Definiția graficului de cunoștințe
Un grafic de cunoștințe este o bază de date de informații interconectate care reprezintă entități din lumea reală — precum persoane, locuri, organizații și concepte — și ilustrează relațiile semantice dintre acestea. Spre deosebire de bazele de date tradiționale care organizează informația în formate tabulare rigide, graficele de cunoștințe structurează datele ca rețele de noduri (entități) și muchii (relații), permițând sistemelor să înțeleagă sensul și contextul, nu doar să potrivească cuvinte cheie. Graficul de cunoștințe al Google, lansat în 2012, a revoluționat căutarea prin introducerea înțelegerii bazate pe entități, permițând motorului de căutare să răspundă la întrebări factuale precum „Cât de înalt este Turnul Eiffel?” sau „Unde au avut loc Jocurile Olimpice de vară 2016?” prin înțelegerea a ceea ce caută de fapt utilizatorul, nu doar cuvintele folosite. În mai 2024, Graficul de cunoștințe al Google conține peste 1,6 trilioane de fapte despre 54 de miliarde de entități, reprezentând o expansiune masivă față de 500 de miliarde de fapte despre 5 miliarde de entități în 2020. Această creștere reflectă importanța tot mai mare a cunoștințelor structurate și semantice în alimentarea căutărilor moderne, a sistemelor AI și a aplicațiilor inteligente din diverse industrii.
Context și dezvoltare istorică
Conceptul de grafic de cunoștințe a apărut din decenii de cercetare în inteligența artificială, tehnologii web semantice și reprezentarea cunoștințelor. Totuși, termenul a devenit larg recunoscut atunci când Google a introdus Graficul său de cunoștințe în 2012, schimbând fundamental modul în care motoarele de căutare livrează rezultate. Înainte de Graficul de cunoștințe, motoarele de căutare foloseau în principal potrivirea de cuvinte cheie — dacă căutai „focă”, Google returna rezultate pentru toate sensurile posibile ale cuvântului fără a înțelege despre ce entitate vrei de fapt să afli. Graficul de cunoștințe a schimbat acest paradigm aplicând principii de ontologie — un cadru formal pentru definirea entităților, atributelor și relațiilor lor — la scară largă. Această trecere de la „șiruri la lucruri” a reprezentat un avans fundamental în tehnologia de căutare, permițând algoritmilor să înțeleagă că „focă” poate însemna un mamifer marin, un artist muzical, o unitate militară sau un dispozitiv de siguranță, și să determine care sens este cel mai relevant în funcție de context. Piața globală a graficelor de cunoștințe reflectă această importanță, cu proiecții de creștere de la 1,49 miliarde dolari în 2024 la 6,94 miliarde dolari până în 2030, reprezentând o rată anuală compusă de creștere de aproximativ 35%. Această creștere explozivă este alimentată de adoptarea în companii din domenii precum finanțe, sănătate, retail și managementul lanțului de aprovizionare, unde organizațiile recunosc tot mai mult că înțelegerea relațiilor dintre entități este esențială pentru luarea deciziilor, detectarea fraudei și eficiența operațională.
Cum funcționează graficele de cunoștințe: Arhitectură tehnică
Graficele de cunoștințe funcționează printr-o combinație sofisticată de structuri de date, tehnologii semantice și algoritmi de învățare automată. La bază, graficele de cunoștințe folosesc un model de date structurat ca graf format din trei componente fundamentale: noduri (reprezentând entități precum persoane, organizații sau concepte), muchii (reprezentând relații între entități) și etichete (care descriu natura acelor relații). De exemplu, într-un grafic simplu, „Seal” poate fi un nod, „este-un” poate fi o etichetă de muchie, iar „Artist muzical” alt nod, creând relația semantică „Seal este-un Artist muzical”. Această structură este fundamental diferită de bazele de date relaționale, care forțează datele în rânduri și coloane cu scheme predefinite. Graficele de cunoștințe sunt construite fie folosind grafuri cu proprietăți etichetate (care stochează proprietăți direct pe noduri și muchii), fie magazine RDF (Resource Description Framework) triple stores (care reprezintă toate informațiile ca triple subiect-predicat-obiect). Puterea graficelor de cunoștințe provine din abilitatea lor de a integra date din surse multiple cu structuri și formate diferite. Când datele sunt preluate într-un grafic de cunoștințe, procesele de îmbogățire semantică folosesc NLP și machine learning pentru a identifica entități, a extrage relații și a înțelege contextul. Astfel, graficul de cunoștințe recunoaște automat că „IBM”, „International Business Machines” și „Big Blue” se referă la aceeași entitate și înțelege cum se leagă aceasta de alte entități precum „Watson”, „Cloud Computing” sau „Inteligență Artificială”. Structura rezultată permite interogări și raționamente sofisticate imposibile în bazele de date tradiționale, permițând sistemelor să răspundă la întrebări complexe traversând relații și inferând cunoștințe noi din conexiunile existente.
Grafic de cunoștințe vs. baze de date tradiționale: Tabel comparativ
| Aspect | Grafic de cunoștințe | Bază de date relațională tradițională | Bază de date graf |
|---|
| Structură de date | Noduri, muchii și etichete ce reprezintă entități și relații | Tabele, rânduri și coloane cu scheme predefinite | Noduri și muchii optimizate pentru traversarea relațiilor |
| Flexibilitatea schemei | Foarte flexibilă; evoluează pe măsură ce se descoperă informații noi | Rigidă; necesită definirea schemei înainte de introducerea datelor | Flexibilă; permite evoluția dinamică a schemei |
| Gestionarea relațiilor | Suport nativ pentru relații complexe, multi-hop | Necesită join-uri între tabele multiple; costisitor computațional | Optimizată pentru interogări eficiente de relații |
| Limbaj de interogare | SPARQL (pentru RDF), Cypher (pentru grafuri cu proprietăți), sau API-uri custom | SQL | Cypher, Gremlin sau SPARQL |
| Înțelegere semantică | Pune accent pe sens și context prin ontologii | Se concentrează pe stocarea și regăsirea datelor | Se concentrează pe traversare eficientă și pattern matching |
| Utilizări | Căutare semantică, descoperire de cunoștințe, sisteme AI, rezoluție de entități | Tranzacții de business, rapoarte, sisteme OLTP | Motoare de recomandare, detectare fraude, analiză de rețea |
| Integrare de date | Excelează la integrarea datelor eterogene din surse multiple | Necesită ETL și transformare semnificativă a datelor | Bună pentru date conectate, dar mai puțin semantică |
| Scalabilitate | Se scalează la miliarde de entități și trilioane de fapte | Scalare bună pentru date structurate, tranzacționale | Scalare bună pentru interogări cu multe relații |
| Capacități de inferență | Raționament avansat și derivare de cunoștințe prin ontologii | Limitate; necesită programare explicită | Limitate; focus pe potrivire de pattern-uri |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Rolul graficelor de cunoștințe în SEO și vizibilitatea AI
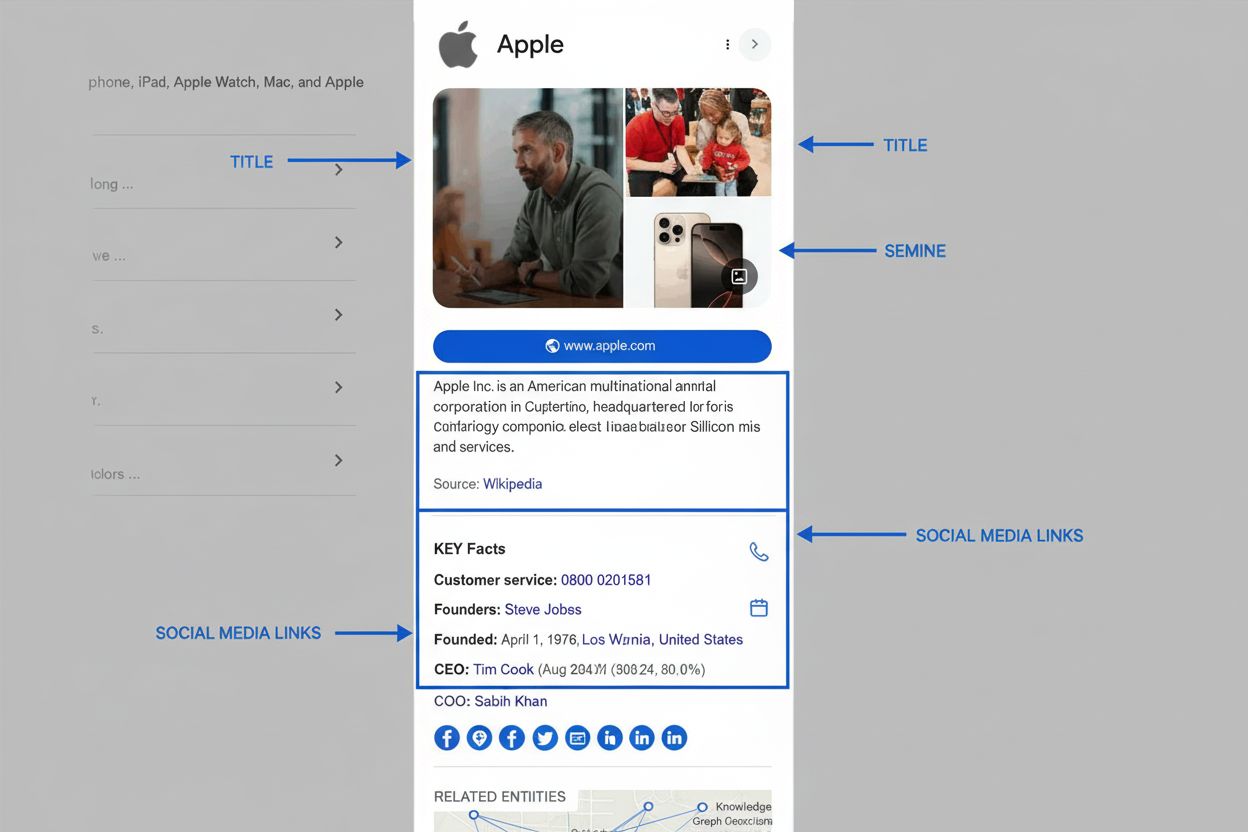
Graficele de cunoștințe au devenit centrale în strategiile moderne de SEO și vizibilitate AI pentru că determină fundamental modul în care informația apare în rezultatele căutării și în răspunsurile generate de AI. Când Google procesează o interogare, una dintre sarcinile principale este identificarea entității căutate, apoi extragerea informațiilor relevante din Graficul de cunoștințe pentru a popula funcțiile SERP. Această abordare bazată pe entități a dus la apariția căutării semantice — abilitatea Google de a înțelege sensul și contextul interogărilor, nu doar de a potrivi cuvinte cheie. Graficul de cunoștințe alimentează multiple funcții SERP cu vizibilitate ridicată care influențează direct ratele de click și vizibilitatea brandului. Panourile de cunoștințe apar proeminent pe desktop și mobil, afișând fapte curatoriate despre entitatea căutată, extrase din Graficul de cunoștințe. AI Overviews (fost Search Generative Experience) sintetizează informații din surse multiple identificate prin relații din grafic, oferind răspunsuri complete care, de multe ori, împing listele organice tradiționale mai jos pe pagină. People Also Ask folosește relații între entități pentru a sugera căutări și subiecte înrudite. Înțelegerea acestor funcții este esențială pentru branduri, deoarece reprezintă spațiu valoros în rezultate, adesea deasupra listărilor organice. Pentru organizațiile care monitorizează prezența în sisteme AI precum Perplexity, ChatGPT, Claude și Google AI Overviews, optimizarea pentru graficele de cunoștințe devine crucială. Aceste sisteme AI se bazează tot mai mult pe informații structurate despre entități și relații semantice pentru a genera răspunsuri corecte și contextualizate. Un brand care și-a optimizat prezența entității în graficele de cunoștințe — prin markup structurat, panouri revendicate și informații consistente în surse — va apărea mai probabil în răspunsuri AI relevante. În schimb, brandurile cu informații incomplete sau inconsistente pot fi trecute cu vederea sau reprezentate greșit în sistemele AI, afectând direct vizibilitatea și reputația.
Surse de date și construcția graficului de cunoștințe
Graficul de cunoștințe Google se bazează pe un ecosistem divers de surse de date, fiecare contribuind cu tipuri diferite de informații și având roluri diferite. Proiecte de date deschise și comunitare precum Wikipedia și Wikidata formează fundația pentru mult conținut din Grafic. Wikipedia oferă descrieri narative și informații de sinteză ce apar frecvent în panouri, în timp ce Wikidata — o bază de cunoștințe structurată care susține Wikipedia — furnizează date despre entități și relații în format machine-readable. Google a folosit anterior Freebase, propria bază de date editabilă comunitar, dar a trecut la Wikidata după închiderea Freebase în 2016. Sursele guvernamentale oferă informații autoritare, în special pentru întrebări factuale. CIA World Factbook furnizează informații despre țări, zone geografice și organizații. Data Commons, proiectul Google de date publice structurate, agregă date de la organizații guvernamentale și multi-guvernamentale precum ONU sau UE, oferind statistici și date demografice. Datele despre vreme și calitatea aerului provin de la agenții meteorologice naționale și internaționale, alimentând funcțiile de „nowcast” meteo ale Google. Datele private licențiate completează graficul cu informații care se schimbă rapid sau necesită expertiză specializată. Google licențiază date de piață financiară de la furnizori precum Morningstar, S&P Global sau Intercontinental Exchange pentru afișarea prețurilor acțiunilor. Datele sportive provin din parteneriate cu ligi, echipe și agregatori precum Stats Perform, oferind scoruri în timp real și statistici istorice. Datele structurate de pe site-uri web contribuie semnificativ la îmbogățirea graficului. Când site-urile implementează markup Schema.org, oferă explicit informații semantice pe care Google le poate extrage și integra. De aceea, implementarea markup-ului corect — Organization, LocalBusiness, FAQPage și altele relevante — este critică pentru brandurile care doresc să influențeze reprezentarea lor în Grafic. Google Books oferă date din peste 40 de milioane de cărți scanate și digitalizate, furnizând context istoric, informații biografice și descrieri detaliate ce îmbogățesc cunoștințele despre entități. Feedback-ul utilizatorilor și panourile revendicate permit indivizilor și organizațiilor să influențeze direct informațiile din Grafic. Când utilizatorii trimit feedback sau când reprezentanții autorizați revendică și actualizează panouri, aceste informații sunt procesate și pot duce la actualizări în Grafic. Această abordare human-in-the-loop asigură acuratețea și reprezentativitatea, deși sistemele automate Google decid informația afișată final.
Graficele de cunoștințe și E-E-A-T: Construirea autorității și încrederii
Google a declarat explicit că prioritizează informațiile din surse ce demonstrează E-E-A-T (Experiență, Expertiză, Autoritate și Încredere) la construirea și actualizarea Graficului de cunoștințe. Această legătură nu este întâmplătoare — reflectă angajamentul Google de a afișa informații de încredere și autoritare. Dacă site-ul tău este sursă pentru funcții SERP alimentate de Grafic, de obicei e un semnal puternic că Google te recunoaște ca autoritate pe subiect. În schimb, dacă nu apari în funcții alimentate de Grafic, pot exista probleme de E-E-A-T ce trebuie adresate. Construirea E-E-A-T pentru vizibilitate în Grafic presupune o abordare pe mai multe planuri. Experiența înseamnă să demonstrezi că tu sau colaboratorii ai experiență reală în domeniu. Pentru un site medical, asta înseamnă conținut semnat de profesioniști acreditați. Pentru companiile tech, evidențierea expertizei inginerilor implicați direct. Expertiza presupune conținut aprofundat și corect, ce tratează subiectul cu acuratețe și detaliu. Autoritatea se construiește prin recunoaștere în domeniu — premii, certificări, apariții media, conferințe și citări din alte surse autoritare. Pentru organizații, înseamnă stabilirea brandului ca lider recunoscut. Încrederea se bazează pe transparență, acuratețe, citare corectă, autori clari și servicii clienți responsabile. Organizațiile ce excelează la semnalele E-E-A-T au mai multe șanse ca informațiile lor să fie incluse în Grafic și să apară în răspunsuri generate de AI, creând un cerc virtuos unde autoritatea duce la vizibilitate și viceversa.
Graficele de cunoștințe în sisteme AI și căutarea generativă
Apariția modelelor lingvistice mari (LLM) și a AI generative a adus o importanță nouă graficelor de cunoștințe în ecosistemul AI. Deși LLM-uri precum ChatGPT, Claude sau Perplexity nu sunt antrenate direct pe Graficul de cunoștințe Google, ele se bazează tot mai mult pe cunoștințe structurate și înțelegere semantică similară. Multe sisteme AI utilizează metode de retrieval-augmented generation (RAG), unde modelul interoghează grafice de cunoștințe sau baze de date structurate în timp real, pentru a fundamenta răspunsurile pe informații factuale și a reduce halucinațiile. Graficele publice precum Wikidata sunt folosite pentru fine-tuning sau injectare de cunoștințe structurate, îmbunătățind capacitatea modelelor de a înțelege relațiile dintre entități. Pentru branduri, optimizarea pentru graficele de cunoștințe are implicații ce depășesc căutarea tradițională Google. Când utilizatorii întreabă sisteme AI despre industria, produsele sau organizația ta, corectitudinea răspunsului depinde parțial de cât de bine este reprezentată entitatea ta în surse structurate. O organizație cu o intrare Wikidata bine întreținută, panou Google revendicat și date structurate consistente pe site va fi reprezentată mai corect în răspunsuri AI. În schimb, organizațiile cu informații incomplete sau contradictorii pot fi reprezentate greșit sau ignorate. Aceasta creează o nouă dimensiune de monitorizare a vizibilității AI — nu doar cum apare brandul în căutare tradițională, ci și în răspunsuri AI pe mai multe platforme. Instrumentele de monitorizare a prezenței brandului în AI se concentrează din ce în ce mai mult pe relațiile dintre entități și reprezentarea în grafice, recunoscând că acești factori influențează direct vizibilitatea în AI.
Implementare practică: Optimizarea pentru graficele de cunoștințe
Organizațiile care doresc să își optimizeze prezența în graficele de cunoștințe ar trebui să urmeze o abordare sistematică, bazată pe fundamente SEO, la care se adaugă strategii specifice entităților. Primul pas este implementarea markup-ului de date structurate folosind vocabular Schema.org. Acesta presupune adăugarea de markup JSON-LD, Microdata sau RDFa pe site, care descrie explicit organizația, produsele, persoanele și alte entități relevante. Tipurile cheie de scheme sunt Organization (pentru companii), LocalBusiness (pentru locații), Person (pentru profiluri individuale), Product (pentru produse) și FAQPage (pentru întrebări frecvente). După implementarea schemei, este esențial să testezi și validezi markup-ul folosind Google Structured Data Testing Tool pentru a te asigura că este corect și recunoscut. Al doilea pas presupune auditarea și optimizarea informațiilor din Wikidata și Wikipedia. Dacă organizația sau entitățile cheie au pagini Wikipedia, asigură-te că sunt corecte, complete și bine surse. Pentru Wikidata, verifică existența entității și corectitudinea proprietăților și relațiilor. Editarea Wikipedia/Wikidata necesită însă atenție la politici și norme comunitare — autopromovarea sau conflictele de interese nedeclarate pot duce la reverturi și afectarea reputației. Al treilea pas este revendicarea și optimizarea Google Business Profile (pentru afaceri locale) și panourilor de cunoștințe (pentru persoane și organizații). Un panou revendicat oferă control sporit asupra modului de afișare și permite sugerarea rapidă a modificărilor. Următorul pas este asigurarea consistenței pe toate proprietățile — website, Google Business Profile, profiluri social media și directoare de afaceri. Informațiile contradictorii bulversează sistemele Google și pot împiedica reprezentarea corectă în Grafic. Al cincilea pas este crearea de conținut axat pe entități, nu pe cuvinte cheie tradiționale. În loc să scrii articole separate pentru „cel mai bun software CRM”, „funcții Salesforce” sau „prețuri HubSpot”, creează un cluster de conținut complex care stabilește relații clare de entitate: Salesforce este o platformă CRM, concurează cu HubSpot, se integrează cu Slack etc. Această abordare ajută graficele să înțeleagă semnificația semantică și relațiile din conținutul tău.
Aspecte cheie ale optimizării și implementării graficelor de cunoștințe
- Implementare date structurate: Adaugă markup Schema.org pe toate paginile relevante, inclusiv Organization, LocalBusiness, Product, Person și FAQPage, și validează cu instrumentele Google
- Consistența entității: Menține informații identice (nume, adresă, telefon, descriere) pe website, Google Business Profile, social media și directoare terțe pentru a evita semnale contradictorii
- Revendicare panou de cunoștințe: Revendică panoul pentru control direct asupra informațiilor și posibilitatea de a sugera modificări procesate mai rapid de Google
- Optimizare Wikidata: Asigură-te că organizația sau entitățile cheie au intrări Wikidata corecte, complete, cu proprietăți și relații corespunzătoare, respectând regulile comunității
- Semnale E-E-A-T: Construiește autoritate prin conținut expert, acreditări ale autorilor, recunoaștere în industrie, premii, mențiuni media și surse transparente pentru creșterea includerii în Grafic
- Strategie de conținut bazată pe entități: Organizează conținutul în jurul entităților și relațiilor lor, nu doar al cuvintelor cheie, creând grupuri de conținut cu legături semantice evidente
- Profiluri social media: Creează și optimizează profiluri pe platforme recunoscute de Google (Facebook, Instagram, LinkedIn, YouTube, TikTok, X, Pinterest, Snapchat) și leagă-le folosind proprietatea “sameAs”
- Profiluri de business terțe: Menține profiluri pe directoare autoritare precum Crunchbase, Forbes și Fortune, pe care Google le folosește ca surse pentru Grafic
- Monitorizare acuratețe date: Auditează regulat informațiile despre entitate din toate sursele și corectează datele expirate sau incorecte, inclusiv contactând site-uri terțe dacă e nevoie
- Trimitere feedback: Folosește mecanismele Google din panouri și rezultate pentru a raporta inexactități și a sugera îmbunătățiri la informațiile din Grafic
- Monitorizare vizibilitate AI: Urmărește cum apare brandul tău în răspunsuri generate de AI pe Perplexity, ChatGPT, Claude și Google AI Overviews pentru a înțelege reprezentarea entității tale în sisteme AI
Viitorul graficelor de cunoștințe: Evoluție și implicații strategice
Graficele de cunoștințe evoluează rapid ca răspuns la avansul inteligenței artificiale, schimbarea comportamentului de căutare și apariția de noi platforme și tehnologii. O tendință importantă este extinderea graficelor multimodale care integrează text, imagini, audio și video. Pe măsură ce căutarea vocală și vizuală devin tot mai prezente, graficele se adaptează pentru a înțelege și reprezenta informație prin mai multe modalități. Proiectele Google de căutare multimodală — precum Google Lens — reflectă această evoluție: sistemul trebuie să înțeleagă nu doar interogări text, ci și inputuri vizuale, necesitând grafice capabile să conecteze informații între medii diferite. Altă direcție importantă este creșterea sofisticării în îmbogățirea semantică și procesarea limbajului natural la construcția graficelor. Pe măsură ce NLP-ul avansează, graficele pot extrage relații semantice tot mai nuanțate din text nestructurat, reducând dependența de date marcate manual sau explicit. Astfel, organizațiile cu conținut de calitate și bine