AI-crawlers förklarade: GPTBot, ClaudeBot och fler
Förstå hur AI-crawlers som GPTBot och ClaudeBot fungerar, deras skillnader från traditionella sökmotor-crawlers och hur du optimerar din webbplats för synlighet i AI-sök.
Publicerad den Jan 3, 2026.Senast ändrad den Jan 3, 2026 kl 3:24 am
AI-crawlers är automatiserade program utformade för att systematiskt surfa på internet och samla in data från webbplatser, specifikt för att träna och förbättra artificiella intelligensmodeller. Till skillnad från traditionella sökmotor-crawlers som Googlebot, vilka indexerar innehåll för sökresultat, samlar AI-crawlers in rå webbdata för att mata in i stora språkmodeller (LLMs) som ChatGPT, Claude och andra AI-system. Dessa bots arbetar kontinuerligt över miljontals webbplatser, laddar ner sidor, analyserar innehåll och extraherar information som hjälper AI-plattformar att förstå språkets mönster, faktainformation och olika skrivstilar. De största aktörerna inom detta område inkluderar GPTBot från OpenAI, ClaudeBot från Anthropic, Meta-ExternalAgent från Meta, Amazonbot från Amazon och PerplexityBot från Perplexity.ai, vilka alla tjänar sina respektive AI-plattformars tränings- och driftbehov. Att förstå hur dessa crawlers fungerar har blivit avgörande för webbplatsägare och innehållsskapare, eftersom AI-synlighet nu direkt påverkar hur ditt varumärke visas i AI-drivna sökresultat och rekommendationer.
AI-crawlers uppgång
Landskapet för webb-crawling har genomgått en dramatisk förändring det senaste året, där AI-crawlers upplevt explosiv tillväxt medan traditionella sök-crawlers behåller jämna mönster. Mellan maj 2024 och maj 2025 ökade den totala crawlertrafiken med 18 %, men fördelningen ändrades markant—GPTBot ökade med 305 % i råa förfrågningar, medan andra crawlers som ClaudeBot minskade med 46 % och Bytespider rasade med 85 %. Denna omfördelning speglar den intensifierade konkurrensen mellan AI-företag om att säkra träningsdata och förbättra sina modeller. Här är en detaljerad översikt över de största crawlers och deras nuvarande marknadsposition:
Crawler-namn
Företag
Månatliga förfrågningar
Tillväxt YoY
Huvudsakligt syfte
Googlebot
Google
4,5 miljarder
96%
Sökindexering & AI Overviews
GPTBot
OpenAI
569 miljoner
305%
ChatGPT-modellträning & sök
Claude
Anthropic
370 miljoner
-46%
Claude-modellträning & sök
Bingbot
Microsoft
~450 miljoner
2%
Sökindexering
PerplexityBot
Perplexity.ai
24,4 miljoner
157 490%
AI-sökindexering
Meta-ExternalAgent
Meta
~380 miljoner
Ny aktör
Meta AI-träning
Amazonbot
Amazon
~210 miljoner
-35%
Sök & AI-applikationer
Data visar att även om Googlebot behåller dominansen med 4,5 miljarder månatliga förfrågningar, står AI-crawlers tillsammans för cirka 28 % av Googlebots volym, vilket gör dem till en betydande kraft i webbtrafiken. Den explosiva tillväxten för PerplexityBot (157 490 % ökning) visar hur snabbt nya AI-plattformar skalar upp sina crawling-operationer, medan nedgången för vissa etablerade AI-crawlers antyder marknadskonsolidering kring de mest framgångsrika AI-plattformarna.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
GPTBot är OpenAIs webb-crawler, särskilt utformad för att samla in data för att träna och förbättra ChatGPT och andra OpenAI-modeller. Lanserad som en relativt liten aktör med endast 5 % marknadsandel i maj 2024, har GPTBot blivit den dominerande AI-crawlern och står för 30 % av all AI-crawlertrafik i maj 2025—en anmärkningsvärd ökning med 305 % i råa förfrågningar. Denna explosiva tillväxt speglar OpenAIs aggressiva strategi för att säkerställa att ChatGPT har tillgång till färskt, varierat webbinnehåll för både modellträning och realtids-sökfunktionalitet via ChatGPT Search. GPTBot arbetar med ett särskilt crawlmönster och prioriterar HTML-innehåll (57,70 % av hämtningarna) samtidigt som den också laddar ner JavaScript-filer och bilder, även om den inte kör JavaScript för att rendera dynamiskt innehåll. Crawlerns beteende visar att den ofta stöter på 404-fel (34,82 % av förfrågningarna), vilket antyder att den kan följa föråldrade länkar eller försöka få tillgång till resurser som inte längre finns. För webbplatsägare innebär GPTBots dominans att det är avgörande att säkerställa att ditt innehåll är tillgängligt för denna crawler för synlighet i ChatGPTs sökfunktioner och för möjlig inkludering i framtida modellträningsversioner.
ClaudeBot och Anthropics strategi
ClaudeBot, utvecklad av Anthropic, fungerar som huvudcrawler för att träna och uppdatera Claude AI-assistenten samt stödja Claudes sök- och grundfunktioner. Tidigare den näst största AI-crawlern med 27 % marknadsandel i maj 2024, har ClaudeBot upplevt en anmärkningsvärd nedgång till 21 % i maj 2025, med råa förfrågningar som minskat med 46 % år över år. Denna nedgång behöver inte nödvändigtvis indikera några problem med Anthropics strategi, utan speglar snarare den bredare marknadsförskjutningen mot OpenAIs dominans och framväxten av nya konkurrenter som Meta-ExternalAgent. ClaudeBot uppvisar liknande beteende som GPTBot, prioriterar HTML-innehåll men ägnar en högre andel av förfrågningarna åt bilder (35,17 % av hämtningarna), vilket antyder att Anthropic kan träna Claude för att bättre förstå visuellt innehåll tillsammans med text. Precis som andra AI-crawlers renderar inte ClaudeBot JavaScript, vilket innebär att den endast ser sidornas råa HTML utan dynamiskt laddat innehåll. För innehållsskapare är det fortsatt viktigt att synas för ClaudeBot för att säkerställa att Claude kan komma åt och citera ditt innehåll, särskilt när Anthropic fortsätter att utveckla Claudes sök- och resonemangsförmåga.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Andra stora AI-crawlers
Utöver GPTBot och ClaudeBot finns flera andra betydande AI-crawlers som aktivt samlar in webbdata för sina respektive plattformar:
Meta-ExternalAgent (Meta): Metas crawler gjorde en dramatisk entré i topprankningen och tog 19 % av marknaden i maj 2025 som ny aktör. Denna bot samlar in data för Metas AI-initiativ, inklusive eventuell träning för Meta AI och integration med Instagrams och Facebooks AI-funktioner. Metas snabba uppgång antyder att företaget satsar stort på AI-drivet sök och rekommendationer.
PerplexityBot (Perplexity.ai): Trots endast 0,2 % marknadsandel hade PerplexityBot den mest explosiva tillväxttakten på 157 490 % år över år. Detta speglar Perplexitys snabba expansion som AI-svarsmotor som är beroende av realtidswebbsök för att grunda sina svar. För webbplatser innebär besök av PerplexityBot direkta möjligheter att bli citerad i Perplexitys AI-genererade svar.
Amazonbot (Amazon): Amazons crawler minskade från 21 % till 11 % marknadsandel, med förfrågningar som sjönk 35 % år över år. Amazonbot samlar in data för Amazons sökfunktion och AI-applikationer, även om dess minskande andel antyder att Amazon kan ändra sin AI-strategi eller konsolidera sina crawling-operationer.
Applebot (Apple): Apples crawler upplevde en minskning med 26 % i förfrågningar, från 1,9 % till 1,2 % marknadsandel. Applebot tjänar främst Siri och Spotlight-sök, men kan också stödja Apples framväxande AI-initiativ. Till skillnad från de flesta andra AI-crawlers kan Applebot rendera JavaScript, vilket ger den liknande möjligheter som Googlebot.
Hur AI-crawlers skiljer sig från Googlebot
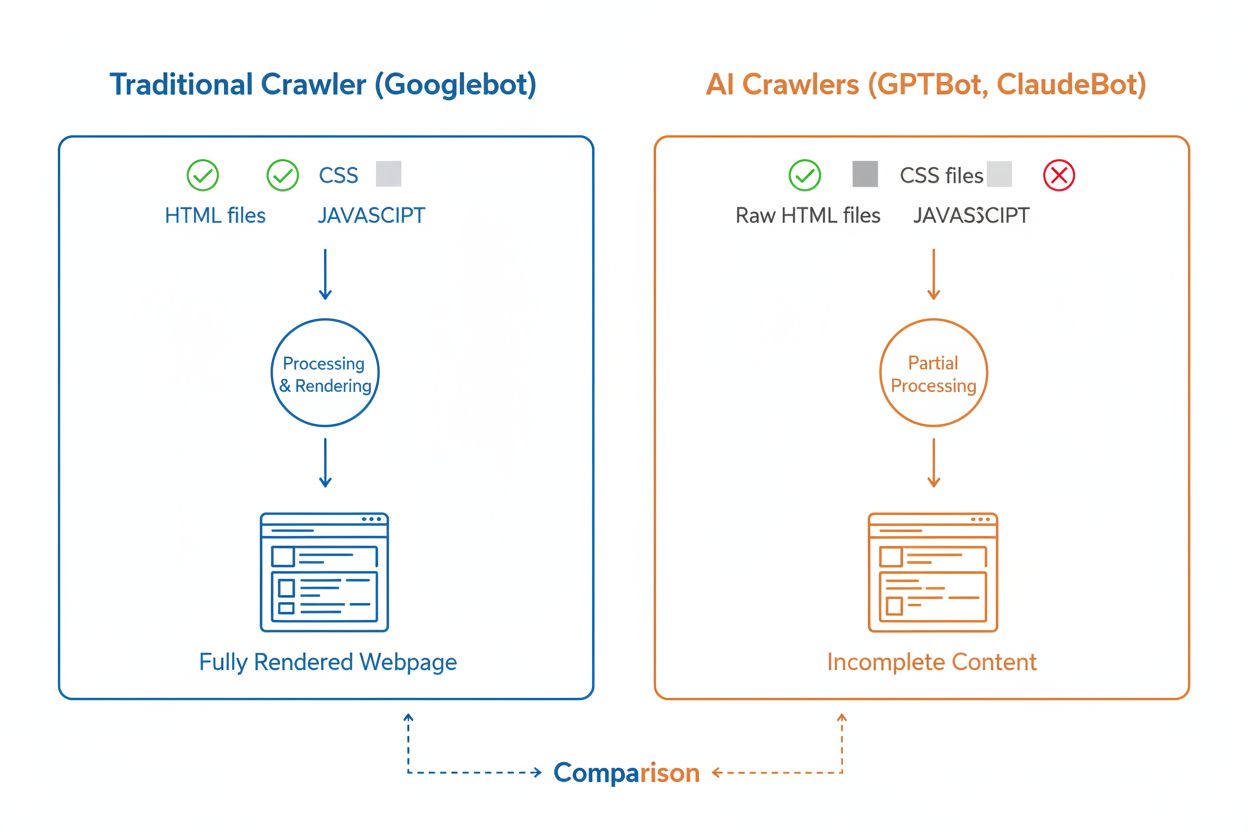
Även om AI-crawlers och traditionella sökcrawlers som Googlebot båda systematiskt surfar på webben, skiljer sig deras tekniska förmågor och beteenden avsevärt på sätt som direkt påverkar hur ditt innehåll upptäcks och förstås. Den mest avgörande skillnaden är JavaScript-rendering: Googlebot kan köra JavaScript efter att ha laddat ner en sida och kan därmed se dynamiskt laddat innehåll, medan de flesta AI-crawlers (GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider) bara läser den råa HTML-koden och ignorerar allt som är beroende av JavaScript. Det betyder att om din webbplats är beroende av client-side rendering för att visa viktig information, ser AI-crawlers en ofullständig version av dina sidor. Dessutom visar AI-crawlers mindre förutsägbara crawlmönster jämfört med Googlebots systematiska tillvägagångssätt—de spenderar 34,82 % av förfrågningarna på 404-sidor och 14,36 % på att följa omdirigeringar, jämfört med Googlebots mer effektiva 8,22 % på 404:or och 1,49 % på omdirigeringar. Crawl-frekvensen skiljer sig också: medan Googlebot besöker sidor baserat på ett sofistikerat crawlbudgetsystem, verkar AI-crawlers crawla oftare men mindre systematiskt, och viss forskning visar att AI-crawlers besöker sidor över 100 gånger oftare än Google i vissa fall. Dessa skillnader innebär att traditionella SEO-optimeringsstrategier inte nödvändigtvis täcker AI-crawlbarhet, vilket kräver ett särskilt tillvägagångssätt med fokus på server-side rendering och rena URL-strukturer.
Begränsningar i JavaScript-rendering
En av de mest betydande tekniska utmaningarna för AI-crawlers är deras oförmåga att rendera JavaScript, en begränsning som kommer av de datorkraftskostnader som skulle krävas för att köra JavaScript i den omfattning som krävs för träning av stora språkmodeller. När en crawler laddar ner din webbsida får den det initiala HTML-svaret, men allt innehåll som laddas eller ändras av JavaScript—som produktdetaljer, prisinformation, användarrecensioner eller dynamiska navigationsmenyer—förblir osynligt för AI-crawlers. Detta skapar ett kritiskt problem för moderna webbplatser som är starkt beroende av client-side rendering-ramverk som React, Vue eller Angular utan server-side rendering (SSR) eller statisk sidgenerering (SSG). Till exempel kommer en e-handelssida som laddar produktinformation via JavaScript att framstå för AI-crawlers som en tom sida utan produktinformation, vilket gör det omöjligt för AI-system att förstå eller citera det innehållet. Lösningen är att säkerställa att allt viktigt innehåll serveras i det initiala HTML-svaret genom server-side rendering, som genererar komplett HTML på servern innan det skickas till webbläsaren. Detta tillvägagångssätt säkerställer att både mänskliga besökare och AI-crawlers får samma innehållsrika upplevelse. Webbplatser som använder moderna ramverk som Next.js med SSR, statiska sidgeneratorer som Hugo eller Gatsby, eller traditionella server-renderade plattformar som WordPress är naturligt AI-crawler-vänliga, medan de som bygger helt på client-side rendering står inför stora utmaningar med synlighet i AI-sök.
Crawl-frekvens och mönster
AI-crawlers uppvisar särskilda crawlfrekvensmönster som skiljer sig markant från Googlebots beteende, med viktiga följder för hur snabbt ditt innehåll plockas upp av AI-system. Forskning visar att AI-crawlers som ChatGPT och Perplexity ofta besöker sidor oftare än Google på kort sikt efter publicering—i vissa fall besöker de sidor 8 gånger oftare än Googlebot under de första dagarna. Denna snabba initiala crawling antyder att AI-plattformar prioriterar att snabbt upptäcka och indexera nytt innehåll, troligen för att säkerställa att deras modeller och sökfunktioner har tillgång till den senaste informationen. Men denna aggressiva första crawling följs av ett mönster där AI-crawlers kanske inte återkommer om innehållet inte uppfyller kvalitetskraven, vilket gör det första intrycket avgörande. Till skillnad från Googlebot, som har ett sofistikerat crawlbudgetsystem och återvänder till sidor regelbundet utifrån uppdateringsfrekvens och betydelse, verkar AI-crawlers göra en bedömning om innehållet är värt att återvända till. Det betyder att om en AI-crawler besöker din sida och hittar tunt innehåll, tekniska fel eller dåliga användarsignaler, kan det ta betydligt längre tid innan den återkommer—om den ens återkommer. Slutsatsen för innehållsskapare är tydlig: du kan inte räkna med en andra chans att optimera innehåll för AI-crawlers på samma sätt som för traditionella sökmotorer, vilket gör kvalitetskontroll före publicering avgörande.
robots.txt och kontroll över AI-crawlers
Webbplatsägare kan använda robots.txt-filen för att kommunicera sina preferenser kring AI-crawleråtkomst, även om effektiviteten och efterlevnaden av dessa regler varierar kraftigt mellan olika crawlers. Enligt färska data har cirka 14 % av de 10 000 största webbplatserna implementerat särskilda tillåt- eller nekringsregler riktade mot AI-bots i sina robots.txt-filer. GPTBot är den mest frekvent blockerade crawlern, med 312 domäner (250 helt, 62 delvis) som uttryckligen nekar den, även om det också är den mest uttryckligt tillåtna crawlern med 61 domäner som ger tillgång. Andra vanliga blockerade crawlers inkluderar CCBot (Common Crawl) och Google-Extended (Googles AI-träningstoken). Utmaningen med robots.txt är att efterlevnad är frivillig—crawlers följer dessa regler endast om deras operatörer väljer att implementera den funktionen, och vissa nyare eller mindre transparenta crawlers kanske inte respekterar robots.txt-direktiv alls. Dessutom motsvarar robots.txt-tokens som “Google-Extended” inte direkt user-agent-strängar i HTTP-förfrågningar; istället signalerar de syftet med crawling, vilket innebär att du inte alltid kan verifiera efterlevnad via serverloggar. För starkare kontroll vänder sig allt fler webbplatsägare till brandväggsregler och Web Application Firewalls (WAFs) som aktivt kan blockera specifika crawler-user-agents, vilket ger mer tillförlitlig kontroll än robots.txt ensam. Denna övergång till aktiva blockeringsmekanismer speglar ökande oro kring innehållsrättigheter och önskan om mer verkställbara kontroller över AI-crawleråtkomst.
Övervakning av AI-crawler-aktivitet
Att spåra AI-crawlers aktivitet på din webbplats är avgörande för att förstå din synlighet i AI-sök, men det innebär unika utmaningar jämfört med att övervaka traditionella sökmotor-crawlers. Traditionella analysverktyg som Google Analytics bygger på JavaScript-spårning, vilket AI-crawlers inte kör, vilket innebär att dessa verktyg inte ger någon synlighet av AI-bot-besök. På samma sätt fungerar inte pixelbaserad spårning eftersom de flesta AI-crawlers bara bearbetar text och ignorerar bilder. Det enda tillförlitliga sättet att spåra AI-crawler-aktivitet är genom server-side-övervakning—analys av HTTP-förfrågningshuvuden och serverloggar för att identifiera crawler-user-agents innan sidan skickas. Detta kräver antingen manuell logganalys eller specialiserade verktyg som är utformade specifikt för att identifiera och spåra AI-crawlertrafik. Övervakning i realtid är särskilt kritiskt eftersom AI-crawlers arbetar på oförutsägbara scheman och kanske inte återkommer till sidor om de stöter på problem, vilket innebär att en veckovis eller månadsvis crawlgranskning kan missa viktiga problem. Om en AI-crawler besöker din sida och hittar ett tekniskt fel eller dålig innehållskvalitet, kanske du inte får en ny chans att göra ett gott intryck. Genom att implementera 24/7-övervakningslösningar som larmar dig omedelbart när AI-crawlers stöter på problem—såsom 404-fel, långsam sidladdning eller saknade schema-markeringar—kan du åtgärda problem innan de påverkar din synlighet i AI-sök. Detta realtidsfokuserade tillvägagångssätt innebär ett grundläggande skifte från traditionella SEO-övervakningsrutiner och speglar AI-crawlers snabba och oförutsägbara beteende.
Optimera för AI-crawlers
Att optimera din webbplats för AI-crawlers kräver ett särskilt tillvägagångssätt jämfört med traditionell SEO, med fokus på tekniska faktorer som direkt påverkar hur AI-system kan komma åt och förstå ditt innehåll. Den första prioriteringen är server-side rendering: se till att allt viktigt innehåll—rubriker, brödtext, metadata, strukturerad data—finns med i det initiala HTML-svaret istället för att laddas dynamiskt via JavaScript. Detta gäller för startsidan, viktiga landningssidor och allt innehåll du vill att AI-system ska citera eller referera till. För det andra, implementera strukturerad datamarkering (Schema.org) på dina sidor med stor påverkan, inklusive artikel-schema för blogginlägg, produkt-schema för e-handel och författar-schema för att etablera expertis och auktoritet. AI-crawlers använder strukturerad data för att snabbt förstå innehållshierarki och sammanhang, vilket gör det betydligt enklare för dem att tolka och citera din information. För det tredje, upprätthåll hög innehållskvalitet på alla sidor, eftersom AI-crawlers verkar fatta snabba beslut om innehållet är värt att indexera och citera. Det innebär att säkerställa att ditt innehåll är originellt, välundersökt, faktamässigt korrekt och ger genuellt värde för läsaren. För det fjärde, övervaka och optimera Core Web Vitals och övergripande sidprestanda, eftersom långsamma sidor signalerar dålig användarupplevelse och kan avskräcka AI-crawlers från att återvända. Slutligen, håll din URL-struktur ren och konsekvent, underhåll en uppdaterad XML-sitemap och se till att din robots.txt är korrekt konfigurerad för att guida crawlers till ditt viktigaste innehåll. Dessa tekniska optimeringar skapar en grund som gör ditt innehåll upptäckbart, förståeligt och citerbart av AI-system.
AI-crawlers framtid
Landskapet för AI-crawlers kommer att fortsätta utvecklas snabbt när konkurrensen intensifieras mellan AI-företag och teknologin mognar. En tydlig trend är konsolideringen av marknadsandelar kring de mest framgångsrika plattformarna—OpenAIs GPTBot har blivit den dominerande kraften, medan nya aktörer som Meta-ExternalAgent snabbt skalar upp, vilket antyder att marknaden sannolikt kommer att stabiliseras kring ett fåtal större aktörer. I takt med att AI-crawlers mognar kan vi förvänta oss förbättringar i deras tekniska förmågor, särskilt kring JavaScript-rendering och effektivare crawlmönster som minskar slöseri med förfrågningar på 404-sidor och föråldrat innehåll. Branschen rör sig också mot mer standardiserade kommunikationsprotokoll, såsom den framväxande llms.txt-standarden, som låter webbplatser explicit kommunicera sin innehållsstruktur och crawling-preferenser till AI-system. Dessutom blir mekanismerna för att kontrollera AI-crawler-åtkomst allt mer sofistikerade, med plattformar som Cloudflare som nu erbjuder automatisk blockering av AI-träningsbots som standard, vilket ger webbplatsägare mer detaljerad kontroll över sitt innehåll. För innehållsskapare och webbplatsägare innebär det att ligga steget före dessa förändringar att kontinuerligt övervaka AI-crawleraktivitet, hålla den tekniska infrastrukturen optimerad för AI-tillgänglighet och anpassa sin innehållsstrategi till verkligheten att AI-system nu utgör en betydande del av din webbplats trafik och en kritisk kanal för varumärkessynlighet. Framtiden tillhör dem som förstår och optimerar för detta nya crawler-ekosystem.
Vanliga frågor
Vad är en AI-crawler och hur skiljer den sig från en sökmotor-crawler?
AI-crawlers är automatiserade program som samlar in webbdata specifikt för att träna och förbättra artificiella intelligensmodeller som ChatGPT och Claude. Till skillnad från traditionella sökmotor-crawlers som Googlebot, som indexerar innehåll för sökresultat, samlar AI-crawlers in rå webbdata för att mata in i stora språkmodeller. Båda typerna av crawlers surfar systematiskt på internet, men de har olika syften och tekniska möjligheter.
Varför behöver AI-crawlers tillgång till min webbplats?
AI-crawlers får tillgång till din webbplats för att samla in data till träning av AI-modeller, förbättra sökfunktioner och använda aktuell information för att grunda AI-svar. När AI-system som ChatGPT eller Perplexity besvarar användarfrågor behöver de ofta hämta ditt innehåll i realtid för att tillhandahålla korrekt, citerad information. Genom att tillåta AI-crawlers att komma åt din sida ökar chanserna att ditt varumärke nämns och citeras i AI-genererade svar.
Kan jag blockera AI-crawlers från att komma åt min webbplats?
Ja, du kan använda din robots.txt-fil för att neka specifika AI-crawlers genom att ange deras user-agent-namn. Dock är efterlevnaden av robots.txt frivillig och inte alla crawlers följer dessa regler. För starkare kontroll kan du använda brandväggsregler och Web Application Firewalls (WAFs) för att aktivt blockera specifika crawler-user-agents. Detta ger dig mer tillförlitlig kontroll över vilka AI-crawlers som kan komma åt ditt innehåll.
Renderar AI-crawlers JavaScript på samma sätt som Google gör?
Nej, de flesta AI-crawlers (GPTBot, ClaudeBot, Meta-ExternalAgent) kör inte JavaScript. De läser bara den råa HTML-koden på dina sidor, vilket innebär att allt innehåll som laddas dynamiskt via JavaScript är osynligt för dem. Därför är server-side rendering avgörande för AI-crawlbarhet. Om din sida bygger på client-side rendering kommer AI-crawlers se en ofullständig version av dina sidor.
Hur ofta besöker AI-crawlers webbplatser?
AI-crawlers besöker webbplatser oftare än traditionella sökmotorer under de första dagarna efter att innehåll publicerats. Forskning visar att de kan besöka sidor 8–100 gånger oftare än Google inom de första dagarna. Dock, om innehållet inte uppfyller kvalitetskraven, kanske de inte återkommer. Detta gör första intrycket avgörande—du kanske inte får en andra chans att optimera innehåll för AI-crawlers.
Vad är det bästa sättet att optimera min webbplats för AI-crawlers?
De viktigaste optimeringarna är: (1) Använd server-side rendering för att säkerställa att viktigt innehåll finns i den initiala HTML-koden, (2) Lägg till strukturerad datamarkering (Schema) för att hjälpa AI förstå ditt innehåll, (3) Upprätthåll hög innehållskvalitet och aktualitet, (4) Övervaka Core Web Vitals för god användarupplevelse och (5) Håll din URL-struktur ren samt underhåll en uppdaterad sitemap. Dessa tekniska optimeringar skapar en grund som gör ditt innehåll upptäckbart och citerbart av AI-system.
Vilken AI-crawler är viktigast för min webbplats?
GPTBot från OpenAI är för närvarande den dominerande AI-crawlern och står för 30 % av all AI-crawlertrafik och växer med 305 % år över år. Du bör dock optimera för alla större crawlers inklusive ClaudeBot (Anthropic), Meta-ExternalAgent (Meta), PerplexityBot (Perplexity) och andra. Olika AI-plattformar har olika användarbaser, så synlighet över flera crawlers maximerar ditt varumärkes närvaro i AI-sök.
Hur kan jag spåra AI-crawlers aktivitet på min webbplats?
Traditionella analysverktyg som Google Analytics fångar inte AI-crawlers aktivitet eftersom de bygger på JavaScript-spårning. Istället behöver du server-side-övervakning som analyserar HTTP-förfrågningshuvuden och serverloggar för att identifiera crawler-user-agents. Specialiserade verktyg för spårning av AI-crawlers ger insyn i realtid om vilka sidor som crawlas, hur ofta och om crawlers stöter på tekniska problem.
Övervaka ditt varumärkes synlighet i AI-sök
Spåra hur AI-crawlers som GPTBot och ClaudeBot får tillgång till och citerar ditt innehåll. Få insikter i realtid om din synlighet i AI-sök med AmICited.
Hur du Tillåter AI-botar att Crawla din Webbplats: Komplett robots.txt & llms.txt-guide
Lär dig hur du tillåter AI-botar som GPTBot, PerplexityBot och ClaudeBot att crawla din webbplats. Konfigurera robots.txt, ställ in llms.txt och optimera för AI...
Vilka AI-crawlers bör jag tillåta? Komplett guide för 2025
Lär dig vilka AI-crawlers du ska tillåta eller blockera i din robots.txt. Omfattande guide som täcker GPTBot, ClaudeBot, PerplexityBot och 25+ AI-crawlers med k...
Komplett lista över AI-crawlers 2025: Alla botar du bör känna till
Omfattande guide till AI-crawlers 2025. Identifiera GPTBot, ClaudeBot, PerplexityBot och 20+ andra AI-botar. Lär dig blockera, tillåta eller övervaka crawlers m...
12 min läsning
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.