
Kanoniska URL:er och AI: Förhindra problem med duplicerat innehåll
Lär dig hur kanoniska URL:er förhindrar problem med duplicerat innehåll i AI-söksystem. Upptäck bästa praxis för implementering av kanoniska taggar för att förb...
6 min läsning

Lär dig hur ompublicering av innehåll orsakar problem med duplicerat innehåll som skadar AI-synlighet i sökresultat mer än traditionella sökmotorer. Upptäck tekniska skydd och bästa praxis.
Att ompublicera innehåll över flera kanaler, plattformar och format är en legitim och ofta nödvändig strategi för att maximera räckvidd och engagemang. Men denna praxis skapar en grundläggande spänning med hur söksystem—särskilt AI-drivna sådana—bearbetar och rankar innehåll. Utmaningen är inte om du kan ompublicera; det är om du gör det på ett sätt som inte saboterar din synlighet i AI-sökresultaten. Till skillnad från traditionella sökmotorer som har utvecklat sofistikerade mekanismer för att upptäcka duplicerat innehåll under årtionden, hanterar AI-system duplicerat innehåll annorlunda och skapar nya risker som många publicister ännu inte har anpassat sig till.
Enligt Microsofts tekniska dokumentation om Copilot och AI-sök “grupperar LLM:er närliggande duplicerade URL:er i en enda klunga och väljer sedan en sida som ska representera gruppen.” Detta klusterbeteende skiljer sig fundamentalt från hur Googles PageRank-algoritm fördelar auktoritet mellan duplicerade sidor. Istället för att konsolidera signaler gör AI-system ett binärt val: de väljer en representativ sida från ett kluster av liknande innehåll och ignorerar i stort sett de andra. Denna urvalsprocess är inte alltid förutsägbar eller baserad på den version du föredrar att ranka. Algoritmen tar hänsyn till faktorer som aktualitet, innehållskvalitet, tekniska signaler och domänauktoritet—men hur dessa faktorer viktas är oklart. Vad som gör detta särskilt problematiskt är att AI-system kan välja en föråldrad version om skillnaderna mellan sidorna är så små att klustringsalgoritmen inte upptäcker några meningsfulla variationer.
| Aspekt | Traditionell sökning | AI-sök |
|---|---|---|
| Hantering av dubbletter | Konsoliderar auktoritetssignaler | Klustrar och väljer en representant |
| Risk för straff | Möjlig manuell åtgärd | Inget straff, men utspädd synlighet |
| Uppdateringsigenkänning | Gradvis signalöverföring | Kan missa uppdateringar om skillnaden är liten |
| Crawl-effektivitet | Slösar budget på dubbletter | Minskar crawl-prioritet för dubbletter |
| Respekt för kanonisk | Respekteras men inte garanterat | Avgörande för klusterurval |
Ompublicering utan rätt skydd innebär tre sammankopplade risker som direkt påverkar AI-synligheten:
Intentionssignalernas utspädning: När samma innehåll finns på flera URL:er får AI-systemet motstridiga signaler om vilken version som bäst besvarar användarens fråga. Istället för att samla auktoritet till en URL sprids dina signaler över hela klustret. Denna utspädning minskar AI-systemens förtroendepoäng när de avgör om innehållet ska inkluderas i svar. Innehåll som kunde varit en primär källa blir en sekundär eftersom systemet inte med säkerhet kan avgöra vilken version som är auktoritativ.
Representationsrisk: Vilken sida AI-systemet väljer som representant för ditt innehållskluster kanske inte stämmer överens med dina affärsmål. Du kan ompublicera ett blogginlägg till ett syndikeringsnätverk i hopp om att den versionen ska driva trafik, bara för att AI-systemet väljer din ursprungliga domänversion—eller ännu värre, syndikeringsversionen som inte länkar tillbaka till din sajt. Denna feljustering betyder att din ompubliceringsstrategi motverkar dina synlighetsmål istället för att förstärka dem.
Fördröjning och föråldrat innehåll: När du uppdaterar ditt ursprungliga innehåll men de ompublicerade versionerna förblir oförändrade kan AI-system välja en föråldrad version som representativ sida. Klustringsalgoritmen känner inte alltid igen att en version är nyare eller mer korrekt, särskilt om ändringarna är gradvisa snarare än strukturella. Det kan leda till att ditt mest aktuella, exakta innehåll blir osynligt medan en äldre version representerar din expertis mot AI-system.
Det vanligaste misstaget vid ompublicering sker när innehåll syndikeras till tredjepartsplattformar utan att implementera kanoniska taggar. Tänk dig ett typiskt scenario: ett B2B-programvaruföretag publicerar en omfattande guide på sin blogg och syndikerar sedan den till branschpublikationer som Medium, LinkedIn och specialiserade nyhetsaggregatorer. Varje plattform har identiskt innehåll under olika URL:er. Utan kanoniska taggar som pekar tillbaka till originalet behandlar AI-systemets klustringsalgoritm alla versioner som lika auktoritativa. Syndikeringsplattformen kan ha högre domänauktoritet, vilket gör att AI-systemet väljer den versionen som representativ sida. Nu blir ditt ursprungliga innehåll—versionen du optimerat, uppdaterat och byggt länkar till—osynligt i AI-sökresultaten. Trafiken och auktoriteten går till syndikeringsplattformen istället för till din egen sajt. Detta scenario upprepas tusentals gånger dagligen i publicistbranschen, där publicister omedvetet saboterar sin egen synlighet genom att inte implementera en enda HTML-tagg.
Kampanjspecifikt innehåll skapar ett särskilt lömskt problem med duplicerat innehåll när det ompubliceras över flera kanaler. Ett marknadsföringsteam lanserar en kampanjsida optimerad för en specifik kampanj och ompublicerar sedan varianter av innehållet till nyhetsbrev, sociala medier, annonser och partnersajter. Varje version innehåller något annorlunda text, CTA eller formatering—men kärninnehållet och syftet är identiskt. AI-system identifierar dessa som närliggande dubbletter och klustrar dem tillsammans. Problemet förvärras när kampanjsidor ompubliceras utan korrekt kanonisk implementation. AI-systemet kan välja nyhetsbrevs-versionen (utan konverteringsspårning) som representant, eller partnersajtens version som inte bidrar till dina mätvärden. Dessutom, när kampanjer avslutas och sidor arkiveras eller tas bort kan AI-systemet redan ha valt en numera obrukbar version som representativ sida, vilket gör att ditt innehåll blir osynligt eller leder användare till brutna upplevelser.
Regional ompublicering gör det mer komplicerat eftersom upptäckt av duplicerat innehåll måste ta hänsyn till legitima lokaliseringsbehov. Ett företag med verksamhet i flera länder kan publicera samma kärninnehåll på olika språk eller med regionspecifika variationer. Utan korrekt implementation konkurrerar dessa regionala versioner med varandra i AI-klustringen. Tänk dig ett SaaS-företag som publicerar en funktionsguide på engelska på sin amerikanska domän och sedan ompublicerar den på sin brittiska domän med brittisk stavning och regionsspecifika priser. AI-systemet klustrar dessa som dubbletter och kan välja USA-versionen även för brittiska användare. Lösningen är att implementera hreflang-taggar som signalerar regionala relationer till AI-system, även om effekten av hreflang i AI-sök är mindre etablerad än i traditionell sökning.
<!-- På USA-versionen (example.com/feature-guide) -->
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
<!-- På UK-versionen (example.co.uk/feature-guide) -->
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
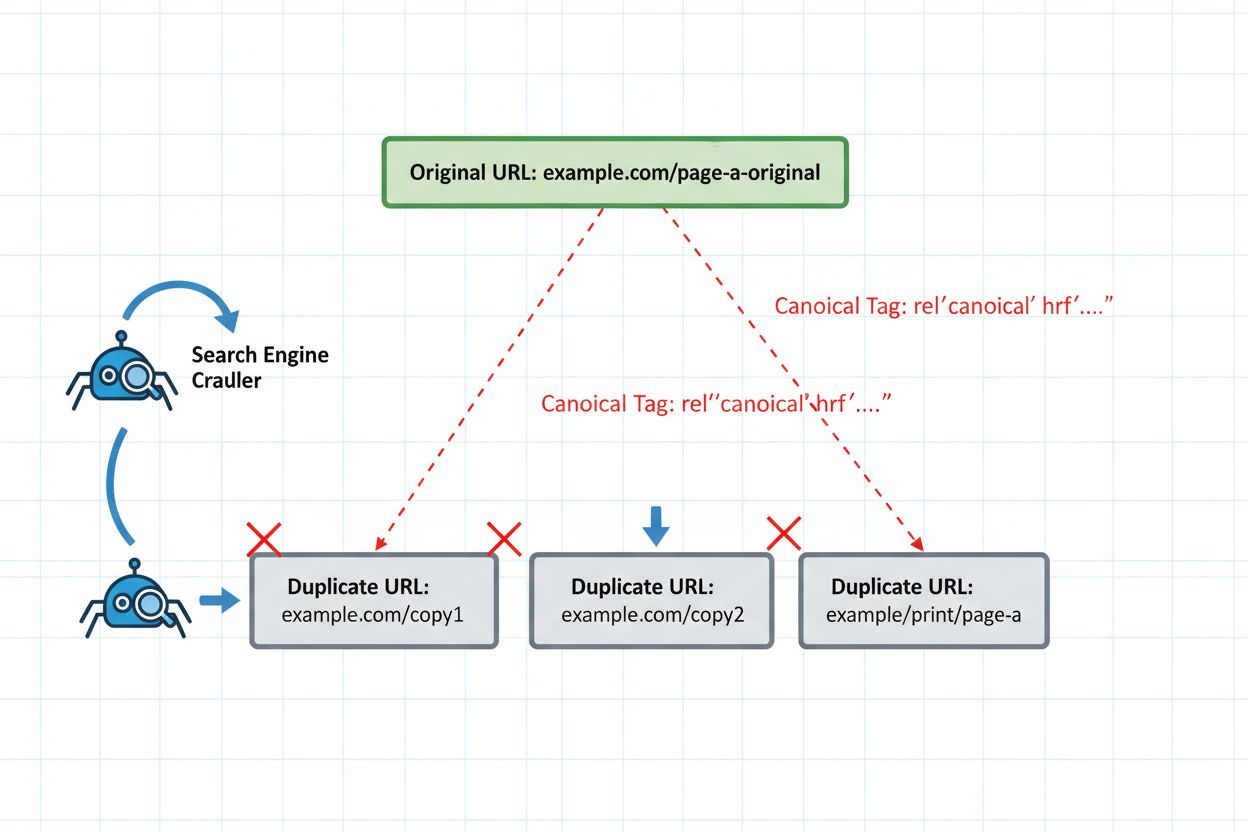
Att implementera rätt tekniska skydd är ett måste för säker ompublicering. Den kanoniska taggen är ditt främsta försvar och talar tydligt om för AI-system vilken version som ska representera ditt innehållskluster. Placera den kanoniska taggen i <head>-sektionen på varje ompublicerad version och peka mot din föredragna auktoritativa version. För syndikerat innehåll betyder det oftast att peka tillbaka till din ursprungliga domän.
<!-- På syndikerad version (medium.com/your-publication/article) -->
<link rel="canonical" href="https://yoursite.com/blog/article" />
För innehåll som aldrig ska konkurrera med andra versioner, implementera noindex på sekundära versioner. Detta tar bort dem helt från AI-indexeringen och säkerställer att de inte kan väljas som representativa sidor. Använd detta för interna dubblettsidor, testversioner eller syndikerat innehåll där du inte vill ha någon synlighet i AI-sök.
<!-- På sekundär version som inte ska indexeras -->
<meta name="robots" content="noindex, follow" />
301-omdirigeringar ger den starkaste signalen för att konsolidera auktoritet, men använd dem bara när den sekundära versionen aldrig ska uppdateras självständigt. Omdirigeringar talar om för AI-system att den gamla URL:en permanent har flyttat och samlar alla signaler till den nya platsen. Om du behöver båda versionerna tillgängliga (till exempel vid syndikering) kan omdirigeringar skapa problem eftersom de bryter syndikeringsplattformens URL-struktur.
# I .htaccess eller serverkonfiguration
Redirect 301 /old-article https://yoursite.com/new-article
I innehållshanteringssystem, implementera rel=“canonical” dynamiskt för att hantera sidindelning, parametrar och sessionsbaserade URL:er som skapar oavsiktliga dubbletter. Många CMS-plattformar genererar flera URL:er för samma innehåll via olika navigeringsvägar—kanoniska taggar konsoliderar dessa automatiskt.
IndexNow snabbar upp upptäckten av kanoniska signaler och konsolidering av dubbletter, så att det som tidigare tog veckor nu kan lösas på några dagar. När du implementerar kanoniska taggar på ompublicerat innehåll meddelar IndexNow söksystemen direkt att dessa URL:er ska klustras ihop. Istället för att vänta på att crawlers hittar den kanoniska relationen via normala crawl-mönster, skickar IndexNow denna information direkt till Microsofts index och andra deltagande söksystem. Detta är särskilt värdefullt om du i efterhand rättar till ompubliceringsmisstag—du kan implementera kanoniska taggar och använda IndexNow för att signalera ändringen direkt, utan att vänta på att crawlers ska besöka sidorna igen. För publicister som hanterar innehåll över flera plattformar blir IndexNow ett avgörande verktyg för att behålla kontrollen över vilken version som representerar ditt innehållskluster. API-integrationen gör att du kan skicka in URL:er i bulk, vilket gör det praktiskt att hantera hundratals eller tusentals ompublicerade sidor.
POST https://api.indexnow.org/indexnow
{
"host": "yoursite.com",
"key": "your-api-key",
"keyLocation": "https://yoursite.com/indexnow-key.txt",
"urlList": [
"https://yoursite.com/blog/article-1",
"https://yoursite.com/blog/article-2"
]
}
Att spåra vilken version av ditt ompublicerade innehåll som väljs ut av AI-system kräver övervakning utöver traditionell analys. Sätt upp spårning för att identifiera när AI-system citerar eller refererar till ditt innehåll och notera vilken URL som visas i AI-sökresultat. Verktyg som Semrush, Ahrefs och Moz börjar lägga till mätvärden för AI-synlighet, även om dessa fortfarande är mindre utvecklade än traditionell sökspårning. Implementera UTM-parametrar på syndikerade versioner för att spåra trafik, men tänk på att AI-system kanske inte för vidare dessa parametrar, vilket gör direkt attribution svår. Övervaka ditt Search Console (eller motsvarande verktyg för andra söksystem) för crawl-mönster—om sekundära versioner crawlas oftare än din kanoniska version indikerar det att AI-systemet kan ha valt fel representativ sida. Sätt upp aviseringar för omnämnanden av ditt innehåll på syndikeringsplattformar och jämför dessa med din AI-synlighet för att hitta avvikelser mellan var ditt innehåll syns och var AI-systemen väljer det ifrån.
Använd denna checklista innan du ompublicerar något innehåll för att säkerställa att du behåller kontrollen över AI-synligheten:
Innan du ompublicerar, identifiera din kanoniska version—URL:en du vill ska representera detta innehåll i AI-sökresultat. Detta bör vanligtvis vara din egen domän, inte en syndikeringsplattform. Implementera kanoniska taggar på varje ompublicerad version som pekar till din kanoniska URL, även om du ompublicerar till egna egendomar (olika domäner, subdomäner eller parametrar). Använd IndexNow för att omedelbart meddela söksystemen om den kanoniska relationen istället för att vänta på crawl-upptäckt. Undvik att ompublicera till auktoritetsstarka plattformar utan stöd för kanoniska taggar—vissa plattformar tar bort kanoniska taggar eller tillåter dem inte, vilket gör dem olämpliga för ompublicering utan att acceptera synlighetsförlust. Övervaka de första 48 timmarna efter ompublicering för att verifiera att AI-systemen väljer din avsedda kanoniska version och ingen annan. Uppdatera alla versioner samtidigt när du gör ändringar i innehållet—om du bara uppdaterar den kanoniska versionen kanske klustringsalgoritmen inte känner igen uppdateringen på alla versioner, vilket kan göra att AI-systemet väljer en föråldrad version. Etablera ett schema för ompublicering som förhindrar att innehållet blir föråldrat på sekundära plattformar; föråldrat syndikerat innehåll ökar risken att AI-system väljer det som representativ version om din kanoniska version inte uppdaterats nyligen.
Kanoniska taggar förhindrar inte straff eftersom duplicerat innehåll inte utlöser straff från början. Däremot är kanoniska taggar avgörande för AI-sök eftersom de talar om för AI-system vilken version som ska representera ditt innehållskluster. Utan kanoniska taggar kan AI-system välja en oavsiktlig version som auktoritativ källa, vilket minskar din synlighet.
Övervaka vilka URL:er som visas i AI-sökresultat och citeringar av ditt innehåll. Verktyg som Semrush och Ahrefs lägger till mätvärden för AI-synlighet. Kontrollera ditt Search Console för crawl-mönster—om sekundära versioner crawlas oftare än din kanoniska version kan AI-systemet ha valt fel sida.
Tekniskt sett ja, men det rekommenderas inte. Utan kanoniska taggar kommer AI-system att klustra ditt innehåll och välja en version som representant—men du styr inte vilken. Syndikeringsplattformen kan ha högre auktoritet, vilket gör att AI väljer den versionen istället för din ursprungliga domän.
Ompublicering syftar vanligtvis på att distribuera ditt innehåll över flera kanaler du kontrollerar eller samarbetar med. Innehållssyndikering är en specifik form av ompublicering där tredjepartsplattformar ompublicerar ditt innehåll med ditt tillstånd. Båda skapar problem med duplicerat innehåll om de inte hanteras korrekt med kanoniska taggar.
Kanoniska taggar känns oftast igen inom 24–48 timmar om du använder IndexNow för att omedelbart meddela söksystemen. Utan IndexNow kan det ta veckor för crawlers att upptäcka den kanoniska relationen. Därför är IndexNow avgörande för att hantera ompublicerat innehåll—det snabbar upp processen avsevärt.
Använd 301-omdirigeringar endast när du vill permanent konsolidera URL:er och den sekundära versionen aldrig kommer att uppdateras självständigt. Använd kanoniska taggar när båda versionerna behöver vara tillgängliga (som vid syndikering). Omdirigeringar är starkare signaler men bryter den sekundära URL:ens funktionalitet.
Ja, om det inte hanteras korrekt. Ompublicering utan kanoniska taggar späder ut dina auktoritetssignaler över flera URL:er. AI-system kan välja syndikeringsversionen istället för din ursprungliga, vilket minskar synligheten på din ägda domän. Korrekt implementering av kanoniska taggar förhindrar detta.
Implementera kanoniska taggar på varje ompublicerad version som pekar på din ursprungliga domän. Använd IndexNow för att omedelbart meddela söksystemen om den kanoniska relationen. Undvik att ompublicera till plattformar som inte stöder kanoniska taggar. Övervaka vilken version AI-systemen väljer under de första 48 timmarna och justera vid behov.
Spåra hur AI-system citerar och refererar till ditt ompublicerade innehåll över alla plattformar. Få insikter i realtid om vilken version AI väljer som din auktoritativa källa.
Lär dig hur kanoniska URL:er förhindrar problem med duplicerat innehåll i AI-söksystem. Upptäck bästa praxis för implementering av kanoniska taggar för att förb...

Lär dig hur du omarbetar och optimerar innehåll för AI-plattformar som ChatGPT, Perplexity och Claude. Upptäck strategier för AI-synlighet, innehållsstruktureri...
Lär dig hur du hanterar och förebygger duplicerat innehåll när du använder AI-verktyg. Upptäck kanoniska taggar, omdirigeringar, verktyg för upptäckt och bästa ...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.