Cum să automatizezi monitorizarea căutărilor AI pentru brandul tău
Află cum să automatizezi monitorizarea mențiunilor brandului tău și a citărilor site-ului pe ChatGPT, Perplexity, Google AI Overviews și alte motoare de căutare...
9 min citire
Un mecanism de atenție este o componentă a rețelelor neuronale care cântărește dinamic importanța diferitelor elemente de intrare, permițând modelelor să se concentreze pe cele mai relevante părți ale datelor atunci când fac predicții. Calculează ponderi de atenție prin transformări învățate ale query-urilor, cheilor și valorilor, permițând modelelor de învățare profundă să surprindă dependențe pe distanțe lungi și relații contextuale în date secvențiale.
Un mecanism de atenție este o componentă a rețelelor neuronale care cântărește dinamic importanța diferitelor elemente de intrare, permițând modelelor să se concentreze pe cele mai relevante părți ale datelor atunci când fac predicții. Calculează ponderi de atenție prin transformări învățate ale query-urilor, cheilor și valorilor, permițând modelelor de învățare profundă să surprindă dependențe pe distanțe lungi și relații contextuale în date secvențiale.
Mecanismul de atenție este o tehnică de învățare automată care direcționează modelele de învățare profundă să prioritizeze (sau „să acorde atenție”) celor mai relevante părți ale datelor de intrare atunci când fac predicții. În loc să trateze toate elementele de intrare în mod egal, mecanismele de atenție calculează ponderi de atenție care reflectă importanța relativă a fiecărui element pentru sarcina de rezolvat, aplicând apoi aceste ponderi pentru a accentua sau diminua dinamic anumite intrări. Această inovație fundamentală a devenit piatra de temelie a arhitecturilor transformer moderne și a marilor modele de limbaj (LLMs) precum ChatGPT, Claude și Perplexity, permițându-le să proceseze date secvențiale cu o eficiență și acuratețe fără precedent. Mecanismul este inspirat de atenția cognitivă umană — capacitatea de a se concentra selectiv pe detalii relevante și de a filtra informațiile irelevante — și transpune acest principiu biologic într-o componentă de rețea neuronală matematic riguroasă și învățabilă.
Conceptul de mecanisme de atenție a fost introdus pentru prima dată de Bahdanau și colaboratorii săi în 2014 pentru a aborda limitări critice ale rețelelor neuronale recurente (RNN) utilizate pentru traducerea automată. Înainte de introducerea atenției, modelele Seq2Seq se bazau pe un singur vector de context pentru a codifica întreaga propoziție sursă, creând un blocaj informațional care limita sever performanța pe secvențe lungi. Mecanismul de atenție original a permis decodorului să acceseze toate stările ascunse ale encoderului, nu doar pe cea finală, selectând dinamic care părți ale intrării erau cele mai relevante la fiecare pas de decodare. Această descoperire a îmbunătățit dramatic calitatea traducerii, mai ales pentru propoziții lungi. În 2015, Luong și colaboratorii au introdus atenția cu produs scalar, care a înlocuit atenția aditivă costisitoare computațional cu înmulțiri matriciale eficiente. Momentul decisiv a venit în 2017 odată cu publicarea lucrării „Attention is All You Need”, care a introdus arhitectura transformer ce a renunțat complet la recurență în favoarea mecanismelor pure de atenție. Această lucrare a revoluționat învățarea profundă, făcând posibilă dezvoltarea BERT, modelelor GPT și a întregului ecosistem AI generativ modern. Astăzi, mecanismele de atenție sunt omniprezente în procesarea limbajului natural, viziune computerizată și sisteme AI multimodale, peste 85% dintre modelele de ultimă generație incluzând o formă de arhitectură bazată pe atenție.
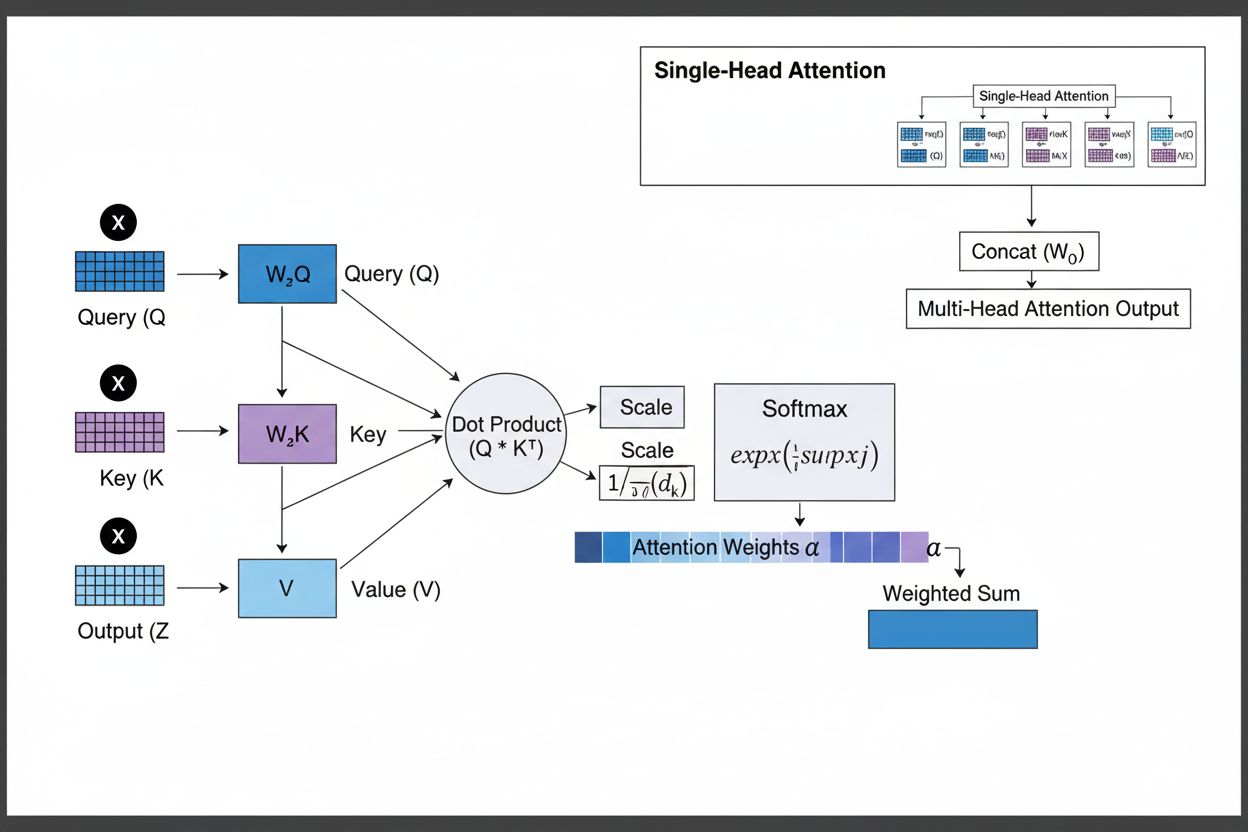
Mecanismul de atenție operează printr-o interacțiune sofisticată a trei componente matematice de bază: query-uri (Q), chei (K) și valori (V). Fiecare element de intrare este transformat în aceste trei reprezentări prin proiecții liniare învățate, creând o structură asemănătoare unei baze de date relaționale în care cheile servesc drept identificatori, iar valorile conțin informația reală. Mecanismul calculează scoruri de aliniere măsurând similaritatea dintre un query și toate cheile, de obicei folosind atenția cu produs scalar scalat, unde scorul este calculat ca QK^T/√d_k. Aceste scoruri brute sunt apoi normalizate folosind funcția softmax, care le convertește într-o distribuție de probabilitate cu suma ponderilor egală cu 1, asigurând că fiecare element primește o pondere între 0 și 1. Ultimul pas constă în calcularea unei sume ponderate a vectorilor de valoare folosind aceste ponderi de atenție, rezultând un vector de context care reprezintă cele mai relevante informații din întreaga secvență de intrare. Acest vector de context este apoi combinat cu intrarea originală prin conexiuni reziduale și trecut prin straturi feedforward, permițând modelului să își rafineze iterativ înțelegerea asupra datelor de intrare. Eleganța matematică a acestui design — combinând transformări învățabile, calcule de similaritate și ponderare probabilistică — permite mecanismelor de atenție să surprindă dependențe complexe, rămânând complet diferențiabile pentru optimizarea bazată pe gradient.
| Tip de atenție | Metodă de calcul | Complexitate computațională | Caz de utilizare optim | Principal avantaj |
|---|---|---|---|---|
| Atenție aditivă | Rețea feed-forward + activare tanh | O(n·d) per query | Secvențe scurte, dimensiuni variabile | Gestionează dimensiuni diferite query/cheie |
| Atenție cu produs scalar | Înmulțire matricială simplă | O(n·d) per query | Secvențe standard | Eficiență computațională |
| Produs scalar scalat | QK^T/√d_k + softmax | O(n·d) per query | Transformere moderne | Previne dispariția gradientului |
| Atenție multi-head | Mai multe head-uri de atenție paralele | O(h·n·d) unde h=head-uri | Relații complexe | Surprinde aspecte semantice diverse |
| Self-Attention | Query, chei, valori din aceeași secvență | O(n²·d) | Relații intra-secvență | Permite procesare paralelă |
| Cross-Attention | Query dintr-o secvență, chei/valori din alta | O(n·m·d) | Encoder-decoder, multimodal | Aliniază diferite modalități |
| Grouped Query Attention | Chei/valori partajate între head-urile query | O(n·d) | Inferență eficientă | Reduce memoria și calculul |
| Atenție rară | Atenție limitată la poziții locale/stratificate | O(n·√n·d) | Secvențe foarte lungi | Gestionează lungimi extreme de secvență |
Mecanismul de atenție funcționează printr-o succesiune riguroasă de transformări matematice care permit rețelelor neuronale să se concentreze dinamic pe informația relevantă. La procesarea unei secvențe de intrare, fiecare element este mai întâi încapsulat într-un spațiu vectorial de dimensiuni mari, captând informații semantice și sintactice. Aceste embeddinguri sunt apoi proiectate în trei spații separate prin matrici de greutăți învățate: spațiul query (reprezentând ce informație se caută), spațiul cheie (ce informație conține fiecare element) și spațiul valoare (informația efectivă ce va fi agregată). Pentru fiecare poziție query, mecanismul calculează un scor de similaritate cu fiecare cheie, făcând produsul scalar, rezultând un vector de scoruri brute de aliniere. Aceste scoruri sunt scalate prin împărțirea la rădăcina pătrată a dimensiunii cheii (√d_k), pas esențial pentru a preveni ca produsele scalare să devină prea mari la dimensiuni ridicate, ceea ce ar cauza dispariția gradientului la backpropagation. Scorurile scalate sunt apoi trecute printr-o funcție softmax, care exponențiază fiecare scor și le normalizează astfel încât să însumeze 1, creând o distribuție de probabilitate peste toate pozițiile de intrare. În final, aceste ponderi de atenție sunt folosite pentru a calcula o medie ponderată a vectorilor de valoare, pozițiile cu ponderi mai mari contribuind mai mult la vectorul final de context. Acest vector de context este apoi combinat cu intrarea originală prin conexiuni reziduale și procesat prin straturi feedforward, permițând modelului să își rafineze iterativ reprezentările. Întregul proces este diferențiabil, ceea ce permite modelului să învețe tipare optime de atenție prin gradient descent în timpul antrenării.
Mecanismele de atenție reprezintă blocul fundamental al arhitecturilor transformer, care au devenit paradigma dominantă în învățarea profundă. Spre deosebire de RNN-uri care procesează secvențele secvențial și CNN-uri care operează pe ferestre locale fixe, transformerele folosesc self-attention pentru ca fiecare poziție să poată acorda atenție tuturor celorlalte poziții simultan, facilitând paralelizarea masivă pe GPU-uri și TPU-uri. Arhitectura transformer constă în straturi alternative de self-attention multi-head și rețele feedforward, fiecare strat de atenție permițând modelului să își rafineze înțelegerea asupra intrării concentrându-se selectiv pe diverse aspecte. Atenția multi-head rulează mai multe mecanisme de atenție în paralel, fiecare head specializându-se pe tipuri diferite de relații — unul pe dependențe gramaticale, altul pe relații semantice, altul pe coreferințe de lungă distanță. Ieșirile tuturor head-urilor sunt concatenate și proiectate, permițând modelului să mențină simultan conștientizarea mai multor fenomene lingvistice. Această arhitectură s-a dovedit extrem de eficientă pentru marile modele de limbaj precum GPT-4, Claude 3 și Gemini, care folosesc arhitecturi transformer numai cu decodor, unde fiecare token poate acorda atenție doar token-urilor anterioare (mascare cauzală) pentru a menține proprietatea de generare autoregresivă. Capacitatea mecanismului de atenție de a surprinde dependențe pe distanțe lungi fără problemele de gradient care afectau RNN-urile a fost esențială pentru ca aceste modele să proceseze ferestre de context de peste 100.000 de token-uri, păstrând coerența și consistența pe texte vaste. Cercetările arată că aproximativ 92% din modelele NLP de ultimă generație se bazează acum pe arhitecturi transformer alimentate de mecanisme de atenție, demonstrând importanța lor fundamentală pentru sistemele AI moderne.
În contextul platformelor de căutare AI precum ChatGPT, Perplexity, Claude și Google AI Overviews, mecanismele de atenție joacă un rol crucial în determinarea celor mai relevante părți din documentele și bazele de cunoștințe regăsite pentru interogările utilizatorilor. Atunci când aceste sisteme generează răspunsuri, mecanismele lor de atenție cântăresc dinamic diferite surse și pasaje în funcție de relevanță, permițându-le să sintetizeze răspunsuri coerente din surse multiple și să mențină acuratețea factuală. Ponderile de atenție calculate în timpul generării pot fi analizate pentru a înțelege ce informații au fost prioritizate de model, oferind perspective asupra modului în care sistemele AI interpretează și răspund la întrebări. Pentru monitorizarea brandului și GEO (Generative Engine Optimization), înțelegerea mecanismelor de atenție este esențială deoarece acestea determină ce conținut și surse sunt puse în evidență în răspunsurile AI generate. Conținutul structurat astfel încât să se alinieze cu modul în care mecanismele de atenție cântăresc informația — prin definiții clare de entități, surse autoritare și relevanță contextuală — are șanse mai mari să fie citat și evidențiat în răspunsurile AI. AmICited valorifică perspectivele despre mecanismele de atenție pentru a urmări modul în care brandurile și domeniile apar pe platformele AI, recunoscând că citările ponderate de atenție reprezintă cele mai influente mențiuni în conținutul AI generat. Pe măsură ce tot mai multe companii monitorizează prezența lor în răspunsurile AI, faptul că mecanismele de atenție dictează tiparele de citare devine esențial pentru optimizarea strategiei de conținut și asigurarea vizibilității brandului în era AI generative.
Domeniul mecanismelor de atenție evoluează rapid, cercetătorii dezvoltând variante tot mai sofisticate pentru a depăși limitările computaționale și a îmbunătăți performanța. Tiparele de atenție rară limitează atenția la vecinătăți locale sau poziții stratificate, reducând complexitatea de la O(n²) la O(n·√n) păstrând performanța pe secvențe foarte lungi. Mecanisme eficiente de atenție precum FlashAttention optimizează tiparele de acces la memorie ale calculelor de atenție, obținând viteze de 2-4 ori mai mari prin utilizare GPU mai bună. Grouped query attention și multi-query attention reduc numărul de head-uri cheie-valoare menținând performanța, micșorând semnificativ cerințele de memorie la inferență — aspect critic pentru implementarea modelelor mari în producție. Arhitecturile Mixture of Experts combină atenția cu rutare rară, permițând scalarea modelelor la trilioane de parametri cu eficiență computațională. Cercetări emergente explorează tipare de atenție învățate care se adaptează dinamic în funcție de caracteristicile inputului și atenția ierarhică care operează la mai multe niveluri de abstractizare. Integrarea mecanismelor de atenție cu retrieval-augmented generation (RAG) permite modelelor să acorde atenție dinamică cunoștințelor externe, îmbunătățind factualitatea și reducând halucinațiile. Pe măsură ce sistemele AI sunt tot mai mult folosite în aplicații critice, mecanismele de atenție sunt îmbunătățite cu funcții de explicabilitate care oferă perspective mai clare asupra deciziilor modelului. Viitorul probabil va implica arhitecturi hibride care combină atenția cu mecanisme alternative precum modelele de tip state-space (exemplificate de Mamba), care oferă complexitate liniară menținând performanțe competitive. Înțelegerea acestor mecanisme de atenție în evoluție este esențială pentru practicienii care construiesc sisteme AI de nouă generație și pentru organizațiile care monitorizează prezența lor în conținutul AI generat, pe măsură ce mecanismele ce determină tiparele de citare și evidențiere a conținutului continuă să avanseze.
Pentru organizațiile care folosesc AmICited pentru a monitoriza vizibilitatea brandului în răspunsurile AI, înțelegerea mecanismelor de atenție oferă context esențial pentru interpretarea tiparelor de citare. Atunci când ChatGPT, Claude sau Perplexity citează domeniul tău în răspunsurile lor, ponderile de atenție calculate în timpul generării au determinat că informația ta a fost cea mai relevantă pentru interogarea utilizatorului. Conținutul de calitate, bine structurat, care definește clar entitățile și oferă informații autoritare primește în mod natural ponderi de atenție mai mari, fiind astfel selectat mai frecvent pentru citare. Funcțiile de vizualizare a atenției din unele platforme AI arată sursele care au primit cea mai mare atenție în timpul generării răspunsurilor, evidențiind practic ce citări au fost cele mai influente. Această perspectivă permite organizațiilor să își optimizeze strategia de conținut înțelegând că mecanismele de atenție recompensează claritatea, relevanța și sursele de autoritate. Pe măsură ce căutarea AI crește — peste 60% dintre companii investind acum în inițiative AI generative — abilitatea de a înțelege și optimiza pentru mecanismele de atenție devine tot mai valoroasă pentru menținerea vizibilității brandului și asigurarea reprezentării corecte în conținutul AI generat. Intersecția dintre mecanismele de atenție și monitorizarea brandului reprezintă o frontieră în GEO, unde înțelegerea fundamentelor matematice ale modului în care sistemele AI cântăresc și citează informația se traduce direct în vizibilitate și influență sporită în ecosistemul AI generativ.
RNN-urile tradiționale procesează secvențele în serie, ceea ce face dificilă surprinderea dependențelor pe distanțe lungi, în timp ce CNN-urile au câmpuri receptive locale fixe care le limitează capacitatea de a modela relații îndepărtate. Mecanismele de atenție depășesc aceste limitări prin calcularea relațiilor dintre toate pozițiile de intrare simultan, permițând procesare paralelă și surprinderea dependențelor indiferent de distanță. Această flexibilitate în timp și spațiu face ca mecanismele de atenție să fie semnificativ mai eficiente și mai performante pentru date secvențiale și spațiale complexe.
Query-urile reprezintă informația pe care modelul o caută în prezent, cheile reprezintă conținutul informațional pe care îl conține fiecare element de intrare, iar valorile dețin datele efective care trebuie agregate. Modelul calculează scoruri de similaritate între query-uri și chei pentru a determina ce valori trebuie ponderate cel mai mult. Această terminologie inspirată din baze de date, popularizată de articolul 'Attention is All You Need', oferă un cadru intuitiv pentru a înțelege cum mecanismele de atenție recuperează și combină selectiv informația relevantă din secvențele de intrare.
Self-attention calculează relații în cadrul unei singure secvențe de intrare, unde query-urile, cheile și valorile provin din aceeași sursă, permițând modelului să înțeleagă cum se raportează diferite elemente între ele. Cross-attention, în schimb, folosește query-uri dintr-o secvență și chei/valori dintr-o altă secvență, permițând modelului să alinieze și să combine informații din mai multe surse. Cross-attention este esențial în arhitecturi encoder-decoder precum traducerea automată și în modele multimodale precum Stable Diffusion, care combină informații text și imagine.
Atenția cu produs scalar scalat folosește înmulțirea în locul adunării pentru a calcula scorurile de aliniere, ceea ce o face mai eficientă computațional prin operații matriciale care valorifică paralelizarea GPU. Factorul de scalare 1/√dk previne ca produsele scalare să devină prea mari atunci când dimensiunea cheilor este mare, ceea ce ar cauza dispariția gradientului în timpul backpropagation. Deși atenția aditivă depășește uneori atenția cu produs scalar pentru dimensiuni foarte mari, eficiența computațională și performanța practică superioare fac ca atenția cu produs scalar scalat să fie alegerea standard în arhitecturile moderne de transformer.
Atenția multi-head rulează mai multe mecanisme de atenție în paralel, fiecare head învățând să se concentreze pe aspecte diferite ale intrării, cum ar fi relații gramaticale, semnificație semantică sau dependențe pe distanțe lungi. Fiecare head operează pe proiecții liniare diferite ale intrării, permițând modelului să surprindă simultan tipuri diverse de relații. Ieșirile tuturor head-urilor sunt concatenate și proiectate, permițând modelului să mențină conștientizarea mai multor caracteristici lingvistice și contextuale în același timp, îmbunătățind semnificativ calitatea reprezentărilor și performanța pe sarcini ulterioare.
Softmax normalizează scorurile brute de aliniere calculate între query-uri și chei într-o distribuție de probabilitate în care toate ponderile însumează 1. Această normalizare asigură că ponderile de atenție sunt interpretate ca scoruri de importanță, valorile mai mari indicând o relevanță mai mare. Funcția softmax este diferențiabilă, permițând învățarea bazată pe gradient a mecanismului de atenție în timpul antrenării, iar natura sa exponențială accentuează diferențele dintre scoruri, făcând concentrarea modelului mai selectivă și mai interpretabilă.
Mecanismele de atenție permit acestor modele să cântărească dinamic diferite părți ale promptului de intrare în funcție de relevanța pentru pasul curent de generare. La generarea unui răspuns, modelul folosește atenția pentru a determina ce token-uri și elemente de intrare anterioare ar trebui să influențeze cel mai mult predicția următorului token. Această ponderare dependentă de context permite modelelor să mențină coerența, să urmărească entități pe parcursul unor documente lungi, să rezolve ambiguități și să genereze răspunsuri care fac referire adecvată la anumite părți ale inputului, făcând ieșirile mai precise și adecvate contextului.
Începe să urmărești cum te menționează chatbot-urile AI pe ChatGPT, Perplexity și alte platforme. Obține informații utile pentru a-ți îmbunătăți prezența în AI.
Află cum să automatizezi monitorizarea mențiunilor brandului tău și a citărilor site-ului pe ChatGPT, Perplexity, Google AI Overviews și alte motoare de căutare...
Află ce este atribuirea vizibilității AI, cum diferă de SEO-ul tradițional și de ce este esențial să monitorizezi apariția brandului tău în răspunsurile generat...
Află despre penalizările din motoarele de căutare AI și generatoarele de răspunsuri. Descoperă cum ChatGPT, Perplexity și alte platforme AI evaluează calitatea ...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.