
GPTBot
Erfahren Sie, was GPTBot ist, wie er funktioniert und ob Sie ihn von Ihrer Website blockieren sollten. Verstehen Sie die Auswirkungen auf SEO, Serverlast und Ma...
9 Min. Lesezeit

Erfahren Sie die wichtigsten Unterschiede zwischen den Crawlern GPTBot und OAI-SearchBot. Verstehen Sie deren Zwecke, Crawl-Verhalten und wie Sie diese für optimale Sichtbarkeit Ihrer Inhalte in KI-Suchergebnissen verwalten können.
OpenAI betreibt zwei unterschiedliche Webcrawler, die verschiedene Zwecke innerhalb ihres Ökosystems erfüllen. Für Content-Ersteller und Website-Betreiber ist es entscheidend, diese Unterschiede zu kennen. GPTBot und OAI-SearchBot stehen für unterschiedliche Ansätze der Datensammlung: Der eine dient dem Training von KI-Modellen, der andere der Suchfunktion. Sie unterscheiden sich im Verhalten, den Zugriffsmustern sowie in ihren Auswirkungen auf die Sichtbarkeit und Nutzung Ihrer Website-Daten. Zu wissen, welcher Crawler Ihre Seite besucht und wie Sie diese verwalten, kann Ihre Content-Strategie maßgeblich beeinflussen.
GPTBot ist OpenAIs primärer Webcrawler, der Trainingsdaten für große Sprachmodelle wie ChatGPT und weitere KI-Systeme sammelt. Er wurde eingeführt, um die Qualität und Vielfalt der Trainingsdaten zu verbessern, indem er Webseiten systematisch durchsucht, um Textinhalte zur Verfeinerung der KI-Modelle zu gewinnen. Der Crawler arbeitet mit dem User-Agent “GPTBot” und respektiert die robots.txt-Datei, sodass Website-Betreiber sich gegen die Datensammlung entscheiden können. Die Hauptaufgabe von GPTBot ist es, die Fähigkeiten von KI-Modellen durch das Lernen von vielfältigen, hochwertigen Inhalten im Internet zu verbessern. Der Crawler ist so konzipiert, dass er serverfreundlich arbeitet und gleichzeitig umfassende Informationen für KI-Trainingsdatensätze sammelt. Wer möchte, dass seine Inhalte in zukünftigen KI-Modellen verwendet werden, kann GPTBot den Zugriff erlauben; wer Bedenken hat, kann ihn vollständig blockieren.
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
OAI-SearchBot ist OpenAIs spezialisierter Crawler für die Suchfunktion in ChatGPT. Er ermöglicht es Nutzern, direkt über ChatGPT im Web zu suchen. Dieser Crawler wurde im Rahmen der Suchfunktion von ChatGPT eingeführt und erlaubt es der KI, aktuelle, relevante Informationen aus dem Web bereitzustellen. Im Gegensatz zu GPTBot konzentriert sich OAI-SearchBot darauf, Inhalte für den sofortigen Abruf zu indexieren, nicht für das langfristige KI-Training. Der Crawler arbeitet mit dem User-Agent “OAI-SearchBot” und respektiert ebenfalls robots.txt-Anweisungen, sodass Sie als Website-Betreiber steuern können, ob Ihre Inhalte in den ChatGPT-Suchergebnissen erscheinen. Die Crawl-Muster sind meist häufiger und gezielter, da aktuelle Indizes für die Echtzeit-Suche erforderlich sind. Dieser Crawler ist für Websites wichtig, die möchten, dass ihre Inhalte bei Suchanfragen in ChatGPT auffindbar und zitiert werden.
Beide Crawler sind Teil des OpenAI-Ökosystems, verfolgen jedoch unterschiedliche Ziele, zeigen unterschiedliches Verhalten und haben verschiedene Auswirkungen auf Content-Ersteller. Das Verständnis dieser Unterschiede hilft Ihnen, fundierte Entscheidungen darüber zu treffen, welche Crawler Sie auf Ihrer Website zulassen oder blockieren. Hier ein umfassender Vergleich:
| Merkmal | GPTBot | OAI-SearchBot |
|---|---|---|
| Hauptzweck | Sammlung von Trainingsdaten für KI-Modelle | Echtzeit-Suchindexierung für ChatGPT |
| User-Agent-String | GPTBot | OAI-SearchBot |
| Crawl-Frequenz | Periodisch, weniger häufig | Häufiger, kontinuierliche Updates |
| Datennutzung | Langfristiges Modelltraining und Verbesserung | Sofortiger Abruf von Suchergebnissen |
| Sichtbarkeit von Inhalten | Beeinflusst zukünftige KI-Modellfähigkeiten | Beeinflusst ChatGPT-Suchergebnis-Rankings |
| robots.txt-Unterstützung | Ja, beachtet Vorgaben vollständig | Ja, beachtet Vorgaben vollständig |
| Echtzeitanforderungen | Nein, Batch-Verarbeitung ausreichend | Ja, aktuelle Indizes erforderlich |
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Der grundlegende Unterschied dieser Crawler liegt in ihren Zielen und der Nutzung der gesammelten Daten. GPTBot verfolgt eine langfristige Vision: Er sammelt vielfältige Inhalte, um das KI-Modelltraining über Monate und Jahre hinweg zu verbessern und so das Sprachverständnis und die Textgenerierung weiterzuentwickeln. OAI-SearchBot arbeitet hingegen in Echtzeit, pflegt aktuelle Indizes und ermöglicht es ChatGPT-Nutzern, aktuelle Informationen zu finden – beispielsweise zu Nachrichten, Ereignissen oder zeitkritischen Themen. Die Datensammlung durch GPTBot ist umfassender und explorativer, mit dem Ziel, den gesamten Umfang menschlichen Wissens und Schreibstils zu erfassen. OAI-SearchBot ist gezielter und effizienter, wobei Relevanz und Aktualität für Suchanfragen im Vordergrund stehen. Das hat weitreichende Konsequenzen: Wer GPTBot zulässt, trägt zur Entwicklung von KI-Modellen bei, während die Zulassung von OAI-SearchBot die Auffindbarkeit und Zitierbarkeit der eigenen Inhalte in der ChatGPT-Suche fördert. Viele Websites wählen unterschiedliche Strategien für jeden Crawler – je nach Inhaltstyp und Geschäftsziel.
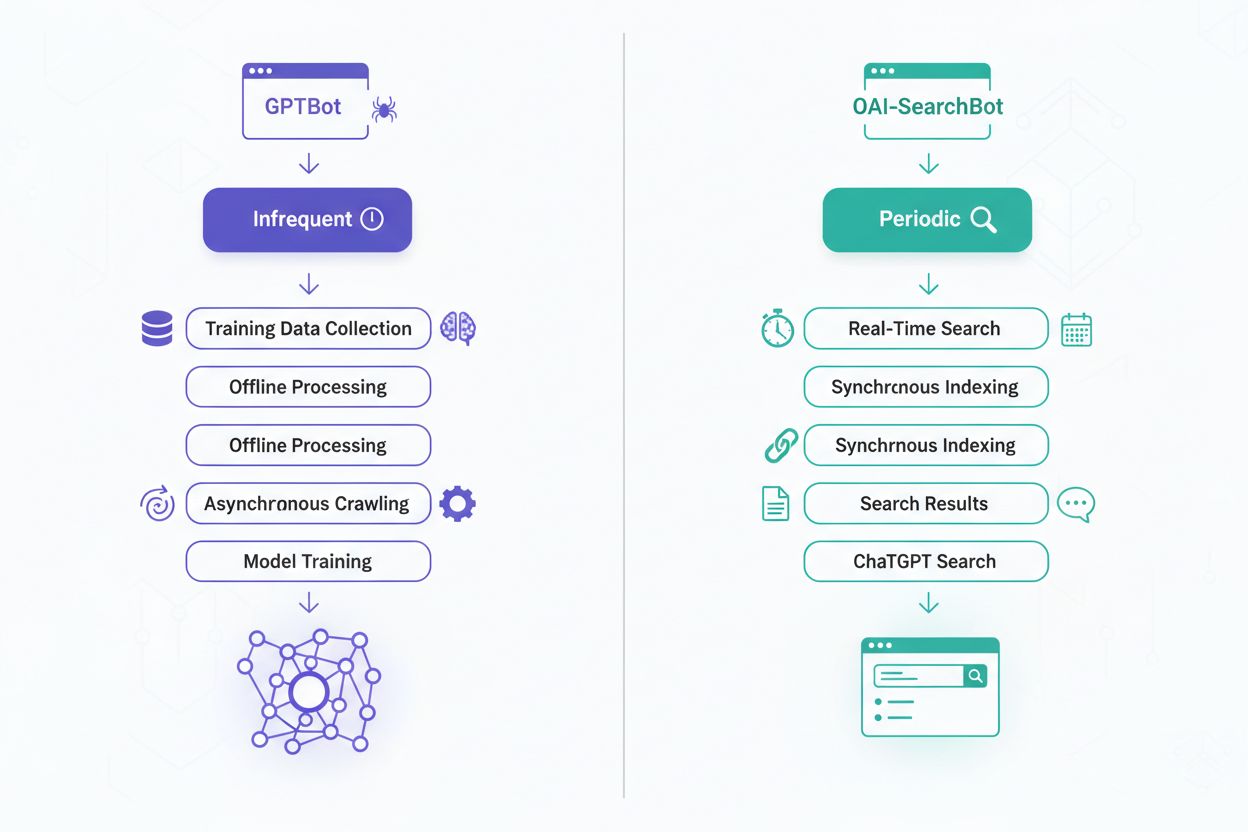
GPTBot folgt einem periodischen Crawl-Zeitplan und besucht Websites in Abständen von Wochen oder Monaten – abhängig von Aktualität und Bedeutung der Inhalte. Da GPTBot keine Echtzeitdaten benötigt, ist er bandbreiten- und serverfreundlich. Die Tiefe und Breite des Crawlens sind meist umfassend, da GPTBot möglichst vielfältige Inhalte und Schreibstile für das KI-Training erfassen möchte. OAI-SearchBot hingegen verfolgt einen aggressiveren Crawl-Ansatz mit häufigeren Wiederholungen, um Indizes stets aktuell zu halten. Er priorisiert frisch aktualisierte Inhalte und Trendthemen, indem er beliebte oder oft aktualisierte Websites mehrfach besucht. Die Frequenzunterschiede spiegeln ihre unterschiedlichen Ziele wider: GPTBot ist gründlich und geduldig, OAI-SearchBot hingegen muss mit der schnellen Entwicklung des Webs Schritt halten, um relevante Suchergebnisse zu liefern.
Erlauben Sie GPTBot den Zugriff, werden Ihre Inhalte Teil der Trainingsdaten für zukünftige KI-Modelle und können beeinflussen, wie KI-Systeme Themen aus Ihrem Bereich verstehen und Inhalte generieren. Das bringt langfristige Vorteile, da Ihr Schreibstil, Ihre Fachkenntnisse und Ihre Perspektiven die KI-Antworten in Ihrem Themengebiet prägen können. Allerdings werden Ihre Inhalte so auch zur Schulung von Systemen genutzt, die später mit Ihren Originalinhalten konkurrieren könnten. Der Zugriff von OAI-SearchBot wirkt sich direkt auf die Sichtbarkeit in den ChatGPT-Suchergebnissen aus: Ihre Inhalte werden für Millionen von Nutzer*innen auffindbar, die nach Informationen suchen. Finden Nutzer Ihre Inhalte über die ChatGPT-Suche, kann das erheblichen Traffic und eine stärkere Positionierung als Autoritätsquelle bedeuten. Die Auswirkungen unterscheiden sich also deutlich: GPTBot beeinflusst Ihre Rolle bei der KI-Entwicklung, OAI-SearchBot Ihre unmittelbare Auffindbarkeit und das Potenzial für Besucherströme. Content-Ersteller sollten diese Faktoren je nach Zielsetzung abwägen – ob sie Wert auf KI-Training oder Suchsichtbarkeit legen.
Sowohl GPTBot als auch OAI-SearchBot halten sich an die robots.txt-Datei, sodass Sie als Website-Betreiber die Kontrolle über den Zugriff der Crawler über etablierte Protokolle behalten. Sie können einen oder beide Crawler durch gezielte Anweisungen in robots.txt blockieren oder auch zulassen und andere Crawler ausschließen. Diese Flexibilität ermöglicht differenzierte Content-Strategien, bei denen Sie z. B. einen Crawler zulassen und den anderen blockieren – ganz nach Ihren Anforderungen und Bedenken. OpenAI stellt dazu auch offizielle Dokumentationen und Richtlinien bereit, sodass die Umsetzung Ihrer Zugangspolitik unkompliziert ist. Die robots.txt-Methode ist transparent, entspricht Web-Standards und ist mit anderen Tools und Monitoringsystemen kompatibel. Hier einige übliche Konfigurationen:
User-agent: GPTBot und User-agent: OAI-SearchBot mit Disallow: /User-agent: GPTBot mit Disallow: / und OAI-SearchBot erlaubenUser-agent: OAI-SearchBot mit Disallow: / und GPTBot erlaubenDisallow: /private/ den Zugriff auf sensible Bereiche verhindernCrawl-delay: 10 die Crawl-Frequenz und Serverbelastung steuernUm zu überprüfen, ob OpenAI-Crawler tatsächlich auf Ihre Website zugreifen, sollten Sie Ihre Server-Logs nach den spezifischen User-Agent-Strings durchsuchen. GPTBot-Anfragen erkennen Sie an “GPTBot”, OAI-SearchBot an “OAI-SearchBot” im Access-Log. Viele Website-Betreiber nutzen Log-Analyse-Tools oder Web-Analyse-Plattformen, die Aktivitäten gezielt auswerten können. Das Monitoring des Crawler-Verhaltens hilft Ihnen, zu beurteilen, ob Ihre robots.txt-Richtlinien funktionieren und ob die Crawler Ihre Vorgaben respektieren. Die regelmäßige Überwachung zeigt außerdem Crawl-Muster und Frequenzen auf, sodass Sie Ihre Serverressourcen optimieren und die Auswirkungen auf Ihre Infrastruktur verstehen können. Zusätzlich können Sie Crawler-IP-Adressen mit den von OpenAI veröffentlichten Bereichen abgleichen, um legitime Anfragen von möglichen Angriffen zu unterscheiden.
Ob Sie diese Crawler zulassen oder blockieren, sollte sich an Ihrer Content-Strategie und Ihren Geschäftszielen orientieren. Wenn Sie hauptsächlich Traffic und Sichtbarkeit wünschen, empfiehlt sich die Zulassung von OAI-SearchBot, da dies Ihre Auffindbarkeit in den ChatGPT-Suchergebnissen direkt beeinflusst. Haben Sie Bedenken bezüglich des KI-Trainings oder möchten Sie die Kontrolle über Ihre Inhalte behalten, schützt das Blockieren von GPTBot Ihr geistiges Eigentum vor der Verwendung im Modelltraining. Einige Websites setzen auf einen hybriden Ansatz: OAI-SearchBot wird für die Suchsichtbarkeit zugelassen, GPTBot dagegen blockiert. Berücksichtigen Sie auch den Inhaltstyp: Nachrichtenportale und aktuelle Themen profitieren besonders von OAI-SearchBot, während Anbieter proprietärer oder sensibler Inhalte häufig beide blockieren. Die Entscheidung ist nicht endgültig – Sie können Ihre robots.txt jederzeit anpassen, um Ihre Zugriffsrichtlinien zu ändern. Prüfen Sie Ihre Crawler-Strategie regelmäßig, damit sie weiterhin zu Ihren Zielen und Prioritäten passt.
AmICited bietet umfassende Lösungen zur Überwachung von Crawlern, mit denen Sie Aktivitäten von GPTBot und OAI-SearchBot auf Ihrer Website samt detaillierter Analysen und Einblicke verfolgen können. Die Plattform informiert Sie in Echtzeit, wenn diese Crawler auf Ihre Inhalte zugreifen. So können Sie die Einhaltung Ihrer robots.txt-Richtlinien prüfen und Crawl-Muster überwachen. Mit AmICited erhalten Sie Transparenz darüber, wie Ihre Inhalte von OpenAI indexiert und genutzt werden – und können datengestützte Entscheidungen über Ihre Zugriffsrichtlinien treffen. Diese Monitoring-Lösung vereinfacht die Kontrolle über die Rolle Ihrer Inhalte im KI-Training und in der Suchindexierung und gibt Ihnen die nötige Übersicht und Steuerung in einer sich wandelnden KI-Landschaft.
Verfolgen Sie, wie GPTBot und OAI-SearchBot auf Ihre Inhalte zugreifen – mit Echtzeit-Einblicken und Analysen. Verstehen Sie die Rolle Ihrer Inhalte beim KI-Training und der Suchindexierung.
Erfahren Sie, was GPTBot ist, wie er funktioniert und ob Sie ihn von Ihrer Website blockieren sollten. Verstehen Sie die Auswirkungen auf SEO, Serverlast und Ma...

Erfahren Sie, was GPTBot ist, wie er funktioniert und ob Sie den Webcrawler von OpenAI zulassen oder blockieren sollten. Verstehen Sie die Auswirkungen auf Ihre...
Erfahren Sie, was OAI-SearchBot ist, wie er funktioniert und wie Sie Ihre Website für OpenAIs dedizierten Suchcrawler für SearchGPT und ChatGPT optimieren.
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.