
Správa AI crawlerov
Zistite, ako spravovať prístup AI crawlerov k obsahu vašej webovej stránky. Pochopte rozdiel medzi trénovacími a vyhľadávacími crawlermi, implementujte pravidlá...
6 min čítania
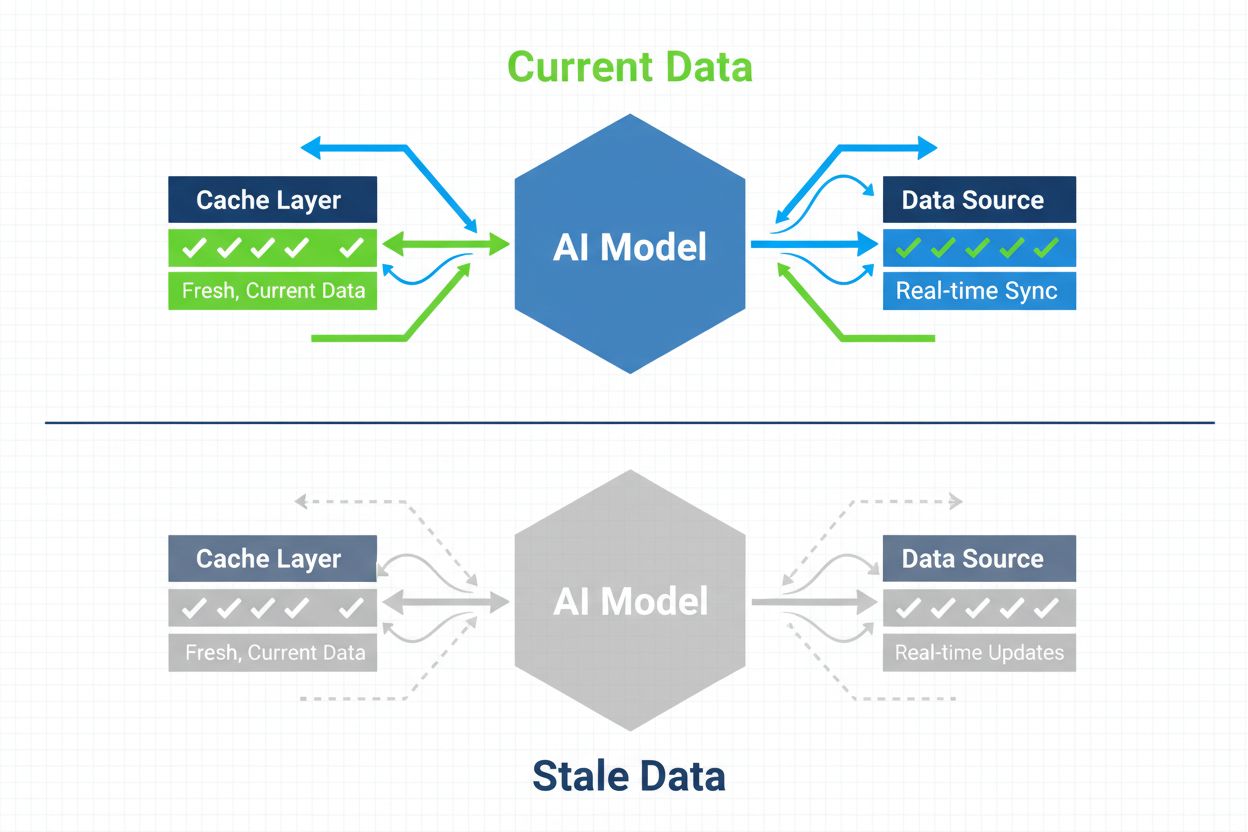
Stratégie zabezpečenia, aby AI systémy mali prístup k aktuálnemu obsahu namiesto zastaraných verzií v cache. Správa cache vyvažuje výkonové výhody cacheovania proti riziku podávania neaktuálnych informácií, využíva stratégie invalidácie a monitorovanie na udržiavanie čerstvosti dát pri súčasnom znižovaní latencie a nákladov.
Stratégie zabezpečenia, aby AI systémy mali prístup k aktuálnemu obsahu namiesto zastaraných verzií v cache. Správa cache vyvažuje výkonové výhody cacheovania proti riziku podávania neaktuálnych informácií, využíva stratégie invalidácie a monitorovanie na udržiavanie čerstvosti dát pri súčasnom znižovaní latencie a nákladov.
Správa AI cache označuje systematický prístup k ukladaniu a načítavaniu predtým vypočítaných výsledkov, výstupov modelov alebo odpovedí API, aby sa predišlo zbytočnému spracovaniu a znížila latencia v systémoch umelej inteligencie. Hlavnou výzvou je vyvážiť výkonové výhody cacheovaných dát proti riziku poskytovania zastaraných alebo neaktuálnych informácií, ktoré už neodrážajú aktuálny stav systému alebo požiadavky používateľa. Toto je obzvlášť kritické vo veľkých jazykových modeloch (LLM) a AI aplikáciách, kde sú náklady na inferenciu značné a čas odozvy priamo ovplyvňuje používateľský zážitok. Systémy správy cache musia inteligentne určovať, kedy sú cacheované výsledky stále platné a kedy je potrebné nové spracovanie, čo z nej robí základnú architektonickú otázku pri produkčnom nasadení AI.
Vplyv efektívnej správy cache na výkon AI systémov je značný a merateľný v rôznych oblastiach. Zavedenie stratégií cacheovania môže znížiť latenciu odpovedí o 80-90 % pri opakovaných dopytoch a zároveň znížiť náklady na API o 50-90 %, v závislosti od úspešnosti cache a architektúry systému. Okrem výkonnostných metrík správa cache priamo ovplyvňuje konzistentnosť presnosti a spoľahlivosť systému, pretože správne invalidované cache zabezpečia používateľom aktuálne informácie, zatiaľ čo zle spravované cache spôsobujú problémy so zastaranými dátami. Tieto zlepšenia sú čoraz dôležitejšie pri škálovaní AI systémov na milióny požiadaviek, kde kumulatívny efekt efektivity cache priamo určuje náklady na infraštruktúru a spokojnosť používateľov.
| Aspekt | Cacheované systémy | Systémy bez cache |
|---|---|---|
| Čas odozvy | O 80-90 % rýchlejšie | Základ |
| Náklady na API | 50-90 % zníženie | Plné náklady |
| Presnosť | Konzistentná | Premenná |
| Škálovateľnosť | Vysoká | Obmedzená |
Stratégie invalidácie cache určujú, ako a kedy sa cacheované dáta obnovujú alebo odstraňujú z úložiska, čo predstavuje jedno z najdôležitejších rozhodnutí pri návrhu cache architektúry. Rôzne prístupy invalidácie ponúkajú odlišné kompromisy medzi čerstvosťou dát a výkonom systému:
Voľba stratégie invalidácie zásadne závisí od požiadaviek aplikácie: systémy uprednostňujúce presnosť dát môžu akceptovať vyššiu latenciu agresívnou invalidáciou, kým výkonnostne kritické aplikácie môžu tolerovať mierne zastarané dáta pre zachovanie submilisekundových časov odozvy.
Prompt cacheovanie vo veľkých jazykových modeloch predstavuje špeciálnu aplikáciu správy cache, ktorá ukladá medzistavy modelu a sekvencie tokenov, aby sa zabránilo opätovnému spracovaniu identických alebo podobných vstupov. LLM podporujú dva hlavné prístupy cacheovania: presné cacheovanie zodpovedá identickým promptom znak po znaku, zatiaľ čo sémantické cacheovanie identifikuje funkčne ekvivalentné prompty aj napriek rôznemu zneniu. OpenAI implementuje automatické prompt cacheovanie s 50 % znížením nákladov na cacheované tokeny, pričom na aktiváciu výhod cache je potrebné minimálne 1024 tokenov v jednom prompt-e. Anthropic ponúka manuálne prompt cacheovanie s ešte agresívnejším 90 % znížením nákladov, no vyžaduje, aby vývojári explicitne spravovali cache kľúče a trvanie, s minimálnymi požiadavkami na cacheovanie 1024-2048 tokenov v závislosti od konfigurácie modelu. Trvanie cache vo veľkých jazykových modeloch sa zvyčajne pohybuje od minút po hodiny, čím sa vyvažuje úspora výpočtových zdrojov opakovaným využitím cacheovaných stavov a riziko poskytovania zastaraných výstupov modelov pri časovo citlivých aplikáciách.
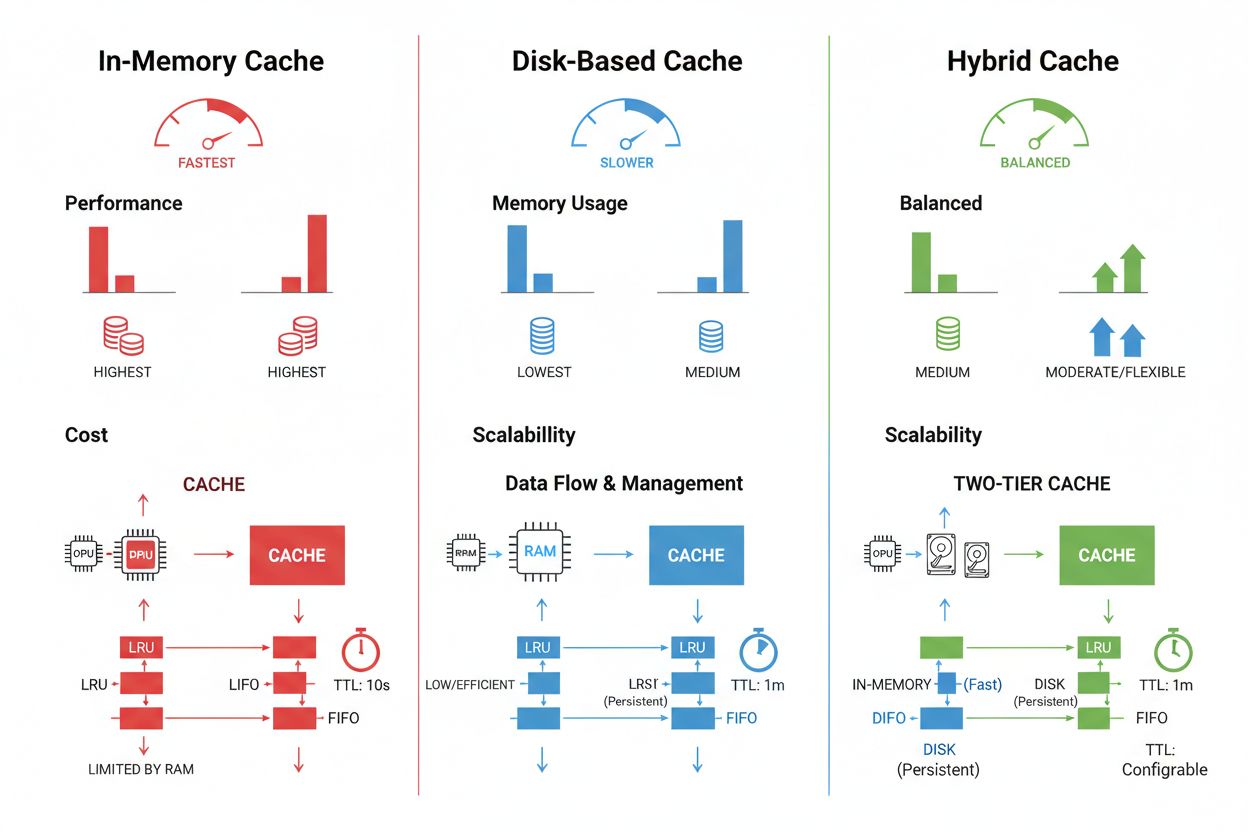
Techniky ukladania a správy cache sa významne líšia podľa požiadaviek na výkon, objem dát a infraštruktúrnych obmedzení a každá ponúka odlišné výhody a limity. In-memory cache riešenia ako Redis poskytujú prístup v mikrosekundách, ideálne pre vysokofrekvenčné dopyty, no spotrebúvajú veľa RAM a vyžadujú dôkladné riadenie pamäte. Cacheovanie na disku umožňuje väčšie datasety a pretrváva po reštarte systému, no spôsobuje latenciu v milisekundách v porovnaní s cacheovaním v pamäti. Hybridné prístupy kombinujú oba typy úložísk, pričom často používané dáta smerujú do pamäte a väčšie datasety sú uložené na disku:
| Typ úložiska | Najlepšie pre | Výkon | Spotreba pamäte |
|---|---|---|---|
| In-memory (Redis) | Časté dopyty | Najrýchlejší | Vyššia |
| Na disku | Veľké datasety | Stredný | Nižšia |
| Hybridný | Zmiešané úlohy | Vyvážený | Vyvážená |
Efektívna správa cache si vyžaduje nastavenie vhodných TTL hodnôt, ktoré odrážajú volatilitu dát—krátke TTL (minúty) pre rýchlo sa meniace dáta oproti dlhším TTL (hodiny/dni) pre stabilný obsah—v kombinácii s kontinuálnym monitorovaním úspešnosti cache, vzorov vyraďovania a využitia pamäte na identifikáciu možností optimalizácie.
Reálne AI aplikácie ukazujú transformačný potenciál aj prevádzkovú zložitosť správy cache v rôznych prípadoch použitia. Chatboti pre zákaznícky servis využívajú cacheovanie na doručovanie konzistentných odpovedí na často kladené otázky a zároveň znižujú náklady na inferenciu o 60-70 %, čo umožňuje efektívne škálovanie pre tisíce súčasných používateľov. Asistenti pre kódovanie cacheujú bežné vzory kódu a útržky dokumentácie, vďaka čomu vývojári získavajú návrhy na automatické dopĺňanie so sub-100ms latenciou aj počas špičky. Systémy na spracovanie dokumentov cacheujú embeddingy a sémantické reprezentácie často analyzovaných dokumentov, čo dramaticky zrýchľuje vyhľadávanie podobnosti a klasifikačné úlohy. Produkčná správa cache však prináša značné výzvy: zložitosť invalidácie rastie exponenciálne v distribuovaných systémoch, kde je potrebné udržať konzistenciu cache cez viacero serverov, obmedzenia zdrojov nútia k ťažkým kompromisom medzi veľkosťou cache a pokrytím, bezpečnostné riziká vznikajú pri cacheovaní citlivých dát vyžadujúcich šifrovanie a kontrolu prístupu, a koordinácia aktualizácií cache v mikroslužbách prináša potenciálne race conditions a nekonzistentnosti dát. Kľúčové sú komplexné monitorovacie riešenia, ktoré sledujú čerstvosť cache, úspešnosť, udalosti invalidácie a umožňujú udržiavať spoľahlivosť systému a včas identifikovať potrebu úpravy cache stratégií podľa meniaceho sa správania dát a používateľov.
Invalidácia cache odstráni alebo aktualizuje zastarané dáta pri zmenách, čím poskytuje okamžitú čerstvosť, ale vyžaduje udalostné spúšťače. Expirácia cache nastavuje časový limit (TTL), ako dlho dáta zostanú v cache, čo je jednoduchšie na implementáciu, ale môže podávať zastarané dáta, ak je TTL príliš dlhý. Mnoho systémov kombinuje oba prístupy pre optimálny výkon.
Efektívna správa cache môže znížiť náklady na API o 50-90 % v závislosti od úspešnosti cache a architektúry systému. Prompt cacheovanie od OpenAI poskytuje 50 % úsporu nákladov na cacheované tokeny, zatiaľ čo Anthropic ponúka až 90 % zníženie. Skutočné úspory závisia od vzorov dopytov a toho, koľko dát je možné efektívne cacheovať.
Prompt cacheovanie ukladá medzistavy modelu a sekvencie tokenov, aby sa zabránilo opätovnému spracovaniu identických alebo podobných vstupov vo veľkých jazykových modeloch. Podporuje presné cacheovanie (znak po znaku) a sémantické cacheovanie (funkčne ekvivalentné prompty s rôznym znením). To znižuje latenciu o 80 % a náklady o 50-90 % pri opakovaných dopytoch.
Hlavné stratégie sú: Expirácia na základe času (TTL) na automatické odstránenie po stanovenom čase, invalidácia na základe udalostí na okamžitú aktualizáciu pri zmene dát, sémantická invalidácia pre podobné dopyty na základe významu a hybridné prístupy kombinujúce viacero stratégií. Výber závisí od volatility dát a požiadaviek na čerstvosť.
Cacheovanie v pamäti (napr. Redis) poskytuje prístup v mikrosekundách, ideálne pre časté dopyty, ale spotrebováva veľa RAM. Cacheovanie na disku umožňuje väčšie datasety a pretrváva po reštarte, no spôsobuje latenciu v milisekundách. Hybridné prístupy kombinujú oboje, pričom často používané dáta smerujú do pamäti a väčšie datasety zostávajú na disku.
TTL je odpočítavací časovač, ktorý určuje, ako dlho zostanú cacheované dáta platné pred expiráciou. Krátke TTL (minúty) sú vhodné pre rýchlo sa meniace dáta, dlhšie TTL (hodiny/dni) pre stabilný obsah. Správna konfigurácia TTL vyvažuje čerstvosť dát s nepotrebnými obnovami cache a zaťažením servera.
Efektívna správa cache umožňuje AI systémom zvládnuť výrazne viac požiadaviek bez úmerného rozširovania infraštruktúry. Znížením výpočtovej záťaže na požiadavku pomocou cacheovania môžu systémy obslúžiť milióny užívateľov nákladovo efektívnejšie. Úspešnosť cache priamo určuje náklady na infraštruktúru a spokojnosť užívateľov v produkčných nasadeniach.
Cacheované citlivé dáta predstavujú bezpečnostné zraniteľnosti, ak nie sú správne šifrované a kontrolované prístupom. Riziká zahŕňajú neoprávnený prístup ku cacheovaným informáciám, únik dát počas invalidácie cache a neúmyselné cacheovanie dôverných údajov. Komplexné šifrovanie, kontrola prístupu a monitorovanie sú nevyhnutné na ochranu citlivých cacheovaných dát.
AmICited sleduje, ako AI systémy odkazujú na vašu značku a zabezpečuje, aby váš obsah zostal aktuálny v AI cache. Získajte prehľad o správe AI cache a čerstvosti obsahu naprieč GPT, Perplexity a Google AI Overviews.
Zistite, ako spravovať prístup AI crawlerov k obsahu vašej webovej stránky. Pochopte rozdiel medzi trénovacími a vyhľadávacími crawlermi, implementujte pravidlá...

Zistite viac o správe obsahu AI – politikách, procesoch a rámcoch, ktoré organizácie používajú na riadenie stratégie obsahu naprieč AI platformami pri zachovaní...

Zistite, ako optimalizovať tlačové správy pre viditeľnosť v AI naprieč ChatGPT, Gemini, Perplexity a ďalšími AI vyhľadávačmi. Objavte GEO najlepšie postupy, str...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.