Stratul LLM merită o analiză mai detaliată.
Selecția modelului:
Perplexity folosește mai multe LLM-uri:
- GPT-4 Omni (pentru interogări complexe)
- Claude 3 (pentru anumite sarcini)
- Modele custom (pentru eficiență)
- Utilizatorii pot selecta modelul preferat în Pro
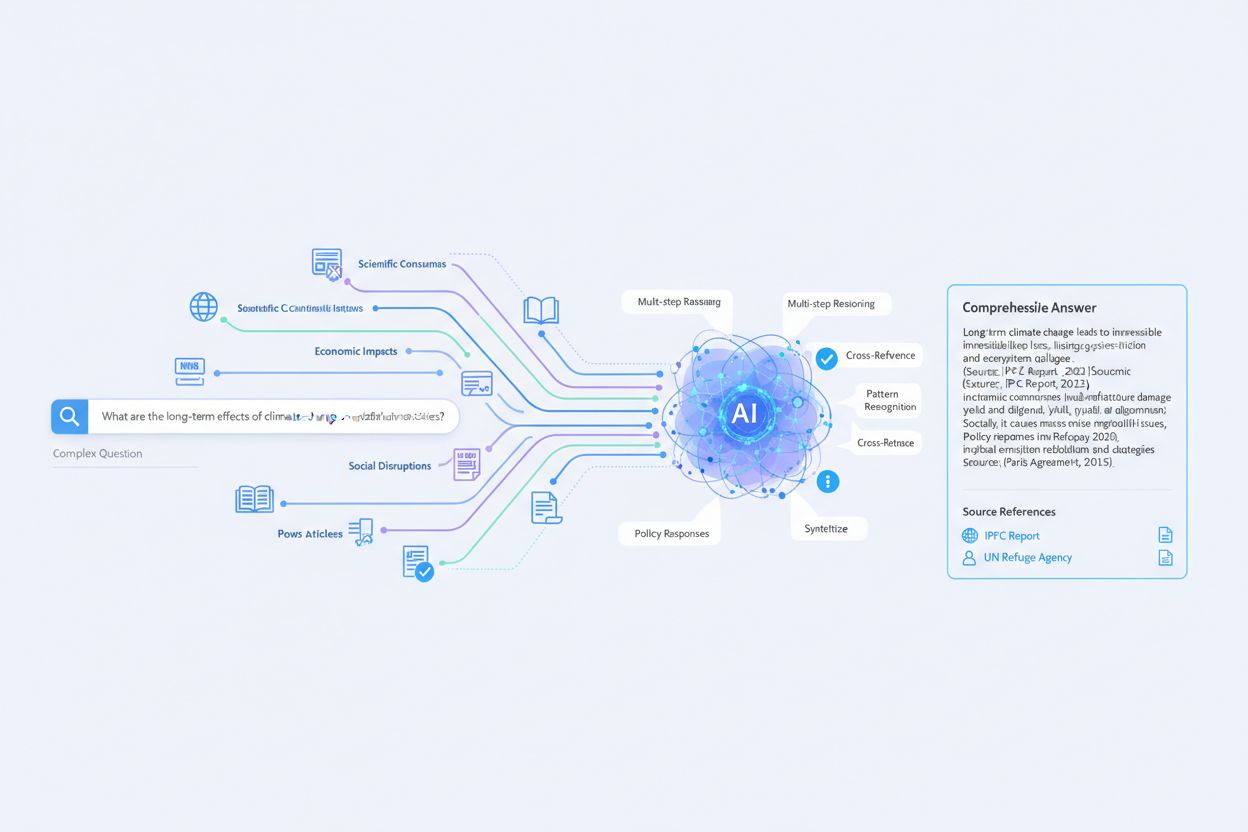
Cum generează LLM-ul răspunsurile citate:
LLM-ul nu copiază pur și simplu textul. El:
- Înțelege intenția interogării
- Citește pasajele recuperate
- Sintetizează un răspuns coerent
- Atribuie fiecare afirmație surselor
- Formatează cu citări
Exemplu de transformare:
Sursa 1: “Calculatoarele cuantice folosesc qubiți care pot exista în superpoziție.”
Sursa 2: “Jucători majori sunt IBM, Google și IonQ.”
Sursa 3: “Descoperiri recente arată procesoare de peste 1000 de qubiți.”
Output Perplexity:
“Calculatoarele cuantice utilizează qubiți care operează în stări de superpoziție [1]. Liderii din industrie IBM, Google și IonQ [2] au realizat recent descoperiri incluzând procesoare de peste 1000 de qubiți [3].”
Sinteza creează text nou păstrând atribuirea corectă.