GPTBot vs OAI-SearchBot: Förstå OpenAI:s olika crawlers
Lär dig de viktigaste skillnaderna mellan GPTBot och OAI-SearchBot crawlers. Förstå deras syften, crawl-beteenden och hur du hanterar dem för optimal synlighet av ditt innehåll i AI-sökresultat.
Publicerad den Jan 3, 2026.Senast ändrad den Jan 3, 2026 kl 8:37 am
Förstå OpenAI:s olika crawlers: GPTBot vs OAI-SearchBot
OpenAI använder två olika webb-crawlers som har olika syften i deras ekosystem, och att förstå skillnaden mellan dem är avgörande för innehållsskapare och webbplatsägare. GPTBot och OAI-SearchBot representerar olika tillvägagångssätt för datainsamling, där den ena är inriktad på träning av AI-modeller och den andra på att möjliggöra sökfunktioner. Dessa crawlers har olika beteenden, åtkomstmönster och konsekvenser för din webbplats synlighet och dataanvändning. Att veta vilken crawler som besöker din sida och hur du hanterar dem kan ha stor betydelse för din innehållsstrategi.
Vad är GPTBot?
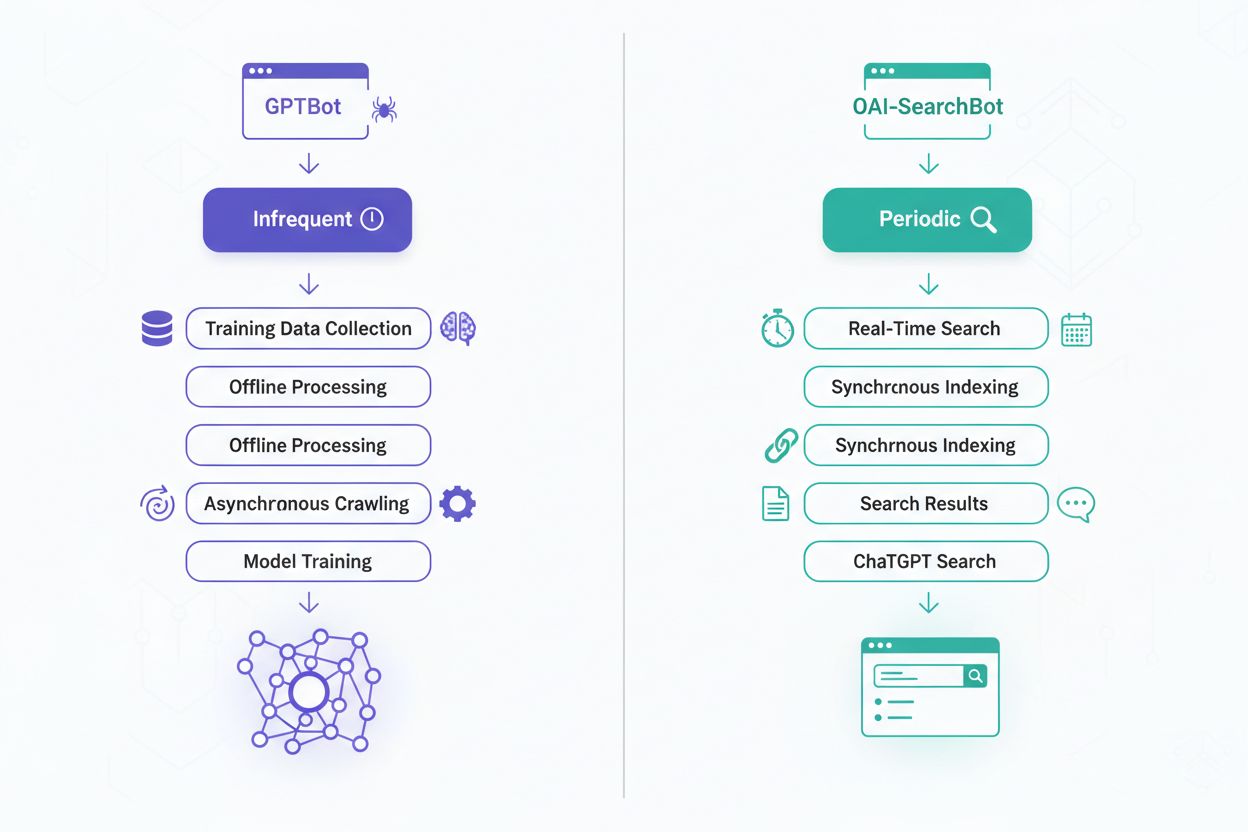
GPTBot är OpenAI:s huvudsakliga webb-crawler som är utformad för att samla in träningsdata till deras stora språkmodeller, inklusive ChatGPT och andra AI-system. Lanserad för att förbättra kvaliteten och bredden av träningsdata, crawlar GPTBot systematiskt webbplatser för att samla in textinnehåll som hjälper till att träna och förfina OpenAI:s AI-modeller. Denna crawler verkar under user-agent-identifieraren “GPTBot” och respekterar robots.txt-filen, vilket gör det möjligt för webbplatsägare att välja bort datainsamling. GPTBots huvudsakliga uppdrag är att förbättra AI-modellernas kapacitet genom att lära sig från varierande, högkvalitativt innehåll över internet. Crawlern är utformad för att vara skonsam mot serverresurser samtidigt som den samlar in information som bidrar till AI-träningsdatabaser. Webbplatsägare som vill att deras innehåll ska inkluderas i framtida AI-modellträning kan tillåta GPTBot åtkomst, medan de som är oroade över dataanvändning kan blockera den helt.
OAI-SearchBot är OpenAI:s specialiserade crawler som är avsedd att möjliggöra sökfunktionalitet inom ChatGPT, vilket låter användare söka på webben direkt från ChatGPT:s gränssnitt. Denna crawler introducerades som en del av ChatGPT:s sökfunktioner och gör det möjligt för AI:n att hämta realtidsinformation och ge aktuella, relevanta resultat till användare. Till skillnad från GPTBot fokuserar OAI-SearchBot på att indexera innehåll för omedelbar åtkomst snarare än för långsiktig modellträning. Crawlern verkar under user-agent-identifieraren “OAI-SearchBot” och följer också robots.txt-direktiv, vilket ger webbplatsägare kontroll över om deras innehåll visas i ChatGPT:s sökresultat. OAI-SearchBots crawl-mönster är vanligtvis mer frekventa och målinriktade, eftersom den behöver hålla index aktuella för realtids-sökfunktion. Denna crawler är viktig för webbplatser som vill att deras innehåll ska vara sökbart och citeras när användare söker inom ChatGPT.
Viktiga skillnader mellan GPTBot och OAI-SearchBot
Även om båda crawlers tjänar OpenAI:s ekosystem har de olika syften, beteenden och konsekvenser för innehållsskapare. Att förstå dessa skillnader hjälper dig att fatta informerade beslut om vilka crawlers du vill tillåta eller blockera på din webbplats. Här är en omfattande jämförelse av de två crawlers:
Funktion
GPTBot
OAI-SearchBot
Huvudsyfte
Insamling av träningsdata för AI-modeller
Realtids-sökindexering för ChatGPT
User-Agent-sträng
GPTBot
OAI-SearchBot
Crawl-frekvens
Periodisk, mindre frekvent
Mer frekvent, kontinuerliga uppdateringar
Dataanvändning
Långsiktig modellträning och förbättring
Omedelbar hämtning av sökresultat
Innehållssynlighet
Påverkar framtida AI-modellers kapacitet
Påverkar ChatGPT:s ranking i sökresultat
robots.txt-stöd
Ja, följer direktiv fullständigt
Ja, följer direktiv fullständigt
Realtidskrav
Nej, batchbearbetning är acceptabelt
Ja, kräver aktuella index
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Syfte och funktionsskillnader
Den grundläggande skillnaden mellan dessa crawlers ligger i deras operativa mål och hur de använder insamlad data. GPTBot är utformad med ett långsiktigt perspektiv, samlar in varierande innehåll för att förbättra AI-modellträning över månader och år, vilket bidrar till bättre språkförståelse och genereringsförmåga. OAI-SearchBot å andra sidan arbetar i realtid, håller index färska så att ChatGPT-användare kan få aktuell information när de söker efter nyheter, händelser eller tidskänsliga ämnen. GPTBots datainsamling är mer omfattande och utforskande, med målet att täcka bredden av mänsklig kunskap och skrivstilar. OAI-SearchBots tillvägagångssätt är mer målinriktat och effektivitetsfokuserat, där innehållsrelevans och färskhet prioriteras vid sökfrågor. Konsekvenserna är betydande: att tillåta GPTBot innebär att ditt innehåll bidrar till AI-modellutveckling, medan tillåter du OAI-SearchBot innebär att ditt innehåll kan upptäckas och citeras i ChatGPT:s sökresultat. Många webbplatser väljer olika strategier för varje crawler beroende på innehållstyp och affärsmål.
Crawl-beteende och frekvens
GPTBot arbetar enligt ett periodiskt crawl-schema och besöker webbplatser med intervaller som kan sträcka sig över veckor eller månader beroende på hur ofta innehållet uppdateras och webbplatsens betydelse. Denna crawler är utformad för att vara effektiv med bandbredd och serverresurser, eftersom den inte behöver realtidsdata för sitt träningssyfte. Crawl-djup och -bredd är vanligtvis omfattande, eftersom GPTBot vill fånga många olika innehållstyper och skrivstilar för modellträning. OAI-SearchBot däremot har ett mer aggressivt crawl-schema med frekventa återbesök för att säkerställa att sökindex är aktuella och korrekta. Denna crawler prioriterar nyligen uppdaterat innehåll och trendande ämnen, och gör flera genomgångar av populära eller ofta uppdaterade webbplatser. Skillnaden i frekvens speglar deras olika syften: GPTBot kan ha tålamod och vara grundlig, medan OAI-SearchBot måste hänga med i det snabbt föränderliga webben för att kunna erbjuda relevanta sökresultat.
Påverkan på innehållssynlighet
Att tillåta GPTBot åtkomst innebär att ditt innehåll blir en del av träningsdata för framtida AI-modeller, vilket potentiellt påverkar hur AI-system förstår och genererar innehåll relaterat till dina ämnen. Detta kan ge långsiktiga fördelar då din skrivstil, expertis och unika perspektiv hjälper till att forma AI-svar inom ditt område. Det innebär dock också att ditt innehåll används för att träna system som så småningom kan konkurrera med ditt originalmaterial. OAI-SearchBot-åtkomst påverkar direkt din synlighet i ChatGPT:s sökresultat, vilket gör ditt innehåll sökbart för miljontals ChatGPT-användare som söker information. När användare hittar ditt innehåll via ChatGPT-sök kan det driva betydande trafik och etablera din webbplats som en auktoritativ källa. Synlighetseffekten skiljer sig markant: GPTBot påverkar din påverkan på AI-utveckling, medan OAI-SearchBot påverkar din omedelbara sökbarhet och trafikpotential. Innehållsskapare måste väga dessa överväganden utifrån sina mål, oavsett om de prioriterar deltagande i AI-träning eller synlighet i sök.
Robots.txt och åtkomstkontroll
Både GPTBot och OAI-SearchBot följer robots.txt-filen, vilket ger webbplatsägare full kontroll över crawler-åtkomst via standardprotokoll för webben. Du kan blockera en eller båda crawlers genom att lägga till specifika direktiv i din robots.txt-fil, eller tillåta dem medan du blockerar andra crawlers. Denna flexibilitet möjliggör nyanserade innehållsstrategier där du kan tillåta en crawler men blockera den andra beroende på dina behov och farhågor. OpenAI har också tillhandahållit officiell dokumentation och riktlinjer för att hantera dessa crawlers, vilket gör det enkelt att implementera dina föredragna åtkomstpolicyer. Robots.txt-lösningen är transparent och följer etablerade webbstandarder, vilket säkerställer kompatibilitet med andra verktyg och övervakningssystem. Här är vanliga robots.txt-konfigurationer för att hantera OpenAI-crawlers:
Blockera båda crawlers: Lägg till User-agent: GPTBot och User-agent: OAI-SearchBot med Disallow: /
Blockera endast GPTBot: Lägg till User-agent: GPTBot med Disallow: / och tillåt OAI-SearchBot
Blockera endast OAI-SearchBot: Lägg till User-agent: OAI-SearchBot med Disallow: / och tillåt GPTBot
Blockera specifika kataloger: Använd Disallow: /private/ för att blockera crawlers från känsliga områden
Tillåt alla crawlers: Utelämna OpenAI-crawler-direktiv för att tillåta både GPTBot och OAI-SearchBot
Fördröj crawlers: Använd Crawl-delay: 10 för att begränsa crawlerfrekvensen och påverkan på servern
Övervakning och verifiering
För att verifiera att OpenAI-crawlers verkligen får åtkomst till din webbplats måste du undersöka serverloggar och leta efter de specifika user-agent-strängarna. Du kan identifiera GPTBot-förfrågningar genom att söka efter “GPTBot” och OAI-SearchBot-förfrågningar genom att söka efter “OAI-SearchBot” i dina accessloggar. Många webbplatsägare använder logganalysverktyg eller webbanalysplattformar som kan filtrera och rapportera om specifik crawleraktivitet. Övervakning av crawler-beteende hjälper dig att förstå om dina robots.txt-direktiv fungerar korrekt och om crawlers följer dina åtkomstpolicyer. Regelbunden övervakning visar även crawl-mönster och frekvens, vilket hjälper dig optimera serverresurser och förstå påverkan på din infrastruktur. Dessutom kan du verifiera crawler-IP-adresser mot OpenAI:s publicerade IP-intervall för att försäkra dig om att förfrågningarna är legitima och inte förfalskade av illvilliga aktörer.
Strategiska överväganden för webbplatsägare
Ditt beslut att tillåta eller blockera dessa crawlers bör stämma överens med din innehållsstrategi och dina affärsmål. Om ditt huvudmål är att driva trafik och synlighet är det logiskt att tillåta OAI-SearchBot, eftersom det direkt påverkar sökbarheten i ChatGPT:s sökresultat. Om du är orolig för hur ditt innehåll används vid AI-träning eller föredrar att exklusivt kontrollera ditt innehåll, skyddar du ditt intellektuella kapital genom att blockera GPTBot. Vissa webbplatser använder en hybridstrategi, där OAI-SearchBot tillåts för synlighet i sök medan GPTBot blockeras för att förhindra att data används i träning. Tänk på din innehållstyp: nyhetssajter och webbplatser med aktuella händelser gynnas i hög grad av OAI-SearchBot-åtkomst, medan skapare av exklusivt eller känsligt innehåll kan föredra att blockera båda. Beslutet är inte permanent – du kan när som helst justera din robots.txt-fil för att ändra dina crawlerpolicyer. Regelbunden översyn av din crawlerstrategi ser till att den fortsätter stödja dina föränderliga affärsmål och innehållsprioriteringar.
Övervaka dina crawlers med AmICited
AmICited erbjuder omfattande lösningar för crawlerövervakning som hjälper dig spåra både GPTBot- och OAI-SearchBot-aktivitet på din webbplats med detaljerad analys och insikter. Plattformen ger realtidsnotiser när dessa crawlers får åtkomst till ditt innehåll, så att du kan verifiera efterlevnad av dina robots.txt-direktiv och övervaka crawl-mönster. Med AmICited får du insyn i hur ditt innehåll indexeras och används av OpenAI:s system, vilket möjliggör datadrivna beslut om dina crawlerpolicyer. Den här övervakningslösningen förenklar processen att förstå ditt innehålls roll i AI-träning och sökindexering, och ger dig den kontroll och transparens du behöver i ett föränderligt AI-landskap.
Vanliga frågor
Vad är den största skillnaden mellan GPTBot och OAI-SearchBot?
GPTBot är OpenAI:s träningscrawler som samlar in data för AI-modellutveckling och arbetar enligt ett periodiskt schema med långsiktiga mål. OAI-SearchBot är OpenAI:s sökcrawler som underhåller realtidsindex för ChatGPT:s sökfunktion. Båda följer robots.txt, men de har olika syften, crawl-frekvenser och påverkan på synligheten för ditt innehåll.
Bör jag blockera GPTBot eller OAI-SearchBot på min webbplats?
Beslutet beror på din innehållsstrategi och dina affärsmål. Tillåt OAI-SearchBot om du vill att ditt innehåll ska vara sökbart i ChatGPT:s sökresultat och om du vill driva trafik. Blockera GPTBot om du är orolig för att ditt innehåll används i AI-modellträning. Många webbplatser använder en hybridstrategi där man tillåter den ena och blockerar den andra utifrån sina behov.
Hur identifierar jag GPTBot och OAI-SearchBot i mina serverloggar?
Sök i dina serveraccessloggar efter user-agent-strängarna 'GPTBot' och 'OAI-SearchBot'. De flesta webbanalysplattformar och logganalysverktyg gör det möjligt att filtrera efter user-agent, vilket gör det enkelt att identifiera och övervaka crawleraktivitet. Du kan också verifiera crawler-IP-adresser mot OpenAI:s publicerade IP-intervall för att säkerställa att begärandena är legitima.
Påverkar blockering av den ena crawlern den andra?
Nej, blockering av GPTBot och OAI-SearchBot är oberoende åtgärder. Du kan blockera båda, tillåta båda eller blockera den ena medan du tillåter den andra med separata robots.txt-direktiv. Varje crawler följer sina egna user-agent-regler, så dina åtkomstpolicyer för en crawler gäller inte automatiskt för den andra.
Hur ofta besöker GPTBot och OAI-SearchBot webbplatser?
GPTBot arbetar enligt ett periodiskt crawl-schema och besöker webbplatser med intervaller som kan sträcka sig över veckor eller månader beroende på innehållets aktualitet och webbplatsens vikt. OAI-SearchBot har ett mer frekvent crawl-schema för att hålla sökindex aktuella och korrekta. Frekvensskillnaden speglar deras olika syften: GPTBot prioriterar noggrannhet medan OAI-SearchBot prioriterar färskhet.
Vad har det för effekt på min trafik att tillåta OAI-SearchBot?
Att tillåta OAI-SearchBot kan driva trafik till din webbplats när användare hittar och klickar via ChatGPT:s sökresultat. Effekten varierar beroende på din innehållstyp och relevans för användarfrågor. Nyheter, aktuella händelser och informationsinnehåll ser vanligtvis mer trafik från AI-sök, medan nischat eller specialiserat innehåll kan märka mindre direkt effekt.
Kan jag blockera specifika kataloger för dessa crawlers?
Ja, du kan använda robots.txt för att blockera specifika kataloger eller filtyper för GPTBot och OAI-SearchBot. Till exempel kan du använda 'Disallow: /private/' för att blockera crawlers från känsliga delar samtidigt som de får åtkomst till offentligt innehåll. Denna granulära kontroll låter dig skydda känslig information och samtidigt behålla synligheten i AI-sökresultat.
Hur hjälper AmICited till att övervaka dessa crawlers?
AmICited tillhandahåller övervakning och analys i realtid för både GPTBot och OAI-SearchBot-aktivitet på din webbplats. Plattformen spårar crawlerbesök, verifierar robots.txt-efterlevnad och ger insikter om hur ditt innehåll indexeras och används av OpenAI:s system. Detta ger dig transparensen och kontrollen du behöver för att fatta informerade beslut om åtkomstpolicyer för crawlers.
Övervaka din AI-crawleraktivitet
Spåra hur GPTBot och OAI-SearchBot får åtkomst till ditt innehåll med insikter och analys i realtid. Förstå ditt innehålls roll i AI-träning och sökindexering.
Vad är GPTBot och Bör Du Tillåta Det? Komplett Guide för Webbplatsägare
Lär dig vad GPTBot är, hur det fungerar och om du bör tillåta eller blockera OpenAI:s webcrawler. Förstå effekten på din varumärkesexponering i AI-sökmotorer oc...
Lär dig vad GPTBot är, hur den fungerar och om du bör blockera den från din webbplats. Förstå påverkan på SEO, serverbelastning och varumärkessynlighet i AI-sök...
Lär dig vad OAI-SearchBot är, hur den fungerar och hur du optimerar din webbplats för OpenAI:s dedikerade sökcrawler som används av SearchGPT och ChatGPT.
6 min läsning
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.