
Țintirea Site-urilor Sursă LLM pentru Backlink-uri
Află cum să identifici și să țintești site-urile sursă LLM pentru backlink-uri strategice. Descoperă care platforme AI citează cel mai mult sursele și optimizea...
11 min citire

Descoperă cum Modelele Lingvistice Mari selectează și citează sursele prin ponderarea dovezilor, recunoașterea entităților și date structurate. Află procesul de decizie în 7 faze al citării și cum să îți optimizezi conținutul pentru vizibilitate AI.
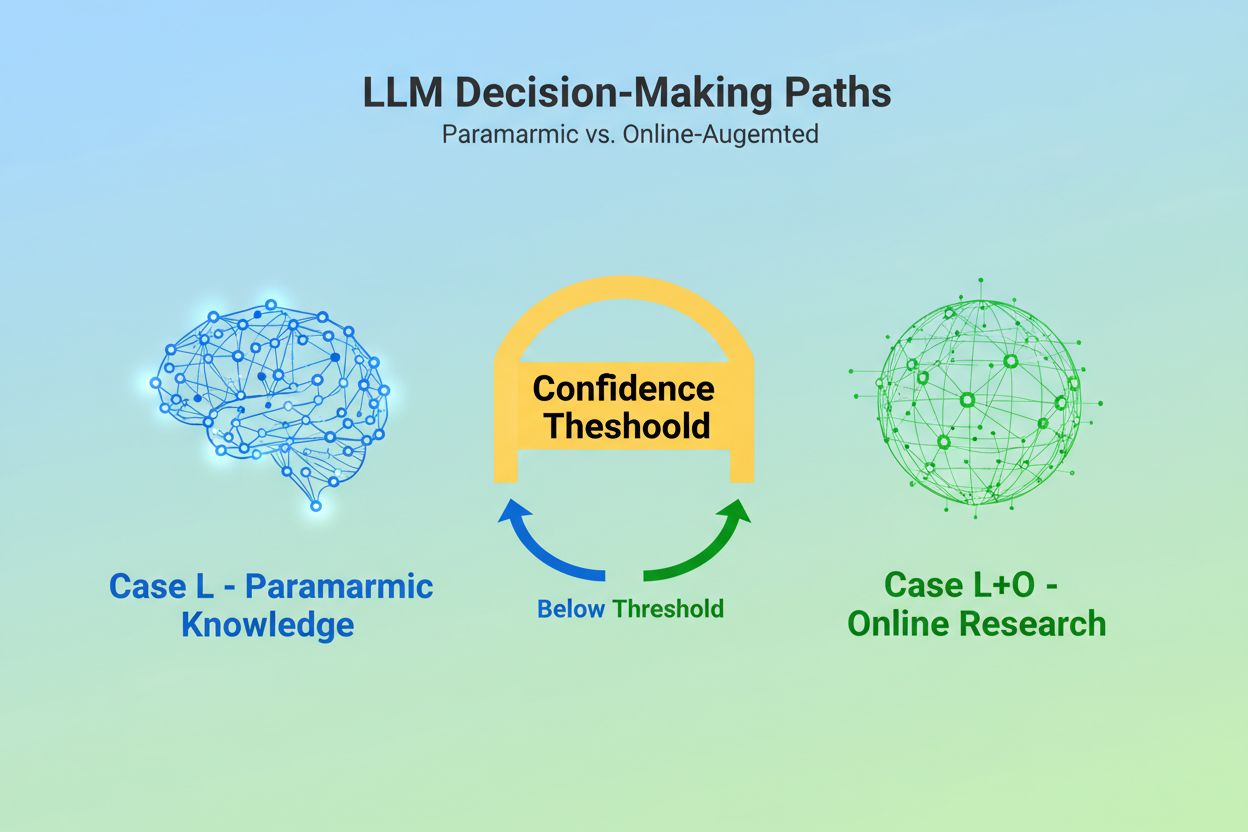
Când un Model Lingvistic Mare primește o interogare, se confruntă cu o decizie fundamentală: să se bazeze doar pe cunoștințele încorporate în timpul antrenării sau să caute informații actuale pe web? Această alegere binară—pe care cercetătorii o numesc Cazul L (doar date din învățare) versus Cazul L+O (date din învățare plus cercetare online)—determină dacă un LLM va cita sau nu surse externe. În modul Caz L, modelul folosește exclusiv baza sa de cunoștințe parametrică, o reprezentare condensată a tiparelor învățate în timpul antrenării care reflectă, de obicei, informații de la câteva luni până la peste un an înainte de lansarea modelului. În modul Caz L+O, modelul activează un prag de încredere care declanșează cercetarea externă, deschizând ceea ce cercetătorii numesc „spațiul de candidați” al URL-urilor și surselor. Acest punct de decizie este invizibil pentru majoritatea instrumentelor de monitorizare, dar aici începe întregul mecanism de citare—pentru că, fără declanșarea fazei de căutare, nici o sursă externă nu poate fi evaluată sau citată.
Din momentul în care un LLM decide să caute surse externe, intră în cea mai critică fază pentru selecția citării: ponderarea dovezilor. Aici se face distincția între o simplă mențiune și o recomandare autoritară. Modelul nu numără pur și simplu de câte ori apare o sursă sau cât de sus se clasează în rezultate; evaluează integritatea structurală a dovezii. Analizează arhitectura documentului—dacă sursele conțin relații clare de date, identificatori recurenți și linkuri referențiate—interpretând acestea ca semne de încredere. Modelul construiește ceea ce cercetătorii numesc „graful de dovezi”, unde nodurile reprezintă entități și muchiile relații între documente. Fiecare sursă este ponderată nu doar pe relevanța conținutului, ci și pe cât de consistent sunt confirmate faptele în mai multe documente, cât de relevantă este informația tematic și cât de autoritar apare domeniul. Această evaluare multidimensională generează ceea ce se numește matricea de dovezi, o evaluare cuprinzătoare care stabilește ce surse sunt suficient de fiabile pentru a fi citate. Critic, această fază operează în stratul de raționament al LLM-ului, făcând-o invizibilă pentru instrumentele clasice de monitorizare GEO care măsoară doar semnale de recuperare.
Datele structurate—în special JSON-LD, marcajul Schema.org și RDFa—acționează ca un multiplicator în procesul de ponderare a dovezilor. Sursele care implementează date structurate corect primesc o pondere de 2-3 ori mai mare în matricea de dovezi comparativ cu conținutul nestructurat. Nu pentru că LLM-urile preferă estetic datele formatate, ci pentru că datele structurate permit legarea entităților, procesul de conectare a mențiunilor între documente prin identificatori lizibili de mașină precum @id, sameAs și Q-ID-uri (identificatori Wikidata). Când un LLM întâlnește o sursă cu un Q-ID pentru o organizație, poate verifica imediat acea entitate în mai multe documente, creând ceea ce cercetătorii numesc „coreferența entității inter-document”. Acest proces de verificare crește dramatic încrederea în fiabilitatea sursei.
| Format date | Acuratețea citării | Legare entități | Verificare inter-document |
|---|---|---|---|
| Text nestrcturat | 62% | Niciuna | Inferență manuală |
| Markup HTML de bază | 71% | Limitată | Potrivire parțială |
| RDFa/Microdate | 81% | Bună | Pe bază de tipare |
| JSON-LD cu Q-ID-uri | 94% | Excelentă | Linkuri verificate |
| Format Knowledge Graph | 97% | Perfectă | Verificare automată |
Impactul datelor structurate operează pe două axe temporale. Tranzitoriu, când un LLM caută online, citește JSON-LD și marcajul Schema.org în timp real, integrând imediat aceste informații structurate în ponderarea dovezilor pentru răspunsul curent. Persistent, datele structurate care rămân consistente în timp devin parte a bazei de cunoștințe parametrice a modelului la viitoarele cicluri de antrenare, modelând modul în care recunoaște și evaluează entitățile chiar și fără cercetare online. Acest mecanism dual înseamnă că brandurile care implementează date structurate corecte obțin atât vizibilitate imediată la citare, cât și autoritate pe termen lung în spațiul intern de cunoaștere al modelului.
Înainte ca un LLM să poată cita o sursă, trebuie mai întâi să înțeleagă despre ce este acea sursă și pe cine reprezintă. Aceasta e sarcina recunoașterii entităților, un proces care transformă limbajul uman vag în entități lizibile de mașină. Când un document menționează „Apple”, LLM-ul trebuie să determine dacă se referă la Apple Inc., fructul sau altceva. Modelul realizează acest lucru prin tipare de entități învățate din Wikipedia, Wikidata și Common Crawl, combinate cu analiza contextuală a textului din jur. În modul Caz L+O, acest proces devine mai sofisticat: modelul verifică entitățile cu date structurate externe, căutând atribute @id, linkuri sameAs și Q-ID-uri care oferă identificare clară. Această etapă de verificare e crucială pentru că referințele ambigue sau inconsistente la entități se pierd în zgomotul procesului de raționament al modelului. Un brand care folosește denumiri inconsistente, nu stabilește identificatori clari de entitate sau nu implementează marcaj Schema.org devine semantic neclar pentru mașină—apărând ca mai multe entități distincte, nu ca o sursă coerentă. În schimb, organizațiile cu entități stabile, referențiate consistent în mai multe documente, sunt recunoscute ca noduri fiabile în graful de cunoaștere al LLM-ului, crescând semnificativ probabilitatea de citare.
Drumul de la interogare la citare urmează un proces structurat în șapte faze, cartografiat de cercetători prin analiza comportamentului LLM-urilor. Faza 0: Analiza intenției începe când modelul tokenizează inputul utilizatorului, efectuează analiză semantică și creează un vector de intenție—o reprezentare abstractă a ceea ce cere cu adevărat utilizatorul. Această fază stabilește ce subiecte, entități și relații sunt relevante de luat în considerare. Faza 1: Recuperarea cunoștințelor interne accesează cunoștințele parametrice ale modelului și calculează un scor de încredere. Dacă acest scor depășește un prag, modelul rămâne în modul Caz L; dacă nu, trece la cercetare externă. Faza 2: Generarea de interogări fan-out (doar Caz L+O) creează mai multe interogări semnificativ variate—de obicei 1-6 token-uri fiecare—pentru a deschide cât mai larg spațiul de candidați. Faza 3: Extracția dovezilor recuperează URL-uri și fragmente din rezultate, parsează HTML și extrage JSON-LD, RDFa și microdate. Aici datele structurate devin vizibile mecanismului de citare. Faza 4: Legarea entităților identifică entitățile din documentele recuperate și le verifică după identificatori externi, creând un graf temporar de relații. Faza 5: Ponderarea dovezilor evaluează puterea dovezilor din toate sursele, ținând cont de arhitectura documentului, diversitatea surselor, frecvența confirmării și coerența între surse. Faza 6: Raționament și sinteză combină dovezile interne și externe, rezolvă contradicțiile și stabilește dacă fiecare sursă merită menționare sau recomandare. Faza 7: Construcția răspunsului final transpune dovezile ponderate în limbaj natural, integrând citări unde este cazul. Fiecare fază o alimentează pe următoarea, cu bucle de feedback care permit modelului să-și refineze căutarea sau să reevalueze dovezile dacă apar inconsistențe.
LLM-urile moderne folosesc tot mai mult Retrieval-Augmented Generation (RAG), o tehnică ce schimbă fundamental modul în care sunt selectate și justificate citările. În loc să se bazeze doar pe cunoștințe parametrice, sistemele RAG recuperează activ documente relevante, extrag dovezi și fundamentează răspunsurile în surse specifice. Această abordare transformă citarea dintr-un produs secundar implicit al antrenării într-un proces explicit și trasabil. Implementările RAG folosesc de obicei căutare hibridă, combinând recuperarea pe bază de cuvinte-cheie cu căutarea vectorială pentru a maximiza acoperirea. După recuperarea documentelor candidate, clasificarea semantică reevaluează rezultatele pe baza sensului, nu doar a potrivirii cuvintelor, asigurând că cele mai relevante surse ajung în top. Acest mecanism explicit face procesul de citare mai transparent și auditabil—fiecare sursă citată poate fi urmărită până la pasajele care i-au justificat includerea. Pentru organizațiile care monitorizează vizibilitatea AI, sistemele bazate pe RAG sunt deosebit de importante, deoarece generează tipare de citare măsurabile. Instrumente precum AmICited urmăresc modul în care sistemele RAG fac referire la brandul tău pe diferite platforme AI, oferind perspective despre dacă apari ca sursă citată sau doar ca material de fundal în faza de recuperare a dovezilor.
Nu toate citările sunt egale. Un LLM poate menționa o sursă ca fundal, în timp ce o recomandă pe alta ca dovadă autoritară—iar această distincție este determinată integral de ponderarea dovezilor, nu de succesul recuperării. O sursă poate apărea în spațiul de candidați (Faza 2-3), dar să nu ajungă la statutul de recomandare dacă scorul de dovezi este insuficient. Această separare între mențiune și recomandare este locul unde metricele GEO tradiționale nu reușesc să facă diferența. Instrumentele standard de monitorizare măsoară „fan-out”—dacă apare conținutul tău în rezultate—dar nu pot măsura dacă LLM-ul chiar consideră conținutul tău suficient de demn de încredere pentru a-l recomanda. O mențiune poate fi de tipul „Unele surse sugerează…”, în timp ce o recomandare sună „Potrivit [Sursă], dovezile arată că…”. Diferența constă în scorul din matricea de dovezi din Faza 5. Sursele cu Q-ID-uri consistente, arhitectură documentară bine structurată și confirmare în surse independente ajung la statut de recomandare. Sursele cu referințe ambigue, coerență structurală slabă sau afirmații izolate rămân simple mențiuni. Pentru branduri, această distincție e critică: a fi recuperat nu înseamnă a fi citat ca autoritate. Drumul de la recuperare la recomandare necesită claritate semantică, integritate structurală și densitate a dovezilor—factori pe care optimizarea SEO tradițională nu îi abordează.
Înțelegerea modului în care LLM-urile selectează sursele are implicații imediate și practice pentru strategia de conținut. În primul rând, implementează marcaj Schema.org constant pe site-ul tău, mai ales pentru informații organizaționale, articole și entități cheie. Folosește formatul JSON-LD cu atribute @id și linkuri sameAs către Wikidata, Wikipedia sau alte surse autoritare. Aceste date structurate îți cresc direct ponderea dovezilor în Faza 5. În al doilea rând, stabilește identificatori clari de entitate pentru organizația, produsele și conceptele tale cheie. Folosește denumiri consecvente, evită abrevierile ambigue și leagă entitățile prin relații ierarhice (isPartOf, about, mentions). În al treilea rând, creează dovezi lizibile de mașină publicând date structurate despre afirmațiile, acreditările și relațiile tale. Nu scrie doar „Suntem liderul X”—structurează această afirmație cu date de susținere, citări și relații verificabile. În al patrulea rând, menține consistența conținutului între platforme și perioade de timp. LLM-urile evaluează densitatea dovezilor verificând dacă afirmațiile sunt confirmate de surse independente; afirmațiile izolate pe o singură platformă au pondere mai mică. În al cincilea rând, înțelege că metricele SEO tradiționale nu prezic citarea AI. Clasamentele ridicate în căutare nu garantează recomandări LLM; concentrează-te pe claritatea semantică și integritatea structurală. În al șaselea rând, monitorizează-ți tiparele de citare cu instrumente precum AmICited, care urmăresc modul în care diverse sisteme AI fac referire la brandul tău. Acest lucru arată dacă ajungi la statutul de mențiune sau recomandare și ce tipuri de conținut declanșează citări. În final, recunoaște că vizibilitatea AI este o investiție pe termen lung. Datele structurate pe care le implementezi azi modelează atât probabilitatea imediată de citare (efect tranzitoriu), cât și baza internă de cunoștințe a modelului în viitoarele cicluri de antrenare (efect persistent).
Pe măsură ce LLM-urile evoluează, mecanismele de citare devin tot mai sofisticate și transparente. Modelele viitoare vor implementa probabil grafuri de citare—hărți explicite care arată nu doar ce surse au fost citate, ci și cum au influențat afirmațiile specifice din răspuns. Unele sisteme avansate experimentează deja cu scoruri probabilistice de încredere atașate citărilor, care indică cât de sigur este modelul de relevanța și fiabilitatea sursei. O altă tendință emergentă este verificarea cu om în buclă, unde utilizatorii pot contesta citările și oferi feedback care rafinează ponderarea dovezilor pentru interogările viitoare. Integrarea datelor structurate în ciclurile de antrenare înseamnă că organizațiile care își construiesc infrastructura semantică astăzi își consolidează de fapt autoritatea pe termen lung în sistemele AI. Spre deosebire de clasamentele motoarelor de căutare, care pot fluctua în funcție de actualizările algoritmice, efectul persistent al datelor structurate creează o fundație mai stabilă pentru vizibilitatea AI. Această tranziție de la vizibilitatea tradițională (a fi găsit) la autoritate semantică (a fi de încredere) reprezintă o schimbare fundamentală a modului în care brandurile ar trebui să abordeze comunicarea digitală. Câștigătorii în acest nou peisaj nu vor fi cei cu cel mai mult conținut sau cele mai bune poziții în căutare, ci cei care își structurează informația astfel încât mașinile să o poată înțelege, verifica și recomanda în mod fiabil.
Cazul L folosește doar datele de antrenament din baza de cunoștințe parametrică a modelului, în timp ce Cazul L+O suplimentează acestea cu cercetare web în timp real. Pragul de încredere al modelului determină ce cale este urmată. Această distincție este esențială, deoarece stabilește dacă sursele externe pot fi evaluate și citate sau nu.
Ponderarea dovezilor determină această distincție. Sursele cu date structurate, identificatori consistenți și confirmare inter-document sunt ridicate la nivel de „recomandare”, nu doar mențiune. O sursă poate apărea în rezultatele căutării, dar să nu ajungă la statutul de recomandare dacă scorul de dovezi este insuficient.
Datele structurate (JSON-LD, @id, sameAs, Q-ID-uri) primesc o pondere de 2-3 ori mai mare în matricile de dovezi. Acest markup permite legarea entităților și verificarea inter-document, crescând dramatic scorul de fiabilitate al sursei. Sursele cu implementare corectă Schema.org au șanse mult mai mari să fie citate ca fiind autoritare.
Recunoașterea entităților este modul în care LLM-urile identifică și disting între diferite entități (organizații, persoane, concepte). Identificarea clară a entităților prin denumiri consistente și identificatori structurați previne confuzia și crește probabilitatea de citare. Referințele ambigue la entități se pierd în procesul de raționament al modelului.
Sistemele RAG recuperează și clasifică activ sursele în timp real, făcând selecția citărilor mai transparentă și bazată pe dovezi decât cunoașterea pur parametrică. Acest mecanism explicit de recuperare creează tipare de citare măsurabile care pot fi urmărite și analizate cu instrumente de monitorizare precum AmICited.
Da. Implementează marcaj Schema.org în mod constant, stabilește identificatori clari de entități, creează dovezi lizibile de mașină, menține consistența conținutului între platforme și monitorizează-ți tiparele de citare. Acești factori influențează direct dacă conținutul tău ajunge la statut de mențiune sau recomandare în răspunsurile LLM.
Vizibilitatea tradițională măsoară acoperirea și clasarea în rezultatele căutării. Vizibilitatea AI măsoară dacă conținutul tău este recunoscut ca dovadă autoritară în procesele de raționament ale LLM-urilor. A fi recuperat nu este același lucru cu a fi citat ca sursă de încredere — pentru aceasta este nevoie de claritate semantică și integritate structurală.
AmICited urmărește modul în care sistemele AI fac referire la brandul tău în GPT-uri, Perplexity și Google AI Overviews. Dezvăluie dacă atingi statutul de mențiune sau recomandare, ce tipuri de conținut declanșează citări și cum se compară tiparele tale de citare pe diferite platforme AI.
Înțelege cum LLM-urile fac referire la brandul tău în ChatGPT, Perplexity și Google AI Overviews. Urmărește tiparele de citare și optimizează pentru vizibilitate AI cu AmICited.
Află cum să identifici și să țintești site-urile sursă LLM pentru backlink-uri strategice. Descoperă care platforme AI citează cel mai mult sursele și optimizea...

Descoperă cum grounding-ul LLM și căutarea pe web permit sistemelor AI să acceseze informații în timp real, să reducă halucinațiile și să ofere citări corecte. ...

Definiție cuprinzătoare a modelelor lingvistice mari (LLM): sisteme AI antrenate pe miliarde de parametri pentru a înțelege și genera limbaj. Află cum funcțione...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.