Ako sa odhlásiť z AI tréningu na hlavných platformách
Kompletný sprievodca odhlásením sa zo zberu dát pre AI tréning na ChatGPT, Perplexity, LinkedIn a ďalších platformách. Naučte sa krok za krokom chrániť svoje dá...
7 min čítania
Technické a právne mechanizmy, ktoré umožňujú tvorcom obsahu a držiteľom autorských práv zabrániť tomu, aby ich dielo bolo použité v dátových súboroch na trénovanie veľkých jazykových modelov. Patria sem direktívy robots.txt, právne vyhlásenia o odmietnutí a zmluvná ochrana podľa nariadení, ako je napríklad EÚ AI Act.
Technické a právne mechanizmy, ktoré umožňujú tvorcom obsahu a držiteľom autorských práv zabrániť tomu, aby ich dielo bolo použité v dátových súboroch na trénovanie veľkých jazykových modelov. Patria sem direktívy robots.txt, právne vyhlásenia o odmietnutí a zmluvná ochrana podľa nariadení, ako je napríklad EÚ AI Act.
Možnosť odmietnutia použitia na trénovanie AI označuje technické a právne mechanizmy, ktoré umožňujú tvorcom obsahu, držiteľom autorských práv a prevádzkovateľom webových stránok zabrániť tomu, aby ich diela boli použité v dátových súboroch na trénovanie veľkých jazykových modelov (LLM). Keďže AI spoločnosti získavajú obrovské množstvo dát z internetu na trénovanie čoraz sofistikovanejších modelov, možnosť kontrolovať, či sa váš obsah stane súčasťou tohto procesu, je kľúčová pre ochranu duševného vlastníctva a zachovanie kreatívnej kontroly. Tieto mechanizmy fungujú na dvoch úrovniach: technické direktívy, ktoré inštruujú AI roboty, aby váš obsah vynechali, a právne rámce, ktoré vytvárajú zmluvné práva na vylúčenie vášho diela z tréningových dát. Porozumenie obom rozmerom je dôležité pre každého, kto sa zaujíma o to, ako sa jeho obsah využíva v ére AI.

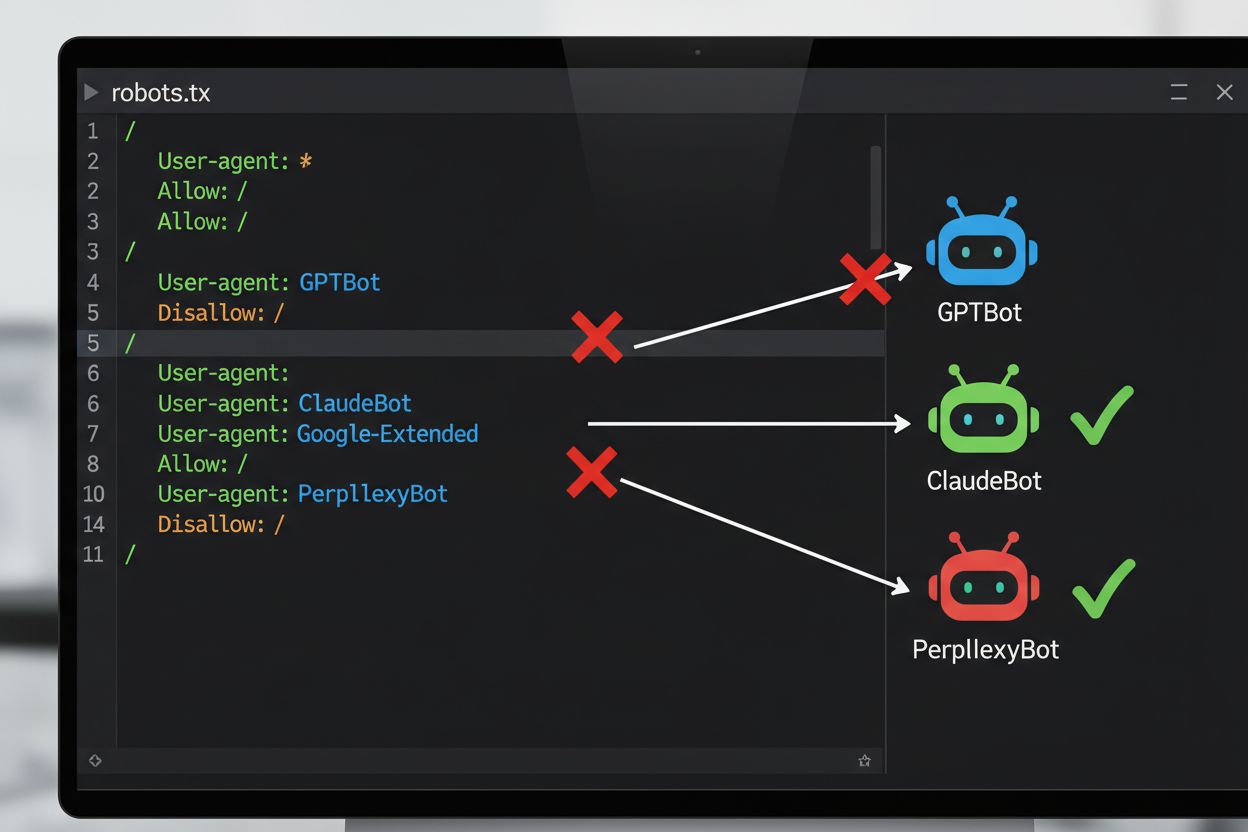
Najbežnejšou technickou metódou odmietnutia trénovania AI je robots.txt – jednoduchý textový súbor umiestnený v koreňovom adresári webu, ktorý určuje práva prehliadania pre automatizované roboty. Keď AI robot navštívi váš web, najprv skontroluje robots.txt, či má povolený prístup k vášmu obsahu. Pridaním konkrétnych disallow direktív pre určité používateľské agenty crawlerov môžete AI robotom prikázať, aby vašu stránku úplne vynechali. Každá AI spoločnosť prevádzkuje viacero crawlerov s vlastnými identifikátormi používateľských agentov – to sú v podstate „mená“, ktorými sa roboty identifikujú pri požiadavkách. Napríklad GPTBot od OpenAI sa identifikuje reťazcom používateľského agenta „GPTBot“, zatiaľ čo Claude od Anthropic používa „ClaudeBot“. Syntax je jednoduchá: zadáte meno používateľského agenta a určíte, ktoré cesty sú zakázané, napríklad „Disallow: /“, čím zablokujete celý web.
| AI spoločnosť | Názov crawlera | Token používateľského agenta | Účel |
|---|---|---|---|
| OpenAI | GPTBot | GPTBot | Zber dát na trénovanie modelu |
| OpenAI | OAI-SearchBot | OAI-SearchBot | Indexácia vyhľadávania ChatGPT |
| Anthropic | ClaudeBot | ClaudeBot | Zber citácií pre chat |
| Google-Extended | Google-Extended | Dátové zdroje pre tréning Gemini AI | |
| Perplexity | PerplexityBot | PerplexityBot | Indexácia AI vyhľadávania |
| Meta | Meta-ExternalAgent | Meta-ExternalAgent | Tréning AI modelu |
| Common Crawl | CCBot | CCBot | Otvorená dátová sada pre tréning LLM |
Právna oblasť v otázke odmietnutia trénovania AI sa výrazne posunula s prijatím EÚ AI Act, ktorý nadobudol účinnosť v roku 2024 a zahŕňa ustanovenia zo smernice o textovom a dátovom dolovaní (TDM Directive). Podľa týchto predpisov môžu vývojári AI používať obsah chránený autorským právom na účely strojového učenia iba vtedy, ak majú k obsahu zákonný prístup a držiteľ autorských práv výslovne nevyhradil právo odmietnutia jeho použitia na textové a dátové dolovanie. To vytvára formálny právny mechanizmus pre odmietnutie: držitelia autorských práv môžu k svojim dielam pridať vyhlásenie o odmietnutí, čím efektívne zabránia ich použitiu na trénovanie AI bez výslovného povolenia. EÚ AI Act znamená významný posun oproti predchádzajúcemu prístupu, ktorý preferoval rýchlosť pred právami, a stanovuje, že spoločnosti trénujúce AI musia overovať, či si držitelia práv vyhradili svoj obsah, a musia zaviesť technické a organizačné opatrenia na zabránenie neúmyselnému použitiu odmietnutých diel. Tento právny rámec platí v celej Európskej únii a ovplyvňuje prístup globálnych AI spoločností k zberu dát a trénovaniu.
Implementácia mechanizmu odmietnutia si vyžaduje technickú konfiguráciu aj právnu dokumentáciu. Po technickej stránke majitelia stránok pridajú do robots.txt disallow direktívy pre konkrétne používateľské agenty AI crawlerov, ktoré vyhovujúci roboty pri návšteve stránky rešpektujú. Po právnej stránke môžu držitelia autorských práv podať vyhlásenia o odmietnutí kolektívnym správcom a právnym organizáciám – napríklad holandská spoločnosť Pictoright a francúzska hudobná spoločnosť SACEM už zaviedli formálne postupy na rezerváciu práv proti trénovaniu AI. Mnohé weby a tvorcovia obsahu dnes zahŕňajú výslovné vyhlásenia o odmietnutí vo svojich podmienkach používania alebo metadátach, kde uvádzajú, že ich obsah nesmie byť použitý na trénovanie AI modelov. Účinnosť týchto mechanizmov však závisí od dodržiavania zo strany crawlerov: hoci veľké spoločnosti ako OpenAI, Google a Anthropic verejne deklarovali, že rešpektujú robots.txt a vyhradené odmietnutie, neexistencia centralizovaného vynucovacieho mechanizmu znamená, že overenie splnenia požiadavky si vyžaduje priebežný monitoring a overovanie.
Napriek dostupnosti mechanizmov odmietnutia existujú významné výzvy, ktoré obmedzujú ich účinnosť:
Pre organizácie, ktoré vyžadujú silnejšiu ochranu, než poskytuje samotný robots.txt, je možné implementovať viaceré ďalšie technické opatrenia. Filtrovanie používateľských agentov na úrovni servera alebo firewallu dokáže zablokovať požiadavky od konkrétnych crawlerov ešte predtým, než dorazia k vašej aplikácii, no aj toto je zraniteľné voči maskovaniu agentov. Blokovanie IP adries môže cieliť na známe rozsahy IP, ktoré publikujú hlavné AI spoločnosti, no odhodlaní scraperi to obídu cez proxy siete. Limitovanie rýchlosti a obmedzovanie požiadaviek môže spomaliť scraperov obmedzením počtu požiadaviek za sekundu a spraviť scraping ekonomicky nevýhodným, ale sofistikované roboty môžu požiadavky rozložiť na viac IP adries a obmedzenia obísť. Vyžadovanie autentifikácie a platobných brán poskytuje silnú ochranu tým, že prístup povoľuje len prihláseným používateľom alebo platiacim zákazníkom a efektívne bráni automatizovanému scrappingu. Device fingerprinting a analýza správania dokážu identifikovať roboty podľa vzorcov, ako sú využívané API prehliadača, TLS handshakes a interakcie odlišné od ľudského používateľa. Niektoré organizácie využívajú dokonca honeypoty a tarpity – skryté odkazy alebo nekonečné labyrinty liniek, ktoré sledujú len roboty, čím im plytvajú zdroje a môžu im do tréningových dát podhodiť irelevantné údaje.
Napätie medzi AI spoločnosťami a tvorcami obsahu viedlo k viacerým medializovaným sporom, ktoré ilustrujú praktické výzvy vymáhania odmietnutia. Reddit v roku 2023 výrazne zvýšil ceny API prístupu, aby účtoval AI spoločnostiam za dáta, čím de facto znemožnil neoprávneným scraperom prístup a prinútil spoločnosti ako OpenAI či Anthropic vyjednávať licenčné zmluvy. Twitter/X zaviedol ešte radikálnejšie opatrenia, dočasne zablokoval neprihlásený prístup k tweetom a obmedzil počet tweetov, ktoré môžu vidieť prihlásení používatelia, s cieľom bojovať proti scraperom. Stack Overflow pôvodne v robots.txt zablokoval GPTBot od OpenAI z dôvodu licenčných obáv pri používateľskom kóde, neskôr však blok odstránil – pravdepodobne v dôsledku rokovaní s OpenAI. Spravodajské organizácie reagovali hromadne: do roku 2023 blokovalo AI roboty vyše 50 % veľkých spravodajských webov, ako The New York Times, CNN, Reuters a The Guardian, ktorí všetci pridali GPTBot do svojich disallow zoznamov. Niektoré médiá zvolili právne kroky – The New York Times podali žalobu voči OpenAI za porušenie autorských práv, iné, ako Associated Press, uzavreli licenčné dohody a zmonetizovali svoj obsah. Tieto prípady ukazujú, že hoci mechanizmy odmietnutia existujú, ich účinnosť závisí na technickej implementácii aj ochote domáhať sa právnych nárokov pri porušení.
Implementácia mechanizmov odmietnutia je len polovica úspechu; overenie ich funkčnosti si vyžaduje priebežné monitorovanie a testovanie. Viacero nástrojov pomáha validovať vašu konfiguráciu: Google Search Console obsahuje tester robots.txt pre validáciu voči Googlebotu, zatiaľ čo Merkle’s Robots.txt Tester a nástroj od TechnicalSEO.com testujú správanie jednotlivých crawlerov podľa zvoleného používateľského agenta. Na komplexný monitoring toho, či AI spoločnosti skutočne rešpektujú vaše direktívy o odmietnutí, ponúkajú platformy ako AmICited.com špecializované sledovanie, ktoré mapuje, ako AI systémy referujú na vašu značku a obsah v GPT, Perplexity, Google AI Overviews a ďalších platformách. Tento typ monitoringu je obzvlášť cenný, pretože neodhaľuje len to, či roboty navštevujú váš web, ale aj to, či sa váš obsah objavuje v odpovediach generovaných AI – čo naznačuje, či je odmietnutie účinné v praxi. Pravidelná analýza serverových logov tiež ukáže, ktoré roboty sa pokúšajú o prístup a či rešpektujú vaše robots.txt direktívy, hoci správna interpretácia si vyžaduje technické znalosti.
Ak chcete účinne ochrániť svoj obsah pred neoprávneným trénovaním AI, zvoľte vrstvený prístup kombinujúci technické aj právne opatrenia. Najprv implementujte robots.txt direktívy pre všetky významné AI tréningové roboty (GPTBot, ClaudeBot, Google-Extended, PerplexityBot, CCBot a ďalšie) s vedomím, že to poskytuje základnú ochranu voči vyhovujúcim spoločnostiam. Následne pridajte výslovné vyhlásenia o odmietnutí do vašich podmienok používania a metadát na webe, kde jasne deklarujete, že váš obsah nesmie byť použitý na trénovanie AI modelov – čím posilníte svoju právnu pozíciu v prípade porušenia. Tretím krokom je priebežné monitorovanie konfigurácie pomocou testovacích nástrojov a analýzy logov, aby ste overili, že roboty vaše direktívy rešpektujú, a aktualizujte robots.txt aspoň raz za štvrťrok, pretože neustále pribúdajú nové AI roboty. Štvrtým krokom je zváženie ďalších technických opatrení ako filtrovanie agentov či limitovanie rýchlosti, ak na to máte technické možnosti, pričom tieto opatrenia poskytujú inkrementálnu ochranu voči sofistikovanejším scraperom. Nakoniec dôkladne dokumentujte vaše odmietnutia, pretože táto dokumentácia je kľúčová, ak budete musieť podniknúť právne kroky voči spoločnostiam, ktoré vaše direktívy ignorujú. Majte na pamäti, že odmietnutie nie je jednorazová konfigurácia, ale trvalý proces, ktorý si vyžaduje pozornosť a prispôsobovanie sa vývoju AI.
robots.txt je technický, dobrovoľný štandard, ktorý inštruuje roboty, aby vynechali váš obsah, zatiaľ čo právne odmietnutie zahŕňa podanie formálnych vyhlásení organizáciám spravujúcim autorské práva alebo zahrnutie zmluvných klauzúl do vašich podmienok používania. robots.txt je jednoduchšie implementovať, ale chýba mu vynútiteľnosť, zatiaľ čo právne odmietnutie poskytuje silnejšiu právnu ochranu, ale vyžaduje formálnejší postup.
Hlavné AI spoločnosti ako OpenAI, Google, Anthropic a Perplexity verejne uviedli, že rešpektujú direktívy robots.txt. Avšak robots.txt je dobrovoľný štandard bez vynucovacieho mechanizmu, takže nevyhovujúce roboty a nelegitímni scraperi môžu vaše direktívy úplne ignorovať.
Nie. Blokovanie AI tréningových crawlerov ako GPTBot a ClaudeBot neovplyvní vaše pozície vo vyhľadávačoch Google alebo Bing, pretože tradičné vyhľadávače používajú iné roboty (Googlebot, Bingbot), ktoré fungujú nezávisle. Týchto blokujte len v prípade, že chcete zo zoznamu vyhľadávania úplne zmiznúť.
EÚ AI Act vyžaduje, aby mali vývojári AI zákonný prístup k obsahu a musia rešpektovať vyhradenie práva odmietnutia držiteľa autorských práv. Držitelia autorských práv môžu k svojim dielam priložiť vyhlásenie o odmietnutí, čím účinne zabránia ich použitiu na trénovanie AI bez výslovného povolenia. To vytvára formálny právny mechanizmus na ochranu obsahu pred neoprávneným použitím na trénovanie.
Závisí to od konkrétneho mechanizmu. Blokovanie všetkých AI robotov zabráni zobrazovaniu vášho obsahu vo výsledkoch AI vyhľadávania, no zároveň vás úplne odstráni z AI poháňaných platforiem. Niektorí vydavatelia uprednostňujú selektívne blokovanie—povolenie crawlerov zameraných na vyhľadávanie a blokovanie tých zameraných na trénovanie—aby si udržali viditeľnosť v AI vyhľadávaní a zároveň ochránili obsah pred trénovaním modelov.
Ak AI spoločnosť ignoruje vaše direktívy o odmietnutí, máte právne možnosti prostredníctvom žaloby za porušenie autorských práv alebo porušenie zmluvy, v závislosti od jurisdikcie a konkrétnych okolností. Právne kroky sú však nákladné a zdĺhavé s neistým výsledkom. Preto je monitorovanie a dokumentácia vašich odmietnutí kľúčová.
Skontrolujte a aktualizujte svoju konfiguráciu robots.txt aspoň štvrťročne. Neustále sa objavujú nové AI roboty a spoločnosti pravidelne zavádzajú nové používateľské agenty crawlerov. Napríklad Anthropic zlúčil svoje roboty 'anthropic-ai' a 'Claude-Web' do 'ClaudeBot', čím nový robot získal dočasne neobmedzený prístup na stránky, ktoré nestihli aktualizovať pravidlá.
Odmietnutie je účinné voči dôveryhodným AI spoločnostiam, ktoré rešpektujú robots.txt a právne rámce. Menej účinné je však voči nelegitímnym robotom a scraperom, ktorí operujú v právnych šedých zónach. robots.txt zastaví približne 40-60% AI robotov, preto sa odporúča vrstvený prístup kombinujúci viaceré technické a právne opatrenia.
Sledujte, či sa váš obsah objavuje v odpovediach generovaných AI naprieč ChatGPT, Perplexity, Google AI Overviews a ďalšími AI platformami s AmICited.
Kompletný sprievodca odhlásením sa zo zberu dát pre AI tréning na ChatGPT, Perplexity, LinkedIn a ďalších platformách. Naučte sa krok za krokom chrániť svoje dá...
Zistite, akým autorskoprávnym výzvam čelia AI vyhľadávače, aké sú obmedzenia fair use, nedávne žaloby a právne dôsledky pre AI-generované odpovede a scrapovanie...
Zistite, ako licencovať obsah pre AI spoločnosti, pochopte platobné štruktúry, licenčné práva a stratégie vyjednávania na maximalizáciu príjmov z vašich kreatív...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.