Diagramă
Află ce sunt diagramele, tipurile lor și cum transformă datele brute în perspective acționabile. Ghid esențial despre formatele de vizualizare a datelor pentru ...
9 min citire
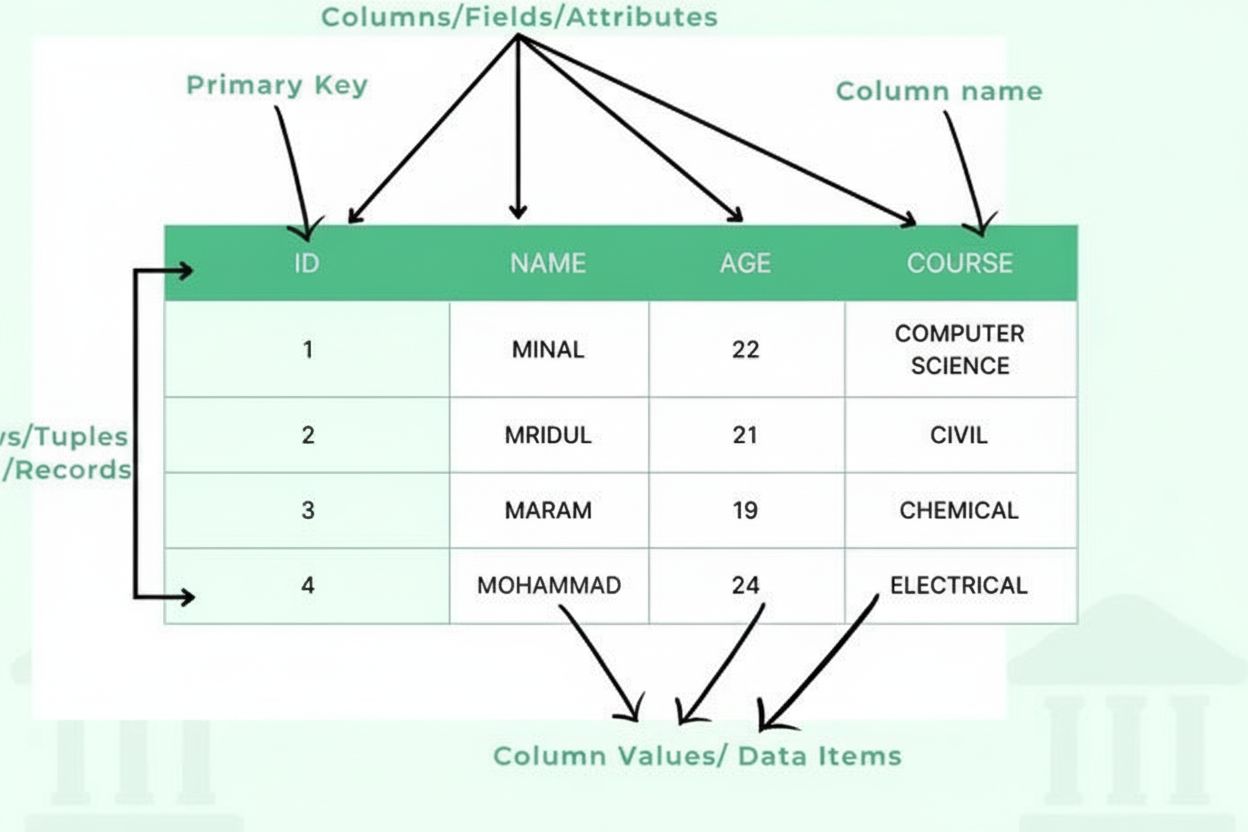
Un tabel este o metodă structurată de organizare a datelor care aranjează informațiile într-un format de grilă bidimensională, alcătuită din rânduri orizontale și coloane verticale, permițând stocarea, regăsirea și analiza eficientă a datelor. Tabelele reprezintă elementul de bază al bazelor de date relaționale, al foilor de calcul și al sistemelor de prezentare a datelor, oferind utilizatorilor posibilitatea de a localiza rapid și compara informații conexe pe mai multe dimensiuni.
Un tabel este o metodă structurată de organizare a datelor care aranjează informațiile într-un format de grilă bidimensională, alcătuită din rânduri orizontale și coloane verticale, permițând stocarea, regăsirea și analiza eficientă a datelor. Tabelele reprezintă elementul de bază al bazelor de date relaționale, al foilor de calcul și al sistemelor de prezentare a datelor, oferind utilizatorilor posibilitatea de a localiza rapid și compara informații conexe pe mai multe dimensiuni.
Un tabel este o structură fundamentală de date care organizează informațiile într-un format de grilă bidimensională, alcătuită din rânduri orizontale și coloane verticale. În forma sa cea mai simplă, un tabel reprezintă o colecție de date conexe aranjate într-o manieră structurată, unde fiecare intersecție dintre un rând și o coloană conține un singur element de date sau celulă. Tabelele servesc drept piatră de temelie pentru bazele de date relaționale, foi de calcul, depozite de date și practic orice sistem care necesită stocare și regăsire organizată a informațiilor. Puterea tabelelor constă în capacitatea lor de a permite scanarea vizuală rapidă, compararea logică a datelor pe mai multe dimensiuni și accesarea programatică a unor informații specifice prin limbaje standardizate de interogare. Fie că sunt folosite în analiza de business, cercetare științifică sau platforme de monitorizare AI, tabelele oferă un format universal înțeles pentru prezentarea datelor structurate, ușor de interpretat atât de oameni, cât și de mașini.
Conceptul de organizare a informațiilor în rânduri și coloane precede cu secole apariția informaticii moderne. Civilizațiile antice foloseau formate tabelare pentru a consemna inventarul, tranzacțiile financiare și observațiile astronomice. Totuși, formalizarea structurilor tabelare în informatică a apărut odată cu dezvoltarea teoriei bazelor de date relaționale de către Edgar F. Codd în 1970, care a revoluționat modul de stocare și interogare a datelor. Modelul relațional a stabilit că datele trebuie organizate în tabele cu relații clar definite, schimbând fundamental principiile de proiectare a bazelor de date. De-a lungul anilor 1980 și 1990, aplicațiile de foi de calcul precum Lotus 1-2-3 și Microsoft Excel au democratizat utilizarea tabelelor, făcând organizarea tabelară a datelor accesibilă utilizatorilor non-tehnici. Astăzi, aproximativ 97% dintre organizații folosesc aplicații de foi de calcul pentru gestionarea și analiza datelor, demonstrând importanța durabilă a organizării datelor în tabele. Evoluția continuă cu dezvoltări moderne în baze de date columnare, sisteme NoSQL și data lakes, care provoacă abordările tradiționale orientate pe rânduri, menținând totodată structuri fundamentale de tip tabel pentru organizarea informațiilor.
Un tabel este alcătuit din mai multe componente structurale esențiale care lucrează împreună pentru a crea un cadru organizat de date. Coloanele (numite și câmpuri sau atribute) sunt dispuse vertical și reprezintă categorii de informații, cum ar fi „Nume client”, „Adresă de email” sau „Data achiziției”. Fiecare coloană are un tip de date definit, care specifică ce fel de informații poate conține—întregi, șiruri de text, date calendaristice, zecimale sau structuri mai complexe. Rândurile (numite și înregistrări sau tupluri) sunt dispuse orizontal și reprezintă intrări sau entități individuale de date, fiecare rând conținând o înregistrare completă. Intersecția dintre un rând și o coloană creează o celulă sau un element de date, care conține o singură valoare. Anteturile de coloană identifică fiecare coloană și apar în partea de sus a tabelului, oferind context datelor de mai jos. Cheile primare sunt coloane speciale care identifică unic fiecare rând, asigurând că nu există înregistrări duplicate. Cheile externe stabilesc relații între tabele, referindu-se la cheile primare din alte tabele. Această organizare ierarhică permite bazelor de date să mențină integritatea datelor, să prevină redundanța și să suporte interogări complexe ce extrag informații pe baza mai multor criterii.
| Aspect | Tabele orientate pe rânduri | Tabele orientate pe coloane | Abordări hibride |
|---|---|---|---|
| Metoda de stocare | Datele sunt stocate și accesate pe înregistrări complete | Datele sunt stocate și accesate pe coloane individuale | Combină avantajele ambelor abordări |
| Performanța interogărilor | Optimizată pentru interogări tranzacționale ce returnează înregistrări complete | Optimizată pentru interogări analitice pe coloane specifice | Performanță echilibrată pentru sarcini mixte |
| Cazuri de utilizare | OLTP (procesare tranzacțională online), operațiuni de business | OLAP (procesare analitică online), depozite de date | Analitică în timp real, inteligență operațională |
| Exemple de baze de date | MySQL, PostgreSQL, Oracle, SQL Server | Vertica, Cassandra, HBase, Parquet | Snowflake, BigQuery, Apache Iceberg |
| Eficiența compresiei | Rate de compresie mai mici din cauza diversității datelor | Rate de compresie mai mari pentru valori similare pe coloană | Compresie optimizată pentru modele specifice |
| Performanța la scriere | Scrieri rapide pentru înregistrări complete | Scrieri mai lente ce necesită actualizarea coloanelor | Performanță echilibrată la scriere |
| Scalabilitate | Scalabil pentru volum mare de tranzacții | Scalabil pentru volum mare de date și complexitate a interogărilor | Scalabilitate pentru ambele dimensiuni |
În sistemele de gestionare a bazelor de date relaționale (RDBMS), tabelele sunt implementate ca și colecții structurate de rânduri, fiecare rând respectând o schemă predefinită. Schema definește structura tabelului, specificând numele coloanelor, tipurile de date, constrângerile și relațiile. Atunci când datele sunt introduse într-un tabel, sistemul de gestionare a bazelor de date validează ca fiecare valoare să corespundă tipului de date al coloanei și să respecte orice constrângeri definite. De exemplu, o coloană definită ca INTEGER va respinge valori de tip text, iar o coloană marcată ca NOT NULL va respinge valori goale. Indexurile sunt create pe coloanele interogate frecvent pentru a accelera regăsirea datelor, funcționând ca referințe organizate care permit bazei de date să localizeze rapid rânduri specifice fără a scana întregul tabel. Normalizarea este un principiu de proiectare care organizează tabelele pentru a minimiza redundanța datelor și a îmbunătăți integritatea acestora, prin împărțirea informațiilor în tabele relaționate conectate prin chei. Bazele de date moderne suportă tranzacții, care asigură că mai multe operațiuni asupra tabelelor fie se finalizează cu succes toate, fie sunt anulate împreună, menținând consistența chiar și în caz de defecțiuni ale sistemului. Optimizatorul de interogări din motoarele de baze de date analizează interogările SQL și determină cea mai eficientă modalitate de accesare a datelor din tabele, ținând cont de indexuri și statistici despre tabele.
Tabelele reprezintă principalul mecanism de prezentare a datelor structurate către utilizatori, atât în format digital, cât și tipărit. În aplicațiile de business intelligence și analiză, tabelele afișează metrici agregate, indicatori de performanță și detalii despre tranzacții, permițând factorilor de decizie să înțeleagă seturi complexe de date dintr-o privire. Cercetările arată că 83% dintre profesioniștii în business se bazează pe tabele ca principal instrument pentru analiza informațiilor, deoarece tabelele permit comparații precise de valori și identificarea de tipare. Tabelele HTML pe website-uri utilizează markup semantic cu elemente <table>, <tr> (rând tabel), <td> (celulă de date) și <th> (antet tabel) pentru structurarea datelor atât pentru afișare vizuală, cât și pentru interpretare programatică. Aplicațiile de foi de calcul precum Microsoft Excel, Google Sheets sau LibreOffice Calc extind funcționalitățile de bază ale tabelului cu formule, formatare condiționată și tabele pivot, permițând utilizatorilor să efectueze calcule și să reorganizeze datele dinamic. Cele mai bune practici în vizualizarea datelor recomandă utilizarea tabelelor atunci când valorile exacte contează mai mult decât tiparele vizuale, când se compară mai multe atribute ale unor înregistrări individuale sau când utilizatorii trebuie să efectueze căutări sau calcule. Inițiativa W3C pentru Accesibilitatea Webului subliniază că tabelele structurate corespunzător, cu antete clare și markup adecvat, sunt esențiale pentru accesibilitatea datelor de către utilizatorii cu dizabilități, în special cei care folosesc cititoare de ecran.
În contextul platformelor de monitorizare AI precum AmICited, tabelele joacă un rol critic în organizarea și prezentarea datelor despre modul în care conținutul apare în diverse sisteme AI. Tabelele de monitorizare urmăresc metrici precum frecvența citărilor, datele aparițiilor, sursele platformelor AI (ChatGPT, Perplexity, Google AI Overviews, Claude) și informații contextuale despre modul în care domeniile și URL-urile sunt referențiate. Aceste tabele permit organizațiilor să înțeleagă vizibilitatea brandului lor în răspunsurile generate de AI și să identifice tendințe privind modul în care diferite sisteme AI citează sau fac referire la conținut. Structura tabelară a monitorizării permite filtrarea, sortarea și agregarea datelor despre citări, făcând posibilă răspunderea la întrebări precum „Care dintre URL-urile noastre apar cel mai frecvent în răspunsurile Perplexity?” sau „Cum a evoluat rata noastră de citare în ultima lună?”. Tabelele de date din sistemele de monitorizare facilitează și comparațiile pe mai multe dimensiuni—compararea tiparelor de citare între diferite platforme AI, analiza creșterii citărilor în timp sau identificarea tipurilor de conținut care primesc cele mai multe referințe AI. Posibilitatea de a exporta datele de monitorizare din tabele în rapoarte, dashboard-uri și alte instrumente de analiză face ca tabelele să fie indispensabile pentru organizațiile care doresc să-și înțeleagă și să-și optimizeze prezența în conținutul generat de AI.
O proiectare eficientă a tabelelor implică o atenție deosebită la structură, convenții de denumire și principii de organizare a datelor. Denumirea coloanelor trebuie să utilizeze identificatori clari și descriptivi, care reflectă cu acuratețe datele conținute, evitând abrevierile ce pot crea confuzii pentru utilizatori sau dezvoltatori. Alegerea tipurilor de date este crucială—selectarea tipurilor potrivite previne introducerea de date invalide și permite sortarea și compararea corectă. Definirea cheii primare asigură că fiecare rând poate fi identificat unic, fiind esențială pentru integritatea datelor și stabilirea relațiilor cu alte tabele. Normalizarea reduce redundanța datelor prin organizarea informațiilor în tabele relaționate, evitând stocarea datelor duplicate în mai multe locuri. Strategia de indexare trebuie să echilibreze performanța la interogare cu costurile de întreținere a indexurilor în timpul modificărilor de date. Documentarea structurii tabelului, incluzând definițiile coloanelor, tipurile de date, restricțiile și relațiile, este esențială pentru mentenanța pe termen lung. Controlul accesului trebuie implementat pentru a proteja datele sensibile din tabele împotriva accesului neautorizat. Optimizarea performanței implică monitorizarea timpilor de execuție ai interogărilor și ajustarea structurii tabelelor, a indexurilor sau a interogărilor pentru a îmbunătăți eficiența. Procedurile de backup și recuperare trebuie stabilite pentru a proteja datele din tabele împotriva pierderii sau coruperii.
Viitorul organizării datelor bazate pe tabele evoluează pentru a răspunde unor cerințe din ce în ce mai complexe, păstrând în același timp principiile fundamentale care fac tabelele eficiente. Formatele de stocare columnare precum Apache Parquet și ORC devin standard în mediile big data, optimizând tabelele pentru sarcini analitice și menținând structura tabelară. Datele semi-structurate în formate JSON și XML sunt stocate tot mai des în coloanele tabelelor, permițând acomodarea atât a datelor structurate cât și a celor flexibile. Integrarea machine learning permite bazelor de date să optimizeze automat structura tabelelor și execuția interogărilor pe baza tiparelor de utilizare. Platformele de analiză în timp real extind tabelele pentru a suporta date de streaming și actualizări continue, depășind operațiunile tradiționale de tip batch. Bazele de date cloud-native reproiectează implementările tabelelor pentru a valorifica calculul distribuit, permițând scalarea tabelelor pe mai multe servere și regiuni geografice. Cadrul de guvernanță a datelor pune accent mai mare pe metadata tabelelor, urmărirea provenienței și metrici de calitate pentru a asigura fiabilitatea datelor. Apariția platformelor de date alimentate de AI creează noi oportunități pentru ca tabelele să servească drept surse structurate pentru antrenarea modelelor de machine learning, ridicând totodată întrebări despre modul în care tabelele ar trebui proiectate pentru a furniza date de instruire de înaltă calitate. Pe măsură ce organizațiile generează volume exponențial mai mari de date, tabelele rămân structura fundamentală pentru organizarea, interogarea și analiza informațiilor, cu inovații concentrate pe îmbunătățirea performanței, scalabilității și integrării cu tehnologiile moderne de date.
Un rând este o aranjare orizontală a datelor care reprezintă o singură înregistrare sau entitate, în timp ce o coloană este o aranjare verticală care reprezintă un anumit atribut sau câmp comun tuturor înregistrărilor. Într-un tabel de bază de date, fiecare rând conține informații complete despre o entitate (cum ar fi un client), iar fiecare coloană conține un tip de informație (precum numele sau adresa de e-mail a clientului). Împreună, rândurile și coloanele creează structura bidimensională care definește un tabel.
Tabelele reprezintă structura organizațională fundamentală în bazele de date relaționale, permițând stocarea, regăsirea și manipularea eficientă a datelor. Acestea permit bazelor de date să mențină integritatea datelor prin scheme structurate, să suporte interogări complexe pe multiple dimensiuni și să faciliteze relațiile dintre diferite entități de date prin chei primare și externe. Tabelele fac posibilă organizarea a milioane de înregistrări într-un mod atât eficient computațional, cât și logic pentru operațiunile de business.
Un tabel este alcătuit din mai multe componente esențiale: coloane (câmpuri/atribute) care definesc tipurile și categoriile de date, rânduri (înregistrări/tupluri) care conțin intrări individuale de date, antete care identifică fiecare coloană, elemente de date (celule) care stochează valorile efective, chei primare care identifică unic fiecare rând și, eventual, chei externe care stabilesc relații cu alte tabele. Fiecare componentă are un rol critic în menținerea organizării și integrității datelor.
În platformele de monitorizare AI precum AmICited, tabelele sunt esențiale pentru organizarea și prezentarea datelor despre aparițiile modelelor AI, citări și mențiuni de brand în diferite sisteme AI. Tabelele permit sistemelor de monitorizare să afișeze date structurate despre când și unde apare conținutul în răspunsurile AI, facilitând urmărirea metricilor, compararea performanței între platforme și identificarea tendințelor privind modul în care sistemele AI citează sau fac referire la anumite domenii și URL-uri.
Bazele de date orientate pe rânduri (precum bazele de date relaționale tradiționale) stochează și accesează datele pe înregistrări complete, fiind eficiente pentru tranzacții ce necesită toate informațiile despre o entitate. Bazele de date orientate pe coloane stochează datele pe coloane, fiind mai rapide pentru interogări analitice ce au nevoie de anumite atribute din multe înregistrări. Alegerea între aceste abordări depinde dacă principalul caz de utilizare implică operațiuni tranzacționale sau interogări analitice.
Tabelele accesibile necesită markup HTML adecvat folosind elemente semantice precum `
Coloanele unui tabel pot stoca diverse tipuri de date, inclusiv întregi, numere cu virgulă mobilă, șiruri de caractere/text, date și ore, booleeni și tipuri tot mai complexe precum JSON sau XML. Fiecare coloană are un tip de date definit care restricționează ce valori pot fi introduse, asigurând consistența datelor și permițând sortarea și compararea corectă. Unele baze de date suportă și tipuri specializate precum date geografice, array-uri sau tipuri definite de utilizator.
Începe să urmărești cum te menționează chatbot-urile AI pe ChatGPT, Perplexity și alte platforme. Obține informații utile pentru a-ți îmbunătăți prezența în AI.
Află ce sunt diagramele, tipurile lor și cum transformă datele brute în perspective acționabile. Ghid esențial despre formatele de vizualizare a datelor pentru ...
Află de ce tabelele sunt esențiale pentru optimizarea căutării AI. Descoperă cum datele structurate din tabele îmbunătățesc înțelegerea AI, cresc șansele de cit...
Datele structurate sunt marcaje standardizate care ajută motoarele de căutare să înțeleagă conținutul paginilor web. Află cum JSON-LD, schema.org și microdata î...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.