Hur du avanmäler dig från AI-träning på stora plattformar
Komplett guide för att avanmäla dig från AI-träning och datainsamling på ChatGPT, Perplexity, LinkedIn och andra plattformar. Lär dig steg-för-steg hur du skydd...
8 min läsning

Upptäck var ChatGPT får sin träningsdata, hur den citerar källor, kunskapsgränser och varför övervakning av AI-citeringar är viktigt för ditt varumärke.
ChatGPT:s kunskapsbas byggs från en mångsidig samling av offentligt tillgänglig internetdata, kombinerad med licensierade datamängder och förbättringar genom mänsklig feedback. Modellen tränades på tre huvudsakliga källor: offentligt tillgänglig internetdata (webbplatser, artiklar och onlineinnehåll), licensierade datamängder (inklusive böcker och akademiska publikationer) och mänsklig feedback från tränare som hjälpte till att förfina svaren. Denna träningsdata omfattar ett oerhört brett spektrum av källor, inklusive nyhetssajter, akademiska tidskrifter, böcker, teknisk dokumentation, forum som Reddit och Stack Overflow, Wikipedia-artiklar och otaliga andra offentligt tillgängliga webbsidor. Den enorma mängden och variationen av dessa källor—över flera språk, ämnesområden och perspektiv—skapar en omfattande kunskapsbas som gör att ChatGPT kan diskutera allt från kvantfysik till medeltidshistoria till samtida populärkultur. Det är dock viktigt att förstå att ChatGPT inte har tillgång till information i realtid eller till proprietära databaser; den kan endast använda det som var tillgängligt under dess träningsperiod.
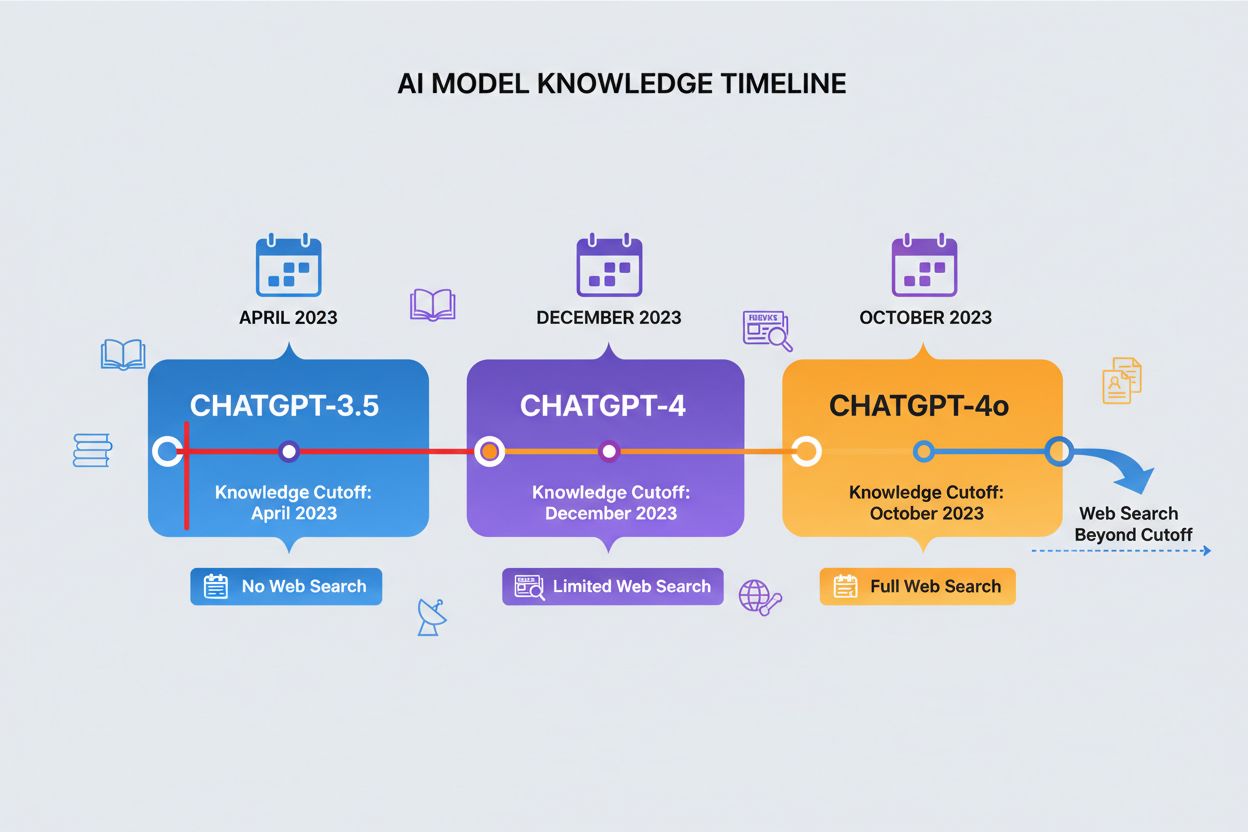
Ett kunskapsgränsdatum markerar den tidpunkt efter vilken ChatGPT inte har någon träningsdata, vilket skapar en tydlig gräns för vilken information den kan komma åt. Olika versioner av ChatGPT har olika gränsdatum: ChatGPT-4 tränades på data till och med december 2023, medan ChatGPT-4o (den optimerade versionen) har en kunskapsgräns i oktober 2023. Dessa gränser påverkar i hög grad svarens noggrannhet och relevans, särskilt för aktuella händelser, nypublicerad forskning eller aktuella statistikuppgifter som kan ha förändrats sedan datainsamlingen. Vissa nyare versioner av ChatGPT kan göra webbsökningar för att hämta aktuell information bortom sina gränsdatum, men denna funktion är inte tillgänglig i alla versioner eller sammanhang. Att känna till modellens kunskapsgräns är avgörande för användare som behöver aktuell information, eftersom ChatGPT inte kan ge korrekta svar om händelser eller utveckling som skett efter träningsperioden slutat. Denna begränsning är en av de viktigaste faktorerna att ta hänsyn till vid bedömning av ChatGPT:s pålitlighet för tidskänsliga frågor.
| ChatGPT-version | Kunskapsgräns | Webbsökningsfunktion | Primärt användningsområde |
|---|---|---|---|
| ChatGPT-4 | December 2023 | Begränsad | Allmän kunskap, analys, resonemang |
| ChatGPT-4o | Oktober 2023 | Tillgänglig | Optimerad prestanda, multimodal användning |
| ChatGPT-3.5 | April 2023 | Nej | Enkla frågor, kostnadseffektivt alternativ |
| ChatGPT med surfing | Realtid | Ja | Aktuella händelser, ny forskning |
Till skillnad från sökmotorer som hämtar specifika dokument eller webbsidor som svar på frågor, genererar ChatGPT svar genom att syntetisera mönster inlärda under träningen—en grundläggande annorlunda process. När du ställer en fråga till ChatGPT söker den inte igenom en databas eller ett index; istället använder den statistiska mönster från sin träningsdata för att förutsäga den mest sannolika ordsekvensen som skulle utgöra ett hjälpsamt svar. Detta generationsbaserade tillvägagångssätt innebär att ChatGPT kombinerar information från flera källor i sin träningsdata för att skapa nya svar som kanske inte finns ordagrant någonstans i källmaterialet. Modellen lär sig i princip relationerna mellan begrepp, fakta och idéer och rekonstruerar denna kunskap som svar på din specifika fråga. Denna process har dock en betydande nackdel: när modellen är osäker på information eller när mönstren i träningsdatan är motsägelsefulla eller bristfälliga kan den generera trovärdigt men felaktigt innehåll, ett fenomen som kallas “hallucination”. Nyare versioner av ChatGPT som integrerar webbsökningsfunktionalitet kan komplettera denna process genom att hämta aktuell information från internet, men denna funktion kräver explicit aktivering och är inte tillgänglig på alla plattformar.
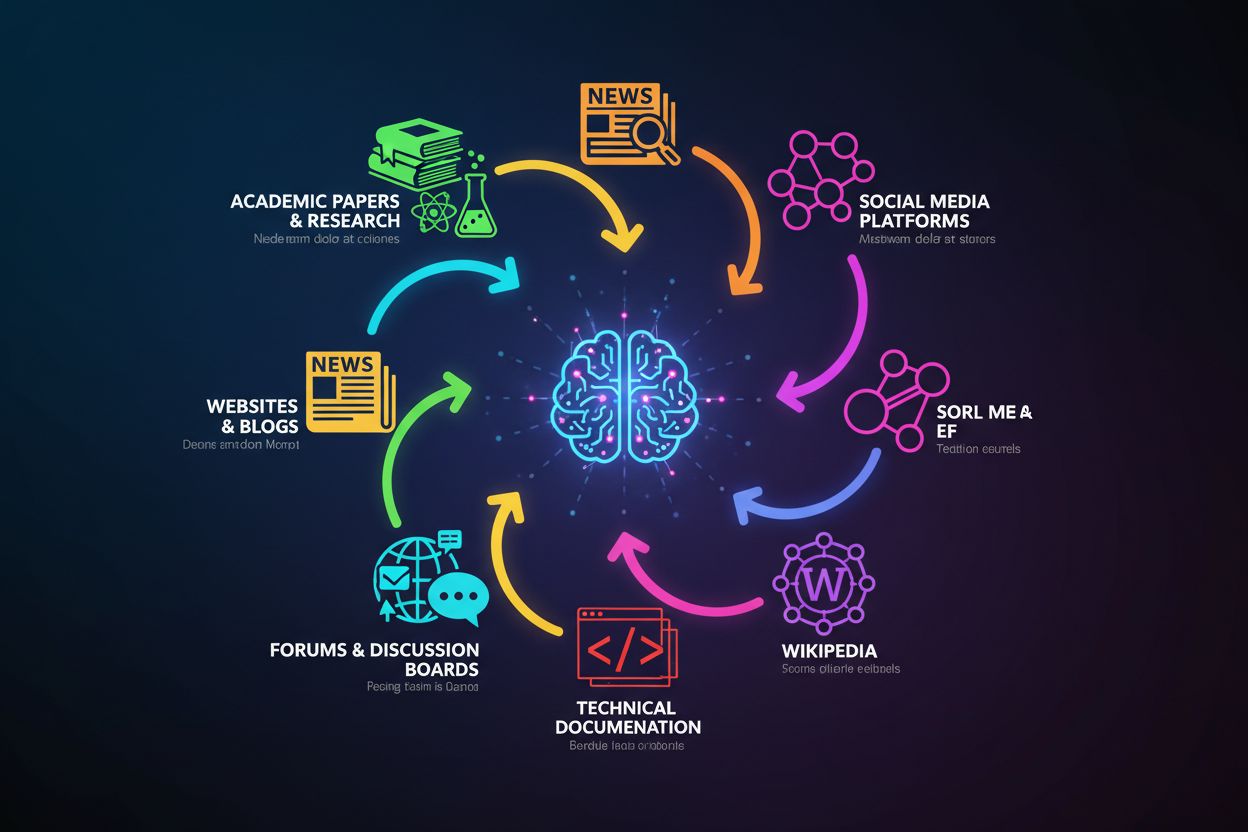
ChatGPT:s träningsdata hämtas från flera större källkategorier, som alla bidrar med unika värden till dess kunskapsbas:
Betydelsen av dessa olika källor ligger i deras kompletterande styrkor: akademiska artiklar ger noggrannhet, nyhetsartiklar ger aktualitet, böcker ger djup och forum ger praktisk tillämpning. Dock varierar källkvaliteten avsevärt—en fackgranskad akademisk artikel väger tyngre än ett slumpmässigt blogginlägg, men ChatGPT:s träningsprocess gör ingen tydlig åtskillnad mellan dem. Det innebär att ChatGPT:s kunskap speglar både högkvalitativa auktoritativa källor och lägre kvalitet eller potentiellt missvisande innehåll, vilket gör att verifiering är avgörande vid viktiga beslut.
Efter den initiala träningen på enorma mängder textdata använde OpenAI en teknik som kallas Reinforcement Learning from Human Feedback (RLHF) för att förfina ChatGPT:s svar. I denna process utvärderade mänskliga tränare modellens svar och gav feedback, vilket hjälpte systemet att lära sig vilka svar som var mest hjälpsamma, korrekta och i linje med mänskliga värderingar. Dessa tränare faktagranskade inte varje påstående; de bedömde snarare övergripande kvalitet, hjälpsamhet och säkerhet, vilket indirekt påverkade hur modellen prioriterar och presenterar information. RLHF-processen påverkar i hög grad vilken information som betonas i svaren och hur olika ämnen framställs, och introducerar mänskliga bedömningar i vad som annars vore en helt statistisk modell. Men denna feedbackprocess har inneboende begränsningar: tränare har egna fördomar, kunskapsluckor och begränsningar, och de kan inte utvärdera riktigheten i varje påstående inom alla områden. Dessutom är feedbackprocessen resurskrävande och kan bara tillämpas på en bråkdel av modellens möjliga svar, vilket innebär att mycket av ChatGPT:s beteende fortfarande speglar råa mönster i träningsdatan snarare än explicit mänsklig kuratering.
Att citera ChatGPT är viktigt för akademisk integritet och transparens, så att läsare kan förstå var informationen kommer ifrån och potentiellt reproducera eller verifiera dina resultat. Citeringsformatet beror på vilken referensstil som krävs, men här är de vanligaste tillvägagångssätten:
Exempel enligt MLA:
OpenAI. "ChatGPT." Åtkomst [Datum], https://chat.openai.com.
I MLA-stil citerar du ChatGPT som en webbplats, inklusive åtkomstdatum eftersom innehållet är dynamiskt och kan ändras. Om du citerar ett specifikt svar bör du ange datumet du fick åtkomst och helst inkludera prompten eller frågan du ställde.
Exempel enligt APA:
OpenAI. (2024). ChatGPT (Version 4) [Large language model].
Hämtad från https://chat.openai.com
APA betraktar ChatGPT som ett mjukvaruverktyg eller en applikation, inklusive versionsnummer och hämtningsdatum. Vissa APA-riktlinjer rekommenderar att du inkluderar den specifika prompten i din referens eller i en bilaga.
När ska man citera ChatGPT: Du bör citera verktyget varje gång du använder dess output i akademiskt arbete, professionella rapporter eller i alla sammanhang där källhänvisning är viktig. Dokumentera den exakta prompten du använde, åtkomstdatumet och helst ChatGPT-versionen, eftersom dessa detaljer påverkar reproducerbarheten. Den viktigaste skillnaden mellan att citera ChatGPT och traditionella källor är att ChatGPT-responsen genereras dynamiskt—samma prompt kan ge något olika svar vid olika tillfällen—så att inkludera själva prompten blir en del av korrekt citeringspraxis. Många institutioner håller fortfarande på att utveckla formella riktlinjer för AI-citering, så kontrollera med din specifika organisation eller publikation vilket format de föredrar.
Även om ChatGPT är mycket kapabel har den betydande begränsningar som påverkar tillförlitligheten i informationen. ChatGPT kan självsäkert ge felaktig information, ett problem som kallas hallucination, särskilt vid frågor om obskyra ämnen, aktuella händelser efter dess kunskapsgräns eller när den stöter på motsägelsefull information i sin träningsdata. Modellens träningsdata innehåller inneboende partiskhet som speglar de perspektiv, demografier och synsätt som finns i källmaterialet, vilket innebär att svaren oavsiktligt kan favorisera vissa perspektiv eller innehålla stereotyper. Informationen i ChatGPT:s träningsdata blir successivt mer föråldrad med tiden, vilket gör den opålitlig för aktuell statistik, senaste forskningsresultat eller föränderliga situationer. Därför är faktagranskning av ChatGPT:s påståenden avgörande, särskilt vid viktiga beslut—du bör kontrollera centrala fakta mot primärkällor, nyare publikationer och auktoritativa databaser. För att verifiera ChatGPT:s påståenden, jämför dess uttalanden med flera oberoende källor, kontrollera datum och siffror mot aktuell data och var särskilt skeptisk till specifika siffror, namn eller nyare händelser. Kom slutligen ihåg att ChatGPT inte är en primärkälla; det är en sekundär källa som syntetiserar information från andra källor, så för akademiskt eller professionellt arbete bör du citera de ursprungliga källor som ChatGPT refererar till, inte ChatGPT självt.
I takt med att ChatGPT och andra AI-system blir alltmer integrerade i hur människor hittar information har det blivit avgörande att övervaka hur dessa system citerar och refererar till ditt varumärke eller din organisation. AmICited är en plattform för övervakning av AI-svar som är särskilt utformad för att spåra hur ChatGPT, Claude och andra stora språkmodeller nämner, citerar eller refererar till ditt företag, dina produkter eller ditt varumärke i sina svar. Plattformen hjälper dig att förstå när och hur ditt varumärke syns i AI-genererade svar och ger insyn i en ny och växande kanal för informationsupptäckt som traditionella webbövervakningsverktyg ofta missar. Denna övervakningsförmåga är viktig eftersom AI-citeringar fungerar annorlunda än traditionella webb-citeringar—de är inbäddade i konversationella svar som miljontals användare interagerar med dagligen, men de flesta varumärken har ingen insyn i hur de representeras. Genom att använda AmICited för att spåra AI-omnämnanden och citeringar får du insikter om varumärkesuppfattning i AI-system, kan identifiera felaktigheter eller föråldrad information som behöver åtgärdas och förstå hur ditt varumärke står sig mot konkurrenter i AI-genererade svar. I en tid då AI-system blir primära informationskällor för många användare är övervakning av din närvaro i dessa system lika viktigt som att övervaka traditionella sökresultat, vilket gör verktyg som AmICited avgörande för modern varumärkeshantering och AI-transparens.
ChatGPT tränades på tre huvudsakliga källor: offentligt tillgänglig internetdata (webbplatser, artiklar, forum), licensierade datamängder (böcker och akademiska publikationer) och mänsklig feedback från tränare. Träningsdatan omfattar nyhetssajter, akademiska tidskrifter, teknisk dokumentation, Wikipedia, Reddit, Stack Overflow och otaliga andra offentligt tillgängliga webbsidor insamlade fram till dess kunskapsgräns.
Ett kunskapsgränsdatum är den tidpunkt efter vilken ChatGPT inte har någon träningsdata. ChatGPT-4 har en gräns i december 2023, medan ChatGPT-4o har en gräns i oktober 2023. Detta är viktigt eftersom ChatGPT inte kan ge korrekt information om händelser, forskning eller utveckling som skett efter att träningsperioden avslutats, vilket gör den opålitlig för tidskänsliga frågor.
ChatGPT kan inte få tillgång till realtidsinformation enbart från sin träningsdata. Nyare versioner av ChatGPT kan dock göra webbsökningar för att hämta aktuell information utöver sina kunskapsgränser, men denna funktion är inte tillgänglig i alla versioner eller sammanhang och kräver explicit aktivering.
I MLA-format citeras ChatGPT som en webbplats med åtkomstdatum. I APA-format behandlas det som programvara med versionsnummer. Båda formaten kräver att du dokumenterar den exakta prompten du använde, åtkomstdatumet och helst ChatGPT-versionen, eftersom samma prompt kan ge olika svar vid olika tillfällen.
Nej. ChatGPT kan självsäkert ge felaktig information (hallucination), särskilt om obskyra ämnen, aktuella händelser efter dess kunskapsgräns, eller motsägelsefull information. Dess träningsdata innehåller inneboende partiskhet, och information blir successivt mer föråldrad. Kontrollera alltid viktiga påståenden mot primärkällor och auktoritativa databaser.
ChatGPT:s träningsdata uppdateras inte kontinuerligt. Nya versioner släpps periodvis med uppdaterade kunskapsgränser, men det sker ingen realtidsuppdatering av basmodellen. OpenAI släpper nya versioner (som GPT-4o) med nyare träningsdata, men exakt uppdateringsschema är inte offentligt.
ChatGPT citerar inte specifika källor för enskilda påståenden eftersom den syntetiserar information från mönster i sin träningsdata snarare än att hämta specifika dokument. Den kan inte peka ut den exakta källan till ett faktum. För akademiskt arbete bör du verifiera ChatGPT:s påståenden och citera de ursprungliga källor du hittar, inte ChatGPT själv.
AmICited spårar hur ChatGPT, Claude och andra AI-system nämner, citerar eller refererar till ditt varumärke i sina svar. Det ger insyn i hur ditt företag syns i AI-genererade svar, hjälper till att identifiera felaktigheter och visar hur ditt varumärke står sig mot konkurrenter i AI-system—väsentligt för modern varumärkeshantering i AI-eran.
Spåra ChatGPT-citeringar och AI-omnämnanden i realtid med AmICited. Förstå hur AI-system refererar till ditt varumärke och ligg steget före AI-drivna informationsupptäckter.
Komplett guide för att avanmäla dig från AI-träning och datainsamling på ChatGPT, Perplexity, LinkedIn och andra plattformar. Lär dig steg-för-steg hur du skydd...
Lär dig hur ChatGPT Search hämtar realtidsinformation från internet genom webbcrawlers, indexering och partnerskap med dataleverantörer för att leverera korrekt...
Diskussion i communityn om skillnaderna mellan ChatGPT och ChatGPT Search. Riktiga erfarenheter från marknadsförare som optimerar innehåll för både träningsdata...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.