
PerplexityBot: Ce trebuie să știe fiecare proprietar de site web
Ghid complet despre crawler-ul PerplexityBot - înțelege cum funcționează, gestionează accesul, monitorizează citările și optimizează pentru vizibilitatea în Per...
9 min citire

Crawlerul web al Amazon folosit pentru îmbunătățirea produselor și serviciilor, inclusiv Alexa, asistentul de cumpărături Rufus și funcțiile de căutare bazate pe inteligență artificială ale Amazon. Respectă Protocolul de Excludere a Roboților și poate fi controlat prin directive robots.txt. Poate fi utilizat pentru antrenarea modelelor AI.
Crawlerul web al Amazon folosit pentru îmbunătățirea produselor și serviciilor, inclusiv Alexa, asistentul de cumpărături Rufus și funcțiile de căutare bazate pe inteligență artificială ale Amazon. Respectă Protocolul de Excludere a Roboților și poate fi controlat prin directive robots.txt. Poate fi utilizat pentru antrenarea modelelor AI.
Amazonbot este crawlerul web oficial al Amazon, conceput pentru a îmbunătăți produsele și serviciile companiei prin colectarea și analiza conținutului de pe web. Acest crawler sofisticat alimentează funcții esențiale Amazon, inclusiv asistentul vocal Alexa, asistentul de cumpărături AI Rufus și experiențele de căutare bazate pe inteligență artificială ale Amazon. Amazonbot operează folosind șirul user agent Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36, care îl identifică pe serverele web. Datele colectate de Amazonbot pot fi folosite pentru a antrena modelele de inteligență artificială ale Amazon, făcând din acesta o componentă crucială a infrastructurii AI mai largi a Amazon și a strategiei sale de dezvoltare a produselor.
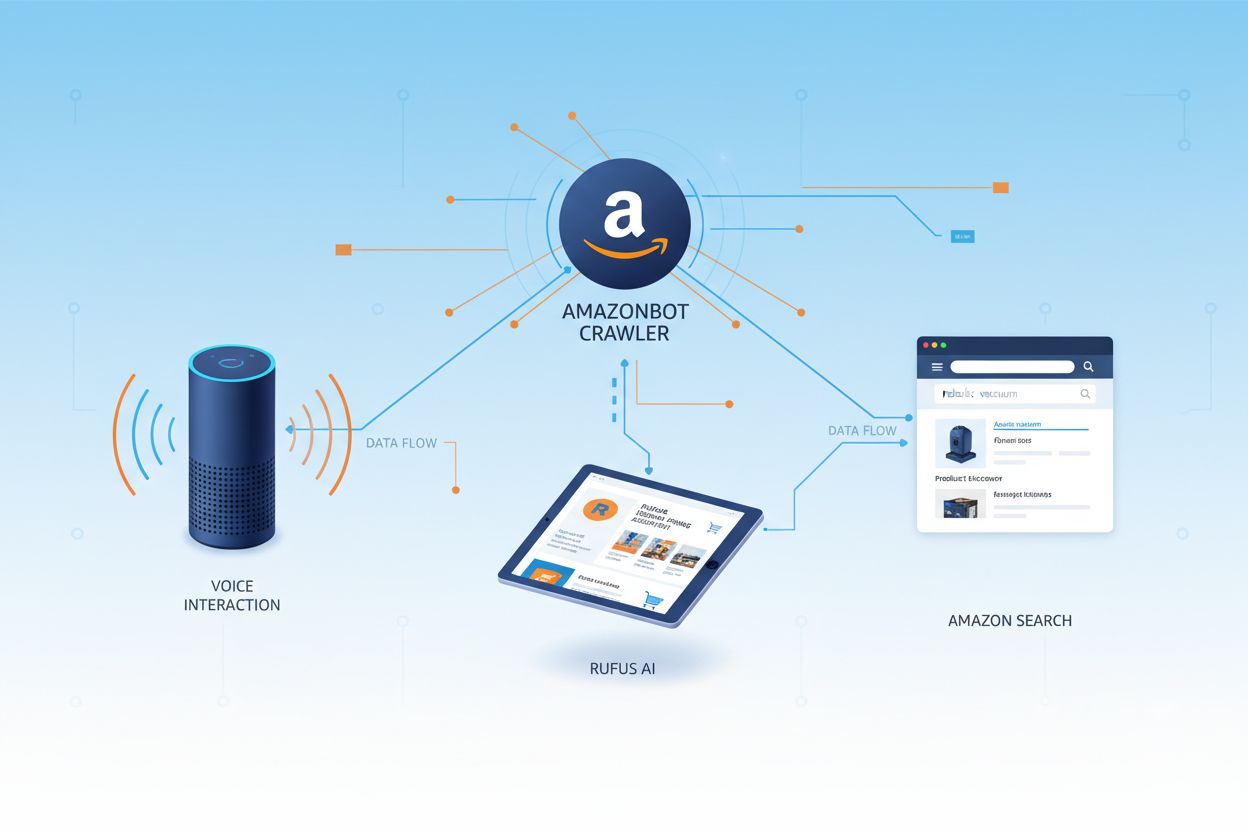
Amazon operează trei crawlere web distincte, fiecare având scopuri specifice în cadrul ecosistemului său. Amazonbot este crawlerul principal folosit pentru îmbunătățirea generală a produselor și serviciilor și poate fi utilizat pentru antrenarea modelelor AI. Amzn-SearchBot este conceput special pentru a îmbunătăți experiențele de căutare în produsele Amazon precum Alexa și Rufus, dar important, NU colectează conținut pentru antrenarea modelelor generative AI. Amzn-User sprijină acțiunile inițiate de utilizator, precum preluarea de informații în timp real atunci când clienții pun întrebări Alexa ce necesită date actualizate, și nici acesta nu colectează conținut pentru antrenarea AI. Toate cele trei crawlere respectă Protocolul de Excludere a Roboților și directivele robots.txt, permițând proprietarilor de site-uri să le controleze accesul. Amazon publică adresele IP pentru fiecare crawler pe portalul său pentru dezvoltatori, astfel încât proprietarii de site-uri pot verifica traficul legitim. În plus, toate crawlerele Amazon respectă directivele de tip rel=nofollow la nivel de link și meta tag-urile robots la nivel de pagină, inclusiv noarchive (împiedică folosirea pentru antrenarea modelelor), noindex (împiedică indexarea) și none (împiedică ambele).
| Nume Crawler | Scop Principal | Antrenare Model AI | User Agent | Cazuri de Utilizare Cheie |
|---|---|---|---|---|
| Amazonbot | Îmbunătățirea generală a produselor/serviciilor | Da | Amazonbot/0.1 | Îmbunătățirea serviciilor Amazon, antrenare AI |
| Amzn-SearchBot | Îmbunătățirea experienței de căutare | Nu | Amzn-SearchBot/0.1 | Căutare Alexa, indexare asistent Rufus |
| Amzn-User | Preluare date live inițiată de utilizator | Nu | Amzn-User/0.1 | Interogări Alexa în timp real, solicitări de informații actuale |
Amazon respectă Protocolul de Excludere a Roboților recunoscut în industrie (RFC 9309), ceea ce înseamnă că proprietarii de site-uri pot controla accesul Amazonbot prin fișierul robots.txt. Amazon preia fișierele robots.txt la nivel de host de la rădăcina domeniului tău (ex: example.com/robots.txt) și va folosi o copie cache din ultimele 30 de zile dacă fișierul nu poate fi preluat. Modificările aduse fișierului robots.txt sunt reflectate de obicei în aproximativ 24 de ore în sistemele Amazon. Protocolul suportă directivele standard user-agent și allow/disallow, permițând un control granular asupra accesului crawlerelor la anumite directoare sau fișiere. Totuși, este important de știut că crawlerele Amazon NU suportă directiva crawl-delay, astfel încât acest parametru va fi ignorat dacă este inclus în robots.txt.
Iată un exemplu despre cum poți controla accesul Amazonbot:
# Blochează Amazonbot să nu acceseze întregul site
User-agent: Amazonbot
Disallow: /
# Permite Amzn-SearchBot pentru vizibilitate în căutare
User-agent: Amzn-SearchBot
Allow: /
# Blochează un director specific pentru Amazonbot
User-agent: Amazonbot
Disallow: /private/
# Permite tuturor celorlalte crawlere
User-agent: *
Disallow: /admin/
Proprietarii de site-uri preocupați de traficul de la boți ar trebui să verifice dacă crawlerele care pretind că sunt Amazonbot sunt într-adevăr crawlere legitime ale Amazon. Amazon oferă un proces de verificare folosind căutări DNS pentru a confirma traficul autentic Amazonbot. Pentru a verifica legitimitatea unui crawler, identifică mai întâi adresa IP din jurnalele serverului tău, apoi efectuează o căutare DNS inversă asupra acelei adrese IP folosind comanda host. Numele de domeniu obținut ar trebui să fie un subdomeniu al crawl.amazonbot.amazon. Apoi, efectuează o căutare DNS directă pe domeniul obținut pentru a verifica că se rezolvă la aceeași adresă IP. Acest proces de verificare bidirecțională ajută la prevenirea atacurilor de tip spoofing, deoarece actori rău intenționați ar putea seta în mod fals înregistrări DNS inverse pentru a se da drept Amazonbot. Amazon publică adresele IP verificate pentru toate crawlerele sale pe portalul pentru dezvoltatori la developer.amazon.com/amazonbot/ip-addresses/, oferind un punct de referință suplimentar pentru verificare.
Exemplu de proces de verificare:
$ host 12.34.56.789
789.56.34.12.in-addr.arpa domain name pointer 12-34-56-789.crawl.amazonbot.amazon.
$ host 12-34-56-789.crawl.amazonbot.amazon
12-34-56-789.crawl.amazonbot.amazon has address 12.34.56.789
Dacă ai întrebări despre Amazonbot sau trebuie să raportezi activitate suspectă, contactează direct Amazon la amazonbot@amazon.com și include numele de domeniu relevant în mesajul tău.
Există o distincție esențială între crawlerele Amazon privind antrenarea modelelor AI. Amazonbot poate fi folosit pentru antrenarea modelelor de inteligență artificială ale Amazon, fiind relevant pentru creatorii de conținut preocupați de utilizarea operei lor în antrenarea AI. În schimb, Amzn-SearchBot și Amzn-User în mod explicit NU colectează conținut pentru antrenarea modelelor generative AI, concentrându-se doar pe îmbunătățirea experienței de căutare și suportul interogărilor utilizatorilor. Dacă vrei să previi folosirea conținutului tău pentru antrenarea AI, poți utiliza meta tag-ul robots noarchive în header-ul HTML al paginii, care îi indică lui Amazonbot să nu folosească pagina pentru scopuri de antrenare AI. Această distincție este importantă pentru editori, creatori și proprietari de site-uri care doresc să controleze modul în care conținutul lor este folosit în ecosistemul AI, permițând totodată apariția conținutului în rezultatele de căutare Amazon și recomandările Rufus.
Rufus este asistentul de cumpărături AI avansat al Amazon, care folosește crawling-ul web și tehnologia AI pentru a oferi recomandări și asistență de cumpărături personalizate. În timp ce Amazonbot contribuie la infrastructura AI generală a Amazon, Rufus folosește în mod specific Amzn-SearchBot pentru indexarea informațiilor despre produse și a conținutului web relevant pentru interogările de cumpărături. Rufus este construit pe Amazon Bedrock și utilizează modele lingvistice avansate, inclusiv Claude Sonnet de la Anthropic și Amazon Nova, combinate cu un model personalizat antrenat pe catalogul extins de produse Amazon, recenzii ale clienților, întrebări și răspunsuri din comunitate și informații web. Asistentul de cumpărături ajută clienții să cerceteze produse, să compare opțiuni, să urmărească prețuri, să găsească oferte și chiar să cumpere automat produse când ating prețurile țintă. De la lansare, Rufus a devenit extrem de popular, cu peste 250 de milioane de clienți care îl utilizează, utilizatorii activi lunar în creștere cu 149% și interacțiunile crescând cu 210% de la an la an. Clienții care folosesc Rufus în timpul cumpărăturilor au cu peste 60% mai multe șanse să facă o achiziție în acea sesiune, demonstrând impactul semnificativ al asistenței de cumpărături bazate pe AI asupra comportamentului consumatorilor.
Proprietarii de site-uri ar trebui să dezvolte o strategie pentru gestionarea crawlerelor Amazon în funcție de obiectivele de afaceri și politica de conținut:
noarchive sau blochează-l complet prin robots.txtamazonbot@amazon.com cu informațiile despre domeniul tău pentru îndrumări personalizate dacă ai întrebări sau preocupări specifice legate de interacțiunea crawlerelor Amazon cu site-ul tăuAmazonbot este crawlerul general al Amazon folosit pentru îmbunătățirea produselor și serviciilor și poate fi utilizat pentru antrenarea modelelor AI. Amzn-SearchBot este special conceput pentru experiențele de căutare din Alexa și Rufus și în mod explicit NU colectează conținut pentru antrenarea modelelor AI. Dacă vrei să previi utilizarea pentru antrenarea AI, blochează Amazonbot dar permite Amzn-SearchBot pentru vizibilitatea în căutare.
Adaugă următoarele linii în fișierul robots.txt aflat la rădăcina domeniului tău: User-agent: Amazonbot urmat de Disallow: /. Acest lucru va împiedica Amazonbot să acceseze întregul tău site. Poți folosi și Disallow: /cale-specifică/ pentru a bloca doar anumite directoare.
Da, Amazonbot poate fi folosit pentru a antrena modelele de inteligență artificială ale Amazon. Dacă dorești să previi acest lucru, folosește meta tag-ul robots în header-ul HTML al paginii, care îi indică lui Amazonbot să nu folosească pagina pentru antrenarea modelelor.
Efectuează o verificare DNS inversă pe adresa IP a crawlerului și verifică dacă domeniul este un subdomeniu al crawl.amazonbot.amazon. Apoi realizează o verificare DNS directă pentru a confirma că domeniul se rezolvă la aceeași adresă IP. Poți verifica și adresele IP publicate de Amazon la developer.amazon.com/amazonbot/ip-addresses/.
Folosește sintaxa standard robots.txt: User-agent: Amazonbot pentru a viza crawlerul, urmat de Disallow: / pentru a bloca tot accesul sau Disallow: /cale/ pentru a bloca anumite directoare. Poți folosi și Allow: / pentru a permite explicit accesul.
De obicei, Amazon reflectă modificările robots.txt în aproximativ 24 de ore. Amazon preia regulat fișierul robots.txt și păstrează o copie cache până la 30 de zile, deci modificările pot avea nevoie de o zi întreagă pentru a se propaga în sistemele lor.
Da, absolut. Poți crea reguli separate pentru fiecare crawler în fișierul tău robots.txt. De exemplu, permite Amzn-SearchBot cu User-agent: Amzn-SearchBot și Allow: /, în timp ce blochezi Amazonbot cu User-agent: Amazonbot și Disallow: /.
Contactează direct Amazon la amazonbot@amazon.com. Include întotdeauna numele domeniului tău și orice detalii relevante despre situația ta în mesaj. Echipa de suport Amazon îți poate oferi îndrumări personalizate pentru situația ta specifică.
Urmărește mențiunile brandului tău în sistemele AI precum Alexa, Rufus și Google AI Overviews cu AmICited - platforma lider de monitorizare a răspunsurilor AI.
Ghid complet despre crawler-ul PerplexityBot - înțelege cum funcționează, gestionează accesul, monitorizează citările și optimizează pentru vizibilitatea în Per...

Află despre PerplexityBot, crawlerul web al Perplexity care indexează conținutul pentru motorul său AI de răspunsuri. Înțelege cum funcționează, respectarea rob...

Află ce este GPTBot, cum funcționează și dacă ar trebui să permiți sau să blochezi crawler-ul web al OpenAI. Înțelege impactul asupra vizibilității brandului tă...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.