Optimizarea datelor de instruire vs. recuperarea în timp real: strategii de optimizare
Compară optimizarea datelor de instruire și strategiile de recuperare în timp real pentru AI. Află când să folosești fine-tuning vs RAG, implicațiile de cost și abordări hibride pentru performanță AI optimă.
Publicat la Jan 3, 2026.Ultima modificare la Jan 3, 2026 la 3:24 am
Optimizarea datelor de instruire și recuperarea în timp real reprezintă abordări fundamental diferite pentru dotarea modelelor AI cu cunoștințe. Optimizarea datelor de instruire presupune încorporarea cunoștințelor direct în parametrii modelului prin fine-tuning pe seturi de date specifice domeniului, creând cunoștințe statice care rămân neschimbate după finalizarea instruirii. Recuperarea în timp real, pe de altă parte, păstrează cunoștințele în afara modelului și aduce informații relevante dinamic în timpul inferenței, permițând acces la informații dinamice care se pot schimba între solicitări. Diferența de bază constă în momentul integrării cunoștințelor în model: optimizarea datelor de instruire are loc înainte de implementare, iar recuperarea în timp real are loc la fiecare apel de inferență. Această diferență fundamentală se reflectă în toate aspectele implementării, de la cerințele de infrastructură la caracteristicile de acuratețe și până la considerațiile de conformitate. Înțelegerea acestei distincții este esențială pentru organizațiile care hotărăsc ce strategie de optimizare se potrivește cel mai bine cazurilor lor de utilizare și constrângerilor specifice.
Cum funcționează optimizarea datelor de instruire
Optimizarea datelor de instruire funcționează prin ajustarea sistematică a parametrilor interni ai modelului, expunându-l la seturi de date selectate, specifice domeniului, în procesul de fine-tuning. Atunci când un model întâlnește de mai multe ori exemple de instruire, acesta internalizează treptat tipare, terminologie și expertiză de domeniu prin backpropagation și actualizări de gradient care remodelează mecanismele de învățare ale modelului. Acest proces permite organizațiilor să insereze cunoștințe specializate — fie terminologie medicală, cadre juridice sau logică de business proprietară — direct în greutățile și biasele modelului. Modelul rezultat devine extrem de specializat pentru domeniul său țintă, adesea atingând performanțe comparabile cu modele mult mai mari; cercetări de la Snorkel AI au demonstrat că modele mai mici fine-tunate pot performa echivalent cu modele de 1.400 de ori mai mari. Caracteristici cheie ale optimizării datelor de instruire includ:
Integrare permanentă a cunoștințelor: După instruire, cunoștințele devin parte din model și nu necesită căutări externe
Reducerea latenței la inferență: Nu există timp suplimentar pentru recuperare în timpul predicției, permițând răspunsuri mai rapide
Stil și formatare consecvente: Modelele învață tipare de comunicare și convenții specifice domeniului
Capacitate de operare offline: Modelele funcționează independent, fără surse externe de date
Cost computațional inițial ridicat: Necesită resurse GPU semnificative și pregătirea de date etichetate
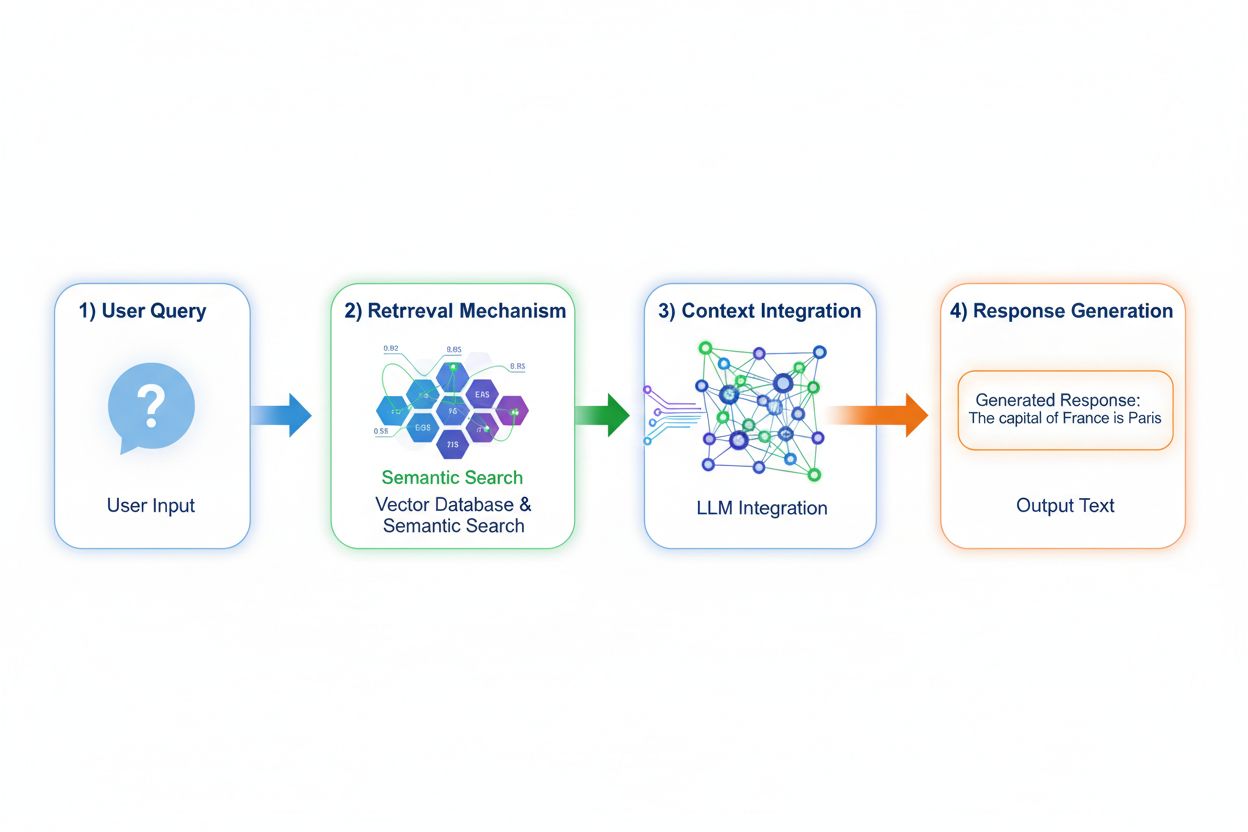
Retrieval Augmented Generation (RAG) schimbă fundamental modul în care modelele accesează cunoștințele, implementând un proces în patru etape: codificarea întrebării, căutare semantică, ordonarea contextului și generarea cu ancorare. Când un utilizator pune o întrebare, RAG o convertește mai întâi într-o reprezentare vectorială densă folosind modele de embedding, apoi caută într-o bază de date vectorială ce conține documente sau surse de cunoștințe indexate. Etapa de recuperare utilizează căutare semantică pentru a găsi pasaje relevante contextual, nu doar potriviri de cuvinte cheie, ordonând rezultatele după scoruri de relevanță. În final, modelul generează răspunsuri menținând referințe explicite la sursele recuperate, ancorând output-ul în date reale, nu doar în parametrii învățați. Această arhitectură permite modelelor să acceseze informații care nu existau la momentul instruirii, făcând RAG deosebit de valoros pentru aplicații ce necesită informații actuale, date proprietare sau baze de cunoștințe actualizate frecvent. Mecanismul RAG transformă astfel modelul dintr-un depozit static de cunoștințe într-un sintetizator dinamic de informații care poate integra date noi fără a fi nevoie de reinstruire.
Comparație de performanță și acuratețe
Profilurile de acuratețe și halucinație ale acestor abordări diferă semnificativ, influențând implementarea practică. Optimizarea datelor de instruire produce modele cu înțelegere profundă a domeniului, dar cu o capacitate limitată de a recunoaște limitările proprii; când un model fine-tunat întâlnește întrebări în afara distribuției sale de instruire, poate genera cu încredere informații plauzibile, dar incorecte. RAG reduce considerabil halucinațiile, ancorând răspunsurile în documente recuperate — modelul nu poate afirma informații care nu apar în sursa sa, creând limite naturale pentru fabricare. Totuși, RAG introduce alte riscuri de acuratețe: dacă etapa de recuperare nu găsește surse relevante sau clasează documente irelevante pe poziții înalte, modelul va genera răspunsuri pe baza unui context slab. Actualitatea datelor devine critică pentru sistemele RAG; optimizarea datelor de instruire captează o imagine statică a cunoștințelor la momentul instruirii, pe când RAG reflectă continuu starea curentă a documentelor sursă. Atribuirea sursei reprezintă o altă distincție: RAG permite citarea și verificarea afirmațiilor, în timp ce modelele fine-tunate nu pot indica sursele exacte pentru cunoștințele lor, complicând verificarea faptelor și conformitatea.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Implicații de cost și infrastructură
Profilurile economice ale acestor abordări generează structuri de cost distincte pe care organizațiile trebuie să le analizeze atent. Optimizarea datelor de instruire necesită costuri computaționale semnificative la început: clustere GPU care rulează zile sau săptămâni pentru fine-tuning, servicii de adnotare a datelor pentru crearea seturilor de date etichetate și expertiză ML pentru proiectarea pipeline-urilor de instruire. După instruire, costurile de servire rămân relativ mici deoarece inferența necesită doar infrastructură standard, fără căutări externe. Sistemele RAG inversează această structură: costuri de instruire inițiale mici (nu se face fine-tuning), dar cheltuieli continue de infrastructură pentru întreținerea bazelor de date vectoriale, servirea modelelor de embedding, servicii de recuperare și pipeline-uri de indexare a documentelor. Factori cheie de cost:
Fine-tuning: ore GPU (10.000-100.000 USD+ per model), adnotare date (0,50-5 USD per exemplu), timp de inginerie
Infrastructură RAG: licențiere baze de date vectoriale, servire modele de embedding, stocare și indexare documente, optimizare latență recuperare
Scalabilitate: modelele fine-tunate se scalează liniar cu volumul de inferență; sistemele RAG se scalează cu volumul de inferență și dimensiunea bazei de cunoștințe
Mentenanță: fine-tuning-ul necesită reinstruire periodică; RAG necesită actualizări continue ale documentelor și mentenanță a indexării
Considerații de securitate și conformitate
Implicațiile de securitate și conformitate diferă semnificativ între aceste abordări, afectând organizațiile din industrii reglementate. Modelele fine-tunate creează provocări de protecție a datelor deoarece datele de instruire devin încorporate în greutățile modelului; extragerea sau auditarea cunoștințelor modelului necesită tehnici sofisticate, iar preocupările de confidențialitate apar atunci când datele sensibile influențează comportamentul modelului. Conformitatea cu reglementări precum GDPR devine complicată, deoarece modelul „își amintește” datele de instruire într-un mod greu de șters sau modificat. Sistemele RAG oferă un profil de securitate diferit: cunoștințele rămân în surse externe, auditate, nu în parametrii modelului, permițând controale de securitate și restricții de acces clare. Organizațiile pot implementa permisiuni detaliate asupra surselor de recuperare, audita ce documente au fost accesate pentru fiecare răspuns și elimina rapid informații sensibile actualizând documentele sursă, fără reinstruire. Totuși, RAG introduce riscuri de securitate legate de protejarea bazei de date vectoriale, de securitatea modelelor de embedding și de faptul că documentele recuperate nu trebuie să divulge informații sensibile. Organizațiile din sănătate reglementate HIPAA și companiile europene supuse GDPR preferă adesea transparența și auditabilitatea RAG, în timp ce organizațiile care prioritizează portabilitatea modelului și operarea offline preferă abordarea self-contained a fine-tuning-ului.
Cadru practic de decizie
Alegerea între aceste abordări necesită evaluarea constrângerilor organizaționale și a caracteristicilor cazului de utilizare. Organizațiile ar trebui să prioritizeze fine-tuning-ul când cunoștințele sunt stabile și nu se schimbă frecvent, când latența inferenței este critică, când modelele trebuie să funcționeze offline sau în medii izolate, sau când stilul și formatarea specifice domeniului sunt esențiale. Recuperarea în timp real devine preferabilă când cunoștințele se modifică regulat, când atribuirea sursei și auditabilitatea contează pentru conformitate, când baza de cunoștințe este prea mare pentru a fi eficient codificată în parametrii modelului sau când organizațiile au nevoie de actualizarea informațiilor fără reinstruirea modelului. Exemple de cazuri de utilizare:
Fine-tuning: boți de suport clienți pentru informații stabile despre produse, asistenți medicali specializați, analiză de documente juridice pentru jurisprudență consacrată
RAG: sisteme de sumarizare de știri cu evenimente actuale, suport clienți cu cataloage de produse actualizate frecvent, asistenți de cercetare accesând literatură științifică dinamică
Cadrul decizional: evaluează stabilitatea cunoștințelor, cerințele de conformitate, constrângerile de latență, frecvența actualizărilor și capacitățile infrastructurii
Abordări hibride și strategii combinate
Abordările hibride combină fine-tuning și RAG pentru a capta beneficiile ambelor strategii, reducând limitările fiecărei metode. Organizațiile pot face fine-tuning pe modele pentru fundamentele domeniului și tipare de comunicare, folosind RAG pentru acces la informații actuale și detaliate — modelul învață cum să gândească într-un domeniu, recuperând ce fapte exacte să încorporeze. Această strategie combinată este deosebit de eficientă pentru aplicații ce necesită atât expertiză specializată, cât și informații curente: un bot de consiliere financiară fine-tunat pe principii și terminologie de investiții poate recupera date de piață și financiare în timp real prin RAG. Implementări hibride reale includ sisteme medicale fine-tunate pe cunoștințe medicale și protocoale, recuperând date specifice pacienților prin RAG, și platforme juridice fine-tunate pe raționament legal, recuperând jurisprudență actuală. Beneficiile sinergice includ halucinații reduse (ancorare în surse recuperate), înțelegere de domeniu îmbunătățită (din fine-tuning), inferență mai rapidă la întrebări frecvente (cunoștințe fine-tunate cache-uite) și flexibilitate de a actualiza informații specializate fără reinstruire. Organizațiile adoptă din ce în ce mai mult această optimizare pe măsură ce resursele computaționale devin mai accesibile și complexitatea aplicațiilor reale cere atât profunzime, cât și actualitate.
Monitorizarea răspunsurilor AI și urmărirea citărilor
Capacitatea de a monitoriza răspunsurile AI în timp real devine tot mai critică pe măsură ce organizațiile implementează aceste strategii de optimizare la scară, în special pentru a înțelege care abordare oferă rezultate mai bune pentru cazuri specifice. Sistemele de monitorizare AI urmăresc output-urile modelelor, calitatea recuperării și metrici de satisfacție a utilizatorilor, permițând organizațiilor să măsoare dacă modelele fine-tunate sau sistemele RAG servesc mai bine aplicațiilor lor. Urmărirea citărilor dezvăluie diferențe esențiale între abordări: sistemele RAG generează natural citări și referințe, creând o urmă de audit a documentelor care au influențat fiecare răspuns, în timp ce modelele fine-tunate nu oferă un mecanism nativ de monitorizare a răspunsurilor sau atribuire. Această distincție contează semnificativ pentru siguranța brandului și inteligența competitivă — organizațiile trebuie să înțeleagă cum sistemele AI citează competitorii, fac referire la produsele lor sau atribuie informații surselor. Instrumente precum AmICited.com acoperă acest gol, monitorizând modul în care sistemele AI citează branduri și companii prin diferite strategii de optimizare, oferind urmărire în timp real a modelelor și frecvenței citărilor. Implementând monitorizare cuprinzătoare, organizațiile pot măsura dacă strategia de optimizare aleasă (fine-tuning, RAG sau hibridă) chiar îmbunătățește acuratețea citărilor, reduce halucinațiile despre competitori și menține atribuirea corectă către surse autoritative. Această abordare bazată pe date permite îmbunătățirea continuă a strategiilor de optimizare pe baza performanței reale, nu a așteptărilor teoretice.
Tendințe viitoare și modele emergente
Industria evoluează către abordări hibride și adaptive tot mai sofisticate, care aleg dinamic între strategii de optimizare în funcție de caracteristicile întrebării și cerințele de cunoștințe. Cele mai bune practici emergente includ implementarea fine-tuning-ului augmentat cu recuperare, unde modelele sunt fine-tunate pe modul de utilizare eficientă a informației recuperate, nu pe memorarea de fapte, și sisteme de rutare adaptivă care direcționează întrebările către modele fine-tunate pentru cunoștințe stabile și către sisteme RAG pentru informații dinamice. Tendințele indică o adopție tot mai mare a modelelor de embedding și a bazelor de date vectoriale specializate pentru domenii, permițând căutare semantică mai precisă și reducerea zgomotului la recuperare. Organizațiile dezvoltă modele de îmbunătățire continuă a modelelor ce combină actualizări periodice de fine-tuning cu augmentare RAG în timp real, creând sisteme care se îmbunătățesc în timp menținând totodată acces la informații actuale. Evoluția strategiilor de optimizare reflectă recunoașterea la nivel de industrie că nicio abordare nu servește optim toate cazurile de utilizare; sistemele viitorului vor implementa probabil mecanisme inteligente de selecție care aleg dinamic între fine-tuning, RAG și abordări hibride pe baza contextului întrebării, stabilității cunoștințelor, cerințelor de latență și constrângerilor de conformitate. Pe măsură ce aceste tehnologii se maturizează, avantajul competitiv se va muta de la alegerea unei singure abordări la implementarea expertă a unor sisteme adaptive care valorifică punctele forte ale fiecărei strategii.
Întrebări frecvente
Care este principala diferență dintre optimizarea datelor de instruire și recuperarea în timp real?
Optimizarea datelor de instruire încorporează cunoștințele direct în parametrii modelului prin fine-tuning, creând cunoștințe statice care rămân neschimbate după instruire. Recuperarea în timp real menține cunoștințele în exterior și aduce informații relevante dinamic la inferență, permițând acces la informații dinamice ce pot varia de la o cerere la alta. Diferența de bază constă în momentul integrării cunoștințelor: optimizarea datelor de instruire are loc înainte de implementare, iar recuperarea în timp real se întâmplă la fiecare apel de inferență.
Când ar trebui să folosesc fine-tuning în loc de RAG?
Folosește fine-tuning când cunoștințele sunt stabile și nu se schimbă frecvent, când latența la inferență este critică, când modelele trebuie să funcționeze offline sau când stilul și formatarea specifice domeniului sunt esențiale. Fine-tuning-ul este ideal pentru sarcini specializate precum diagnostic medical, analiza documentelor juridice sau servicii pentru clienți cu informații stabile despre produse. Totuși, fine-tuning-ul necesită resurse computaționale semnificative la început și devine nepractic atunci când informațiile se schimbă des.
Pot combina optimizarea datelor de instruire cu recuperarea în timp real?
Da, abordările hibride combină fine-tuning și RAG pentru a capta beneficiile ambelor strategii. Organizațiile pot face fine-tuning pe modele cu fundamentele domeniului și să folosească RAG pentru acces la informații actuale și detaliate. Această abordare este deosebit de eficientă pentru aplicații ce necesită atât expertiză specializată, cât și informații curente, precum boți consultanți financiari sau sisteme medicale ce au nevoie atât de cunoștințe medicale, cât și de date specifice pacienților.
Cum reduce RAG halucinațiile comparativ cu fine-tuning-ul?
RAG reduce substanțial halucinațiile ancorând răspunsurile în documente recuperate — modelul nu poate afirma informații care nu apar în sursa sa, creând limite naturale pentru fabricare. Modelele fine-tunate, dimpotrivă, pot genera cu încredere informații plauzibile, dar incorecte, când întâlnesc întrebări în afara distribuției de instruire. Atribuirea sursei în RAG permite și verificarea afirmațiilor, în timp ce modelele fine-tunate nu pot indica sursele exacte pentru cunoștințele lor.
Care sunt implicațiile de cost pentru fiecare abordare?
Fine-tuning-ul necesită costuri inițiale importante: ore GPU (10.000-100.000 USD+ per model), adnotare date (0,50-5 USD per exemplu) și timp de inginerie. După instruire, costurile de servire rămân relativ mici. Sistemele RAG au costuri inițiale mai mici, dar cheltuieli continue pentru infrastructura bazelor de date vectoriale, modele de embedding și servicii de recuperare. Modelele fine-tunate se scalează liniar cu volumul de inferență, iar sistemele RAG se scalează cu volumul de inferență și dimensiunea bazei de cunoștințe.
Sistemele RAG generează în mod natural citări și referințe la surse, creând o urmă de audit a documentelor care au influențat fiecare răspuns. Acest lucru este crucial pentru siguranța brandului și informații competitive — organizațiile pot urmări cum sistemele AI citează competitorii și fac referire la produsele lor. Instrumente precum AmICited.com monitorizează modul în care sistemele AI citează branduri prin diferite strategii de optimizare, oferind urmărire în timp real a modelelor și frecvenței citărilor.
Ce abordare este mai bună pentru industriile cu reglementări stricte?
RAG este în general mai potrivit pentru industriile puternic reglementate, precum sănătate și finanțe. Cunoștințele rămân în surse de date externe, auditate, nu în parametrii modelului, permițând controale de securitate simple și restricții de acces. Organizațiile pot implementa permisiuni detaliate, audita ce documente au fost accesate de model și elimina rapid informațiile sensibile fără retraining. Organizațiile din sănătate reglementate HIPAA și cele supuse GDPR preferă adesea transparența și auditabilitatea RAG-ului.
Cum monitorizez eficiența strategiei mele de optimizare alese?
Implementează sisteme de monitorizare AI care urmăresc output-urile modelului, calitatea recuperării și metrici de satisfacție a utilizatorilor. Pentru RAG, monitorizează acuratețea recuperării și calitatea citărilor. Pentru modelele fine-tunate, urmărește acuratețea pe sarcini specifice domeniului și rata halucinațiilor. Folosește instrumente precum AmICited.com pentru a monitoriza cum sistemele AI citează informații și compară performanța între diferite strategii de optimizare pe baza rezultatelor reale.
Monitorizează cum sistemele AI citează brandul tău
Urmărește citările în timp real în GPT-uri, Perplexity și Google AI Overviews. Înțelege ce strategii de optimizare folosesc competitorii tăi și cum sunt ei menționați în răspunsurile AI.
Cum să-ți Optimizezi Conținutul pentru Datele de Antrenament AI și Motoarele de Căutare AI
Află cum să-ți optimizezi conținutul pentru includerea în datele de antrenament AI. Descoperă cele mai bune practici pentru ca website-ul tău să fie descoperit ...
Cum te poți retrage din antrenarea AI pe principalele platforme
Ghid complet pentru retragerea din colectarea datelor de antrenare AI pe ChatGPT, Perplexity, LinkedIn și alte platforme. Află instrucțiuni pas cu pas pentru a-...
Descoperă adaptarea AI în timp real - tehnologia care permite sistemelor AI să învețe continuu din evenimente și date actuale. Explorează cum funcționează AI ad...
8 min citire
Consimțământ Cookie Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.