
Čo je Burstiness v AI Obsahu a Ako Ovplyvňuje Detekciu
Zistite, čo znamená burstiness v AI-generovanom obsahu, ako sa líši od vzorcov ľudského písania a prečo je dôležitý pre detekciu AI a autentickosť obsahu....
7 min čítania
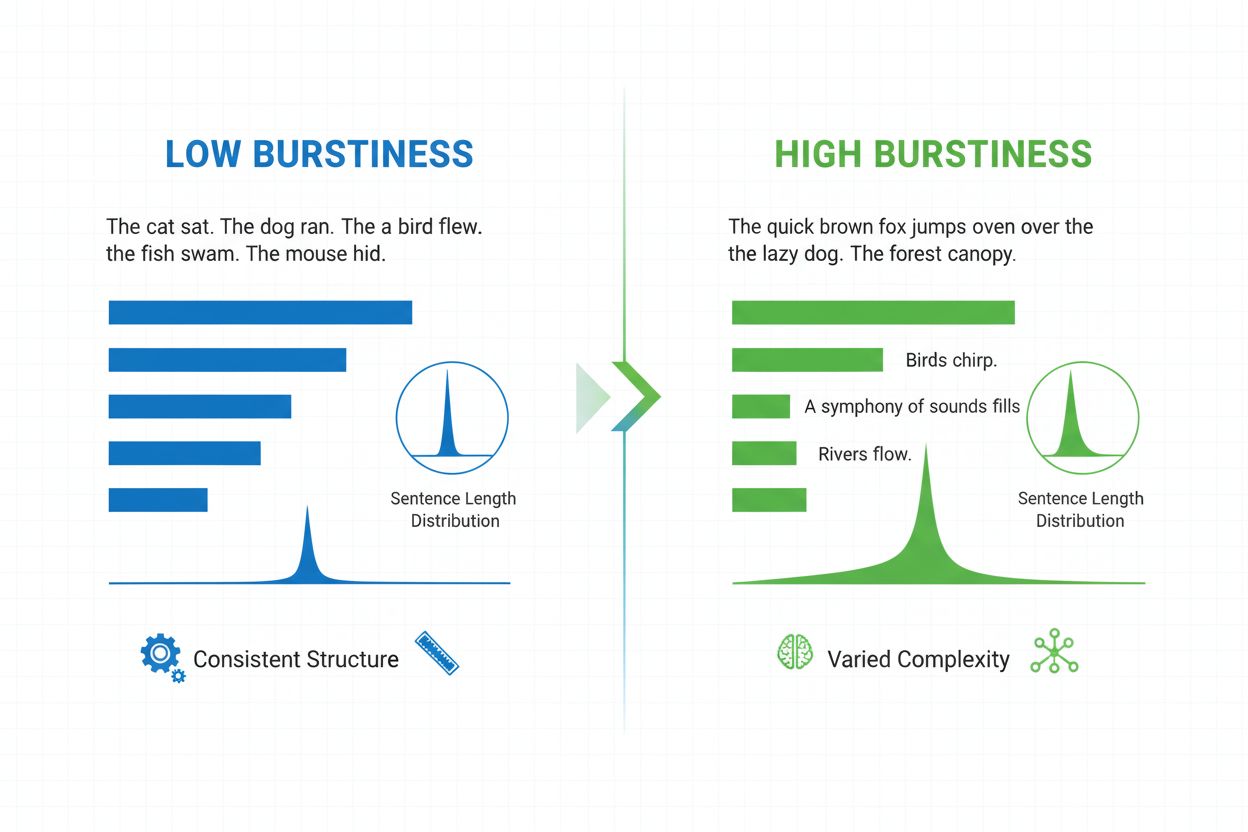
Burstiness je lingvistická metrika, ktorá meria variabilitu dĺžky, štruktúry a komplexnosti viet v celom dokumente. Kvantifikuje, do akej miery autor strieda krátke, úderné vety s dlhšími a zložitejšími, a slúži ako kľúčový indikátor pri detekcii AI-generovaného obsahu a analýze prirodzeného jazyka.
Burstiness je lingvistická metrika, ktorá meria variabilitu dĺžky, štruktúry a komplexnosti viet v celom dokumente. Kvantifikuje, do akej miery autor strieda krátke, úderné vety s dlhšími a zložitejšími, a slúži ako kľúčový indikátor pri detekcii AI-generovaného obsahu a analýze prirodzeného jazyka.
Burstiness je kvantifikovateľná lingvistická metrika, ktorá meria variabilitu a kolísanie dĺžky, štruktúry a komplexnosti viet v písanom dokumente alebo úryvku textu. Termín má pôvod v koncepte „záchvatov“ rôznych vetných vzorov—striedania krátkych, stručných viet s dlhšími, zložitejšími. V kontexte spracovania prirodzeného jazyka a detekcie AI obsahu slúži burstiness ako kľúčový indikátor toho, či bol text napísaný človekom alebo vygenerovaný umelou inteligenciou. Ľudskí autori prirodzene produkujú text s vysokou burstiness, keďže intuitívne striedajú skladbu viet podľa dôrazu, tempa a štýlového zámeru. Naopak, AI-generovaný text zvyčajne vykazuje nízku burstiness, pretože jazykové modely sú trénované na štatistických vzoroch uprednostňujúcich konzistentnosť a predvídateľnosť. Porozumenie burstiness je zásadné pre tvorcov obsahu, pedagógov, výskumníkov aj organizácie monitorujúce AI-generovaný obsah na platformách ako ChatGPT, Perplexity, Google AI Overviews či Claude.
Koncept burstiness vznikol z výskumu v oblasti výpočtovej lingvistiky a teórie informácie, kde sa vedci snažili kvantifikovať štatistické vlastnosti prirodzeného jazyka. Rané štúdie v stylometrii—štatistickej analýze písomného štýlu—identifikovali, že ľudské písanie vykazuje výrazné vzory rozmanitosti, ktoré sa zásadne líšia od strojovo generovaného textu. S rastúcou sofistikovanosťou veľkých jazykových modelov (LLM) v začiatkoch 20. rokov 21. storočia si výskumníci uvedomili, že burstiness v kombinácii s perplexitou (mierou predvídateľnosti slov) môže byť spoľahlivým indikátorom AI-generovaného obsahu. Podľa výskumov QuillBot a akademických inštitúcií približne 78 % podnikov dnes používa AI nástroje na monitoring obsahu, ktoré obsahujú aj analýzu burstiness vo svojich detekčných algoritmoch. Štúdia Stanford University z roku 2023 na TOEFL esejach preukázala, že detekčné metódy založené na burstiness majú aj významné obmedzenia—najmä čo sa týka falošných pozitív pri písaní ne-natívnych používateľov angličtiny. Tento výskum poháňa vývoj sofistikovanejších, viacvrstvových AI detekčných systémov, ktoré berú do úvahy burstiness spolu s ďalšími jazykovými znakmi, sémantickou koherenciou a kontextovou vhodnosťou.
Burstiness sa vypočítava analýzou štatistického rozdelenia dĺžok viet a štruktúrnych vzorov v texte. Metrika kvantifikuje rozptyl—teda meria, o koľko jednotlivé vety odchýľujú od priemernej dĺžky viet v dokumente. Dokument s vysokou burstiness obsahuje vety, ktoré sa výrazne líšia dĺžkou; napríklad autor môže po trojslovnej vete („Vidíš?“) nasledovať dvadsaťpäťslovnú vetu s viacerými vetnými členmi a vedľajšími vetami. Naopak, nízka burstiness indikuje, že väčšina viet sa pohybuje okolo podobnej dĺžky, typicky medzi dvanástimi a osemnástimi slovami, čo vytvára monotónny rytmus. Výpočet zahŕňa niekoľko krokov: najprv sa zmeria dĺžka každej vety v slovách; potom sa vypočíta priemerná dĺžka vety; následne sa stanoví smerodajná odchýlka, ktorá ukazuje, ako veľmi sa jednotlivé vety odchyľujú od priemeru. Vyššia smerodajná odchýlka znamená väčšiu variabilitu, a teda vyššiu burstiness. Moderné AI detektory ako Winston AI a Pangram používajú sofistikované algoritmy, ktoré nepočítajú len slová, ale analyzujú aj syntaktickú komplexnosť—štruktúrne usporiadanie viet, vetných členov a gramatických prvkov. Táto hlbšia analýza odhaľuje, že ľudskí autori používajú rôzne vetné štruktúry (jednoduché, zložené, zložité a zložené-zložité vety) v nepredvídateľných vzoroch, zatiaľ čo AI modely uprednostňujú štruktúry, ktoré sa často vyskytujú v ich tréningových dátach.
| Metrika | Burstiness | Perplexita | Zameranie merania |
|---|---|---|---|
| Definícia | Variabilita dĺžky a štruktúry viet | Predvídateľnosť jednotlivých slov | Vetná vs. slovná úroveň |
| Ľudské písanie | Vysoká (rôznorodé štruktúry) | Vysoká (nepredvídateľné slová) | Prirodzený rytmus a slovná zásoba |
| AI-generovaný text | Nízka (jednotné štruktúry) | Nízka (predvídateľné slová) | Štatistická konzistentnosť |
| Aplikácia v detekcii | Identifikuje štruktúrnu monotónnosť | Identifikuje vzory vo výbere slov | Komplementárne metódy detekcie |
| Riziko falošných pozitív | Vyššie u ESL autorov | Vyššie v technickom/akademickom písaní | Obe majú obmedzenia |
| Metóda výpočtu | Smerodajná odchýlka dĺžok viet | Analýza pravdepodobnostného rozdelenia | Rôzne matematické prístupy |
| Spoľahlivosť samostatne | Nedostatočná na definitívnu detekciu | Nedostatočná na definitívnu detekciu | Najefektívnejšia v kombinácii |
Veľké jazykové modely ako ChatGPT, Claude a Google Gemini sú trénované procesom predikcie ďalšieho tokenu, kde sa model učí predpovedať najpravdepodobnejšie nasledujúce slovo na základe predchádzajúcej sekvencie. Počas trénovania sú tieto modely explicitne optimalizované na minimalizáciu perplexity v tréningových datasetoch, čo ako vedľajší efekt vedie k nízkej burstiness. Keď model opakovane narazí na určitú vetnú štruktúru v tréningových dátach, učí sa ju reprodukovať s vysokou pravdepodobnosťou, čo má za následok konzistentné, predvídateľné dĺžky viet. Výskum Netus AI a Winston AI ukazuje, že AI modely majú výrazný stylometrický odtlačok charakterizovaný jednotnou skladbou viet, nadužívaním prechodových fráz (ako „Okrem toho“, „Preto“, „Dodatočne“) a preferenciou trpného rodu pred činným. Spoliehanie sa na pravdepodobnostné rozdelenia znamená, že modely sa prikláňajú k najčastejším vzorom v tréningových dátach namiesto skúmania celej škály možných skladieb viet. Vzniká tak paradox: čím viac dát má model na trénovanie, tým viac sa učí reprodukovať bežné vzory a tým nižšiu burstiness vykazuje. Navyše, AI modelom chýba spontánnosť a emocionálna variabilita typická pre ľudské písanie—nepíšu inak, keď sú nadšené, frustrované či chcú niečo zdôrazniť. Namiesto toho zachovávajú konzistentný štýlový základ, ktorý odráža štatistický priemer ich tréningového rozdelenia.
AI detekčné platformy zahrnuli analýzu burstiness ako základnú súčasť svojich algoritmov, hoci v rôznej miere sofistikovanosti. Skoré detekčné systémy sa silno spoliehali na burstiness a perplexitu ako hlavné metriky, no výskum odhalil ich významné limity. Podľa Pangram Labs detektory založené na perplexite a burstiness dávajú falošne pozitívne výsledky pri analýze textov z tréningových datasetov jazykových modelov—najmä Deklarácia nezávislosti je často označovaná ako AI-generovaná, pretože sa v tréningových dátach vyskytuje tak často, že model jej priraďuje jednotne nízku perplexitu. Moderné detekčné systémy ako Winston AI a Pangram dnes používajú hybridné prístupy, ktoré kombinujú analýzu burstiness s hlbokými neurónovými sieťami trénovanými na rôznorodých ľudských a AI-generovaných textoch. Tieto systémy analyzujú viac jazykových rozmerov súčasne: variabilitu vetnej štruktúry, lexikálnu rozmanitosť (bohatstvo slovnej zásoby), vzory interpunkcie, kontextovú koherenciu a sémantickú zhodu. Integrácia burstiness do širšieho rámca detekcie výrazne zvýšila presnosť—Winston AI uvádza 99,98 % presnosť v rozlišovaní AI-generovaného a ľudského obsahu práve analýzou viacerých znakov namiesto samotnej burstiness. Napriek tomu táto metrika ostáva cenná ako jedna zo zložiek komplexnej detekčnej stratégie, najmä v kombinácii s analýzou perplexity, stylometrických vzorov a sémantickej konzistencie.
Vzťah medzi burstiness a čitateľnosťou je v lingvistickom výskume dobre podložený. Skóre Flesch Reading Ease a Flesch-Kincaid Grade Level, ktoré merajú prístupnosť textu, silno korelujú s burstiness. Text s vyššou burstiness dosahuje lepšie skóre čitateľnosti, pretože variabilita dĺžky viet zabraňuje kognitívnej únave a udržiava pozornosť čitateľa. Pri konzistentnom rytme rovnako dlhých viet si mozog čitateľa zvykne na predvídateľný vzor, čo môže viesť k strate záujmu a zníženiu porozumenia. Naopak, vysoká burstiness vytvára efekt prílivu a odlivu, ktorý udržuje čitateľa mentálne zapojeného vďaka striedaniu kognitívnej záťaže—krátke vety poskytujú rýchle, ľahko stráviteľné informácie, zatiaľ čo dlhšie umožňujú rozvinúť komplexné myšlienky a nuansy. Výskum Metrics Masters ukazuje, že vysoká burstiness zvyšuje zapamätanie približne o 15–20 % v porovnaní s textom s nízkou burstiness, keďže rozmanitý rytmus efektívnejšie podporuje dlhodobé uloženie informácií. Toto platí naprieč všetkými typmi obsahu: blogy, akademické práce, marketingové texty či technická dokumentácia profitujú zo strategickej burstiness. Vzťah však nie je lineárny—nadmerná burstiness uprednostňujúca variabilitu pred jasnosťou môže text rozkúskovať a sťažiť jeho sledovanie. Optimálny prístup spočíva v zmysluplnej variabilite, kde voľba vetnej štruktúry slúži významu obsahu a komunikačnému zámeru autora, nie len zvýšeniu metriky.
Napriek širokému využívaniu v AI detekcii má detekcia na základe burstiness významné obmedzenia, ktoré by mali poznať výskumníci aj praktici. Pangram Labs publikovali rozsiahly výskum popisujúci päť hlavných nedostatkov: po prvé, texty z tréningových datasetov AI sú falošne označované za AI-generované, lebo modely sú optimalizované na minimalizáciu perplexity na týchto dátach; po druhé, hodnoty burstiness sú relatívne voči konkrétnym jazykovým modelom, takže rôzne modely vytvárajú odlišné perplexitné profily; po tretie, uzavreté komerčné modely ako ChatGPT nezverejňujú pravdepodobnosti tokenov, čo znemožňuje výpočet perplexity; po štvrté, ne-natívni hovoriaci angličtiny sú neprimerane často označovaní za AI-generovaných pre jednotnejšiu skladbu viet; a po piate, burstiness detektory sa nevedia samostatne zlepšovať s ďalšími dátami. Stanfordská štúdia 2023 na TOEFL esejach zistila, že približne 26 % ne-natívneho písania bolo nesprávne označené ako AI-generované detektormi založenými na perplexite a burstiness, pričom u natívnych textov to bolo iba 2 %. Táto zaujatosť vyvoláva vážne etické otázky v školskom prostredí, kde sa AI detekcia používa na hodnotenie prác. Navyše, šablónovitý obsah v marketingu, akademickom písaní či technickej dokumentácii prirodzene vykazuje nižšiu burstiness z dôvodu štýlových požiadaviek a štruktúrnych konvencií, čo vedie k falošným pozitívom aj v týchto oblastiach. Tieto limity urýchlili vývoj sofistikovanejších detekčných prístupov, ktoré berú burstiness ako jeden zo signálov, nie definitívny indikátor AI-generácie.
Vzory burstiness sa výrazne líšia podľa žánru a kontextu písania, čo odráža odlišné komunikačné ciele a očakávania čitateľov v každej oblasti. Akademické písanie, najmä v STEM odboroch, má tendenciu vykazovať nižšiu burstiness, keďže autori dodržiavajú prísne štýlové manuály a používajú konzistentné štruktúry pre jasnosť a presnosť. Právne dokumenty, technické špecifikácie či vedecké práce uprednostňujú konzistentnosť a predvídateľnosť pred štýlovou variabilitou, čo vedie k prirodzene nižším skóre burstiness. Naopak, umelecká literatúra, žurnalistika a marketingové texty zvyčajne vykazujú vysokú burstiness, keďže tieto žánre uprednostňujú čitateľský zážitok a emocionálny vplyv prostredníctvom variabilného tempa a rytmu. Literárna fikcia obzvlášť využíva dramatické zmeny v dĺžke viet na vytvorenie dôrazu, budovanie napätia a ovládanie naratívneho tempa. Biznisová komunikácia stojí na polceste—profesionálne e-maily a správy majú strednú burstiness, aby vyvážili jasnosť a zapojenie. Flesch-Kincaid Grade Level ukazuje, že akademické texty určené pre vysokoškolské publikum často používajú dlhšie, komplexnejšie vety, čo môže opticky znižovať burstiness; avšak variabilita v štruktúre viet a podriadených vetách stále vytvára významnú burstiness. Porozumenie týmto kontextovým variáciám je kľúčové pre AI detekčné systémy, ktoré musia zohľadniť žánrové konvencie, aby sa vyhli falošným pozitívam. Technický manuál s jednotne dlhými vetami by nemal byť označený za AI-generovaný len pre nízku burstiness—nízka burstiness tu odráža vhodné štýlové voľby, nie dôkaz strojovej generácie.
Budúcnosť analýzy burstiness v AI detekcii smeruje k sofistikovanejším, kontextovo citlivým prístupom, ktoré uznávajú limity tejto metriky a zároveň využívajú jej poznatky. Ako sa veľké jazykové modely stávajú čoraz pokročilejšími, začínajú do výstupov cielene vkladať variabilitu burstiness, čím sa detekcia založená len na tejto metrike stáva menej spoľahlivou. Výskumníci vyvíjajú adaptívne detekčné systémy, ktoré analyzujú burstiness spoločne so sémantickou koherenciou, faktickou presnosťou a kontextovou vhodnosťou. Objavujú sa AI humanizačné nástroje, ktoré zámerne zvyšujú burstiness a ďalšie ľudské charakteristiky, čo predstavuje pretrvávajúci súboj medzi detekčnými a obchádzacími technológiami. Odborníci však predpovedajú, že skutočne spoľahlivá AI detekcia bude v konečnom dôsledku závisieť na kryptografickej verifikácii a sledovaní pôvodu obsahu, nie výlučne na jazykovej analýze. Pre tvorcov obsahu a organizácie je strategické odporúčanie jasné: namiesto toho, aby sa na burstiness pozerali ako na metriku, ktorú treba obchádzať či zneužiť, by sa mali autori sústrediť na rozvoj autentického, rozmanitého štýlu, ktorý prirodzene odráža ľudskú komunikáciu. Monitorovacia platforma AmICited otvára v tomto smere nové možnosti, keď sleduje, ako sa značky objavujú v AI-generovaných odpovediach a analyzuje jazykové vlastnosti týchto výskytov. S rastúcim výskytom AI v generovaní a distribúcii obsahu je porozumenie burstiness a súvisiacim metrikám čoraz dôležitejšie na udržiavanie autenticity značky, zabezpečenie akademickej integrity a rozlíšenie medzi ľudským a strojovým textom. Vývoj smerom k viacsigánovým detekčným prístupom naznačuje, že burstiness ostane relevantný ako jeden z prvkov komplexných AI monitorovacích systémov—aj keď jeho úloha bude čoraz nuansovanejšia a závislá od kontextu.
Burstiness a perplexita sú komplementárne metriky používané pri detekcii AI. Perplexita meria, aké predvídateľné sú jednotlivé slová v texte, zatiaľ čo burstiness meria variabilitu vo vetnej štruktúre a dĺžke v celom dokumente. Ľudské písanie zvyčajne vykazuje vyššiu perplexitu (nepredvídateľnejší výber slov) aj vyššiu burstiness (väčšiu rozmanitosť vetných štruktúr), zatiaľ čo AI-generovaný text má tendenciu prejavovať nižšie hodnoty oboch metrík v dôsledku spoliehania sa na štatistické vzory z tréningových dát.
Vysoká burstiness vytvára rytmický tok, ktorý zvyšuje zapojenie čitateľa a porozumenie. Keď autori striedajú krátke, úderné vety s dlhšími a zložitejšími, udržujú záujem čitateľa a predchádzajú monotónnosti. Výskumy ukazujú, že rozmanitá vetná štruktúra zlepšuje zapamätanie a text pôsobí autentickejšie a konverzačne. Nízka burstiness, charakterizovaná rovnakou dĺžkou viet, môže text urobiť robotickým a ťažko sledovateľným, čo znižuje čitateľnosť aj zapojenie publika.
Burstiness možno zámerne zvýšiť úmyselným striedaním vetných štruktúr, avšak umelé zvyšovanie často vedie k neprirodzene znejúcemu textu, ktorý môže aktivovať iné detekčné mechanizmy. Moderné AI detektory analyzujú viacero jazykových čŕt okrem burstiness, vrátane sémantickej koherencie, kontextovej vhodnosti a stylometrických vzorov. Autentická burstiness vzniká prirodzene z ľudského písania a odráža jedinečný štýl autora, zatiaľ čo nútená variabilita zvyčajne postráda organickú kvalitu typickú pre skutočne ľudský text.
Ne-natívni hovoriaci angličtiny často vykazujú nižšie skóre burstiness, pretože ich písomné vzory odrážajú obmedzenejšiu slovnú zásobu a jednoduchšie stratégie skladania viet. Jazykoví študenti zvyčajne používajú jednotnejšie, predvídateľné vetné štruktúry počas rozvíjania jazykovej zdatnosti a vyhýbajú sa zložitým vetám a rôznorodým syntaktickým vzorom. To vytvára stylometrický profil podobný AI-generovanému textu, čo vedie k falošne pozitívnym výsledkom v AI detekčných systémoch. Výskum Stanford University z roku 2023 na TOEFL esejach potvrdil túto zaujatosť a poukázal na zásadné obmedzenie detekcie založenej na burstiness.
Veľké jazykové modely sú trénované na obrovských datasetoch, kde sa učia predpovedať ďalšie slovo na základe štatistických vzorov. Počas trénovania sú tieto modely optimalizované na minimalizáciu perplexity na tréningových dátach, čo ako vedľajší efekt spôsobuje produkciu jednotných vetných štruktúr a predvídateľných slovných sekvencií. Výsledkom je konzistentne nízka burstiness, pretože modely generujú text výberom štatisticky pravdepodobných slovných kombinácií namiesto spontánneho, rozmanitého skladania viet typického pre ľudské písanie. Spoliehanie sa na pravdepodobnostné rozdelenia vytvára homogénny štýlový podpis modelov.
AmICited sleduje, ako sa značky a domény objavujú v AI-generovaných odpovediach na platformách ako ChatGPT, Perplexity a Google AI Overviews. Porozumenie burstiness pomáha monitorovaciemu systému AmICited rozlišovať medzi autentickými ľudsky písanými citáciami a AI-generovaným obsahom, ktorý spomína vašu značku. Analýzou vzorov burstiness spolu s inými jazykovými znakmi môže AmICited poskytnúť presnejšie informácie o tom, či je vaša značka citovaná v skutočne ľudskom obsahu alebo v AI-generovaných odpovediach, čím umožňuje lepšie riadenie reputácie značky.
Autori môžu prirodzene zvýšiť burstiness vedomým striedaním spôsobu skladania viet pri zachovaní jasnosti a účelu. Medzi techniky patrí striedanie jednoduchých oznamovacích viet a zložitých viet s viacerými vetnými členmi, využívanie rétorických prostriedkov ako fragmenty či em pomlčky na zdôraznenie, a variovanie dĺžky odstavcov. Kľúčové je, aby variabilita slúžila významu obsahu a nie bola samoúčelná. Hlasné čítanie, štúdium rôznych štýlov písania a revízia s dôrazom na rytmus prirodzene rozvíja schopnosť produkovať autentický a pútavý text s vysokou burstiness.
Začnite sledovať, ako AI chatboty spomínajú vašu značku na ChatGPT, Perplexity a ďalších platformách. Získajte použiteľné poznatky na zlepšenie vašej prítomnosti v AI.
Zistite, čo znamená burstiness v AI-generovanom obsahu, ako sa líši od vzorcov ľudského písania a prečo je dôležitý pre detekciu AI a autentickosť obsahu....
Diskusia komunity o burstiness pri detekcii AI obsahu – čo to znamená, ako ovplyvňuje viditeľnosť v AI a či by sa tvorcovia obsahu mali tým zaoberať.
Zistite, čo je informačná hustota a ako zvyšuje pravdepodobnosť citácie AI. Objavte praktické techniky na optimalizáciu obsahu pre AI systémy ako ChatGPT, Perpl...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.