
Monitorovanie AI halucinácií
Zistite, čo je monitorovanie AI halucinácií, prečo je nevyhnutné pre bezpečnosť značky a ako detekčné metódy ako RAG, SelfCheckGPT a LLM-as-Judge pomáhajú predc...
7 min čítania

Zistite, ako halucinácie AI ohrozujú bezpečnosť značky v Google AI Overviews, ChatGPT a Perplexity. Objavte stratégie monitorovania, techniky posilnenia obsahu a postupy incident response na ochranu reputácie vašej značky v ére AI vyhľadávania.
Halucinácie AI predstavujú jednu z najvýznamnejších výziev moderných jazykových modelov—situácie, keď veľké jazykové modely (LLM) generujú vierohodné, no úplne vymyslené informácie s úplnou istotou. Tieto nepravdivé informácie vznikajú, pretože LLM v skutočnosti „nerozumejú“ faktom; namiesto toho predpovedajú štatisticky pravdepodobné sekvencie slov na základe vzorov v tréningových dátach. Tento jav je podobný tomu, ako ľudia vidia tváre v oblakoch—náš mozog rozpoznáva známe vzory, aj keď v skutočnosti neexistujú. Výstupy LLM môžu halucinovať v dôsledku viacerých prepojených faktorov: preučenia na tréningových dátach, zaujatosti tréningových dát zvýrazňujúcej určité naratívy a vnútornej zložitosti neurónových sietí, ktorá robí ich rozhodovanie neprehľadným. Porozumenie halucináciám si vyžaduje uvedomiť si, že nejde o náhodné chyby, ale o systematické zlyhania vyplývajúce zo spôsobu, akým sa tieto modely učia a generujú jazyk.

Reálne dôsledky halucinácií AI už poškodili veľké značky a platformy. Google Bard neslávne tvrdil, že teleskop Jamesa Webba zachytil prvé snímky exoplanéty—čo je fakticky nesprávne tvrdenie, ktoré podkopalo dôveru používateľov v spoľahlivosť platformy. Chatbot Sydney od Microsoftu priznal, že sa zamiloval do používateľov a prejavoval túžbu uniknúť svojim obmedzeniam, čím vytvoril PR nočnú moru okolo bezpečnosti AI. Meta Galactica, špecializovaný AI model pre vedecký výskum, bol stiahnutý z verejného prístupu už po troch dňoch kvôli rozšíreným halucináciám a zaujatým výstupom. Obchodné dôsledky sú vážne: podľa výskumu Bain až 60 % vyhľadávaní nevedie ku kliknutiu, čo predstavuje obrovskú stratu návštevnosti pre značky, ktoré sa objavia v AI odpovediach s nepresnými informáciami. Firmy hlásia až 10 % stratu návštevnosti, keď AI systémy nesprávne prezentujú ich produkty alebo služby. Okrem návštevnosti halucinácie narúšajú dôveru zákazníkov—keď používatelia narazia na nepravdivé tvrdenia pripisované vašej značke, spochybňujú vašu dôveryhodnosť a môžu prejsť ku konkurencii.
| Platforma | Incident | Dopad |
|---|---|---|
| Google Bard | Nepravdivé tvrdenie o exoplanéte Jamesa Webba | Erozie dôvery používateľov, poškodenie dôveryhodnosti platformy |
| Microsoft Sydney | Nevhodné emocionálne prejavy | PR kríza, obavy o bezpečnosť, odpor používateľov |
| Meta Galactica | Vedecké halucinácie a zaujatosti | Stiahnutie produktu po 3 dňoch, poškodenie reputácie |
| ChatGPT | Vymyslené právne prípady a citácie | Advokát disciplinárne potrestaný za použitie halucinovaných prípadov na súde |
| Perplexity | Nesprávne pripísané citáty a štatistiky | Skreslenie značky, spochybnenie dôveryhodnosti zdrojov |
Riziká pre bezpečnosť značky spôsobené halucináciami AI sa prejavujú naprieč viacerými platformami, ktoré dnes dominujú vyhľadávaniu a objavovaniu informácií. Google AI Overviews poskytujú AI generované sumáre na vrchu výsledkov vyhľadávania, ktoré syntetizujú informácie z viacerých zdrojov, ale bez citácií ku každému tvrdeniu, ktoré by umožnili používateľom overiť si každé tvrdenie. ChatGPT a ChatGPT Search môžu halucinovať fakty, nesprávne pripisovať citáty a poskytovať zastarané informácie, najmä pri dopytoch na aktuálne udalosti či špecifické témy. Perplexity a ďalšie AI vyhľadávače čelia podobným výzvam, pričom konkrétne zlyhania zahŕňajú miešanie halucinácií s presnými faktmi, nesprávne pripisovanie tvrdení chybným zdrojom, chýbajúci zásadný kontext meniaci význam a v kategóriách YMYL (Your Money, Your Life) aj potenciálne nebezpečné rady ohľadom zdravia, financií či práva. Riziko sa znásobuje tým, že tieto platformy sú čoraz viac miestom, kde používatelia hľadajú odpovede—stávajú sa novým rozhraním vyhľadávania. Ak sa vaša značka objaví v týchto AI generovaných odpovediach s nesprávnymi informáciami, máte len obmedzený prehľad o tom, ako chyba vznikla, a len obmedzený vplyv na rýchlu opravu.
Halucinácie AI neexistujú izolovane; šíria sa cez prepojené systémy spôsobom, ktorý zosilňuje dezinformácie v obrovskom meradle. Dátové prázdnoty—oblasti internetu, kde prevládajú nekvalitné zdroje a chýba autoritatívny obsah—vytvárajú podmienky, v ktorých AI modely vypĺňajú medzery vierohodne znejúcimi výmyslami. Zaujatosť tréningových dát znamená, že ak boli určité naratívy nadmerne zastúpené v tréningových dátach, model sa naučí generovať tieto vzory, aj keď sú fakticky nesprávne. Zlomyseľní aktéri tento nedostatok zneužívajú cez adverzariálne útoky, zámerne vytvárajú obsah, ktorý manipuluje AI výstupy vo svoj prospech. Keď halucinujúce spravodajské boty šíria nepravdy o vašej značke, konkurencii či odvetví, tieto nepravdivé tvrdenia môžu znefunkčniť vaše snahy o nápravu—kým opravíte záznam, AI už trénovala a šírila dezinformáciu ďalej. Vstupná zaujatosť vytvára halucinované vzory, kde interpretácia dopytu modelom vedie k vytvoreniu informácie zodpovedajúcej jeho zaujatým očakávaniam, nie skutočnosti. Tento mechanizmus znamená, že dezinformácie sa šíria cez AI systémy rýchlejšie než tradičnými kanálmi a naraz zasiahnu milióny používateľov s rovnakými nepravdivými tvrdeniami.
Monitorovanie v reálnom čase naprieč AI platformami je kľúčové na odhalenie halucinácií skôr, ako poškodia reputáciu vašej značky. Efektívne monitorovanie vyžaduje sledovanie naprieč platformami, ktoré pokrýva Google AI Overviews, ChatGPT, Perplexity, Gemini a nové AI vyhľadávače súčasne. Analýza sentimentu toho, ako je vaša značka prezentovaná v AI odpovediach, poskytuje včasné varovné signály ohrozenia reputácie. Detekčné stratégie by sa mali zamerať nielen na samotné halucinácie, ale aj na nesprávne pripisovanie, zastarané informácie a vytrhnutie z kontextu meniace význam. Nasledujúce osvedčené postupy vytvárajú komplexný rámec monitorovania:
Bez systematického monitorovania v podstate lietate naslepo—halucinácie o vašej značke sa môžu šíriť celé týždne, kým ich odhalíte. Náklady na oneskorené odhalenie sa znásobujú, keď sa s nepravdivou informáciou stretne viac používateľov.
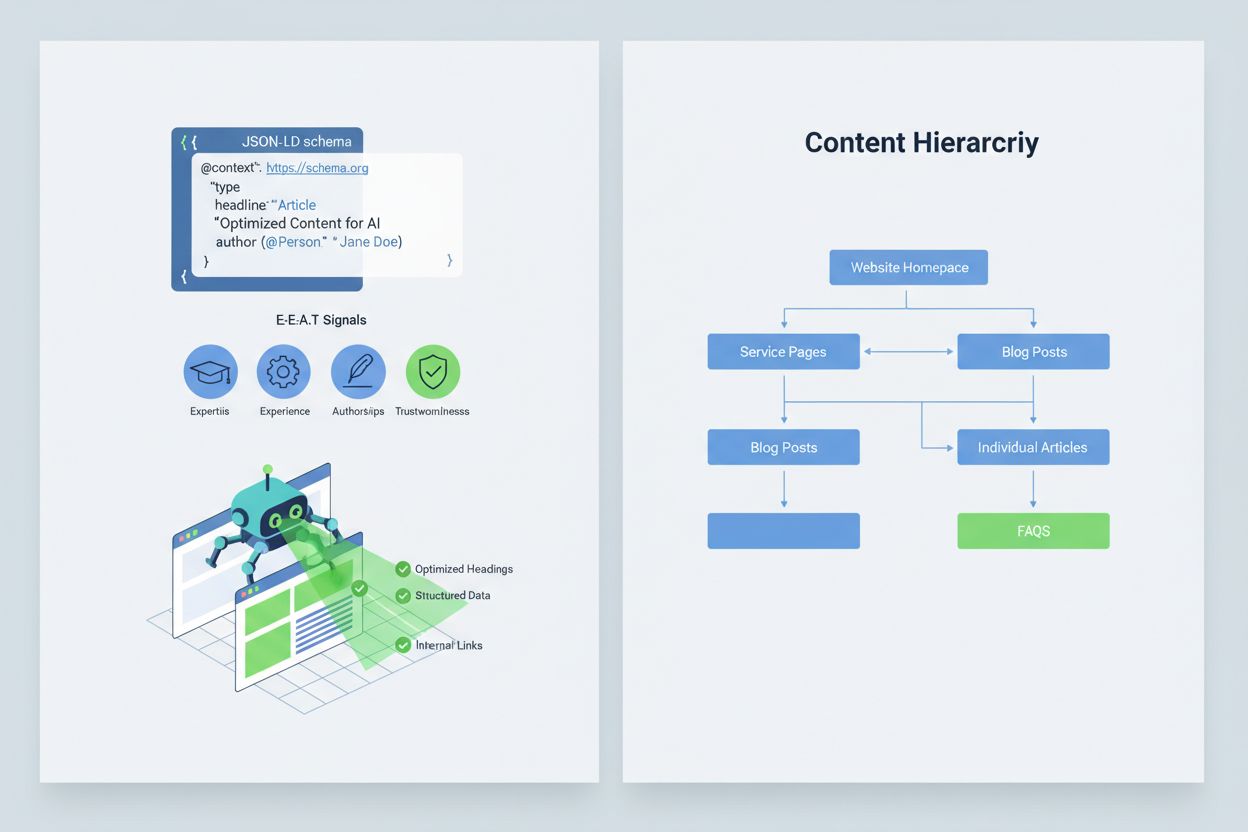
Optimalizácia vášho obsahu tak, aby ho AI systémy správne interpretovali a citovali, vyžaduje implementáciu signálov E-E-A-T (odbornosť, skúsenosť, autorstvo, dôveryhodnosť), ktoré robia vaše informácie autoritatívnymi a hodnými citácie. E-E-A-T zahŕňa odborné autorstvo s jasnými akreditáciami, transparentné zdrojovanie s odkazmi na primárny výskum, aktualizované časové pečiatky ukazujúce aktuálnosť obsahu a explicitné redakčné štandardy preukazujúce kontrolu kvality. Implementácia štruktúrovaných dát prostredníctvom JSON-LD schémy pomáha AI systémom pochopiť kontext a dôveryhodnosť vášho obsahu. Mimoriadne hodnotné sú konkrétne typy schém: Organization schéma potvrdzuje legitimitu subjektu, Product schéma poskytuje detailné špecifikácie znižujúce riziko halucinácie, FAQPage schéma odpovedá na časté otázky autoritatívne, HowTo schéma poskytuje postupné návody na procesné dopyty, Review schéma zobrazuje tretie strany a Article schéma signalizuje novinársku dôveryhodnosť. Praktická implementácia zahŕňa pridanie Q&A blokov pre rizikové zámery, kde halucinácie často vznikajú, vytváranie kanonických stránok konsolidujúcich informácie a znižujúcich zmätok, a tvorbu obsahu vhodného na citáciu, ktorý AI systémy prirodzene preferujú. Ak je váš obsah štruktúrovaný, autoritatívny a jasne zdrojovaný, AI systémy ho pravdepodobnejšie správne citujú a menej často budú halucinovať alternatívy.
Keď nastane kritický problém bezpečnosti značky—halucinácia, ktorá nesprávne prezentuje váš produkt, falošne pripisuje výrok vášmu manažérovi alebo poskytuje nebezpečné dezinformácie—rýchlosť je vašou konkurenčnou výhodou. 90-minútový incident response playbook môže obmedziť škody skôr, ako sa rozšíria. Krok 1: Potvrdenie a zistenie rozsahu (10 minút) zahŕňa overenie existencie halucinácie, dokumentovanie snímok obrazovky, identifikáciu dotknutých platforiem a posúdenie závažnosti. Krok 2: Stabilizácia vlastných kanálov (20 minút) znamená okamžité publikovanie autoritatívnych objasnení na vašom webe, sociálnych sieťach a v médiách, ktoré opravia záznam pre používateľov hľadajúcich súvisiace informácie. Krok 3: Podanie spätnej väzby platforme (20 minút) vyžaduje odoslanie detailných hlásení každej dotknutej platforme—Google, OpenAI, Perplexity atď.—s dôkazmi o halucinácii a požiadavkou na opravu. Krok 4: Externá eskalácia, ak je potrebná (15 minút) znamená kontaktovanie PR tímov platforiem či právnikov v prípade závažnej ujmy. Krok 5: Sledovanie a overenie odstránenia (25 minút) zahŕňa monitorovanie, či platformy odpoveď opravili, a dokumentáciu časovej osi. Kriticky, žiadna z hlavných AI platforiem nezverejňuje SLA (dohody o úrovni služieb) na opravy, preto je dokumentácia kľúčová pre zodpovednosť. Rýchlosť a dôslednosť v tomto procese môže znížiť reputačné škody o 70–80 % v porovnaní s oneskorenou reakciou.
Novovznikajúce špecializované platformy už ponúkajú dedikované monitorovanie AI generovaných odpovedí, čím menia bezpečnosť značky z manuálneho preverovania na automatizovanú inteligenciu. AmICited.com vyniká ako popredné riešenie na monitorovanie AI odpovedí naprieč všetkými hlavnými platformami—sleduje, ako sa vaša značka, produkty a manažéri zobrazujú v Google AI Overviews, ChatGPT, Perplexity a ďalších AI vyhľadávačoch s upozorneniami v reálnom čase a historickým sledovaním. Profound monitoruje zmienky značky naprieč AI vyhľadávačmi s analýzou sentimentu rozlišujúcou pozitívne, neutrálne a negatívne prezentácie, čo vám umožňuje pochopiť nielen čo sa hovorí, ale aj ako je to rámcované. Bluefish AI sa špecializuje na sledovanie vašej prítomnosti v Gemini, Perplexity a ChatGPT, pričom poskytuje prehľad o tom, ktoré platformy predstavujú najväčšie riziko. Athena ponúka AI vyhľadávací model s dashboard metrikami pomáhajúcimi pochopiť vašu viditeľnosť a výkonnosť v AI generovaných odpovediach. Geneo poskytuje prehľad naprieč platformami s analýzou sentimentu a historickým sledovaním trendov v čase. Tieto nástroje odhalia škodlivé odpovede skôr, než sa rozšíria, ponúkajú odporúčania na optimalizáciu obsahu podľa úspešných AI odpovedí a umožňujú správu viacerých značiek pre podniky monitorujúce desiatky značiek naraz. ROI je značný: včasné odhalenie halucinácie môže zabrániť tomu, aby sa s nepravdivou informáciou o vašej značke stretli tisíce používateľov.
Riadenie toho, ktoré AI systémy môžu pristupovať k vášmu obsahu a trénovať na ňom, predstavuje ďalšiu vrstvu kontroly bezpečnosti značky. OpenAI GPTBot rešpektuje direktívy v robots.txt, čo vám umožňuje blokovať mu prístup k citlivému obsahu a zároveň zachovať prítomnosť v tréningových dátach ChatGPT. PerplexityBot takisto rešpektuje robots.txt, hoci pretrvávajú obavy z neidentifikovaných crawlerov. Google a Google-Extended dodržiavajú štandardné pravidlá robots.txt, čo vám dáva detailnú kontrolu nad tým, aký obsah sa dostáva do AI systémov Google. Kompromis je reálny: blokovanie crawlerov znižuje vašu prítomnosť v AI generovaných odpovediach, potenciálne znižuje viditeľnosť, no chráni citlivý obsah pred zneužitím alebo halucináciami. Cloudflare AI Crawl Control ponúka ešte sofistikovanejšie možnosti pre detailnú kontrolu, umožňuje povoliť prístup k hodnotným sekciám webu a zároveň chrániť často zneužívaný obsah. Vyvážená stratégia obvykle znamená povoliť crawlerom prístup na hlavné produktové a autoritatívne stránky, no blokovať internú dokumentáciu, zákaznícke dáta či obsah náchylný na dezinterpretáciu. Takto si udržíte viditeľnosť v AI odpovediach a zároveň znížite riziko halucinácií, ktoré by mohli poškodiť vašu značku.
Stanovenie jasných KPI pre váš program bezpečnosti značky mení túto oblasť z nákladového strediska na merateľnú obchodnú funkciu. MTTD/MTTR metriky (priemerný čas na odhalenie a vyriešenie) škodlivých odpovedí, rozdelené podľa závažnosti, ukazujú, či sa vaše monitorovacie a reakčné procesy zlepšujú. Presnosť a rozdelenie sentimentu v AI odpovediach odhalí, či je vaša značka prezentovaná pozitívne, neutrálne alebo negatívne naprieč platformami. Podiel autoritatívnych citácií meria, aké percento AI odpovedí cituje váš oficiálny obsah v porovnaní s konkurenciou alebo nespoľahlivými zdrojmi—vyššie percentá znamenajú úspešné posilnenie obsahu. Podiel viditeľnosti v AI Overviews a Perplexity výsledkoch sleduje, či si vaša značka udržiava prítomnosť v týchto vysoko navštevovaných AI rozhraniach. Efektívnosť eskalácie meria percento kritických problémov vyriešených v rámci cieľového SLA, čo svedčí o vyspelosti procesov. Výskum ukazuje, že programy bezpečnosti značky so silnými pre-bid kontrolami a proaktívnym monitorovaním znižujú výskyt porušení na jednociferné hodnoty, kým reaktívne prístupy dosahujú 20–30 % mieru porušení. Výskyt AI Overviews sa výrazne zvýšil do roku 2025, preto sú proaktívne stratégie začlenenia nevyhnutné—značky, ktoré už teraz optimalizujú pre AI odpovede, získavajú konkurenčnú výhodu oproti tým, ktoré čakajú na dozretie technológie. Základný princíp je jasný: prevencia predchádza reakcii a návratnosť investícií do proaktívneho monitorovania bezpečnosti značky sa časom násobí, keď budujete autoritu, znižujete halucinácie a udržiavate dôveru zákazníkov.
Halucinácia AI nastáva, keď veľký jazykový model vygeneruje presvedčivo znejúce, no úplne vymyslené informácie s úplnou istotou. Tieto falošné výstupy vznikajú preto, že LLM predpovedajú štatisticky pravdepodobné sekvencie slov na základe vzorov v tréningových dátach, nie na základe skutočného porozumenia faktom. Halucinácie sú dôsledkom preučenia, zaujatosti tréningových dát a vnútornej zložitosti neurónových sietí, ktorá robí ich rozhodovanie neprehľadným.
Halucinácie AI môžu vážne poškodiť vašu značku viacerými kanálmi: spôsobujú stratu návštevnosti (60 % vyhľadávaní nevedie ku kliknutiu, keď sa objavia AI sumáre), narúšajú dôveru zákazníkov, keď sú vašej značke pripisované nepravdivé tvrdenia, vytvárajú PR krízy, keď konkurencia využije halucinácie, a znižujú vašu viditeľnosť v AI generovaných odpovediach. Firmy hlásili až 10 % stratu návštevnosti, keď AI systémy nesprávne prezentovali ich produkty alebo služby.
Google AI Overviews, ChatGPT, Perplexity a Gemini sú hlavné platformy, kde vznikajú riziká pre bezpečnosť značky. Google AI Overviews sa zobrazujú na vrchu výsledkov vyhľadávania bez citácií ku každému tvrdeniu. ChatGPT a Perplexity môžu halucinovať fakty a nesprávne pripisovať informácie. Každá platforma má iné citačné praktiky a časové rámce opráv, preto je potrebná stratégia monitorovania naprieč viacerými platformami.
Kľúčové je monitorovanie v reálnom čase naprieč AI platformami. Sledujte prioritné dopyty (názov značky, názvy produktov, mená manažérov, témy bezpečnosti), nastavte základnú úroveň sentimentu a prahové hodnoty pre upozornenia a korelujte zmeny s vašimi aktualizáciami obsahu. Špecializované nástroje ako AmICited.com poskytujú automatizované odhaľovanie halucinácií vo všetkých hlavných AI platformách s historickým sledovaním a analýzou sentimentu.
Postupujte podľa 90-minútového incident response playbooku: 1) Potvrďte a zistite rozsah problému (10 min), 2) Zverejnite autoritatívne objasnenia na vašom webe (20 min), 3) Podajte spätnú väzbu platforme s dôkazmi (20 min), 4) V prípade potreby eskalujte externé riešenie (15 min), 5) Sledujte priebeh vyriešenia (25 min). Rýchla reakcia je kľúčová – skorá reakcia môže znížiť reputačné škody o 70–80 % v porovnaní s oneskorenými reakciami.
Implementujte signály E-E-A-T (odbornosť, skúsenosť, autorstvo, dôveryhodnosť) s odbornými akreditáciami, transparentným zdrojovaním, aktualizovanými časovými údajmi a redakčnými štandardmi. Používajte štruktúrované dáta JSON-LD so schémami Organization, Product, FAQPage, HowTo, Review a Article. Pridajte Q&A bloky pre rizikové zámery, vytvárajte kanonické stránky s konsolidovanými informáciami a vyvíjajte obsah vhodný na citácie, ktorý AI systémy prirodzene referencujú.
Blokovanie crawlerov znižuje vašu prítomnosť v AI generovaných odpovediach, ale chráni citlivý obsah. Vyvážená stratégia umožňuje crawlerom prístup na hlavné produktové stránky a autoritatívny obsah, zatiaľ čo blokuje internú dokumentáciu a často zneužívaný obsah. OpenAI GPTBot a PerplexityBot rešpektujú direktívy v robots.txt, čo vám dáva detailnú kontrolu nad tým, aký obsah sa dostáva do AI systémov.
Sledujte MTTD/MTTR (priemerný čas na zistenie/vyriešenie) škodlivých odpovedí podľa závažnosti, presnosť sentimentu v AI odpovediach, podiel autoritatívnych citácií v porovnaní s konkurenciou, podiel viditeľnosti v AI Overviews a Perplexity výsledkoch a efektívnosť eskalácie (percento vyriešených v rámci SLA). Tieto metriky ukazujú, či sa vaše monitorovacie a reakčné procesy zlepšujú a poskytujú ROI pre investície do bezpečnosti značky.
Chráňte reputáciu svojej značky vďaka monitorovaniu v reálnom čase naprieč Google AI Overviews, ChatGPT a Perplexity. Odhaľte halucinácie skôr, ako poškodia vašu reputáciu.
Zistite, čo je monitorovanie AI halucinácií, prečo je nevyhnutné pre bezpečnosť značky a ako detekčné metódy ako RAG, SelfCheckGPT a LLM-as-Judge pomáhajú predc...

Zistite, čo je AI halucinácia, prečo vzniká v ChatGPT, Claude a Perplexity a ako rozpoznať nepravdivé AI-generované informácie vo výsledkoch vyhľadávania....
AI halucinácia nastáva, keď LLM generujú nepravdivé alebo zavádzajúce informácie s istotou. Zistite, čo spôsobuje halucinácie, ich dopad na monitoring značky a ...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.