl) și Google-Extended (tokenul AI training de la Google). Provocarea cu robots.txt este că respectarea lui este voluntară—crawleri respectă regulile doar dacă operatorii lor implementează această funcționalitate, iar unii crawleri noi sau mai puțin transparenți pot ignora directivele robots.txt. În plus, tokenii robots.txt precum “Google-Extended” nu corespund direct user-agent-ilor din cererile HTTP; în schimb, semnalizează scopul crawling-ului, deci nu poți verifica întotdeauna respectarea lor din logurile serverului. Pentru o aplicare mai strictă, proprietarii de site-uri recurg din ce în ce mai mult la reguli de firewall și Web Application Firewalls (WAF) care pot bloca activ anumiți user-agent-i de crawler, oferind un control mai fiabil decât robots.txt singur. Această trecere la mecanisme de blocare active reflectă preocupările crescânde privind drepturile de conținut și dorința de a avea un control mai aplicabil asupra accesului crawlerilor AI.
Urmărirea activității crawlerilor AI pe site-ul tău este esențială pentru a înțelege vizibilitatea în căutarea AI, dar prezintă provocări unice față de monitorizarea crawlerilor tradiționali. Instrumentele clasice de analiză precum Google Analytics se bazează pe tracking JavaScript, pe care crawlerii AI nu îl execută, ceea ce înseamnă că aceste instrumente nu oferă vizibilitate asupra vizitelor boților AI. Similar, tracking-ul bazat pe pixel nu funcționează pentru că majoritatea crawlerilor AI procesează doar textul și ignoră imaginile. Singura metodă fiabilă de a urmări activitatea crawlerilor AI este monitorizarea la nivel de server—analizarea header-elor HTTP și a logurilor serverului pentru a identifica user-agent-ii crawlerilor înainte ca pagina să fie servită. Acest lucru necesită fie analiză manuală a logurilor, fie instrumente specializate concepute pentru a identifica și urmări traficul crawlerilor AI. Monitorizarea în timp real este deosebit de importantă, deoarece crawlerii AI operează pe programe imprevizibile și pot să nu revină la pagini dacă întâmpină probleme, ceea ce înseamnă că un audit săptămânal sau lunar poate rata probleme importante. Dacă un crawler AI vizitează site-ul tău și găsește o eroare tehnică sau conținut de slabă calitate, s-ar putea să nu mai ai ocazia să faci o impresie bună. Implementarea unor soluții de monitorizare 24/7 care să te alerteze imediat când crawlerii AI întâmpină probleme—precum erori 404, timpi de încărcare lenți sau markup schema lipsă—îți permite să remediezi rapid problemele înainte ca ele să îți afecteze vizibilitatea în căutarea AI. Această abordare în timp real reprezintă o schimbare fundamentală față de practicile tradiționale de monitorizare SEO, reflectând viteza și impredictibilitatea comportamentului crawlerilor AI.
Optimizarea site-ului pentru crawlerii AI necesită o abordare distinctă față de SEO tradițional, concentrându-se pe factori tehnici care influențează direct modul în care sistemele AI pot accesa și înțelege conținutul tău. Prima prioritate este randarea pe server: asigură-te că tot conținutul critic—titluri, text, metadate, date structurate—este inclus în răspunsul HTML inițial, nu încărcat dinamic prin JavaScript. Acest lucru este valabil pentru homepage, paginile de destinație cheie și orice conținut pe care dorești să fie citat sau referențiat de sistemele AI. În al doilea rând, implementează markup cu date structurate (Schema.org) pe paginile cu impact mare, inclusiv schema pentru articole la postările de blog, schema pentru produse la paginile e-commerce și schema pentru autor pentru a stabili expertiza și autoritatea. Crawlerii AI folosesc datele structurate pentru a înțelege rapid ierarhia și contextul conținutului, facilitând citarea acestuia. În al treilea rând, menține standarde ridicate de calitate a conținutului pe toate paginile, deoarece crawlerii AI par să decidă rapid dacă merită să indexeze și să citeze un conținut. Asta înseamnă să asiguri originalitate, documentare, acuratețe factuală și valoare reală pentru cititori. În al patrulea rând, monitorizează și optimizează Core Web Vitals și performanța generală a paginilor, deoarece paginile lente semnalează o experiență slabă pentru utilizator și pot descuraja crawlerii AI să revină. În final, păstrează structura URL-urilor curată și consistentă, menține un sitemap XML actualizat și asigură-te că robots.txt este configurat corect pentru a ghida crawlerii către conținutul important. Aceste optimizări tehnice creează o fundație care face ca informația ta să fie descoperibilă, inteligibilă și citabilă de sistemele AI.
Peisajul crawlerilor AI va continua să evolueze rapid pe măsură ce competiția dintre companiile AI se intensifică și tehnologia se maturizează. O tendință clară este consolidarea cotei de piață în jurul celor mai de succes platforme—GPTBot de la OpenAI a devenit forța dominantă, în timp ce noi veniți precum Meta-ExternalAgent cresc agresiv, sugerând că piața se va stabiliza probabil în jurul câtorva jucători majori. Pe măsură ce crawlerii AI se maturizează, ne putem aștepta la îmbunătățiri ale capabilităților tehnice, în special în redarea JavaScript și tipare mai eficiente de crawling care să reducă cererile irosite pe pagini 404 și conținut învechit. Industria se îndreaptă și spre protocoale de comunicare mai standardizate, precum specificația emergentă llms.txt, care permite site-urilor să comunice explicit structura conținutului și preferințele de crawling către sistemele AI. În plus, mecanismele de control pentru accesul crawlerilor AI devin tot mai sofisticate, cu platforme precum Cloudflare care oferă acum blocarea automată a boților de antrenare AI în mod implicit, oferind proprietarilor de site-uri un control mai granular asupra conținutului lor. Pentru creatorii de conținut și proprietarii de site-uri, a rămâne în fața acestor schimbări înseamnă monitorizarea continuă a activității crawlerilor AI, menținerea unei infrastructuri tehnice optimizate pentru accesibilitatea AI și adaptarea strategiei de conținut la realitatea că sistemele AI reprezintă acum o parte semnificativă din traficul site-ului tău și un canal critic pentru vizibilitatea brandului. Viitorul aparține celor care înțeleg și optimizează pentru acest nou ecosistem al crawlerilor.
Crawlerii AI sunt programe automate care colectează date web special pentru a antrena și îmbunătăți modelele de inteligență artificială precum ChatGPT și Claude. Spre deosebire de crawlerii tradiționali ai motoarelor de căutare, cum ar fi Googlebot, care indexează conținut pentru rezultate de căutare, crawlerii AI colectează date web brute pentru a le introduce în modele lingvistice de mari dimensiuni. Ambele tipuri de crawleri navighează sistematic pe internet, însă servesc scopuri diferite și au capabilități tehnice distincte.
Crawlerii AI accesează site-ul tău pentru a colecta date necesare antrenării modelelor AI, îmbunătățirii funcțiilor de căutare și ancorării răspunsurilor AI cu informații actuale. Când sisteme AI precum ChatGPT sau Perplexity răspund la întrebările utilizatorilor, acestea au adesea nevoie să preia conținutul tău în timp real pentru a oferi informații exacte și citate. Permiterea accesului crawlerilor AI la site-ul tău crește șansele ca brandul tău să fie menționat și citat în răspunsurile generate de AI.
Da, poți folosi fișierul robots.txt pentru a interzice anumiți crawleri AI specificând numele user-agent-ului lor. Totuși, respectarea robots.txt este voluntară și nu toți crawlerii respectă aceste reguli. Pentru o aplicare mai strictă, poți folosi reguli de firewall și Web Application Firewalls (WAF) pentru a bloca activ anumiți user-agent-i de crawler. Acest lucru îți oferă un control mai fiabil asupra crawlerilor AI care pot accesa conținutul tău.
Nu, majoritatea crawlerilor AI (GPTBot, ClaudeBot, Meta-ExternalAgent) nu execută JavaScript. Ei citesc doar HTML-ul brut al paginilor tale, ceea ce înseamnă că orice conținut încărcat dinamic prin JavaScript va fi invizibil pentru ei. Din acest motiv, randarea pe server (server-side rendering) este esențială pentru ca paginile să fie accesibile crawlerilor AI. Dacă site-ul tău se bazează pe randare pe partea de client, crawlerii AI vor vedea o versiune incompletă a paginilor tale.
Crawlerii AI vizitează site-urile mai frecvent decât motoarele de căutare tradiționale pe termen scurt, imediat după publicarea conținutului. Cercetările arată că pot vizita paginile de 8-100 de ori mai des decât Google în primele câteva zile. Cu toate acestea, dacă conținutul nu îndeplinește standardele de calitate, este posibil să nu revină. Acest lucru face ca prima impresie să fie critică—s-ar putea să nu ai o a doua șansă să optimizezi conținutul pentru crawlerii AI.
Optimizările cheie sunt: (1) Folosește randare pe server pentru a te asigura că tot conținutul critic este prezent în HTML-ul inițial, (2) Adaugă markup cu date structurate (Schema) pentru a ajuta AI-ul să îți înțeleagă conținutul, (3) Menține calitatea și actualitatea ridicată a conținutului, (4) Monitorizează Core Web Vitals pentru o experiență bună a utilizatorului și (5) Păstrează o structură curată a URL-urilor și un sitemap actualizat. Aceste optimizări tehnice creează o fundație care face conținutul tău descoperibil și citabil de sistemele AI.
GPTBot de la OpenAI este în prezent cel mai dominant crawler AI, captând 30% din tot traficul crawlerilor AI și crescând cu 305% de la an la an. Totuși, ar trebui să optimizezi pentru toți crawlerii principali, inclusiv ClaudeBot (Anthropic), Meta-ExternalAgent (Meta), PerplexityBot (Perplexity) și alții. Diferite platforme AI au baze de utilizatori diferite, astfel încât vizibilitatea în mai mulți crawleri maximizează prezența brandului tău în căutarea AI.
Instrumentele tradiționale de analiză precum Google Analytics nu detectează activitatea crawlerilor AI deoarece se bazează pe tracking JavaScript. În schimb, ai nevoie de monitorizare la nivel de server care analizează header-ele HTTP și logurile serverului pentru a identifica user-agent-ii crawlerilor. Instrumentele specializate pentru urmărirea crawlerilor AI oferă vizibilitate în timp real asupra paginilor accesate, frecvenței cu care sunt accesate și dacă crawlerii întâmpină probleme tehnice.
Urmărește modul în care crawlerii AI precum GPTBot și ClaudeBot accesează și citează conținutul tău. Obține informații în timp real despre vizibilitatea ta în căutarea AI cu AmICited.
Aflați cum să luați decizii strategice despre blocarea crawlerilor AI. Evaluați tipul de conținut, sursele de trafic, modelele de venituri și poziția competitiv...

Află cum crawlerii AI influențează resursele serverului, lățimea de bandă și performanța. Descoperă statistici reale, strategii de reducere și soluții de infras...

Află ce crawlere AI să permiți sau să blochezi în robots.txt. Ghid cuprinzător despre GPTBot, ClaudeBot, PerplexityBot și peste 25 de crawlere AI, cu exemple de...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.