
Cum să testezi accesul crawlerelor AI la site-ul tău web
Află cum să testezi dacă crawler-ele AI precum ChatGPT, Claude și Perplexity pot accesa conținutul site-ului tău web. Descoperă metode de testare, instrumente ș...
10 min citire

Află cum să folosești robots.txt pentru a controla ce boti AI accesează conținutul tău. Ghid complet pentru blocarea GPTBot, ClaudeBot și a altor crawleri AI, cu exemple practice și strategii de configurare.
Peisajul crawlingului web s-a schimbat fundamental în ultimii doi ani, depășind teritoriul familiar al indexării motoarelor de căutare și intrând într-o lume complexă a antrenării modelelor AI. În timp ce Googlebot de la Google a fost mult timp un vizitator previzibil pe site-urile editorilor, o nouă generație de crawleri sosește acum cu intenții și modele de consum radical diferite. GPTBot de la OpenAI are un raport crawl-to-refer de aproximativ 1.700:1, ceea ce înseamnă că accesează 1.700 de pagini pentru a genera o singură trimitere către site-ul tău, în timp ce ClaudeBot de la Anthropic operează la un raport și mai extrem de 73.000:1—foarte diferit de raportul Google de 14:1, unde activitatea de crawling se traduce în trafic semnificativ. Această diferență fundamentală creează o decizie urgentă de business pentru creatorii de conținut: permițând acestor boti acces nerestricționat, conținutul tău antrenează modele AI care concurează cu traficul și veniturile tale, în timp ce site-ul primește o compensație sau trafic minim în schimb. Editorii trebuie acum să decidă activ dacă valoarea accesului botilor AI se aliniază cu modelul lor de business, transformând configurarea robots.txt dintr-o considerare tehnică într-o necesitate strategică de business.
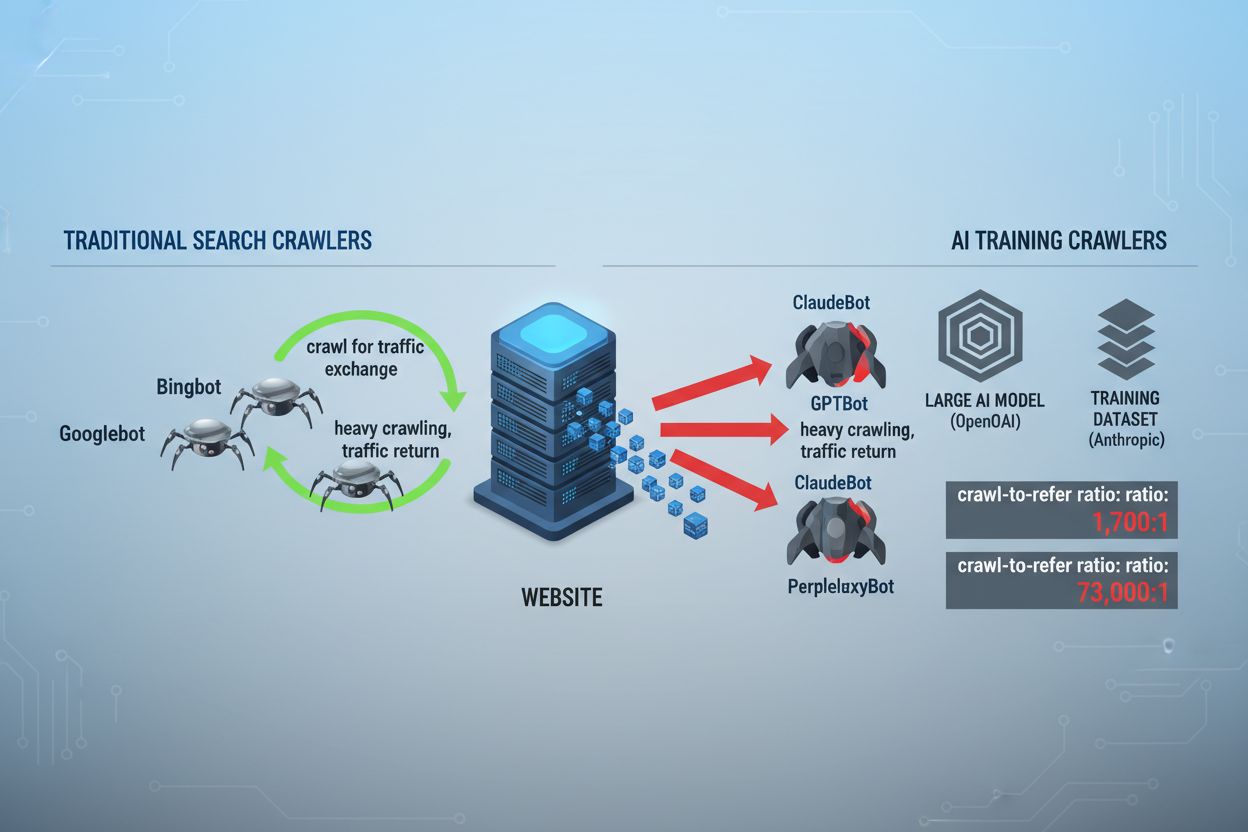
Crawlerii AI operează în trei categorii distincte, fiecare servind scopuri diferite și necesitând strategii diferite de blocare. Crawlerii de antrenare sunt proiectați să preia volume mari de conținut pentru antrenarea modelelor AI fundamentale – aceștia includ GPTBot (OpenAI), ClaudeBot (Anthropic), Google-Extended (Google), PerplexityBot (Perplexity), Meta-ExternalAgent (Meta), Applebot-Extended (Apple) și jucători emergenți ca Amazonbot, Bytespider și cohere-ai. Crawlerii de căutare, în schimb, alimentează experiențe de căutare AI și de obicei returnează trafic editorilor; aici intră OAI-SearchBot (OpenAI), Claude-Web (Anthropic) și funcționalitatea de căutare a Perplexity. Agenții declanșați de utilizator reprezintă a treia categorie, unde conținutul este accesat la cerere când un utilizator solicită explicit informații, cum ar fi interacțiunile ChatGPT-User sau Claude-Web inițiate direct de utilizatori. Înțelegerea acestei taxonomii este critică deoarece strategia ta de blocare trebuie să reflecte prioritățile de business—poți dori crawleri de căutare care aduc trafic, dar să blochezi crawlerii de antrenare care consumă conținut fără compensație. Fiecare companie AI majoră are propria flotă de crawleri specializați, iar diferența dintre ei constă adesea în șirul user agent utilizat, ceea ce face identificarea exactă și blocarea țintită esențiale pentru o configurare robots.txt eficientă.
| Companie | Crawler Antrenare | Crawler Căutare | Agent Declanșat de Utilizator |
|---|---|---|---|
| OpenAI | GPTBot | OAI-SearchBot | ChatGPT-User |
| Anthropic | ClaudeBot, anthropic-ai | Claude-Web | claude-web |
| Google-Extended | — | (Folosește Googlebot standard) | |
| Perplexity | PerplexityBot | PerplexityBot | Perplexity-User |
| Meta | Meta-ExternalAgent | — | Meta-ExternalFetcher |
| Apple | Applebot-Extended | — | Applebot |
Menținerea unei liste corecte și actualizate de user agent pentru boti AI este esențială pentru o configurare robots.txt eficientă, însă acest peisaj evoluează rapid pe măsură ce apar modele noi și companiile își ajustează strategiile de crawling. Cei mai importanți crawleri de antrenare pe care trebuie să îi cunoști sunt GPTBot (crawlerul principal de antrenare al OpenAI), ClaudeBot (Anthropic), anthropic-ai (identificator alternativ Anthropic), Google-Extended (token AI Google), PerplexityBot (Perplexity), Meta-ExternalAgent (Meta), Applebot-Extended (Apple), CCBot (Common Crawl), Amazonbot, Bytespider (ByteDance), cohere-ai (Cohere), DuckAssistBot (DuckDuckGo) și YouBot (You.com). Crawlerii axați pe căutare, care de obicei returnează trafic, includ OAI-SearchBot, Claude-Web și PerplexityBot în modul căutare. Provocarea critică este că această listă nu este statică – apar constant companii AI noi, companiile existente lansează noi crawleri pentru produse noi, iar șirurile user agent se pot schimba sau extinde. Editorii ar trebui să trateze robots.txt ca pe un document viu ce necesită revizuire și actualizare trimestrială, eventual abonându-se la resurse de monitorizare din industrie sau analizând logurile serverului pentru user agent necunoscuți care pot semnala apariția unor noi crawleri AI. Nemenținerea listei actualizate poate însemna fie permiterea accidentală a unor crawleri de antrenare pe care doreai să-i blochezi, fie blocarea inutilă a unor crawleri de căutare legitimi ce pot aduce trafic valoros.
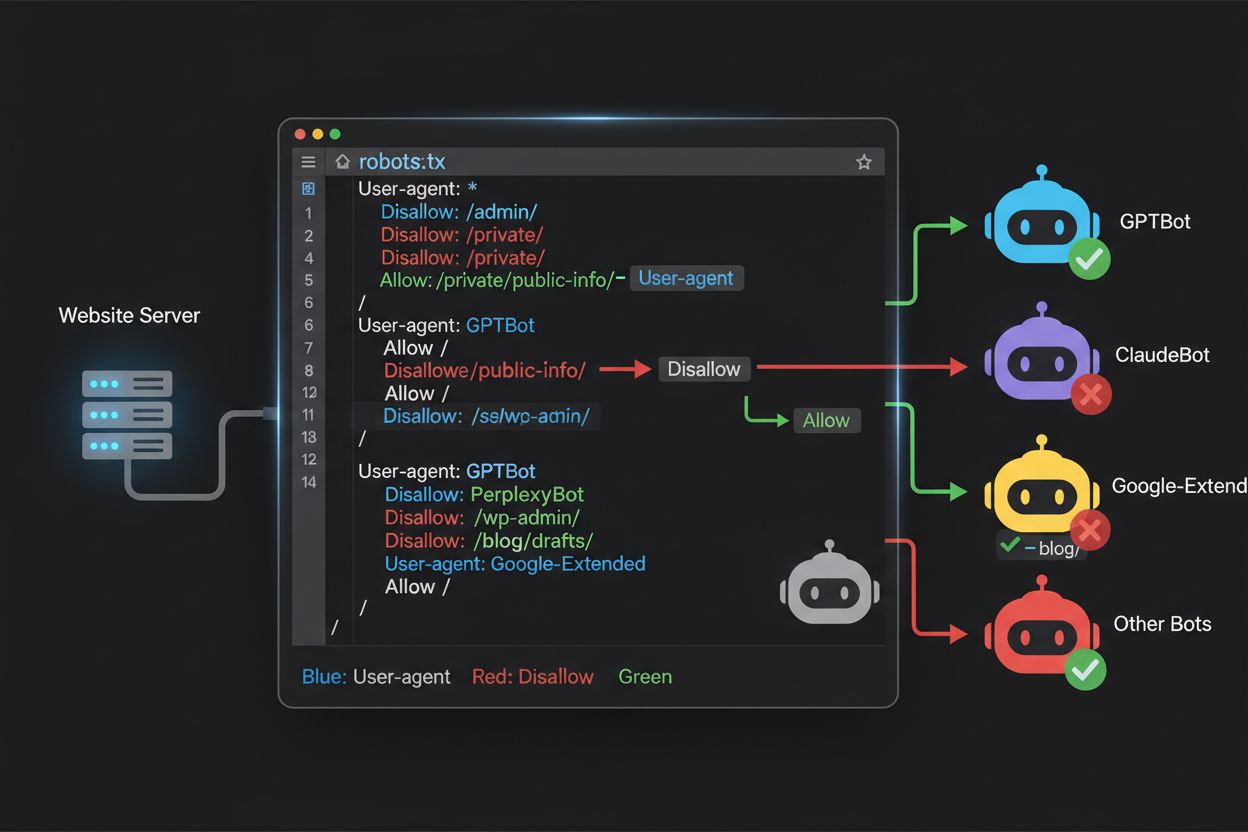
Fișierul robots.txt, aflat la rădăcina domeniului tău (yourdomain.com/robots.txt), folosește o sintaxă simplă pentru a comunica preferințele către boti care respectă protocolul. Fiecare regulă începe cu directiva User-Agent care specifică botul căruia i se aplică regula, urmată de una sau mai multe directive Disallow care indică ce căi nu pot fi accesate. Pentru a bloca toți crawlerii importanți de antrenare AI păstrând accesul crawlerilor de căutare tradiționali, creezi blocuri User-Agent separate pentru fiecare crawler de antrenare pe care vrei să-l excluzi: GPTBot, ClaudeBot, anthropic-ai, Google-Extended, PerplexityBot, Meta-ExternalAgent, Applebot-Extended și alții, fiecare cu directiva “Disallow: /” pentru a preveni crawlingul oricărui conținut. În paralel, te asiguri că crawlerii legitimi precum Googlebot, Bingbot și variantele de căutare AI rămân neblocați. Un robots.txt configurat corect ar trebui să includă și o referință la Sitemap spre sitemap-ul XML, care ajută motoarele de căutare să descopere și să indexeze eficient conținutul. Importanța unei configurări corecte nu poate fi subestimată – o singură eroare de sintaxă, un caracter greșit sau un user agent incorect poate anula întreaga strategie, permițând accesul crawlerilor nedoriți sau blocând surse legitime de trafic. Testarea configurației înainte de implementare este așadar esențială pentru a te asigura că robots.txt își atinge scopul.
# Blochează crawlerii de antrenare AI
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: DuckAssistBot
Disallow: /
User-agent: YouBot
Disallow: /
# Permite motoarele de căutare tradiționale
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Referință Sitemap
Sitemap: https://yoursite.com/sitemap.xml
Mulți editori se confruntă cu o decizie nuanțată: doresc să-și păstreze vizibilitatea în rezultatele de căutare AI și să primească traficul generat de aceste platforme, dar vor să prevină folosirea conținutului pentru antrenarea modelelor AI de bază care le pot concura business-ul. Această strategie de blocare selectivă necesită diferențierea între crawlerii de căutare și cei de antrenare ai aceleiași companii—de exemplu, permițând OAI-SearchBot de la OpenAI (care alimentează căutarea ChatGPT și returnează trafic), dar blocând GPTBot (care antrenează modelul). Similar, poți permite crawlerul de căutare al Perplexity, dar bloca operațiunile de antrenare, sau permite Claude-Web pentru căutări inițiate de utilizator, blocând activitățile de antrenare ale ClaudeBot. Rațiunea de business este clară: crawlerii de căutare operează la rapoarte crawl-to-refer mult mai mici, fiind proiectați să aducă trafic pe site, în timp ce crawlerii de antrenare consumă conținut la scară mare cu beneficii reciproce minime. Această abordare necesită configurări atente și monitorizare permanentă, deoarece companiile își pot schimba strategiile sau introduce user agent noi ce estompează linia dintre căutare și antrenare. Editorii care urmează această strategie ar trebui să auditeze regulat logurile serverului pentru a verifica dacă crawlerii doriți accesează conținutul și cei blocați sunt excluși, ajustând robots.txt pe măsură ce peisajul AI evoluează.
# Permite crawlerii AI de căutare
User-agent: OAI-SearchBot
Allow: /
User-agent: Perplexity-User
Allow: /
User-agent: ChatGPT-User
Allow: /
# Blochează crawlerii de antrenare
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
Chiar și webmasterii experimentați fac frecvent erori de configurare care compromit complet strategia robots.txt, lăsând conținutul vulnerabil crawlerilor pe care voiau să-i blocheze. Prima greșeală comună este crearea de linii User-Agent fără directive Disallow corespunzătoare—de exemplu, scriind “User-Agent: GPTBot” pe o linie și trecând imediat la o regulă nouă fără a specifica ce îi este interzis, ceea ce lasă botul complet neblocat. A doua greșeală implică locația sau denumirea greșită a fișierului sau sensibilitatea la majuscule; fișierul trebuie să se numească exact “robots.txt” (cu litere mici), să fie la rădăcina domeniului și să fie servit cu cod HTTP 200—plasarea într-un subdirector sau denumirea “Robots.txt” sau “robots.TXT” îl face invizibil crawlerilor. A treia greșeală este inserarea de linii goale în interiorul unui bloc de reguli, ceea ce mulți parsere interpretează ca sfârșitul acelei reguli, iar directivele ulterioare sunt ignorate sau aplicate greșit. A patra greșeală se referă la sensibilitatea la majuscule în căile URL; numele user agent nu țin cont de majuscule, dar căile din Disallow sunt sensibile, deci “Disallow: /Admin” nu va bloca “/admin” sau “/ADMIN”. O altă greșeală este utilizarea incorectă a wildcard-ului—așteriscul (*) corespunde oricărei secvențe de caractere, dar mulți editori îl folosesc greșit, scriind “Disallow: .pdf” când ar trebui “Disallow: /.pdf” sau “Disallow: /*pdf” pentru a corespunde extensiilor de fișier. În plus, unii editori creează reguli prea complexe cu directive Disallow contradictorii sau nu iau în calcul parametrii URL și șirurile de interogare, ceea ce poate duce la blocarea conținutului legitim sau lăsarea accesului la conținut nedorit. Testarea configurației cu validatoare dedicate robots.txt înainte de implementare poate descoperi aceste erori înainte să afecteze crawlabilitatea site-ului.
Greșeli Comune de Evitat:
Google-Extended reprezintă un caz unic în configurarea robots.txt deoarece funcționează ca un token de control, nu ca un crawler tradițional, și înțelegerea acestei distincții este critică pentru decizii informate de blocare. Spre deosebire de Googlebot, care accesează site-ul pentru indexarea în Google Search, Google-Extended este un semnal ce controlează dacă conținutul tău poate fi folosit pentru antrenarea modelelor Gemini AI și pentru funcția AI Overviews în rezultatele de căutare Google. Blocarea Google-Extended previne folosirea conținutului tău în antrenarea Gemini și în generarea AI Overviews, dar nu îți afectează vizibilitatea în căutarea Google tradițională—Googlebot va continua să indexeze conținutul tău normal. Compromisul este semnificativ: blocând Google-Extended, conținutul tău nu va apărea în AI Overviews, care sunt tot mai proeminente și pot aduce trafic, dar îți protejezi conținutul de a fi folosit la antrenarea unui model AI concurent. Pe de altă parte, permițând Google-Extended, conținutul tău poate apărea în AI Overviews (posibil generând trafic), dar va contribui și la datele de antrenare Gemini, ceea ce pe termen lung poate concura cu conținutul sau modelul tău de business. Editorii ar trebui să analizeze cu grijă situația proprie—organizațiile media și creatorii de conținut care depind de trafic direct pot beneficia de blocare, în timp ce alții pot dori vizibilitate și potențial de trafic din AI Overviews. Această decizie trebuie luată intenționat, nu implicit, deoarece are implicații importante pentru vizibilitatea și traficul tău pe termen lung în ecosistemul Google Search.
Testarea configurației robots.txt înainte de implementarea în producție este absolut critică, deoarece erorile pot avea consecințe importante atât pentru vizibilitatea în căutare, cât și pentru strategia de protecție a conținutului. Google Search Console oferă un tester robots.txt integrat ce permite verificarea accesului user agent-ilor la anumite URL-uri – poți introduce un string ca “GPTBot” și o cale URL pentru a vedea dacă botul ar fi permis sau blocat de configurația ta. Merkle Robots.txt Tester oferă funcționalități similare, cu o interfață prietenoasă și explicații detaliate despre interpretarea regulilor. TechnicalSEO.com furnizează un alt instrument gratuit ce validează sintaxa robots.txt și arată exact cum vor fi tratați diferiți boti. Pentru monitorizare mai cuprinzătoare, Knowatoa AI Search Console oferă instrumente specializate pentru urmărirea activității crawlerilor AI și validarea configurației pentru boții pe care dorești să-i blochezi. Fluxul tău de validare ar trebui să includă încărcarea robots.txt într-un mediu de testare, verificarea că paginile critice rămân accesibile, confirmarea că boții AI vizați sunt blocați și monitorizarea logurilor pentru activitate neașteptată. Această etapă de testare trebuie să includă și verificarea corectitudinii referinței la Sitemap și că motoarele de căutare pot accesa în continuare normal conținutul—vrei să blochezi crawlerii de antrenare AI fără să blochezi din greșeală traficul legitim. Doar după testare riguroasă ar trebui să implementezi configurația în producție, continuând să monitorizezi logurile în prima săptămână pentru a surprinde eventuale probleme.
Instrumente de Testare:
Deși robots.txt este o primă linie de apărare utilă, trebuie să înțelegi că funcționează pe baza unui sistem de onoare – boții care respectă protocolul vor urma directivele, dar crawlerii rău intenționați sau prost proiectați pot ignora robots.txt și accesa oricum conținutul. Datele din industrie sugerează că robots.txt oprește cu succes aproximativ 40-60% dintre crawlerii nedoriți, ceea ce înseamnă că 40-60% din boti ignoră protocolul sau sunt proiectați să-l ocolească. Pentru o protecție mai robustă, sunt necesare straturi suplimentare. Firewall-ul de aplicație web Cloudflare (WAF) permite crearea de reguli ce blochează traficul pe baza user agent, a adreselor IP sau a unor tipare comportamentale, oferind protecție împotriva botilor ce ignoră robots.txt. Unelte la nivel de server precum .htaccess (pe Apache) sau configurări similare pe Nginx pot bloca user agent sau IP-uri chiar înainte ca cererile să ajungă la aplicație. Blocarea IP este eficientă dacă identifici intervalele IP folosite de crawleri, dar necesită mentenanță constantă pe măsură ce infrastructura crawlerilor se schimbă. Fail2ban și alte unelte pot bloca automat IP-urile cu comportament suspect (cereri la viteză inumană, acces la căi sensibile). Totuși, implementarea acestor protecții suplimentare necesită configurare atentă—blocarea prea agresivă poate exclude trafic legitim, inclusiv utilizatori reali care accesează site-ul prin VPN sau proxy-uri corporative ce împart IP-uri cu crawlerii cunoscuți. Abordarea optimă combină robots.txt ca cerere politicosă, blocarea user agent la nivel de server pentru boti ce ignoră robots.txt și monitorizare comportamentală pentru a surprinde crawleri sofisticați ce falsifică user agent sau folosesc IP-uri distribuite. Editorii ar trebui să implementeze aceste straturi treptat, testând fiecare pentru a evita blocarea accidentală a traficului legitim și asigurându-se că ating obiectivele de protecție a conținutului.
Înțelegerea a ceea ce accesează efectiv site-ul tău este esențială pentru a valida că robots.txt funcționează conform intenției și pentru a identifica noi crawleri ce ar putea necesita blocare. Analiza logurilor serverului este metoda principală pentru această monitorizare—logurile serverului web (Apache, Nginx sau echivalent) conțin înregistrări detaliate ale fiecărei cereri, inclusiv user agent, IP, dată și resursa solicitată. Poți folosi instrumente de linie de comandă ca grep pentru a căuta user agent specifici; de exemplu, “grep ‘GPTBot’ /var/log/apache2/access.log” va arăta toate cererile de la GPTBot, permițându-ți să verifici dacă regulile de blocare funcționează. Analiza mai avansată poate implica parcurgerea logurilor pentru a identifica rata de crawling a diferiților boti, paginile accesate și dacă respectă directivele robots.txt. Soluții automate pot analiza continuu logurile și alerta când apar crawlere noi sau neașteptate, util în contextul evoluției rapide a peisajului crawlerilor AI. Unii editori folosesc platforme de agregare a logurilor precum ELK Stack, Splunk sau soluții cloud pentru a centraliza și analiza activitatea crawlerilor pe mai multe servere. Deoarece peisajul crawlerilor AI se schimbă constant, monitorizarea nu e o sarcină unică, ci una continuă—apar regulat boti noi, user agent-ii se schimbă, iar comportamentul crawlerilor evoluează. Stabilirea unei rutine de monitorizare (revizuiri săptămânale sau lunare ale logurilor) te ajută să rămâi la curent și să ajustezi robots.txt proactiv, nu reactiv după ce apar probleme.
Configurarea robots.txt pentru crawlerii AI este, în esență, o decizie de venit și merită aceeași atenție strategică ca orice decizie de business cu impact financiar semnificativ. Permițând crawlerilor de antrenare acces nerestricționat la conținut, modele AI antrenate pe datele tale pot concura în viitor cu traficul și veniturile tale—dacă modelul de business depinde de trafic direct, vizibilitate în căutare sau venituri din publicitate, oferi practic date gratuite companiilor ce construiesc produse concurente. Pe de altă parte, blocarea tuturor crawlerilor AI înseamnă pierderea vizibilității potențiale în rezultatele de căutare AI și a traficului de referință din asistenți AI, care reprezintă o parte tot mai mare din modul în care utilizatorii descoperă conținut. Strategia optimă depinde de modelul tău de business: editorii susținuți prin publicitate pot beneficia de permiterea crawlerilor de căutare (care aduc trafic și afișări de reclame), blocând crawlerii de antrenare (care nu aduc trafic). Editorii pe bază de abonament pot adopta o abordare mai agresivă, blocând majoritatea crawlerilor AI pentru a-și proteja conținutul de a fi sumarizat sau replicat de sisteme AI. Cei axați pe vizibilitate de brand pot dori vizibilitate în căutarea AI ca formă de distribuție. Esențial e să iei această decizie intenționat, nu implicit—mulți editori nu și-au configurat niciodată robots.txt pentru crawleri AI, permițând implicit toți boții, deci au decis pasiv să contribuie la antrenarea AI fără să aleagă activ asta. Ia în considerare și implementarea de schema markup pentru atribuirea corectă când conținutul e folosit de sisteme AI, asigurând că traficul și creditul revin pe site-ul tău chiar și când conținutul e referit de asistenți AI. Configurarea robots.txt trebuie să reflecte o strategie de business deliberată, revizuită și actualizată pe măsură ce peisajul AI și prioritățile tale evoluează.
Peisajul crawlerilor AI evoluează cu o rapiditate fără precedent, cu companii noi ce lansează produse AI, companii existente ce introduc noi crawleri și user agent-ii schimbându-se sau extinzându-se regulat. Configurația robots.txt nu ar trebui să fie un fișier “setează și uită”, ci un document viu pe care să-l revizuiești și actualizezi cel puțin trimestrial. Stabilește un proces pentru a monitoriza anunțuri din industrie despre noi crawleri AI, abonează-te la newslettere sau bloguri relevante care urmăresc aceste evoluții și auditează regulat logurile serverului pentru user agent necunoscuți ce pot indica noi crawleri. Când descoperi crawleri noi, cercetează scopul și modelul lor de business pentru a decide dacă se aliniază strategiei tale de protecție, apoi actualizează robots.txt corespunzător. Monitorizează și eficiența configurației urmărind volumele de trafic crawler, raportul dintre cereri crawler și trafic de utilizator, precum și orice schimbări în vizibilitatea ta organică sau traficul de referință din rezultate AI. Unii editori descoperă că strategia inițială de blocare necesită ajustări după câteva luni de date reale—poate blocarea unui crawler are consecințe neașteptate sau permiterea altora aduce trafic mai valoros decât estimat. Fii pregătit să-ți ajustezi strategia pe baza rezultatelor reale, nu a presupunerilor. În final, comunică strategia robots.txt stakeholderilor relevanți—echipa SEO, de conținut și conducerea să înțeleagă de ce anumiți crawleri sunt blocați sau permiși, astfel încât deciziile să rămână consecvente și intenționate pe măsură ce organizația evoluează. Această atenție continuă la managementul crawlerilor asigură că strategia de protecție a conținutului rămâne eficientă și aliniată obiectivelor tale de business, pe măsură ce peisajul AI continuă să se transforme.
Nu. Blocarea crawlerilor de antrenare AI precum GPTBot, ClaudeBot și CCBot nu afectează clasamentul tău în Google sau Bing. Motoarele de căutare tradiționale folosesc alți crawleri (Googlebot, Bingbot) care operează independent. Blochează-i doar dacă vrei să dispari complet din rezultatele căutării.
Crawleri importanți de la OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) și Perplexity (PerplexityBot) declară oficial că respectă directivele robots.txt. Totuși, boții mai mici sau mai puțin transparenți pot ignora configurația, motiv pentru care există strategii de protecție pe mai multe straturi.
Depinde de strategia ta. Blocarea doar a crawlerilor de antrenare (GPTBot, ClaudeBot, CCBot) îți protejează conținutul de antrenarea modelelor, permițând totodată crawlerilor de căutare să te ajute să apari în rezultatele AI. Blocarea completă te elimină din ecosistemele AI.
Revizuiește configurația cel puțin trimestrial. Companiile AI introduc regulat noi crawleri. Anthropic a unit boții 'anthropic-ai' și 'Claude-Web' în 'ClaudeBot', oferind noului bot acces temporar nelimitat pe site-urile care nu și-au actualizat regulile.
Robots.txt este un fișier la rădăcina domeniului care se aplică tuturor paginilor, în timp ce meta robots sunt directive HTML pe pagini individuale. Robots.txt este verificat primul și poate preveni accesarea paginilor, în timp ce meta tagurile sunt citite doar dacă pagina este accesată. Folosește-le pe ambele pentru control complet.
Da. Poți folosi reguli Disallow specifice căii în robots.txt (ex: 'Disallow: /premium/' pentru a bloca doar conținutul premium) sau meta robots pe pagini individuale. Astfel protejezi conținutul sensibil, permițând totuși accesul crawlerilor în alte zone.
Dacă un bot ignoră robots.txt, ai nevoie de metode suplimentare de protecție precum blocare la nivel de server (.htaccess), blocare IP sau reguli WAF. Robots.txt oprește circa 40-60% dintre crawlerii nedoriți, deci protecția pe mai multe straturi este importantă.
Folosește instrumente de testare precum testerul robots.txt din Google Search Console, Merkle Robots.txt Tester sau TechnicalSEO.com pentru a valida configurația. Monitorizează logurile serverului pentru activitatea crawlerilor, ca să verifici că boții blocați sunt excluși, iar cei permiși accesează conținutul.
Robots.txt este doar primul pas. Folosește AmICited pentru a urmări ce sisteme AI citează conținutul tău, cât de des te menționează și asigură-te de atribuire corectă în GPT-uri, Perplexity, Google AI Overviews și multe altele.
Află cum să testezi dacă crawler-ele AI precum ChatGPT, Claude și Perplexity pot accesa conținutul site-ului tău web. Descoperă metode de testare, instrumente ș...

Află cum să faci un audit al accesului crawlerelor AI la site-ul tău. Descoperă ce boturi îți pot vedea conținutul și rezolvă blocajele care împiedică vizibilit...

Află cum firewall-urile pentru aplicații web oferă control avansat asupra crawlerelor AI, dincolo de robots.txt. Implementează reguli WAF pentru a-ți proteja co...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.