
Ajustare fină
Definiția ajustării fine: adaptarea modelelor AI pre-antrenate pentru sarcini specifice prin antrenament pe seturi de date de domeniu. Află cum ajustarea fină î...
14 min citire

Ajustarea fină a modelelor AI reprezintă procesul de adaptare a modelelor de inteligență artificială pre-antrenate pentru a îndeplini sarcini specifice sau pentru a lucra cu date specializate, prin ajustarea parametrilor acestora prin instruire suplimentară pe seturi de date dintr-un anumit domeniu. Această abordare valorifică cunoștințele de bază existente, personalizând modelele pentru aplicații de afaceri particulare și permițând organizațiilor să creeze sisteme AI extrem de specializate fără cheltuieli computaționale ridicate asociate antrenării de la zero.
Ajustarea fină a modelelor AI reprezintă procesul de adaptare a modelelor de inteligență artificială pre-antrenate pentru a îndeplini sarcini specifice sau pentru a lucra cu date specializate, prin ajustarea parametrilor acestora prin instruire suplimentară pe seturi de date dintr-un anumit domeniu. Această abordare valorifică cunoștințele de bază existente, personalizând modelele pentru aplicații de afaceri particulare și permițând organizațiilor să creeze sisteme AI extrem de specializate fără cheltuieli computaționale ridicate asociate antrenării de la zero.
Ajustarea fină a modelelor AI reprezintă procesul de preluare a unui model de inteligență artificială pre-antrenat și adaptarea acestuia pentru a îndeplini sarcini specifice sau pentru a lucra cu date specializate. În loc să antrenezi un model de la zero, ajustarea fină valorifică cunoștințele de bază deja încorporate într-un model pre-antrenat și îi ajustează parametrii prin instruire suplimentară pe seturi de date specifice domeniului sau sarcinii. Această abordare combină eficiența transferului de învățare cu personalizarea necesară pentru aplicații de afaceri particulare. Ajustarea fină permite organizațiilor să creeze modele AI extrem de specializate fără cheltuielile computaționale și investiția de timp cerute de antrenarea de la zero, devenind astfel o tehnică esențială în dezvoltarea modernă a învățării automate.
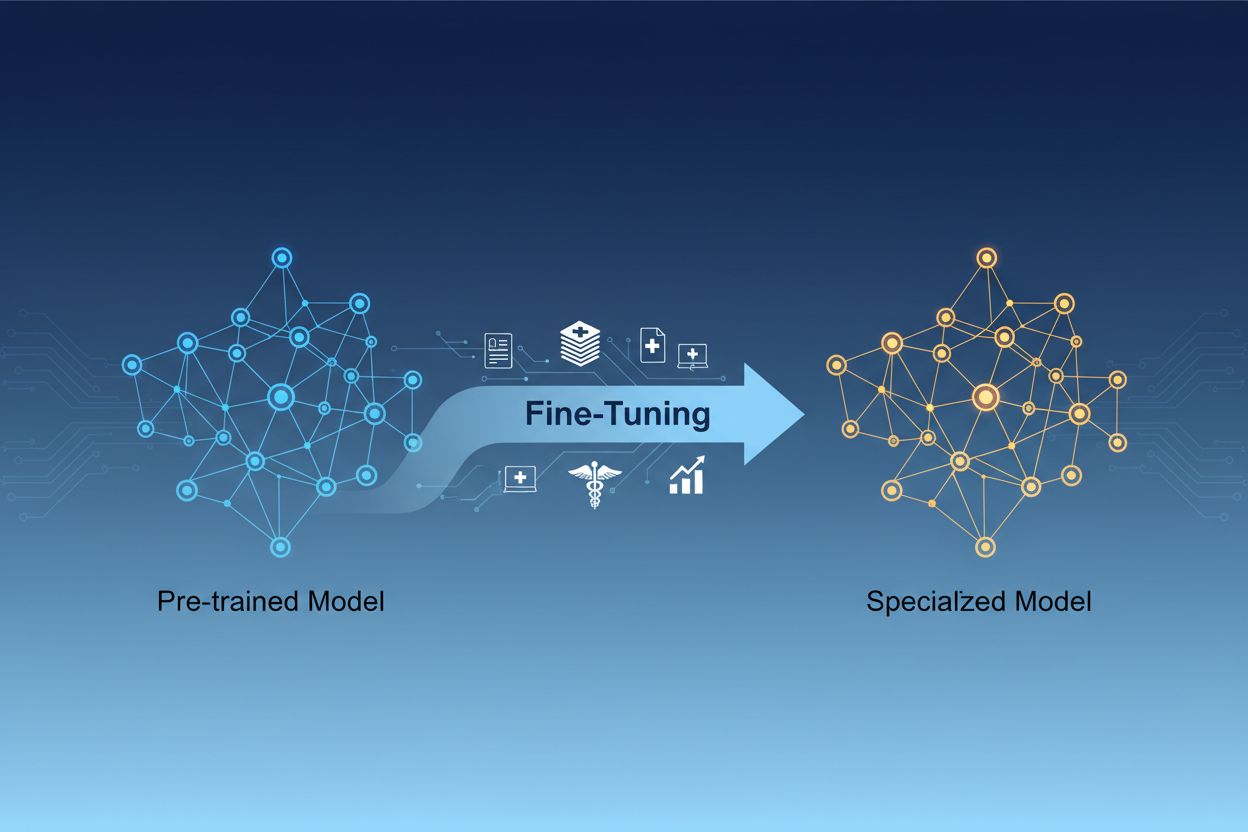
Distincția dintre ajustarea fină și antrenarea de la zero reprezintă una dintre cele mai importante decizii în dezvoltarea de machine learning. Atunci când antrenezi un model de la zero, pornești cu greutăți inițializate aleator și trebuie să înveți modelul totul despre tiparele limbajului, caracteristicile vizuale sau cunoștințele domeniului, folosind seturi de date masive și resurse computaționale substanțiale. Această abordare poate necesita săptămâni sau luni de antrenare și acces la hardware specializat, precum GPU-uri sau TPU-uri. În schimb, ajustarea fină pornește de la un model care deja înțelege tiparele și conceptele fundamentale, necesitând doar o fracțiune din datele și puterea de procesare necesare pentru a-l adapta la nevoile tale specifice. Modelul pre-antrenat a învățat deja caracteristici generale în faza inițială de antrenare, astfel încât ajustarea fină se concentrează pe adaptarea acestor caracteristici la cazul tău de utilizare particular. Acest câștig de eficiență face din ajustarea fină abordarea preferată pentru majoritatea organizațiilor, deoarece reduce atât timpul de lansare pe piață, cât și costurile de infrastructură, oferind adesea performanțe superioare față de antrenarea modelelor mici de la zero.
| Aspect | Ajustare fină | Antrenare de la zero |
|---|---|---|
| Timp de antrenare | Zile până la săptămâni | Săptămâni până la luni |
| Necesar de date | Mii până la milioane de exemple | Milioane până la miliarde de exemple |
| Cost computațional | Moderat (adesea suficient un singur GPU) | Extrem de ridicat (necesită mai multe GPU-uri/TPU-uri) |
| Cunoștințe inițiale | Valorifică greutăți pre-antrenate | Pornește cu inițializare aleatorie |
| Performanță | Adesea superioară cu date limitate | Mai bună cu seturi de date masive |
| Nivel de expertiză necesar | Intermediar | Avansat |
| Grad de personalizare | Ridicat pentru sarcini specifice | Flexibilitate maximă |
| Infrastructură | Resurse cloud standard | Clustere hardware specializate |
Ajustarea fină a devenit o capabilitate esențială pentru organizațiile care doresc să implementeze soluții AI ce oferă avantaje competitive. Prin adaptarea modelelor pre-antrenate la contextul specific al afacerii tale, poți crea sisteme AI care înțeleg terminologia industriei, preferințele clienților și cerințele operaționale cu o acuratețe remarcabilă. Această personalizare permite afacerilor să atingă niveluri de performanță pe care modelele generice, gata de utilizare, pur și simplu nu le pot egala, mai ales în domenii specializate precum sănătatea, serviciile juridice sau suportul tehnic. Rentabilitatea ajustării fine face ca și organizațiile mici să poată accesa capabilități AI la nivel enterprise fără investiții masive în infrastructură. În plus, modelele ajustate fin pot fi implementate mai rapid, permițând companiilor să răspundă prompt la oportunități de piață și presiuni concurențiale. Abilitatea de a îmbunătăți continuu modelele prin ajustare fină pe date noi asigură că sistemele tale AI rămân relevante și eficiente pe măsură ce condițiile de business evoluează.
Beneficii cheie de business ale ajustării fine:
Mai multe tehnici consacrate au apărut ca bune practici în peisajul ajustării fine, fiecare având avantaje distincte în funcție de cerințele tale. Ajustarea fină completă implică actualizarea tuturor parametrilor modelului pre-antrenat, oferind flexibilitate maximă și adesea cele mai bune performanțe, dar necesitând resurse computaționale semnificative și seturi de date mai mari pentru a evita supraînvățarea. Metodele eficiente din punct de vedere al parametrilor, precum LoRA (Low-Rank Adaptation) și QLoRA, au revoluționat domeniul, permițând adaptarea eficientă a modelului prin actualizarea doar a unei mici fracțiuni de parametri, reducând dramatic cerințele de memorie și timpul de antrenare. Aceste tehnici funcționează prin adăugarea de matrici cu rang redus antrenabile la matricile de greutate ale modelului, captând adaptări specifice sarcinii fără a modifica greutățile originale pre-antrenate. Modulele adapter reprezintă o altă abordare, inserând mici rețele antrenabile între straturile modelului pre-antrenat înghețat, permițând ajustare fină eficientă cu un număr minim de parametri suplimentari. Ajustarea fină bazată pe prompturi se concentrează pe optimizarea prompturilor de intrare, nu a greutăților modelului, fiind utilă acolo unde accesul la parametri este limitat. Ajustarea fină pe instrucțiuni antrenează modelele să urmeze instrucțiuni și comenzi specifice, fiind deosebit de importantă pentru modelele lingvistice mari care trebuie să răspundă adecvat unor cereri diverse. Alegerea dintre aceste tehnici depinde de constrângerile tale computaționale, mărimea setului de date, cerințele de performanță și arhitectura specifică a modelului utilizat.
Ajustarea fină a modelelor lingvistice mari (LLM) prezintă oportunități și provocări unice comparativ cu ajustarea modelelor mai mici sau a altor tipuri de rețele neuronale. Modelele LLM moderne de tip GPT conțin miliarde de parametri, ceea ce face ajustarea fină completă prohibitivă din punct de vedere computațional pentru majoritatea organizațiilor. Această realitate a condus la adoptarea tehnicilor eficiente din punct de vedere al parametrilor, care permit adaptarea eficientă a LLM fără a necesita infrastructură la scară enterprise. Ajustarea fină pe instrucțiuni a devenit deosebit de importantă pentru LLM, unde modelele sunt antrenate pe exemple de instrucțiuni împerecheate cu răspunsuri de calitate înaltă, permițându-le să urmeze directivele utilizatorilor mai eficient. Învățarea prin recompensă din feedback uman (RLHF) reprezintă o abordare avansată de ajustare fină, unde modelele sunt rafinate pe baza preferințelor și evaluărilor umane, îmbunătățind alinierea la valorile și așteptările umane. Cantitatea relativ mică de date specifice sarcinii necesare pentru ajustarea fină a LLM — adesea doar câteva sute sau mii de exemple — face această abordare accesibilă organizațiilor fără seturi de date masive etichetate. Totuși, ajustarea fină a LLM necesită atenție sporită la selectarea hiperparametrilor, programarea ratei de învățare și prevenirea uitării catastrofale, unde modelul pierde capabilități învățate anterior în timp ce se adaptează la sarcini noi.

Organizațiile din diverse industrii au descoperit aplicații puternice pentru modelele AI ajustate fin, care aduc valoare de business măsurabilă. Automatizarea serviciului clienți este unul dintre cele mai răspândite cazuri de utilizare, unde modelele sunt ajustate pe tichete de suport specifice companiei, informații despre produse și stiluri de comunicare pentru a crea chatbot-uri ce gestionează solicitările clienților cu expertiză de domeniu și consistența brandului. Analiza documentelor medicale și juridice utilizează ajustarea fină pentru a adapta modelele lingvistice generale la terminologie specializată, cerințe de reglementare și formate specifice industriei, permițând extragerea și clasificarea corectă a informațiilor. Analiza sentimentului și moderarea conținutului pot fi îmbunătățite semnificativ prin ajustarea modelelor pe exemple relevante pentru industria sau comunitatea ta, surprinzând nuanțele de limbaj și contextul pe care modelele generice le ratează. Generarea de cod și asistența în dezvoltarea software beneficiază de ajustarea pe baza codului, a convențiilor de programare și a arhitecturii organizației tale, permițând instrumentelor AI să genereze cod aliniat standardelor tale. Sistemele de recomandare sunt frecvent ajustate pe date despre comportamentul utilizatorilor și cataloage de produse pentru a oferi sugestii personalizate ce cresc engagement-ul și veniturile. Recunoașterea entităților denumite și extragerea informațiilor din documente specifice domeniului — precum rapoarte financiare, lucrări științifice sau specificații tehnice — pot fi îmbunătățite dramatic prin ajustarea pe exemple relevante. Aceste aplicații diverse demonstrează că ajustarea fină nu este limitată la o anumită industrie sau caz de utilizare, ci reprezintă o capabilitate fundamentală pentru crearea de sisteme AI ce aduc avantaje competitive în aproape orice domeniu de afaceri.
Procesul de ajustare fină urmează un flux de lucru structurat, care începe cu o pregătire atentă și se extinde până la implementare și monitorizare. Pregătirea datelor reprezintă primul pas critic, necesitând colectarea, curățarea și formatarea setului de date specific domeniului, astfel încât să corespundă structurii input-output așteptate de modelul pre-antrenat. Acest set de date trebuie să fie reprezentativ pentru sarcinile pe care modelul ajustat fin le va executa în producție, iar calitatea contează mai mult decât cantitatea — un set de date mai mic, dar cu exemple de calitate înaltă, depășește de obicei un set de date mai mare cu etichete inconsistente sau zgomotoase. Împărțirea în seturi de antrenare, validare și testare asigură evaluarea corectă a performanței modelului, cu alocări tipice de 70-80% pentru antrenare, 10-15% pentru validare și 10-15% pentru testare. Selectarea hiperparametrilor presupune alegerea ratelor de învățare, dimensiunii batch-ului, numărului de epoci de antrenare și a altor parametri ce controlează procesul de ajustare, aceste alegeri având impact semnificativ asupra performanței și eficienței antrenării. Inițializarea modelului utilizează greutățile pre-antrenate drept punct de pornire, păstrând cunoștințele de bază și permițând ajustarea parametrilor pentru sarcina ta specifică. Executarea antrenării implică actualizarea iterativă a parametrilor pe datele de antrenare, monitorizând în același timp performanța la validare pentru detectarea supraînvățării. Evaluarea și iterația folosesc setul de testare pentru a evalua performanța finală și a decide dacă este necesară ajustare suplimentară, hiperparametri diferiți sau mai multe date de antrenare pentru îmbunătățirea rezultatelor. Pregătirea pentru implementare include optimizarea modelului pentru viteza de inferență și eficiența resurselor, eventual prin tehnici de cuantizare sau distilare. În final, monitorizarea și mentenanța în producție asigură că modelul continuă să performeze bine pe măsură ce distribuțiile de date se schimbă în timp, cu reantrenări periodice pe date noi pentru a menține acuratețea.
Ajustarea fină, deși mai eficientă decât antrenarea de la zero, aduce propriile provocări pe care practicienii trebuie să le gestioneze cu atenție. Supraînvățarea apare atunci când modelele memorează datele de antrenament în loc să învețe tipare generalizabile, un risc deosebit când se ajustează pe seturi de date mici; acest lucru poate fi atenuat prin tehnici precum oprirea timpurie, regularizarea și augmentarea datelor. Uitarea catastrofală apare când ajustarea fină determină modelul să piardă capabilități învățate anterior, problemă întâlnită mai ales la adaptarea modelelor generale la sarcini specializate; o selecție atentă a ratei de învățare și tehnici precum distilarea cunoștințelor ajută la păstrarea cunoștințelor de bază. Calitatea și etichetarea datelor reprezintă provocări practice semnificative, deoarece ajustarea fină necesită exemple etichetate de înaltă calitate, reprezentative pentru domeniul și cazurile tale de utilizare. Gestionarea resurselor computaționale implică echilibrarea îmbunătățirii performanței cu timpul de antrenare și costurile de infrastructură, aspect deosebit de important la modelele mari. Sensibilitatea la hiperparametri înseamnă că performanța ajustării fine poate varia dramatic în funcție de rata de învățare, dimensiunea batch-ului și alți parametri, necesitând experimentare sistematică și validare.
Bune practici pentru ajustare fină de succes:
Organizațiile se confruntă adesea cu alegerea între trei abordări complementare pentru adaptarea modelelor AI la sarcini specifice: ajustarea fină, Retrieval-Augmented Generation (RAG) și ingineria de prompturi. Ingineria de prompturi presupune formularea atentă a instrucțiunilor și exemplelor pentru a ghida comportamentul modelului fără a-i modifica efectiv parametrii; această abordare este rapidă și nu necesită antrenare, dar are eficiență limitată pentru sarcini complexe și nu poate învăța modelelor informații cu adevărat noi. RAG îmbunătățește răspunsurile modelului prin recuperarea de documente sau date relevante din surse externe înainte de generarea răspunsurilor, permițând accesul la informații actuale și cunoștințe de domeniu fără actualizarea parametrilor; această metodă este potrivită pentru sarcini ce necesită multe cunoștințe, dar adaugă latență și complexitate în inferență. Ajustarea fină modifică parametrii modelului pentru a încorpora profund cunoștințe și tipare specifice sarcinii, oferind cea mai bună performanță pentru sarcini bine definite cu suficiente date de antrenare, dar necesitând mai mult timp și resurse computaționale față de celelalte abordări. Soluția optimă implică adesea combinarea acestor tehnici: ingineria de prompturi pentru prototipare rapidă, RAG pentru aplicații ce necesită informații actualizate sau proprietare și ajustarea fină pentru sisteme critice din punct de vedere al performanței, unde investiția în antrenare este justificată. Ajustarea fină excelează atunci când ai nevoie de comportament consecvent și performant pe sarcini specifice, dispui de suficiente date de antrenare și când câștigurile de performanță justifică efortul de dezvoltare. RAG funcționează cel mai bine pentru aplicații ce necesită acces la informații actuale sau proprietare ce se schimbă frecvent. Ingineria de prompturi este un punct de pornire excelent pentru explorare și prototipare înainte de a investi în abordări mai consumatoare de resurse. Înțelegerea punctelor forte și a limitărilor fiecărei abordări permite organizațiilor să ia decizii informate despre ce tehnici să folosească pentru diferite componente ale sistemelor AI.
Transferul de învățare reprezintă conceptul mai larg de valorificare a cunoștințelor dintr-o sarcină pentru a îmbunătăți performanța pe o altă sarcină, în timp ce ajustarea fină este o implementare specifică a transferului de învățare. Ajustarea fină presupune preluarea unui model pre-antrenat și ajustarea parametrilor pe date noi, în timp ce transferul de învățare poate include și extragerea de caracteristici, unde îngheți greutățile pre-antrenate și antrenezi doar straturi noi. Toată ajustarea fină implică transfer de învățare, dar nu tot transferul de învățare necesită ajustare fină.
Durata ajustării fine variază semnificativ în funcție de dimensiunea modelului, mărimea setului de date și resursele hardware disponibile. Folosind tehnici eficiente din punct de vedere al parametrilor, precum LoRA, un model cu 13 miliarde de parametri poate fi ajustat fin în aproximativ 5 ore pe o singură placă GPU A100. Modelele mai mici sau metodele eficiente pot dura doar câteva ore, în timp ce ajustarea completă a modelelor mari poate dura zile sau săptămâni. Principalul avantaj este că ajustarea fină este mult mai rapidă decât antrenarea de la zero, care poate dura luni.
Da, ajustarea fină este concepută special pentru a funcționa eficient cu date limitate. Modelele pre-antrenate au învățat deja tipare generale, astfel încât în mod obișnuit sunt necesare doar câteva sute sau mii de exemple pentru o ajustare fină eficientă, comparativ cu milioanele necesare pentru antrenarea de la zero. Totuși, calitatea datelor contează mai mult decât cantitatea — un set de date mai mic, dar de înaltă calitate și reprezentativ, va oferi rezultate mai bune decât un set de date mai mare, dar cu etichete inconsistente sau zgomotoase.
LoRA (Low-Rank Adaptation) este o tehnică de ajustare fină eficientă din punct de vedere al parametrilor, care adaugă matrici cu rang redus antrenabile la matricile de greutate ale modelului, în loc să actualizeze toți parametrii. Această abordare reduce numărul de parametri antrenabili de mii de ori, menținând în același timp performanțe comparabile cu ajustarea fină completă. LoRA este importantă deoarece face ajustarea fină accesibilă pe hardware standard, reduce semnificativ cerințele de memorie și permite organizațiilor să ajusteze modele mari fără infrastructură costisitoare.
Supraînvățarea apare atunci când pierderea la antrenare scade, dar pierderea la validare crește, indicând că modelul memorează datele de antrenament în loc să învețe tipare generalizabile. Monitorizează ambele valori în timpul antrenării — dacă performanța la validare stagnează sau scade, în timp ce performanța la antrenare continuă să crească, modelul tău probabil supraînvață. Implementează oprirea timpurie pentru a opri antrenarea când performanța la validare nu se mai îmbunătățește și folosește tehnici precum regularizarea și augmentarea datelor pentru a preveni supraînvățarea.
Costurile ajustării fine includ resursele computaționale (timp GPU/TPU), pregătirea și etichetarea datelor, infrastructura de stocare și implementare a modelului, precum și monitorizarea și mentenanța continuă. Totuși, aceste costuri sunt de obicei de 10-100 de ori mai mici decât antrenarea modelelor de la zero. Folosirea tehnicilor eficiente precum LoRA poate reduce costurile computaționale cu 80-90% în comparație cu ajustarea fină completă, făcând ajustarea fină o abordare economică pentru majoritatea organizațiilor.
Da, ajustarea fină îmbunătățește de obicei semnificativ acuratețea modelului pentru sarcini specifice. Prin antrenarea pe date dintr-un domeniu specific, modelele învață tipare și terminologie relevante pentru sarcină, pe care modelele generice le omit. Studiile arată că ajustarea fină poate îmbunătăți acuratețea cu 10-30% sau mai mult, în funcție de sarcină și calitatea setului de date. Îmbunătățirea este cea mai evidentă atunci când sarcina de ajustare fină diferă de cea de pre-antrenare, deoarece modelul își adaptează caracteristicile învățate la cerințele tale.
Ajustarea fină permite organizațiilor să păstreze datele sensibile pe propria infrastructură, în loc să le trimită către API-uri terțe. Poți ajusta fin modelele local pe date proprietare sau reglementate fără a le expune către servicii externe, asigurând conformitatea cu reglementări privind protecția datelor precum GDPR, HIPAA sau cerințe specifice industriei. Această abordare oferă atât beneficii de securitate, cât și de conformitate, menținând în același timp avantajele de performanță ale utilizării modelelor pre-antrenate.
Urmărește cum sistemele AI precum GPTs, Perplexity și Google AI Overviews citează și menționează brandul tău cu platforma de monitorizare AI AmICited.
Definiția ajustării fine: adaptarea modelelor AI pre-antrenate pentru sarcini specifice prin antrenament pe seturi de date de domeniu. Află cum ajustarea fină î...

Compară optimizarea datelor de instruire și strategiile de recuperare în timp real pentru AI. Află când să folosești fine-tuning vs RAG, implicațiile de cost și...

Descoperă adaptarea AI în timp real - tehnologia care permite sistemelor AI să învețe continuu din evenimente și date actuale. Explorează cum funcționează AI ad...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.