
Skórovanie relevantnosti obsahu
Zistite, ako skórovanie relevantnosti obsahu využíva algoritmy AI na meranie toho, ako dobre obsah zodpovedá dopytom používateľov a ich zámeru. Pochopte BM25, T...
7 min čítania

Skórovanie vyhľadávania pomocou AI je proces kvantifikácie relevantnosti a kvality získaných dokumentov alebo pasáží vo vzťahu k dopytu používateľa. Využíva sofistikované algoritmy na hodnotenie sémantického významu, kontextovej vhodnosti a kvality informácií, pričom určuje, ktoré zdroje budú odovzdané jazykovým modelom na generovanie odpovedí v RAG systémoch.
Skórovanie vyhľadávania pomocou AI je proces kvantifikácie relevantnosti a kvality získaných dokumentov alebo pasáží vo vzťahu k dopytu používateľa. Využíva sofistikované algoritmy na hodnotenie sémantického významu, kontextovej vhodnosti a kvality informácií, pričom určuje, ktoré zdroje budú odovzdané jazykovým modelom na generovanie odpovedí v RAG systémoch.
Skórovanie vyhľadávania pomocou AI je proces kvantifikácie relevantnosti a kvality získaných dokumentov alebo pasáží vo vzťahu k dopytu alebo úlohe používateľa. Na rozdiel od jednoduchého párovania kľúčových slov, ktoré identifikuje iba povrchovú zhodu pojmov, skórovanie vyhľadávania využíva sofistikované algoritmy na hodnotenie sémantického významu, kontextovej vhodnosti a kvality informácií. Tento skórovací mechanizmus je základom RAG systémov (Retrieval-Augmented Generation), kde určuje, ktoré zdroje budú odovzdané jazykovým modelom na generovanie odpovede. V moderných aplikáciách LLM skórovanie vyhľadávania priamo ovplyvňuje presnosť odpovedí, znižovanie halucinácií a spokojnosť používateľov tým, že do fázy generovania prenikajú len najrelevantnejšie informácie. Kvalita skórovania vyhľadávania je preto kľúčovým prvkom celkového výkonu a spoľahlivosti systému.
Skórovanie vyhľadávania využíva viacero algoritmických prístupov, pričom každý má špecifické silné stránky pre rôzne prípady použitia. Skórovanie sémantickej podobnosti využíva embedding modely na meranie koncepčného súladu medzi dopytmi a dokumentmi vo vektorovom priestore, pričom zachytáva význam nad rámec kľúčových slov. BM25 (Best Matching 25) je pravdepodobnostná hodnotiaca funkcia, ktorá zohľadňuje frekvenciu pojmov, inverznú frekvenciu v dokumentoch a normalizáciu dĺžky dokumentu, vďaka čomu je mimoriadne účinný pri tradičnom textovom vyhľadávaní. TF-IDF (Term Frequency-Inverse Document Frequency) váži pojmy podľa ich dôležitosti v dokumentoch a naprieč kolekciami, hoci mu chýba sémantické pochopenie. Hybridné prístupy kombinujú viacero metód – napríklad spájanie skóre BM25 a sémantických skóre – aby využili lexikálne aj sémantické signály. Okrem samotných skórovacích metód poskytujú hodnotiace metriky ako Precision@k (percento relevantných výsledkov v top-k), Recall@k (percento všetkých relevantných dokumentov v top-k), NDCG (Normalized Discounted Cumulative Gain, zohľadňuje pozíciu v poradí) a MRR (Mean Reciprocal Rank) kvantitatívne merania kvality vyhľadávania. Pochopenie výhod a nevýhod každého prístupu – napríklad efektivity BM25 oproti hlbšiemu pochopeniu sémantického skórovania – je nevyhnutné pre výber vhodnej metódy pre konkrétne aplikácie.
| Skórovacia metóda | Ako funguje | Najvhodnejšie pre | Kľúčová výhoda |
|---|---|---|---|
| Sémantická podobnosť | Porovnáva embeddingy pomocou cosínovej podobnosti alebo iných metrik vzdialenosti | Koncepčný význam, synonymá, parafrázy | Zachytáva sémantické vzťahy nad rámec kľúčových slov |
| BM25 | Pravdepodobnostné radenie so zohľadnením frekvencie pojmov a dĺžky dokumentu | Presné párovanie fráz, dopyty založené na kľúčových slovách | Rýchly, efektívny, overený v praxi |
| TF-IDF | Váži pojmy podľa frekvencie v dokumente a vzácnosti v kolekcii | Tradičné vyhľadávanie informácií | Jednoduchý, interpretovateľný, nenáročný |
| Hybridné skórovanie | Kombinuje sémantické a na kľúčových slovách založené prístupy s váženou fúziou | Všeobecné vyhľadávanie, zložité dopyty | Využíva výhody viacerých metód |
| Skórovanie na báze LLM | Používa jazykové modely na hodnotenie relevantnosti pomocou vlastných promptov | Hodnotenie komplexného kontextu, doménovo špecifické úlohy | Zachytáva jemné sémantické vzťahy |
V RAG systémoch skórovanie vyhľadávania funguje na viacerých úrovniach s cieľom zabezpečiť kvalitu generovania. Systém zvyčajne skóruje jednotlivé útržky alebo pasáže v rámci dokumentov, čo umožňuje detailné hodnotenie relevantnosti namiesto posudzovania celých dokumentov ako celkov. Toto skórovanie relevantnosti na úrovni útržkov umožňuje systému vybrať len tie najpodstatnejšie segmenty informácií, čím sa znižuje šum a irelevantný kontext, ktorý by mohol jazykový model zmiasť. RAG systémy často zavádzajú skórovacie prahy alebo mechanizmy odrezania, ktoré filtrujú výsledky s nízkym skóre ešte pred fázou generovania, čím zabránia, aby nekvalitné zdroje ovplyvnili finálnu odpoveď. Kvalita získaného kontextu priamo súvisí s kvalitou generovania – vysoko skórované, relevantné pasáže vedú k presnejším, podloženým odpovediam, zatiaľ čo nekvalitné vyhľadávanie spôsobuje halucinácie a faktické chyby. Sledovanie skóre vyhľadávania poskytuje včasné signály zhoršenia systému, vďaka čomu je kľúčovou metrikou pre monitorovanie AI odpovedí a zaistenie kvality v produkčných systémoch.
Re-ranking slúži ako druhá fáza filtrovania, ktorá spresňuje počiatočné výsledky vyhľadávania a často výrazne zlepšuje presnosť radenia. Počiatočný vyhľadávač vygeneruje kandidátne výsledky s predbežným skóre a re-ranker následne aplikuje sofistikovanejšiu logiku na ich preusporiadanie alebo filtrovanie, zvyčajne s použitím výpočtovo náročnejších modelov, ktoré umožňujú hlbšiu analýzu. Reciprocal Rank Fusion (RRF) je obľúbená technika, ktorá kombinuje výsledky z viacerých vyhľadávačov priradením skóre na základe pozície výsledku a následnou fúziou týchto skóre na vytvorenie jednotného poradia, ktoré často prekonáva jednotlivé vyhľadávače. Normalizácia skóre je rozhodujúca pri kombinovaní výsledkov z rôznych metód vyhľadávania, pretože surové skóre z BM25, sémantickej podobnosti a iných prístupov sú na rôznych škálach a musia byť kalibrované na porovnateľné rozsahy. Ensemble retriever prístupy využívajú viacero vyhľadávacích stratégií súčasne, pričom re-ranking určuje finálne poradie na základe kombinovaných dôkazov. Tento viacstupňový prístup výrazne zvyšuje presnosť a robustnosť radenia v porovnaní s jednofázovým vyhľadávaním, najmä v zložitých doménach, kde rôzne metódy zachytávajú komplementárne signály relevantnosti.
Precision@k: Meria podiel relevantných dokumentov medzi top-k výsledkami; užitočné na posúdenie, či sú vrátené výsledky dôveryhodné (napr. Precision@5 = 4/5 znamená, že 80 % z top-5 výsledkov je relevantných)
Recall@k: Počíta percento všetkých relevantných dokumentov nájdených v top-k výsledkoch; dôležité na zabezpečenie komplexného pokrytia dostupných relevantných informácií
Hit Rate: Binárna metrika, ktorá indikuje, či sa aspoň jeden relevantný dokument objavil v top-k výsledkoch; vhodné na rýchlu kontrolu kvality v produkčných systémoch
NDCG (Normalized Discounted Cumulative Gain): Zohľadňuje pozíciu v poradí, pričom vyššiu hodnotu priraďuje relevantným dokumentom na vyšších miestach; pohybuje sa v rozmedzí 0-1 a je ideálna na hodnotenie kvality radenia
MRR (Mean Reciprocal Rank): Meria priemernú pozíciu prvého relevantného výsledku naprieč viacerými dopytmi; obzvlášť užitočné na hodnotenie, či najrelevantnejší dokument je vysoko v poradí
F1 skóre: Harmonický priemer presnosti a úplnosti; poskytuje vyvážené hodnotenie, ak sú falošne pozitívne a falošne negatívne prípady rovnako dôležité
MAP (Mean Average Precision): Priemeruje hodnoty presnosti na každej pozícii, kde sa našiel relevantný dokument; komplexná metrika celkovej kvality radenia naprieč viacerými dopytmi
Skórovanie relevantnosti na báze LLM využíva samotné jazykové modely ako sudcov relevantnosti dokumentov a ponúka flexibilnú alternatívu k tradičným algoritmickým prístupom. V tomto prístupe starostlivo navrhnuté promptové inštrukcie zadávajú LLM hodnotenie, či získaná pasáž odpovedá na konkrétny dopyt, pričom môže generovať buď binárne skóre (relevantné / nerelevantné), alebo číselné skóre (napr. 1-5 podľa sily relevantnosti). Tento prístup zachytáva jemné sémantické vzťahy a doménovo špecifické relevantnosti, ktoré by tradičné algoritmy nemuseli postrehnúť, najmä pri zložitých dopytoch vyžadujúcich hlboké pochopenie. Skórovanie na báze LLM však prináša výzvy ako sú výpočtové náklady (inferencia LLM je náročnejšia než porovnávanie embeddingov), možná nekonzistentnosť medzi rôznymi promptmi a modelmi, a potreba kalibrácie s ľudskými hodnoteniami, aby skóre zodpovedalo skutočnej relevantnosti. Napriek týmto obmedzeniam je skórovanie na báze LLM cenné pre hodnotenie kvality RAG systémov a vytváranie tréningových dát pre špecializované skórovacie modely, vďaka čomu je dôležitým nástrojom AI monitoringu na posudzovanie kvality odpovedí.
Efektívna implementácia skórovania vyhľadávania vyžaduje dôkladné zváženie viacerých praktických faktorov. Výber metódy závisí od požiadaviek použitia: sémantické skórovanie vyniká v zachytávaní významu, ale vyžaduje embedding modely, kým BM25 ponúka rýchlosť a efektivitu pri lexikálnom párovaní. Kľúčovým je kompromis medzi rýchlosťou a presnosťou – skórovanie na základe embeddingov poskytuje lepšie pochopenie relevantnosti, ale zvyšuje latenciu, zatiaľ čo BM25 a TF-IDF sú rýchlejšie, ale menej sémanticky sofistikované. Výpočtové náklady zahŕňajú čas inferencie modelu, požiadavky na pamäť a potreby škálovania infraštruktúry, čo je obzvlášť dôležité pre systémy s vysokou záťažou. Ladenie parametrov zahŕňa nastavovanie prahov, váh v hybridných prístupoch a cutoffov v re-rankingu na optimalizáciu výkonu pre konkrétne domény a prípady použitia. Neustále monitorovanie výkonu skórovania pomocou metrík ako NDCG a Precision@k pomáha odhaliť zhoršenie v čase, umožňuje proaktívne zlepšenie systému a zabezpečuje konzistentnú kvalitu odpovedí v produkčných RAG systémoch.
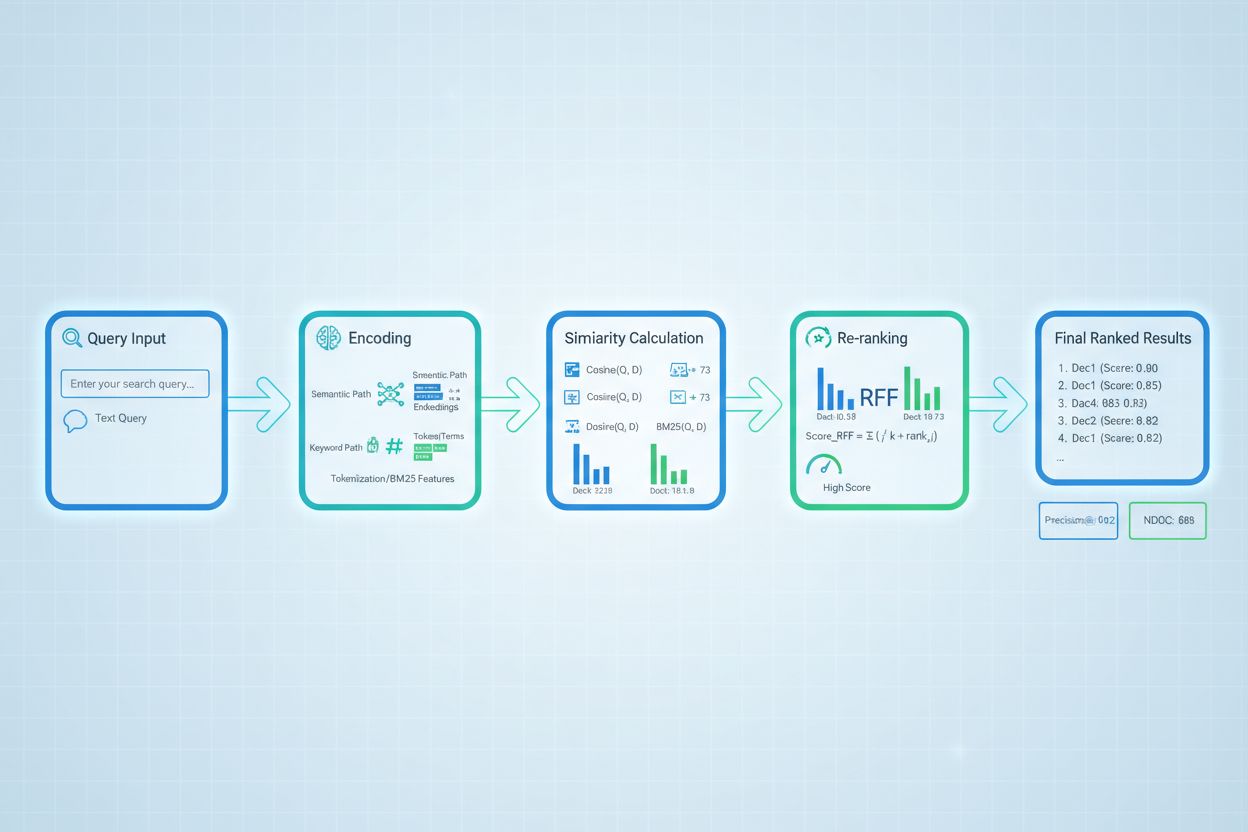
Pokročilé techniky skórovania vyhľadávania idú nad rámec základného hodnotenia relevantnosti a zachytávajú zložité kontextové vzťahy. Prepisovanie dopytov môže zlepšiť skórovanie reformulovaním používateľských dopytov do viacerých sémanticky ekvivalentných podôb, čo umožňuje vyhľadávaču nájsť relevantné dokumenty, ktoré by pri doslovnom párovaní unikli. Hypotetické embeddingy dokumentov (HyDE) generujú syntetické relevantné dokumenty z dopytov a následne využívajú tieto hypotetické dokumenty na zlepšenie skórovania vyhľadávania hľadaním reálnych dokumentov podobných idealizovanému relevantnému obsahu. Multi-query prístupy posielajú vyhľadávačom viacero variácií dopytov a agregujú ich skóre, čím zvyšujú robustnosť a pokrytie v porovnaní s jedným dopytom. Doménovo špecifické skórovacie modely trénované na označených dátach z konkrétnych odvetví alebo znalostných oblastí dosahujú vyšší výkon než univerzálne modely, čo je cenné najmä pre špecializované aplikácie ako medicínske alebo právnické AI systémy. Kontextové úpravy skóre berú do úvahy faktory ako aktuálnosť dokumentu, autorita zdroja či používateľský kontext, čo umožňuje sofistikovanejšie hodnotenie relevantnosti, ktoré presahuje čisto sémantickú podobnosť a zahŕňa reálne faktory dôležité pre produkčné AI systémy.
Skórovanie vyhľadávania prideľuje dokumentom číselné hodnoty relevantnosti na základe ich vzťahu k dopytu, zatiaľ čo radenie zoradí dokumenty podľa týchto skóre. Skórovanie je hodnotiaci proces, radenie je výsledné zoradenie. Obe sú nevyhnutné pre RAG systémy na poskytovanie presných odpovedí.
Skórovanie vyhľadávania určuje, ktoré zdroje sa dostanú k jazykovému modelu na generovanie odpovede. Kvalitné skórovanie zabezpečuje výber relevantných informácií, znižuje halucinácie a zlepšuje presnosť odpovedí. Slabé skórovanie vedie k nevhodnému kontextu a nespoľahlivým AI odpovediam.
Sémantické skórovanie využíva embeddingy na pochopenie koncepčného významu a zachytáva synonymá a príbuzné pojmy. Skórovanie na základe kľúčových slov (napríklad BM25) porovnáva presné výrazy a frázy. Sémantické skórovanie je lepšie na pochopenie zámeru, skóre podľa kľúčových slov je výborné na vyhľadanie konkrétnych informácií.
Kľúčové metriky zahŕňajú Precision@k (presnosť najvyšších výsledkov), Recall@k (pokrytie relevantných dokumentov), NDCG (kvalita radenia) a MRR (pozícia prvého relevantného výsledku). Vyberte si metriky podľa svojho použitia: Precision@k pre systémy zamerané na kvalitu, Recall@k pre komplexné pokrytie.
Áno, skórovanie na báze LLM využíva jazykové modely ako sudcov relevantnosti. Tento prístup zachytáva jemné sémantické vzťahy, ale je výpočtovo náročný. Je hodnotný na vyhodnocovanie kvality RAG a tvorbu trénovacích dát, pričom vyžaduje kalibráciu s ľudskými hodnoteniami.
Re-ranking predstavuje druhú fázu filtrovania, v ktorej sa na spresnenie výsledkov používajú sofistikovanejšie modely. Techniky ako Reciprocal Rank Fusion kombinujú viacero vyhľadávacích metód a zlepšujú presnosť a robustnosť. Re-ranking výrazne prekonáva jednofázové vyhľadávanie v zložitých oblastiach.
BM25 a TF-IDF sú rýchle a nenáročné, vhodné pre systémy v reálnom čase. Sémantické skórovanie vyžaduje inferenciu embedding modelov, čo pridáva latenciu. Skórovanie na báze LLM je najnákladnejšie. Vyberte podľa svojich latenčných požiadaviek a dostupných zdrojov.
Zvážte svoje priority: sémantické skórovanie pre úlohy zamerané na význam, BM25 pre rýchlosť a efektivitu, hybridné prístupy pre vyvážený výkon. Otestujte na vlastnej doméne s použitím metrík ako NDCG a Precision@k. Vyskúšajte viac metód a merajte ich vplyv na kvalitu konečných odpovedí.
Sledujte, ako AI systémy ako ChatGPT, Perplexity a Google AI citujú vašu značku a vyhodnocujú kvalitu ich vyhľadávania a hodnotenia zdrojov. Uistite sa, že váš obsah je AI systémami správne citovaný a hodnotený.
Zistite, ako skórovanie relevantnosti obsahu využíva algoritmy AI na meranie toho, ako dobre obsah zodpovedá dopytom používateľov a ich zámeru. Pochopte BM25, T...

Zistite, čo znamenajú skóre čitateľnosti pre viditeľnosť vo vyhľadávaní cez AI. Objavte, ako Flesch-Kincaid, štruktúra viet a formátovanie obsahu ovplyvňujú cit...
Zistite, ako AI indexovanie vyhľadávania prevádza dáta na vyhľadávateľné vektory, čím umožňuje AI systémom ako ChatGPT a Perplexity vyhľadávať a citovať relevan...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.