
AI-crawlers förklarade: GPTBot, ClaudeBot och fler
Förstå hur AI-crawlers som GPTBot och ClaudeBot fungerar, deras skillnader från traditionella sökmotor-crawlers och hur du optimerar din webbplats för synlighet...
12 min läsning

Lär dig hur du implementerar noai och noimageai-metataggar för att kontrollera AI-crawlers åtkomst till ditt webbplatsinnehåll. Komplett guide till AI-åtkomstkontroll med headers och implementeringsmetoder.
Webb-crawlers är automatiserade program som systematiskt surfar på internet och samlar in information från webbplatser. Historiskt sett har dessa botar främst körts av sökmotorer som Google, vars Googlebot crawlar sidor, indexerar innehåll och skickar trafik tillbaka till webbplatser via sökresultat—vilket skapar en ömsesidigt fördelaktig relation. Men framväxten av AI-crawlers har fundamentalt förändrat denna dynamik. Till skillnad från traditionella sökmotorbotar som ger hänvisningstrafik i utbyte mot innehållsåtkomst konsumerar AI-träningscrawlers enorma mängder webbplatsinnehåll för att bygga dataset till stora språkmodeller, och ger ofta minimal eller ingen trafik tillbaka till utgivarna. Denna förändring har gjort metataggar—små HTML-instruktioner som kommunicerar direktiv till crawlers—allt viktigare för innehållsskapare som vill behålla kontrollen över hur deras arbete används av artificiella intelligenssystem.
noai och noimageai-metataggarna är direktiv som skapades av DeviantArt 2022 för att hjälpa innehållsskapare förhindra att deras verk används för att träna AI-bildgeneratorer. Dessa taggar fungerar likt den väletablerade noindex-instruktionen som talar om för sökmotorer att inte indexera en sida. noai-direktivet signalerar att inget innehåll på sidan får användas för AI-träning, medan noimageai specifikt förhindrar att bilder används för AI-modellträning. Du kan implementera dessa taggar i HTML-head-sektionen med följande syntax:
<!-- Blockera allt innehåll från AI-träning -->
<meta name="robots" content="noai">
<!-- Blockera endast bilder från AI-träning -->
<meta name="robots" content="noimageai">
<!-- Blockera både innehåll och bilder -->
<meta name="robots" content="noai, noimageai">
Här är en jämförelsetabell över olika metataggar och deras syften:
| Direktivet | Syfte | Syntax | Omfattning |
|---|---|---|---|
| noai | Förhindrar allt innehåll från AI-träning | content="noai" | Hela sidans innehåll |
| noimageai | Förhindrar bilder från AI-träning | content="noimageai" | Endast bilder |
| noindex | Förhindrar indexering av sökmotorer | content="noindex" | Sökresultat |
| nofollow | Förhindrar länkföljning | content="nofollow" | Utgående länkar |
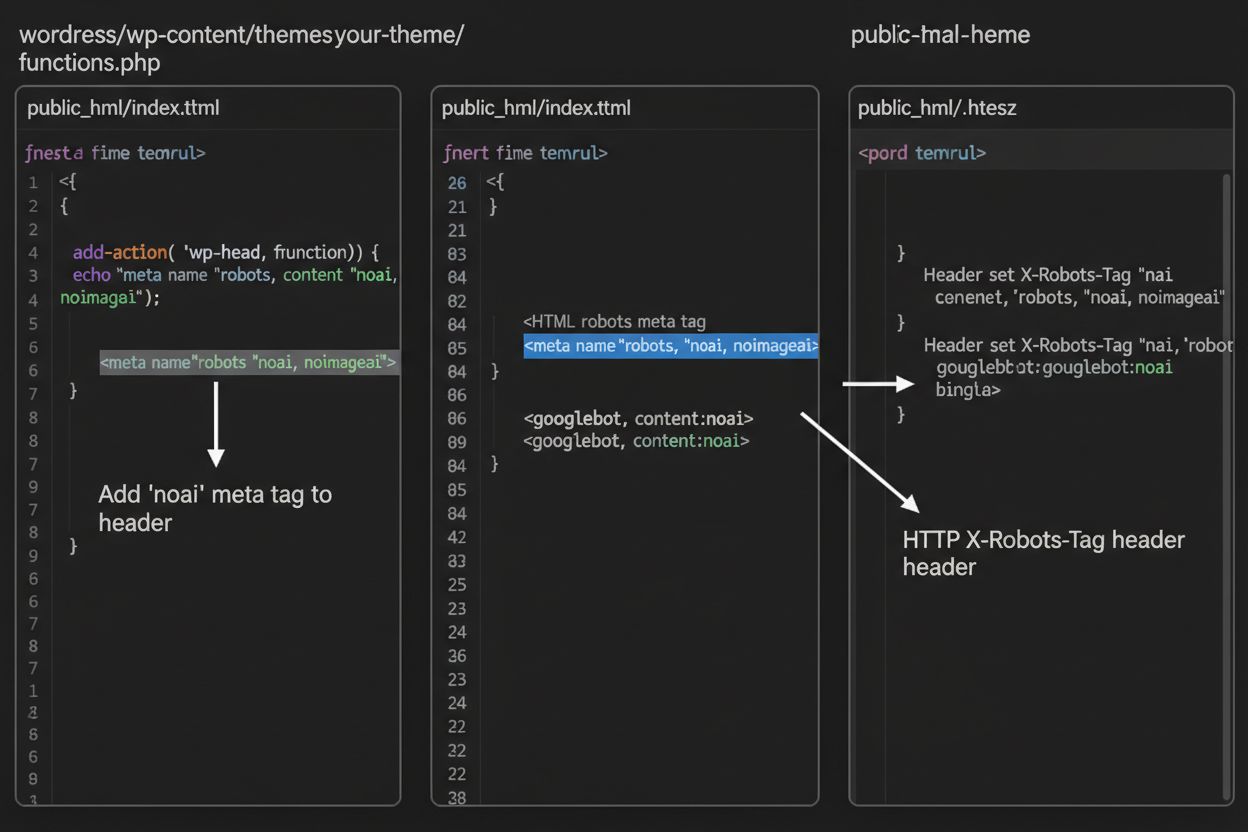
Medan metataggar placeras direkt i din HTML, ger HTTP-headers ett alternativt sätt att kommunicera crawlerdirektiv på servernivå. X-Robots-Tag-headern kan inkludera samma direktiv som metataggar men fungerar annorlunda—den skickas i HTTP-svaret innan sidinnehållet levereras. Detta är särskilt värdefullt för att kontrollera åtkomst till icke-HTML-filer som PDF:er, bilder och videor där du inte kan bädda in HTML-metataggar.
För Apache-servrar kan du ställa in X-Robots-Tag headers i din .htaccess-fil:
<IfModule mod_headers.c>
Header set X-Robots-Tag "noai, noimageai"
</IfModule>
För NGINX-servrar, lägg till headern i din serverkonfiguration:
location / {
add_header X-Robots-Tag "noai, noimageai";
}
Headers ger globalt skydd över hela webbplatsen eller specifika kataloger, vilket gör dem idealiska för heltäckande AI-åtkomstkontroll.
Effektiviteten hos noai- och noimageai-taggar beror helt på om crawlers väljer att respektera dem. Väluppfostrade crawlers från större AI-företag följer vanligtvis dessa direktiv:
Däremot kan dåligt uppförda botar och illvilliga crawlers medvetet ignorera dessa direktiv eftersom det inte finns någon tillsynsmekanism. Till skillnad från robots.txt, som sökmotorer har gått med på att respektera som branschstandard, är noai ingen officiell webbstandard, vilket betyder att crawlers inte har någon skyldighet att följa dem. Därför rekommenderar säkerhetsexperter en lager-på-lager-strategi som kombinerar flera skyddsmetoder istället för att enbart lita på metataggar.
Implementeringen av noai- och noimageai-taggar skiljer sig beroende på din webbplatsplattform. Här är steg-för-steg-instruktioner för de vanligaste plattformarna:
1. WordPress (via functions.php) Lägg till denna kod i ditt child themes functions.php-fil:
function add_noai_meta_tag() {
echo '<meta name="robots" content="noai, noimageai">' . "\n";
}
add_action('wp_head', 'add_noai_meta_tag');
2. Statiska HTML-sajter
Lägg till direkt i <head>-sektionen i din HTML:
<head>
<meta name="robots" content="noai, noimageai">
</head>
3. Squarespace Navigera till Inställningar > Avancerat > Kodinjektion, och lägg till i Header-sektionen:
<meta name="robots" content="noai, noimageai">
4. Wix Gå till Inställningar > Anpassad kod, klicka på “Lägg till anpassad kod”, klistra in metataggen, välj “Head” och tillämpa på alla sidor.
Varje plattform erbjuder olika nivåer av kontroll—WordPress möjliggör sid-specifik implementering via plugins, medan Squarespace och Wix erbjuder globala lösningar för hela webbplatsen. Välj det sätt som passar din tekniska kunskapsnivå och specifika behov bäst.
Även om noai- och noimageai-taggar utgör ett viktigt steg mot skydd för innehållsskapare har de betydande begränsningar. För det första, detta är inga officiella webbstandarder—DeviantArt skapade dem som ett gemenskapsinitiativ, vilket betyder att det inte finns någon formell specifikation eller tillsynsmekanism. För det andra, efterlevnad är helt frivillig. Väluppfostrade crawlers från större företag respekterar dessa, men dåligt uppförda botar och scrapers kan ignorera dem utan konsekvenser. För det tredje, brist på standardisering innebär varierande adoption. Vissa mindre AI-företag och forskningsorganisationer kanske inte ens känner till dessa direktiv, än mindre implementerar stöd för dem. Slutligen, metataggar ensamma kan inte stoppa beslutsamma angripare från att skrapa ditt innehåll. En illvillig crawler kan helt ignorera dina instruktioner, vilket gör ytterligare skyddslager nödvändiga för heltäckande innehållssäkerhet.
Den mest effektiva AI-åtkomstkontrollstrategin använder flera lager av skydd snarare än att förlita sig på en enskild metod. Här är en jämförelse mellan olika skyddsmetoder:
| Metod | Omfattning | Effektivitet | Svårighetsgrad |
|---|---|---|---|
| Metataggar (noai) | Sidnivå | Medel (frivillig efterlevnad) | Lätt |
| robots.txt | Hela sajten | Medel (rådgivande) | Lätt |
| X-Robots-Tag Headers | Servernivå | Medel-Hög (täcker alla filtyper) | Medel |
| Brandväggsregler | Nätverksnivå | Hög (blockerar på infrastruktur) | Svår |
| IP-vitlistning | Nätverksnivå | Mycket hög (endast verifierade källor) | Svår |
En heltäckande strategi kan inkludera: (1) implementera noai-metataggar på alla sidor, (2) lägga till robots.txt-regler som blockerar kända AI-träningscrawlers, (3) sätta X-Robots-Tag headers på servernivå för icke-HTML-filer och (4) övervaka serverloggar för att identifiera crawlers som ignorerar dina instruktioner. Denna lager-på-lager-metod ökar avsevärt svårigheten för angripare och bibehåller kompatibilitet med väluppfostrade crawlers som respekterar dina preferenser.
Efter att du har implementerat noai-taggar och andra direktiv bör du verifiera att crawlers faktiskt respekterar dina regler. Det mest direkta sättet är att kontrollera dina server access logs för crawler-aktivitet. På Apache-servrar kan du söka efter specifika crawlers:
grep "GPTBot\|ClaudeBot\|PerplexityBot" /var/log/apache2/access.log
Om du ser förfrågningar från crawlers du har blockerat, ignorerar de dina instruktioner. För NGINX-servrar, kontrollera /var/log/nginx/access.log med samma grep-kommando. Dessutom ger verktyg som Cloudflare Radar insyn i AI-crawlertrafikmönster på din webbplats, och visar vilka botar som är mest aktiva och hur deras beteende förändras över tid. Regelbunden loggövervakning—minst en gång i månaden—hjälper dig identifiera nya crawlers och verifiera att dina skyddsåtgärder fungerar som tänkt.
För närvarande befinner sig noai och noimageai i ett gränsland: de är allmänt igenkända och respekteras av större AI-företag, men är fortfarande inofficiella och ostandardiserade. Det finns dock en växande rörelse mot formell standardisering. W3C (World Wide Web Consortium) och olika branschgrupper diskuterar hur man kan skapa officiella standarder för AI-åtkomstkontroll som skulle ge dessa direktiv samma tyngd som etablerade standarder som robots.txt. Om noai skulle bli en officiell webbstandard, skulle efterlevnad bli förväntad branschpraxis snarare än frivillig, vilket avsevärt skulle öka dess effektivitet. Detta standardiseringsarbete speglar ett bredare skifte i hur teknikindustrin ser på innehållsskaparnas rättigheter och balansen mellan AI-utveckling och publicistskydd. I takt med att fler publicister tar dessa taggar i bruk och kräver starkare skydd ökar sannolikheten för officiell standardisering, vilket potentiellt gör AI-åtkomstkontroll lika grundläggande för webbens styrning som reglerna för sökmotorindexering.
Noai-metataggen är en instruktion som placeras i din webbplats HTML-head-sektion och signalerar till AI-crawlers att ditt innehåll inte får användas för att träna artificiella intelligensmodeller. Den fungerar genom att kommunicera din preferens till väluppfostrade AI-botar, även om det inte är en officiell webbstandard och vissa crawlers kan ignorera den.
Nej, noai och noimageai är inte officiella webbstandarder. De skapades av DeviantArt som ett gemenskapsinitiativ för att hjälpa innehållsskapare skydda sitt arbete från AI-träning. Dock har större AI-företag som OpenAI, Anthropic och andra börjat respektera dessa instruktioner i sina crawlers.
Större AI-crawlers såsom GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity), Amazonbot (Amazon) och andra respekterar noai-instruktionen. Men vissa mindre eller dåligt uppförda crawlers kan ignorera den, vilket är anledningen till att ett lager-på-lager-skydd rekommenderas.
Metataggar placeras i din HTML-head-sektion och gäller för enskilda sidor, medan HTTP-headers (X-Robots-Tag) sätts på servernivå och kan gälla globalt eller för specifika filtyper. Headers fungerar för icke-HTML-filer som PDF:er och bilder, vilket gör dem mer mångsidiga för heltäckande skydd.
Ja, du kan implementera noai-taggar på WordPress på flera sätt: genom att lägga till kod i ditt temas functions.php-fil, använda ett plugin som WPCode, eller via sidbyggarverktyg som Divi och Elementor. Metoden med functions.php är vanligast och innebär att man lägger till en enkel hook för att injicera metataggen i webbplatsens header.
Detta beror på dina affärsmål. Att blockera tränings-crawlers skyddar ditt innehåll från att användas i AI-modellutveckling. Men att blockera sökcrawlers som OAI-SearchBot kan minska din synlighet i AI-drivna sökresultat och upptäcktsplattformar. Många publicister använder en selektiv strategi som blockerar tränings-crawlers men tillåter sökcrawlers.
Du kan kontrollera dina serverloggar för crawler-aktivitet med kommandon som grep för att söka efter specifika bot-user agents. Verktyg som Cloudflare Radar ger insyn i AI-crawlertrafikmönster. Övervaka dina loggar regelbundet för att se om blockerade crawlers fortfarande når ditt innehåll, vilket skulle indikera att de ignorerar dina instruktioner.
Om crawlers ignorerar dina metataggar, implementera ytterligare skyddslager inklusive robots.txt-regler, X-Robots-Tag HTTP-headers och serverblockering via .htaccess eller brandväggsregler. För starkare verifiering, använd IP-vitlistning för att endast tillåta förfrågningar från verifierade crawler-IP-adresser som publicerats av större AI-företag.
Använd AmICited för att spåra hur AI-system som ChatGPT, Perplexity och Google AI Overviews citerar och refererar till ditt innehåll på olika AI-plattformar.
Förstå hur AI-crawlers som GPTBot och ClaudeBot fungerar, deras skillnader från traditionella sökmotor-crawlers och hur du optimerar din webbplats för synlighet...

Omfattande guide till AI-crawlers 2025. Identifiera GPTBot, ClaudeBot, PerplexityBot och 20+ andra AI-botar. Lär dig blockera, tillåta eller övervaka crawlers m...

Lär dig identifiera och övervaka AI-crawlers som GPTBot, PerplexityBot och ClaudeBot i dina serverloggar. Upptäck user-agent-strängar, IP-verifieringsmetoder oc...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.