Tehnici pentru a asigura că roboții AI accesează și indexează eficient cel mai important conținut al unui site web în limitele lor de crawl. Optimizarea bugetului de crawl gestionează echilibrul dintre capacitatea de crawl (resursele serverului) și cererea de crawl (cererile botului) pentru a maximiza vizibilitatea în răspunsurile generate de AI, controlând în același timp costurile operaționale și încărcarea serverului.
Optimizarea bugetului de crawl pentru AI
Tehnici pentru a asigura că roboții AI accesează și indexează eficient cel mai important conținut al unui site web în limitele lor de crawl. Optimizarea bugetului de crawl gestionează echilibrul dintre capacitatea de crawl (resursele serverului) și cererea de crawl (cererile botului) pentru a maximiza vizibilitatea în răspunsurile generate de AI, controlând în același timp costurile operaționale și încărcarea serverului.
Ce este bugetul de crawl în era AI
Bugetul de crawl se referă la cantitatea de resurse—măsurată în cereri și lățime de bandă—pe care motoarele de căutare și roboții AI le alocă pentru a accesa site-ul tău web. În mod tradițional, acest concept se aplica în principal comportamentului de crawling al Google, dar apariția roboților alimentați de AI a transformat fundamental modul în care organizațiile trebuie să abordeze gestionarea bugetului de crawl. Ecuația bugetului de crawl constă în două variabile critice: capacitatea de crawl (numărul maxim de pagini pe care un bot le poate accesa) și cererea de crawl (numărul efectiv de pagini pe care botul dorește să le acceseze). În era AI, această dinamică a devenit exponențial mai complexă, deoarece roboți precum GPTBot (OpenAI), Perplexity Bot și ClaudeBot (Anthropic) concurează acum pentru resursele serverului alături de crawlerii tradiționali ai motoarelor de căutare. Acești roboți AI operează cu priorități și modele diferite față de Googlebot, consumând adesea semnificativ mai multă lățime de bandă și urmărind obiective de indexare diferite, făcând ca optimizarea bugetului de crawl să nu mai fie opțională, ci esențială pentru menținerea performanței site-ului și controlul costurilor operaționale.
De ce roboții AI au schimbat regulile jocului
Roboții AI diferă fundamental de roboții tradiționali ai motoarelor de căutare prin modelele de crawling, frecvență și consum de resurse. În timp ce Googlebot respectă limitele bugetului de crawl și implementează mecanisme sofisticate de throttling, roboții AI manifestă adesea comportamente de crawling mai agresive, solicitând uneori același conținut de mai multe ori și acordând mai puțină atenție semnalelor de încărcare ale serverului. Cercetările indică faptul că GPTBot de la OpenAI poate consuma de 12-15 ori mai multă lățime de bandă decât crawlerul Google pe anumite site-uri, în special cele cu biblioteci mari de conținut sau pagini actualizate frecvent. Această abordare agresivă rezultă din cerințele de antrenare AI—acești roboți trebuie să ingereze continuu conținut nou pentru a îmbunătăți performanța modelelor, creând o filozofie de crawling fundamental diferită de cea a motoarelor de căutare axată pe indexarea pentru regăsire. Impactul asupra serverului este substanțial: organizațiile raportează creșteri semnificative ale costurilor cu lățimea de bandă, utilizarea CPU și încărcarea serverului direct atribuite traficului bot AI. De asemenea, efectul cumulativ al mai multor roboți AI care accesează simultan poate degrada experiența utilizatorului, încetini timpii de încărcare a paginilor și crește cheltuielile de găzduire, făcând distincția dintre crawlerii tradiționali și cei AI o chestiune de afaceri critică, nu doar una tehnică.
Caracteristică
Crawleri tradiționali (Googlebot)
Crawleri AI (GPTBot, ClaudeBot)
Frecvența crawl-ului
Adaptivă, respectă bugetul
Agresivă, continuă
Consum de lățime de bandă
Moderat, optimizat
Ridicat, intensiv în resurse
Respectarea robots.txt
Conformitate strictă
Conformitate variabilă
Comportament de caching
Caching sofisticat
Cereri frecvente repetate
Identificare user-agent
Clară, consistentă
Uneori obfuscată
Obiectiv de business
Indexare pentru căutare
Antrenare modele/achiziție date
Impactul costului
Minim
Semnificativ (de 12-15x mai mare)
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Cele două componente de bază ale bugetului de crawl
Înțelegerea bugetului de crawl necesită stăpânirea celor două componente fundamentale: capacitatea de crawl și cererea de crawl. Capacitatea de crawl reprezintă numărul maxim de URL-uri pe care serverul tău le poate gestiona într-un interval de timp dat, determinat de factori interconectați. Această capacitate este influențată de:
Resursele serverului (CPU, RAM, disponibilitatea lățimii de bandă)
Timpul de răspuns (răspunsuri mai rapide permit rate de crawl mai mari)
Semnalele de sănătate ale serverului (coduri de stare HTTP, rate de timeout)
Calitatea infrastructurii (utilizarea CDN, load balancing, straturi de caching)
Cererea de crawl, pe de altă parte, reprezintă câte pagini doresc efectiv roboții să acceseze, fiind determinată de caracteristicile conținutului și prioritățile botului. Factorii care influențează cererea de crawl includ:
Prospețimea conținutului (paginile actualizate frecvent atrag mai multe crawl-uri)
Calitatea și autoritatea conținutului (paginile de calitate primesc prioritate mai mare)
Frecvența actualizărilor (paginile actualizate zilnic atrag mai multă atenție decât cele statice)
Structura linkingului intern (paginile bine legate sunt accesate mai des)
Includerea în sitemap (paginile din sitemap primesc prioritate sporită)
Modele istorice de crawl (roboții învață ce pagini se schimbă frecvent)
Provocarea optimizării apare atunci când cererea de crawl depășește capacitatea de crawl—roboții trebuie să aleagă ce pagini să acceseze, putând rata actualizări importante. Pe de altă parte, când capacitatea de crawl depășește mult cererea, se irosesc resursele serverului. Scopul este obținerea eficienței crawl-ului: maximizarea accesării paginilor importante și reducerea crawl-ului inutil pe conținut cu valoare scăzută. Acest echilibru devine tot mai complex în era AI, unde mai multe tipuri de roboți cu priorități diferite concurează pentru aceleași resurse, necesitând strategii sofisticate pentru alocarea eficientă a bugetului de crawl pentru toți stakeholderii.
Măsurarea performanței actuale a bugetului de crawl
Măsurarea performanței bugetului de crawl începe cu Google Search Console, care oferă statistici de crawl în secțiunea „Setări”, afișând cererile zilnice de crawl, octeții descărcați și timpii de răspuns. Pentru a calcula rata de eficiență a crawl-ului, împarte numărul de crawl-uri reușite (răspunsuri HTTP 200) la numărul total de cereri de crawl, site-urile sănătoase obținând de obicei o eficiență de 85-95%. O formulă de bază pentru eficiența crawl-ului este: (Crawl-uri reușite ÷ Total cereri de crawl) × 100 = % Eficiență Crawl. Dincolo de datele Google, monitorizarea practică necesită:
Analiza logurilor serverului cu instrumente precum Splunk sau ELK Stack pentru identificarea traficului tuturor boturilor, inclusiv a celor AI
Monitorizarea ratelor de erori 4xx și 5xx pentru a identifica paginile care irosesc bugetul de crawl pe erori
Măsurarea tendințelor timpului de răspuns pentru identificarea degradării performanței din cauza încărcării de crawl
Segmentarea traficului după user-agent pentru a înțelege ce roboți consumă cele mai multe resurse
Pentru monitorizarea specifică roboților AI, instrumente precum AmICited.com oferă urmărire specializată a activității GPTBot, ClaudeBot și Perplexity Bot, furnizând informații despre ce pagini prioritizează acești roboți și cât de des revin. De asemenea, implementarea alertelor personalizate pentru creșteri neobișnuite de crawl—mai ales de la roboți AI—permite reacții rapide la consumul neașteptat de resurse. Metricul cheie de urmărit este costul de crawl per pagină: împărțirea totalului resurselor serverului consumate prin crawl la numărul de pagini unice accesate arată dacă folosești eficient bugetul de crawl sau irosești resurse pe pagini cu valoare scăzută.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Strategii de optimizare pentru roboții AI
Optimizarea bugetului de crawl pentru roboții AI necesită o abordare multistratificată care combină implementarea tehnică cu decizii strategice. Principalele tactici de optimizare includ:
Rafinarea robots.txt: Blochează roboții AI să acceseze paginile cu valoare scăzută (arhive, conținut duplicat, secțiuni de administrare), permițând accesul la conținutul de bază
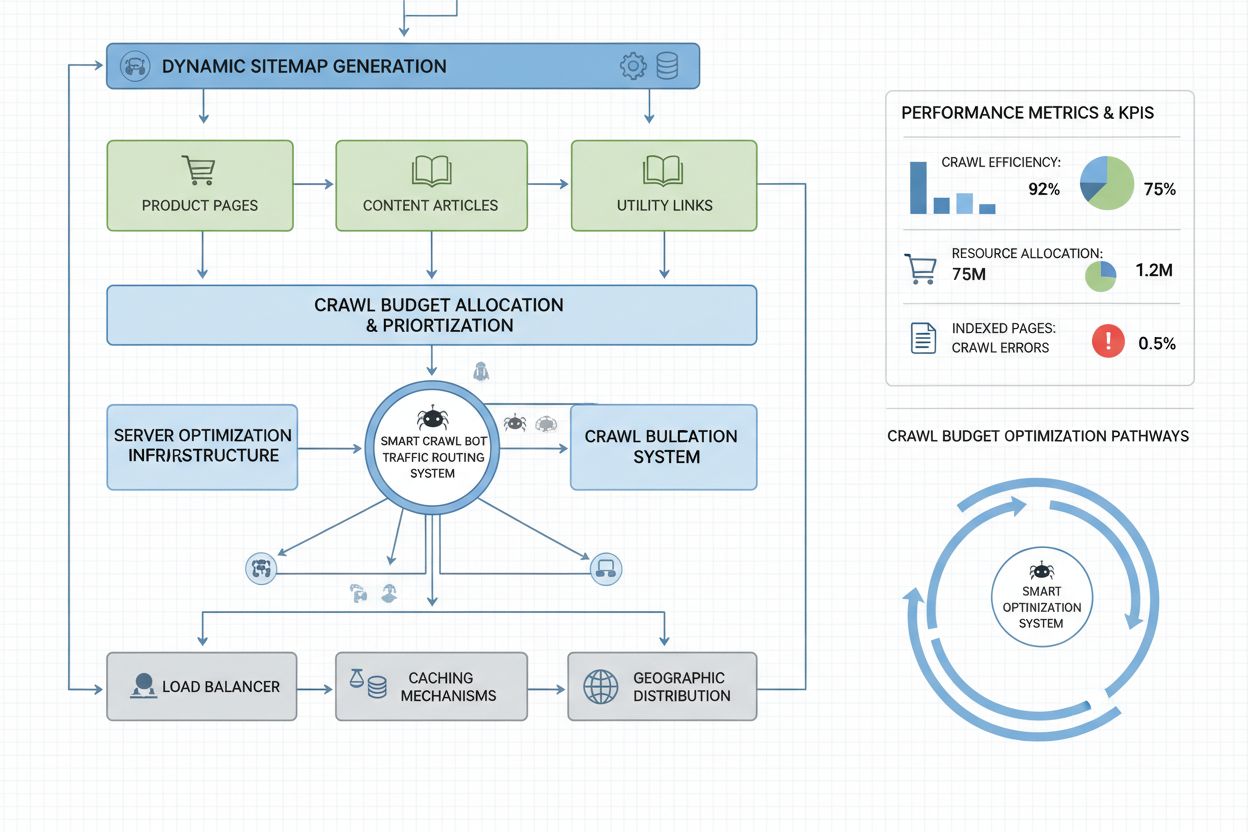
Sitemap-uri dinamice: Creează sitemap-uri separate pentru diferite tipuri de conținut, prioritizând conținutul actualizat frecvent și paginile cu valoare ridicată
Optimizarea structurii URL: Implementează structuri de URL curate, ierarhice, care reduc adâncimea crawl-ului și fac paginile importante mai ușor de găsit
Blocare selectivă: Folosește reguli specifice user-agentului pentru a permite Googlebot, restricționând în același timp roboții AI agresivi dacă aceștia consumă resurse excesive
Directive crawl-delay: Implementează valori adecvate crawl-delay în robots.txt pentru a limita cererile botului (deși roboții AI pot să nu le respecte)
Canonicalizare: Folosește taguri canonice agresiv pentru a consolida conținutul duplicat și a reduce irosirea bugetului de crawl pe variații
Decizia strategică privind ce tactică să folosești depinde de modelul tău de afaceri și de strategia de conținut. Site-urile e-commerce pot bloca roboții AI pe paginile de produse pentru a preveni antrenarea concurenților pe datele lor, în timp ce editorii de conținut pot permite crawlingul pentru a obține vizibilitate în răspunsurile generate de AI. Pentru site-urile care se confruntă cu încărcare reală a serverului de la traficul bot AI, implementarea blocării specifice user-agentului în robots.txt este cea mai directă soluție: User-agent: GPTBot urmat de Disallow: / previne complet accesul crawlerului OpenAI la site. Totuși, această abordare sacrifică potențiala vizibilitate în răspunsurile ChatGPT și alte aplicații AI. O strategie mai nuanțată implică blocarea selectivă: permite accesul roboților AI la conținutul public, blocându-i din zone sensibile, arhive sau conținut duplicat care irosește bugetul de crawl fără valoare adăugată pentru bot sau utilizatori.
Tehnici avansate pentru site-uri mari
Site-urile la scară enterprise, cu milioane de pagini, necesită strategii sofisticate de optimizare a bugetului de crawl, dincolo de configurarea de bază a robots.txt. Sitemap-urile dinamice reprezintă un progres esențial, fiind generate în timp real pe baza prospețimii conținutului, scorurilor de importanță și istoricului de crawl. În locul sitemap-urilor XML statice care listează toate paginile, sitemap-urile dinamice prioritizează paginile recent actualizate, cele cu trafic ridicat și cele cu potențial de conversie, asigurând că roboții își cheltuiesc bugetul de crawl pe conținutul care contează cel mai mult. Segmentarea URL-urilor împarte site-ul în zone logice de crawl, fiecare cu strategii de optimizare dedicate—secțiunile de știri pot folosi actualizări agresive de sitemap pentru ca conținutul zilnic să fie accesat imediat, în timp ce conținutul evergreen folosește actualizări mai rare.
Optimizarea la nivel de server include implementarea strategiilor de caching conștiente de crawl, care servesc răspunsuri din cache roboților și conținut proaspăt utilizatorilor, reducând încărcarea serverului de la cererile repetate ale boturilor. Rețelele de livrare a conținutului (CDN) cu rutare specifică boturilor pot izola traficul bot de cel al utilizatorilor, prevenind consumul lățimii de bandă necesare vizitatorilor reali. Limitarea ratei pe user-agent permite serverelor să încetinească cererile roboților AI, menținând în același timp viteze normale pentru Googlebot și trafic uman. Pentru operațiuni de dimensiuni foarte mari, gestionarea distribuită a bugetului de crawl pe mai multe regiuni server asigură absența unui punct unic de eșec și permite echilibrarea geografică a traficului bot. Predicția de crawl bazată pe machine learning analizează modelele istorice de crawl pentru a anticipa ce pagini vor fi accesate de roboți, permițând optimizarea proactivă a performanței și caching-ului acestor pagini. Aceste strategii la nivel enterprise transformă bugetul de crawl dintr-o constrângere într-o resursă gestionată, permițând organizațiilor mari să servească miliarde de pagini menținând performanță optimă atât pentru roboți, cât și pentru utilizatorii umani.
Decizia strategică – Blochezi sau permiți roboții AI?
Decizia de a bloca sau permite roboții AI reprezintă o alegere strategică fundamentală cu implicații semnificative pentru vizibilitate, poziționare competitivă și costuri operaționale. Permiterea roboților AI aduce beneficii substanțiale: conținutul tău devine eligibil pentru includere în răspunsurile generate de AI, putând genera trafic din ChatGPT, Claude, Perplexity și alte aplicații AI; brandul tău câștigă vizibilitate într-un canal de distribuție nou; și beneficiezi de semnalele SEO obținute prin citarea de către sistemele AI. Totuși, aceste beneficii vin cu costuri: creșterea încărcării serverului și a consumului de lățime de bandă, posibilitatea ca modele AI concurente să se antreneze pe conținutul tău propriu și pierderea controlului asupra modului în care informațiile tale sunt prezentate și atribuite în răspunsurile AI.
Blocarea roboților AI elimină aceste costuri, dar sacrifică beneficiile de vizibilitate și poate ceda cota de piață competitorilor care permit crawlingul. Strategia optimă depinde de modelul tău de afaceri: editorii de conținut și organizațiile de știri beneficiază adesea de pe urma permisiunii de crawl pentru distribuție prin rezumate AI; companiile SaaS și site-urile e-commerce pot bloca roboții pentru a preveni antrenarea concurenților pe informațiile despre produse; instituțiile educaționale și organizațiile de cercetare permit de obicei crawlingul pentru maximizarea diseminării cunoștințelor. O abordare hibridă oferă o cale de mijloc: permite accesul la conținutul public și blochează zonele sensibile, conținutul generat de utilizatori sau informațiile proprietare. Această strategie maximizează beneficiile de vizibilitate, protejând totodată activele valoroase. De asemenea, monitorizarea cu AmICited.com și instrumente similare arată dacă într-adevăr conținutul tău este citat de sistemele AI—dacă site-ul nu apare în răspunsuri AI deși permiți crawlingul, blocarea devine o opțiune mai atractivă, deoarece suporți costul fără a primi beneficii de vizibilitate.
Instrumente și monitorizare pentru gestionarea bugetului de crawl
Gestionarea eficientă a bugetului de crawl necesită instrumente specializate care oferă vizibilitate asupra comportamentului roboților și permit decizii de optimizare bazate pe date. Conductor și Sitebulb oferă analiză de crawl la nivel enterprise, simulând modul în care motoarele de căutare accesează site-ul tău și identificând ineficiențe de crawl, crawl-uri irosite pe pagini cu erori și oportunități de îmbunătățire a alocării bugetului de crawl. Cloudflare oferă managementul boturilor la nivel de rețea, permițând control granular asupra accesului boturilor și limitarea ratei specifice crawlerilor AI. Pentru monitorizarea specifică roboților AI, AmICited.com se remarcă drept cea mai cuprinzătoare soluție, urmărind GPTBot, ClaudeBot, Perplexity Bot și alți roboți AI cu analize detaliate care arată ce pagini accesează acești roboți, cât de des revin și dacă apari cu conținutul tău în răspunsuri generate de AI.
Analiza logurilor serverului rămâne fundamentală pentru optimizarea bugetului de crawl—instrumente precum Splunk, Datadog sau ELK Stack open-source permit parsarea logurilor brute de acces și segmentarea traficului pe user-agent, identificând ce roboți consumă cele mai multe resurse și ce pagini atrag cel mai mult interes. Dashboard-urile personalizate care urmăresc tendințele crawl-ului în timp arată dacă eforturile de optimizare funcționează și dacă apar noi tipuri de roboți agresivi. Google Search Console continuă să ofere date esențiale despre comportamentul de crawl al Google, iar Bing Webmaster Tools oferă informații similare pentru crawlerul Microsoft. Cele mai avansate organizații implementează strategii de monitorizare multi-tool, combinând Google Search Console pentru date tradiționale de crawl, AmICited.com pentru urmărirea roboților AI, analiza logurilor serverului pentru vizibilitate completă și instrumente specializate precum Conductor pentru simulare și analiză de eficiență. Această abordare stratificată oferă vizibilitate completă asupra modului în care toate tipurile de roboți interacționează cu site-ul, permițând decizii de optimizare bazate pe date complete, nu pe presupuneri. Monitorizarea regulată—ideal săptămânală a metricilor de crawl—permite identificarea rapidă a problemelor precum creșteri neașteptate de crawl, rate crescute de erori sau apariția unor roboți agresivi noi, asigurând reacții rapide înainte ca problemele de buget de crawl să afecteze performanța site-ului sau costurile operaționale.
Întrebări frecvente
Care este diferența dintre bugetul de crawl pentru roboții AI și Googlebot?
Roboții AI precum GPTBot și ClaudeBot operează cu priorități diferite față de Googlebot. În timp ce Googlebot respectă limitele bugetului de crawl și implementează mecanisme sofisticate de limitare, roboții AI prezintă adesea modele de crawl mai agresive, consumând de 12-15 ori mai multă lățime de bandă. Roboții AI prioritizează ingestia continuă de conținut pentru antrenarea modelelor, nu indexarea pentru căutare, ceea ce face ca comportamentul lor de crawl să fie fundamental diferit și să necesite strategii distincte de optimizare.
Cât consumă de obicei roboții AI din bugetul de crawl?
Cercetările arată că GPTBot de la OpenAI poate consuma de 12-15 ori mai multă lățime de bandă decât crawlerul Google pe anumite site-uri, în special cele cu biblioteci mari de conținut. Consumul exact depinde de dimensiunea site-ului, frecvența actualizării conținutului și câți roboți AI accesează simultan. Mai mulți roboți AI care accesează în același timp pot crește semnificativ încărcarea serverului și costurile de găzduire.
Pot bloca anumiți roboți AI fără să afectez SEO?
Da, poți bloca roboți AI specifici folosind robots.txt fără a afecta SEO-ul tradițional. Totuși, blocarea roboților AI înseamnă să renunți la vizibilitatea în răspunsurile generate de AI din ChatGPT, Claude, Perplexity și alte aplicații AI. Decizia depinde de modelul tău de afaceri—editorii de conținut beneficiază de obicei de pe urma permisiunii de crawl, în timp ce site-urile e-commerce pot bloca pentru a preveni antrenarea concurenților.
Care este impactul unei gestionări deficitare a bugetului de crawl asupra site-ului meu?
Gestionarea slabă a bugetului de crawl poate duce la necrawlingul sau neindexarea unor pagini importante, indexarea lentă a conținutului nou, creșterea încărcării serverului și a costurilor de lățime de bandă, degradarea experienței utilizatorului din cauza traficului bot care consumă resurse și pierderea oportunităților de vizibilitate atât în căutarea tradițională, cât și în răspunsurile generate de AI. Site-urile mari, cu milioane de pagini, sunt cele mai vulnerabile la aceste efecte.
Cât de des ar trebui să-mi monitorizez bugetul de crawl?
Pentru rezultate optime, monitorizează metricile bugetului de crawl săptămânal, cu verificări zilnice în timpul lansărilor majore de conținut sau la apariția unor creșteri neașteptate de trafic. Folosește Google Search Console pentru date tradiționale de crawl, AmICited.com pentru urmărirea roboților AI și logurile serverului pentru vizibilitate completă asupra boturilor. Monitorizarea regulată permite identificarea rapidă a problemelor înainte ca acestea să afecteze performanța site-ului.
Este robots.txt eficient pentru controlul crawlingului roboților AI?
Robots.txt are eficiență variabilă cu roboții AI. În timp ce Googlebot respectă strict directivele robots.txt, roboții AI au o conformare inconsistentă—unii respectă regulile, alții le ignoră. Pentru un control mai fiabil, implementează blocare specifică user-agentului, limitează rata la nivelul serverului sau folosește instrumente de management bot bazate pe CDN precum Cloudflare pentru un control mai granular.
Care este relația dintre bugetul de crawl și vizibilitatea în AI?
Bugetul de crawl afectează direct vizibilitatea în AI, deoarece roboții AI nu pot cita sau face referire la conținutul pe care nu l-au accesat. Dacă paginile tale importante nu sunt accesate din cauza limitelor bugetului, nu vor apărea în răspunsurile generate de AI. Optimizarea bugetului de crawl asigură ca cel mai valoros conținut să fie descoperit de roboții AI, crescând șansele de a fi citat în răspunsurile ChatGPT, Claude și Perplexity.
Cum prioritizez ce pagini ar trebui să fie accesate de roboții AI?
Prioritizează paginile folosind sitemap-uri dinamice care evidențiază conținutul actualizat recent, paginile cu trafic ridicat și cele cu potențial de conversie. Folosește robots.txt pentru a bloca paginile cu valoare scăzută, precum arhivele sau duplicatele. Implementează structuri de URL curate și linking intern strategic pentru a ghida roboții către conținutul important. Monitorizează ce pagini accesează efectiv roboții AI folosind instrumente precum AmICited.com pentru a-ți rafina strategia.
Monitorizează-ți eficient bugetul de crawl AI
Urmărește modul în care roboții AI accesează site-ul tău și optimizează-ți vizibilitatea în răspunsurile generate de AI cu platforma completă de monitorizare a roboților AI de la AmICited.com.
Ce este Bugetul de Crawl pentru AI? Înțelegerea Alocării Resurselor pentru Boții AI
Află ce înseamnă bugetul de crawl pentru AI, cum diferă față de bugetele tradiționale de crawl pentru motoarele de căutare și de ce contează pentru vizibilitate...
Bugetul de crawl reprezintă numărul de pagini pe care motoarele de căutare le explorează pe site-ul tău într-un interval de timp. Află cum să optimizezi bugetul...
Distrug boții AI bugetul tău de crawl? Cum să gestionezi GPTBot și prietenii săi
Discuție în comunitate despre gestionarea bugetului de crawl pentru AI. Cum să administrezi GPTBot, ClaudeBot și PerplexityBot fără să sacrifici vizibilitatea....
7 min citire
Discussion
Crawl Budget
+2
Consimțământ Cookie Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.